 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
View-Centric Multi-Object Tracking with Homographic Matching in Moving UAV
Mar 16, 2024

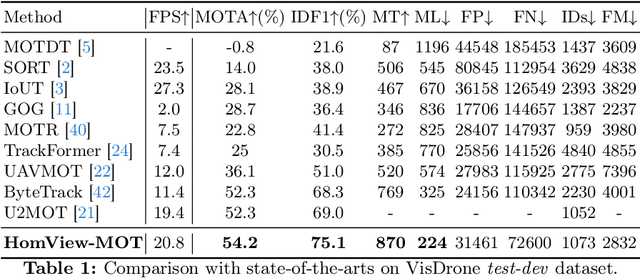
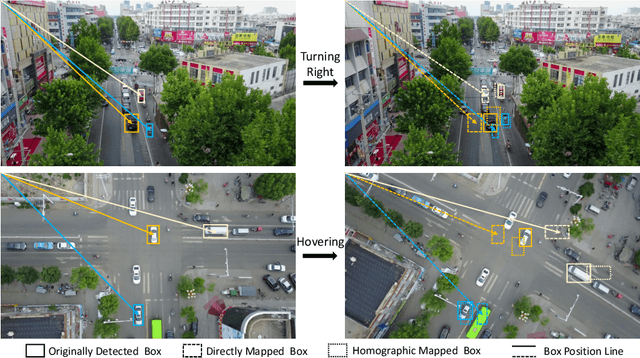
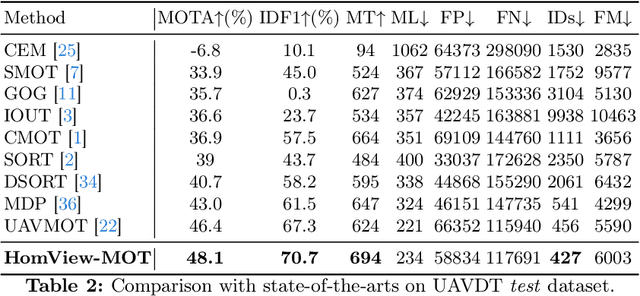
In this paper, we address the challenge of multi-object tracking (MOT) in moving Unmanned Aerial Vehicle (UAV) scenarios, where irregular flight trajectories, such as hovering, turning left/right, and moving up/down, lead to significantly greater complexity compared to fixed-camera MOT. Specifically, changes in the scene background not only render traditional frame-to-frame object IOU association methods ineffective but also introduce significant view shifts in the objects, which complicates tracking. To overcome these issues, we propose a novel universal HomView-MOT framework, which for the first time, harnesses the view Homography inherent in changing scenes to solve MOT challenges in moving environments, incorporating Homographic Matching and View-Centric concepts. We introduce a Fast Homography Estimation (FHE) algorithm for rapid computation of Homography matrices between video frames, enabling object View-Centric ID Learning (VCIL) and leveraging multi-view Homography to learn cross-view ID features. Concurrently, our Homographic Matching Filter (HMF) maps object bounding boxes from different frames onto a common view plane for a more realistic physical IOU association. Extensive experiments have proven that these innovations allow HomView-MOT to achieve state-of-the-art performance on prominent UAV MOT datasets VisDrone and UAVDT.
