 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic location detection based on deep learning
Mar 16, 2024The proliferation of digital images and the advancements in deep learning have paved the way for innovative solutions in various domains, especially in the field of image classification. Our project presents an in-depth study and implementation of an image classification system specifically tailored to identify and classify images of Indian cities. Drawing from an extensive dataset, our model classifies images into five major Indian cities: Ahmedabad, Delhi, Kerala, Kolkata, and Mumbai to recognize the distinct features and characteristics of each city/state. To achieve high precision and recall rates, we adopted two approaches. The first, a vanilla Convolutional Neural Network (CNN) and then we explored the power of transfer learning by leveraging the VGG16 model. The vanilla CNN achieved commendable accuracy and the VGG16 model achieved a test accuracy of 63.6%. Evaluations highlighted the strengths and potential areas of improvement, positioning our model as not only competitive but also scalable for broader applications. With an emphasis on open-source ethos, our work aims to contribute to the community, encouraging further development and diverse applications. Our findings demonstrate the potential applications in tourism, urban planning, and even real-time location identification systems, among others.
Depression Scale Recognition from Audio, Visual and Text Analysis
Sep 18, 2017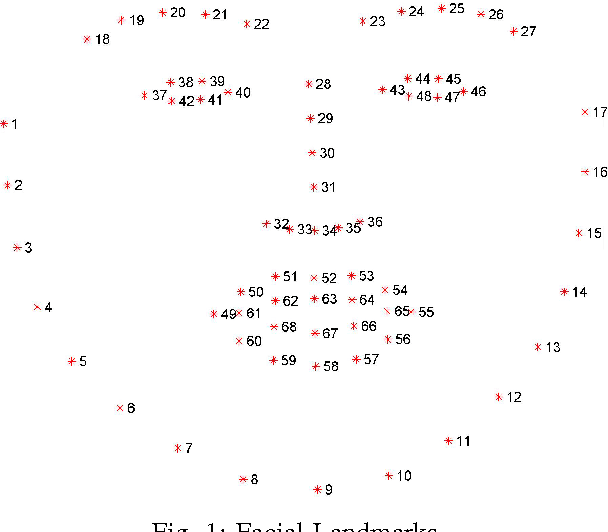
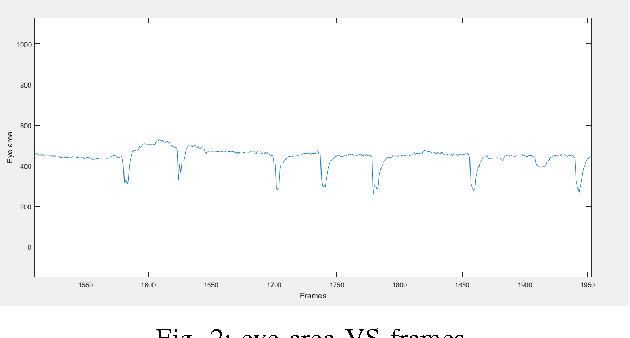
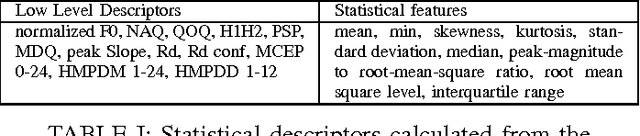
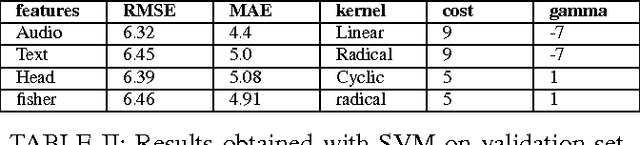
Depression is a major mental health disorder that is rapidly affecting lives worldwide. Depression not only impacts emotional but also physical and psychological state of the person. Its symptoms include lack of interest in daily activities, feeling low, anxiety, frustration, loss of weight and even feeling of self-hatred. This report describes work done by us for Audio Visual Emotion Challenge (AVEC) 2017 during our second year BTech summer internship. With the increase in demand to detect depression automatically with the help of machine learning algorithms, we present our multimodal feature extraction and decision level fusion approach for the same. Features are extracted by processing on the provided Distress Analysis Interview Corpus-Wizard of Oz (DAIC-WOZ) database. Gaussian Mixture Model (GMM) clustering and Fisher vector approach were applied on the visual data; statistical descriptors on gaze, pose; low level audio features and head pose and text features were also extracted. Classification is done on fused as well as independent features using Support Vector Machine (SVM) and neural networks. The results obtained were able to cross the provided baseline on validation data set by 17% on audio features and 24.5% on video features.