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024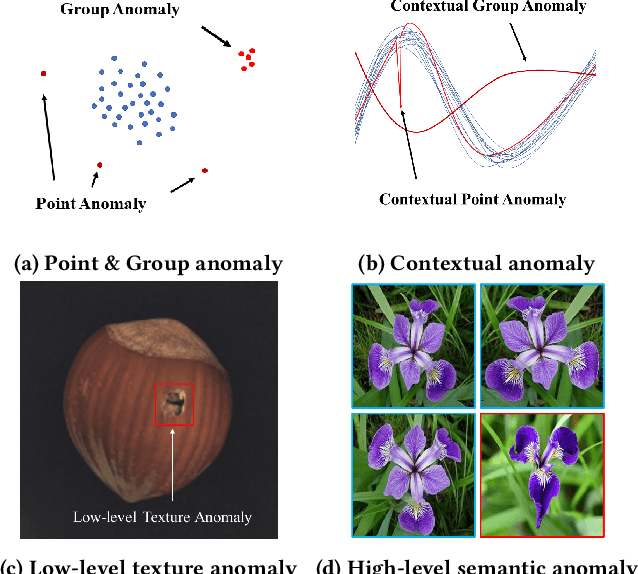
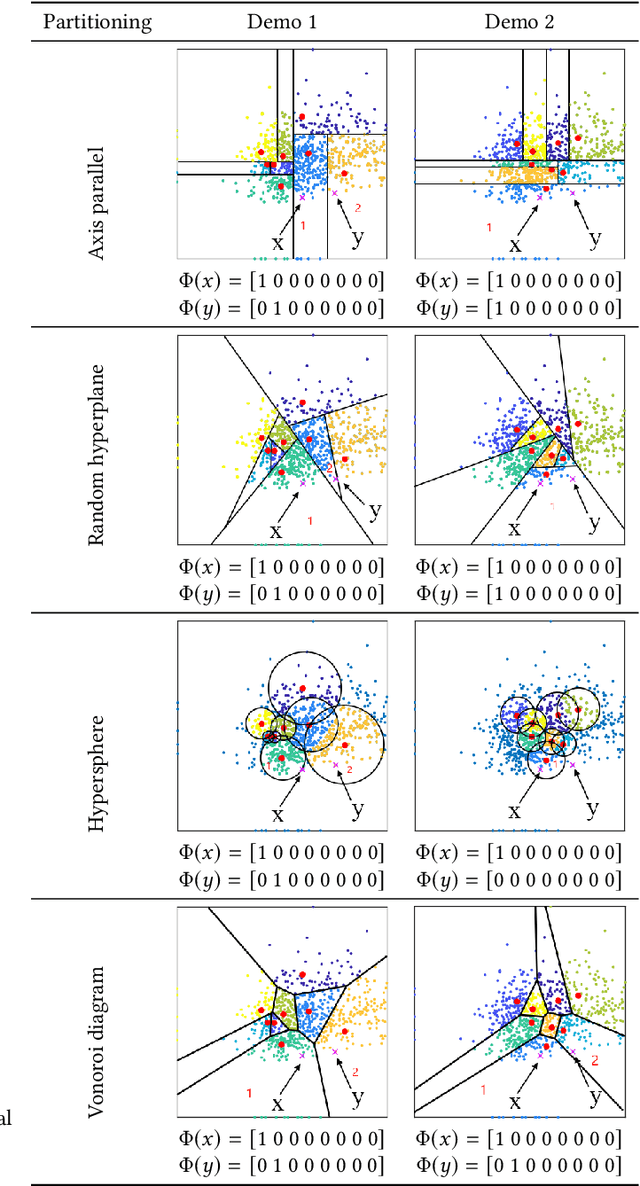
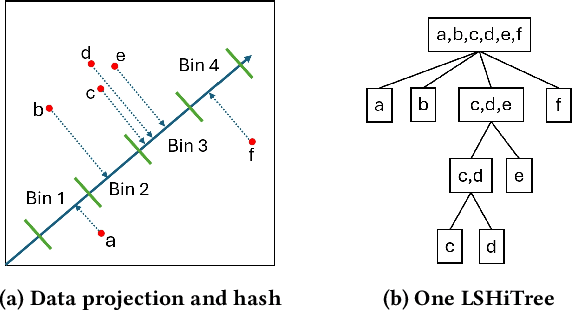

Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
CORN: Contact-based Object Representation for Nonprehensile Manipulation of General Unseen Objects
Mar 16, 2024


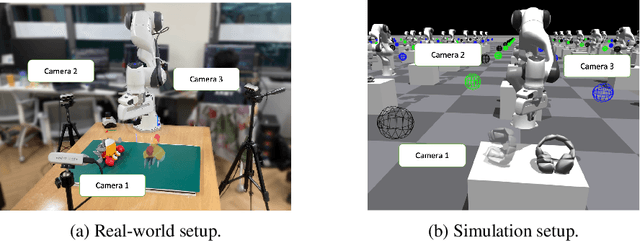
Nonprehensile manipulation is essential for manipulating objects that are too thin, large, or otherwise ungraspable in the wild. To sidestep the difficulty of contact modeling in conventional modeling-based approaches, reinforcement learning (RL) has recently emerged as a promising alternative. However, previous RL approaches either lack the ability to generalize over diverse object shapes, or use simple action primitives that limit the diversity of robot motions. Furthermore, using RL over diverse object geometry is challenging due to the high cost of training a policy that takes in high-dimensional sensory inputs. We propose a novel contact-based object representation and pretraining pipeline to tackle this. To enable massively parallel training, we leverage a lightweight patch-based transformer architecture for our encoder that processes point clouds, thus scaling our training across thousands of environments. Compared to learning from scratch, or other shape representation baselines, our representation facilitates both time- and data-efficient learning. We validate the efficacy of our overall system by zero-shot transferring the trained policy to novel real-world objects. Code and videos are available at https://sites.google.com/view/contact-non-prehensile.
Automatic location detection based on deep learning
Mar 16, 2024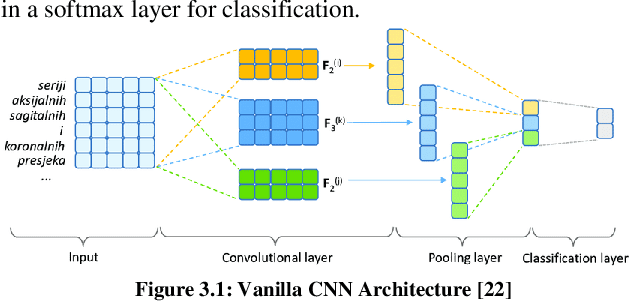
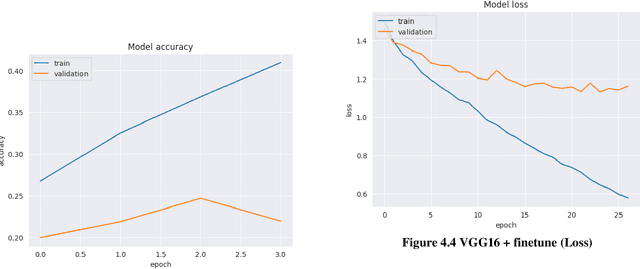
The proliferation of digital images and the advancements in deep learning have paved the way for innovative solutions in various domains, especially in the field of image classification. Our project presents an in-depth study and implementation of an image classification system specifically tailored to identify and classify images of Indian cities. Drawing from an extensive dataset, our model classifies images into five major Indian cities: Ahmedabad, Delhi, Kerala, Kolkata, and Mumbai to recognize the distinct features and characteristics of each city/state. To achieve high precision and recall rates, we adopted two approaches. The first, a vanilla Convolutional Neural Network (CNN) and then we explored the power of transfer learning by leveraging the VGG16 model. The vanilla CNN achieved commendable accuracy and the VGG16 model achieved a test accuracy of 63.6%. Evaluations highlighted the strengths and potential areas of improvement, positioning our model as not only competitive but also scalable for broader applications. With an emphasis on open-source ethos, our work aims to contribute to the community, encouraging further development and diverse applications. Our findings demonstrate the potential applications in tourism, urban planning, and even real-time location identification systems, among others.
Fast Sparse View Guided NeRF Update for Object Reconfigurations
Mar 16, 2024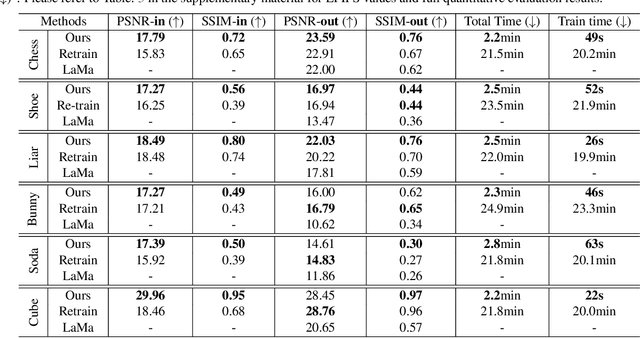
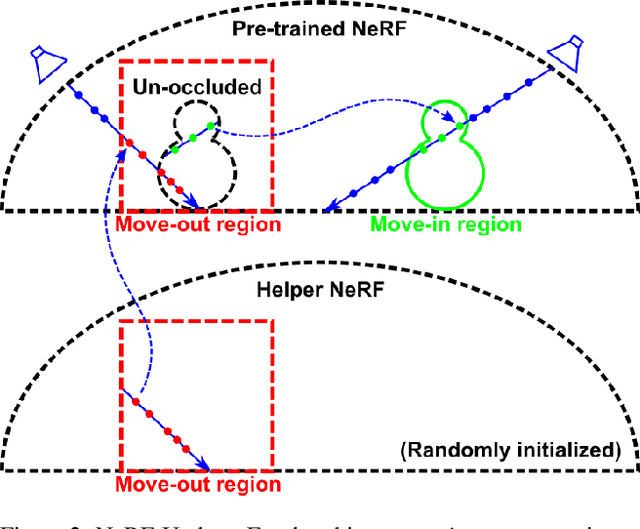
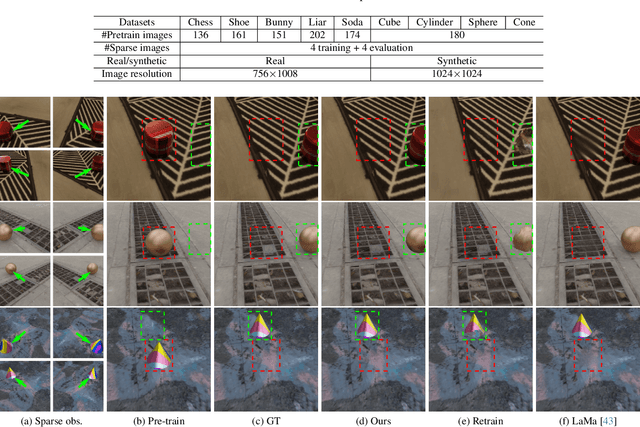
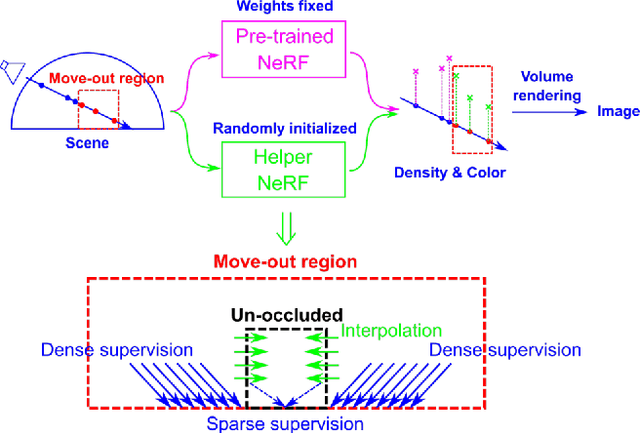
Neural Radiance Field (NeRF), as an implicit 3D scene representation, lacks inherent ability to accommodate changes made to the initial static scene. If objects are reconfigured, it is difficult to update the NeRF to reflect the new state of the scene without time-consuming data re-capturing and NeRF re-training. To address this limitation, we develop the first update method for NeRFs to physical changes. Our method takes only sparse new images (e.g. 4) of the altered scene as extra inputs and update the pre-trained NeRF in around 1 to 2 minutes. Particularly, we develop a pipeline to identify scene changes and update the NeRF accordingly. Our core idea is the use of a second helper NeRF to learn the local geometry and appearance changes, which sidesteps the optimization difficulties in direct NeRF fine-tuning. The interpolation power of the helper NeRF is the key to accurately reconstruct the un-occluded objects regions under sparse view supervision. Our method imposes no constraints on NeRF pre-training, and requires no extra user input or explicit semantic priors. It is an order of magnitude faster than re-training NeRF from scratch while maintaining on-par and even superior performance.
Tight Frames Generated By A Graph Short-Time Fourier Transform
Feb 24, 2024A graph short-time Fourier transform is defined using the eigenvectors of the graph Laplacian and a graph heat kernel as a window parametrized by a non-negative time parameter $t$. We show that the corresponding Gabor-like system forms a frame for $\mathbb{C}^d$ and give a description of the spectrum of the corresponding frame operator in terms of the graph heat kernel and the spectrum of the underlying graph Laplacian. For two classes of algebraic graphs, we prove the frame is tight and independent of the window parameter $t$.
A Novel Implicit Neural Representation for Volume Data
Mar 13, 2024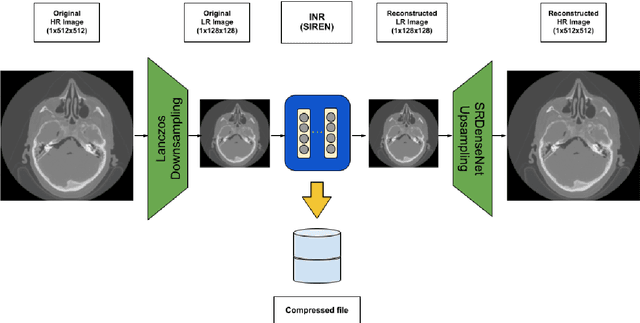
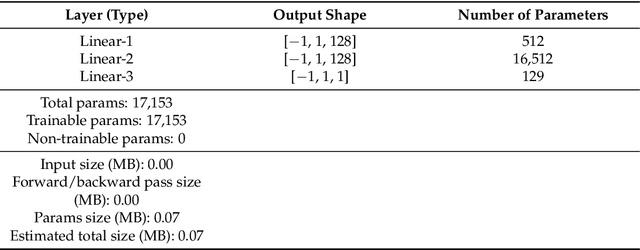
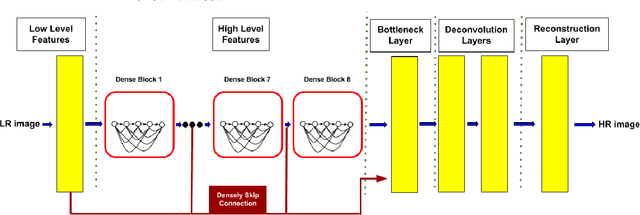
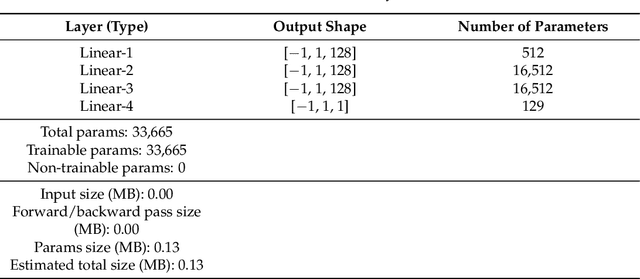
The storage of medical images is one of the challenges in the medical imaging field. There are variable works that use implicit neural representation (INR) to compress volumetric medical images. However, there is room to improve the compression rate for volumetric medical images. Most of the INR techniques need a huge amount of GPU memory and a long training time for high-quality medical volume rendering. In this paper, we present a novel implicit neural representation to compress volume data using our proposed architecture, that is, the Lanczos downsampling scheme, SIREN deep network, and SRDenseNet high-resolution scheme. Our architecture can effectively reduce training time, and gain a high compression rate while retaining the final rendering quality. Moreover, it can save GPU memory in comparison with the existing works. The experiments show that the quality of reconstructed images and training speed using our architecture is higher than current works which use the SIREN only. Besides, the GPU memory cost is evidently decreased
Effective Underwater Glider Path Planning in Dynamic 3D Environments Using Multi-Point Potential Fields
Mar 13, 2024
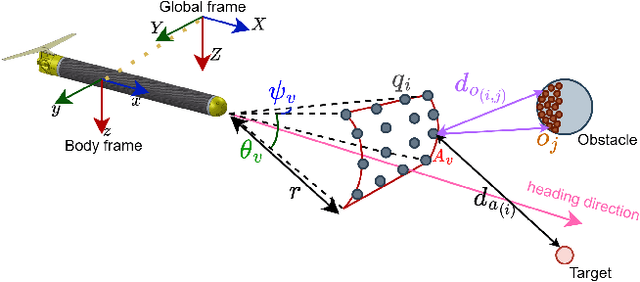
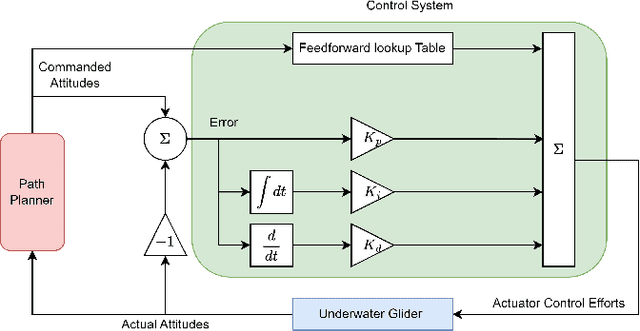
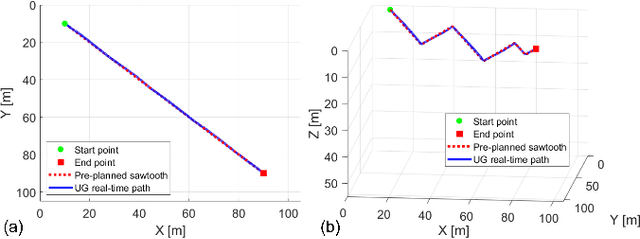
Underwater gliders (UGs) have emerged as highly effective unmanned vehicles for ocean exploration. However, their operation in dynamic and complex underwater environments necessitates robust path-planning strategies. Previous studies have primarily focused on global energy or time-efficient path planning in explored environments, overlooking challenges posed by unpredictable flow conditions and unknown obstacles in varying and dynamic areas like fjords and near-harbor waters. This paper introduces and improves a real-time path planning method, Multi-Point Potential Field (MPPF), tailored for UGs operating in 3D space as they are constrained by buoyancy propulsion and internal actuation. The proposed MPPF method addresses obstacles, flow fields, and local minima, enhancing the efficiency and robustness of UG path planning. A low-cost prototype, the Research Oriented Underwater Glider for Hands-on Investigative Engineering (ROUGHIE), is utilized for validation. Through case studies and simulations, the efficacy of the enhanced MPPF method is demonstrated, highlighting its potential for real-world applications in underwater exploration.
Leveraging Compressed Frame Sizes For Ultra-Fast Video Classification
Mar 13, 2024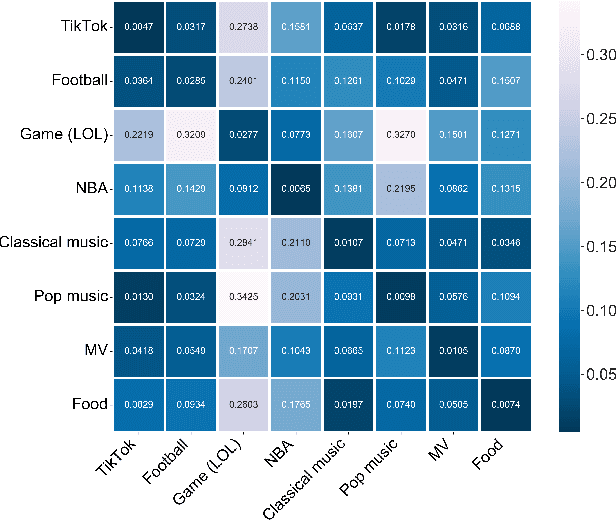
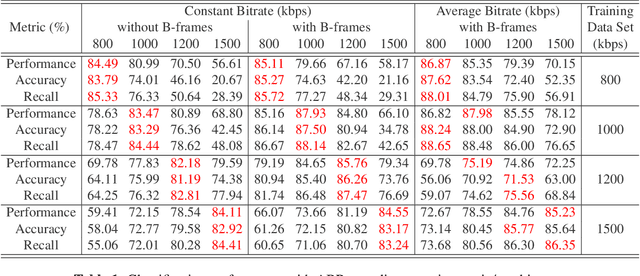
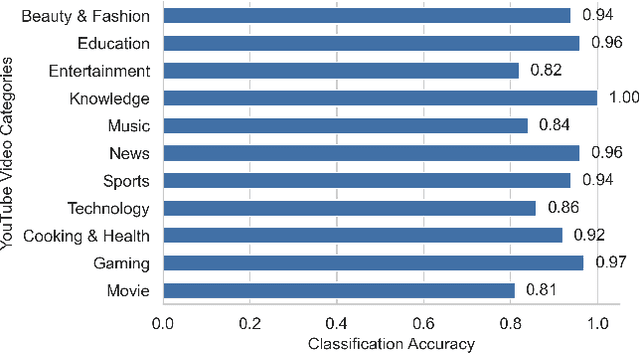
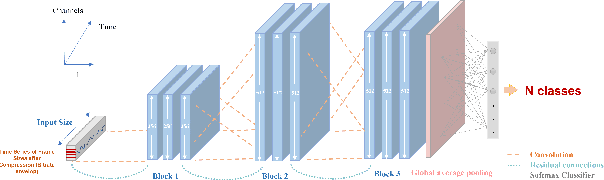
Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially when an immense volume of video content is being constantly generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream decoding. To validate our approach, we built a comprehensive data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our evaluations indicate precision, accuracy, and recall rates consistently above 80%, many exceeding 90%, and some reaching 99%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by seven orders of magnitude.
Robust Sparse Estimation for Gaussians with Optimal Error under Huber Contamination
Mar 15, 2024We study Gaussian sparse estimation tasks in Huber's contamination model with a focus on mean estimation, PCA, and linear regression. For each of these tasks, we give the first sample and computationally efficient robust estimators with optimal error guarantees, within constant factors. All prior efficient algorithms for these tasks incur quantitatively suboptimal error. Concretely, for Gaussian robust $k$-sparse mean estimation on $\mathbb{R}^d$ with corruption rate $\epsilon>0$, our algorithm has sample complexity $(k^2/\epsilon^2)\mathrm{polylog}(d/\epsilon)$, runs in sample polynomial time, and approximates the target mean within $\ell_2$-error $O(\epsilon)$. Previous efficient algorithms inherently incur error $\Omega(\epsilon \sqrt{\log(1/\epsilon)})$. At the technical level, we develop a novel multidimensional filtering method in the sparse regime that may find other applications.