 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discrepancies among Pre-trained Deep Neural Networks: A New Threat to Model Zoo Reliability
Mar 05, 2023
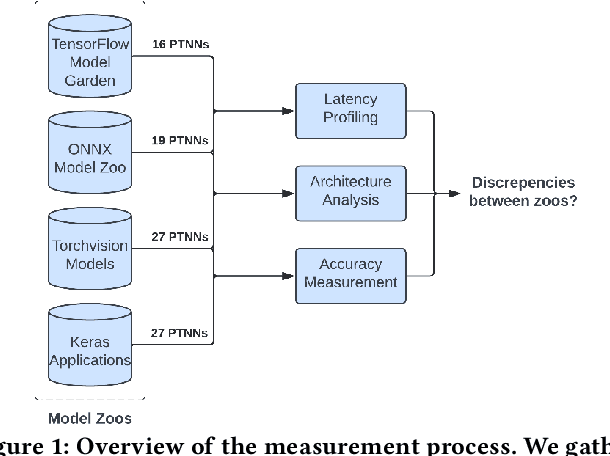

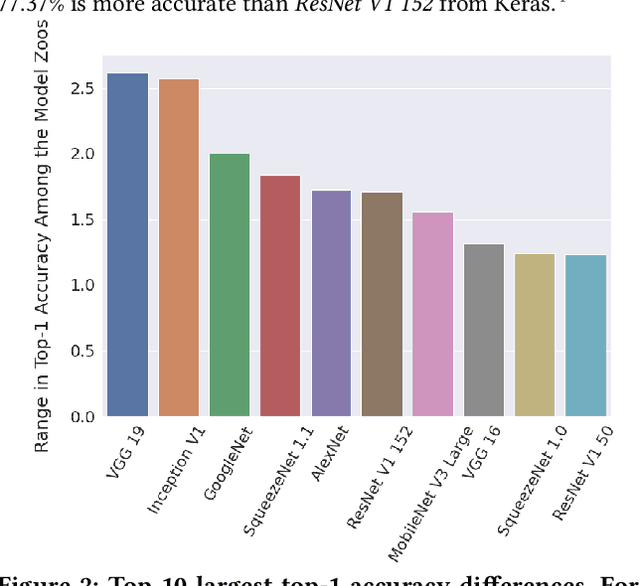
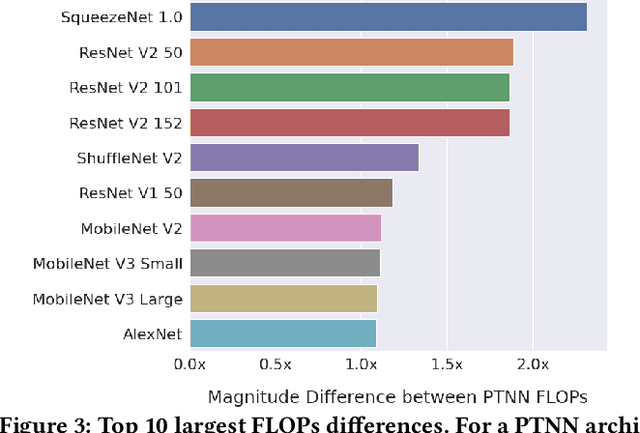
Training deep neural networks (DNNs) takes signifcant time and resources. A practice for expedited deployment is to use pre-trained deep neural networks (PTNNs), often from model zoos -- collections of PTNNs; yet, the reliability of model zoos remains unexamined. In the absence of an industry standard for the implementation and performance of PTNNs, engineers cannot confidently incorporate them into production systems. As a first step, discovering potential discrepancies between PTNNs across model zoos would reveal a threat to model zoo reliability. Prior works indicated existing variances in deep learning systems in terms of accuracy. However, broader measures of reliability for PTNNs from model zoos are unexplored. This work measures notable discrepancies between accuracy, latency, and architecture of 36 PTNNs across four model zoos. Among the top 10 discrepancies, we find differences of 1.23%-2.62% in accuracy and 9%-131% in latency. We also fnd mismatches in architecture for well-known DNN architectures (e.g., ResNet and AlexNet). Our findings call for future works on empirical validation, automated tools for measurement, and best practices for implementation.
Few-shots Portrait Generation with Style Enhancement and Identity Preservation
Mar 01, 2023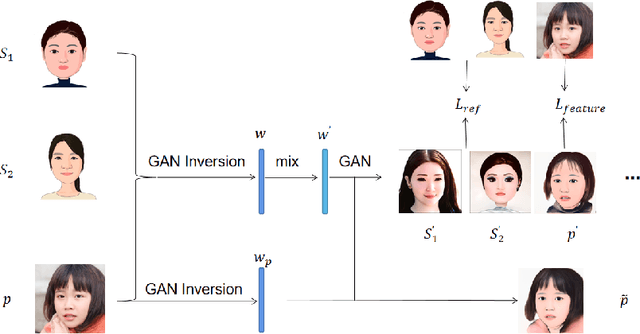


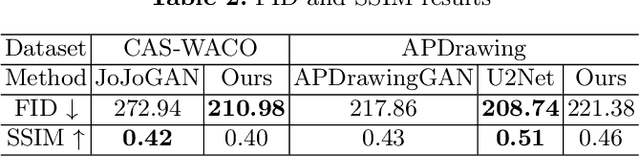
Nowadays, the wide application of virtual digital human promotes the comprehensive prosperity and development of digital culture supported by digital economy. The personalized portrait automatically generated by AI technology needs both the natural artistic style and human sentiment. In this paper, we propose a novel StyleIdentityGAN model, which can ensure the identity and artistry of the generated portrait at the same time. Specifically, the style-enhanced module focuses on artistic style features decoupling and transferring to improve the artistry of generated virtual face images. Meanwhile, the identity-enhanced module preserves the significant features extracted from the input photo. Furthermore, the proposed method requires a small number of reference style data. Experiments demonstrate the superiority of StyleIdentityGAN over state-of-art methods in artistry and identity effects, with comparisons done qualitatively, quantitatively and through a perceptual user study. Code has been released on Github3.
Auxiliary MCMC and particle Gibbs samplers for parallelisable inference in latent dynamical systems
Mar 01, 2023
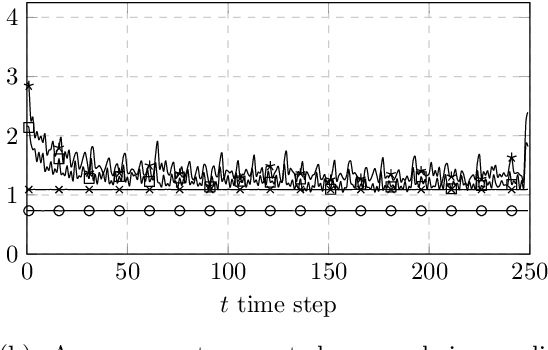
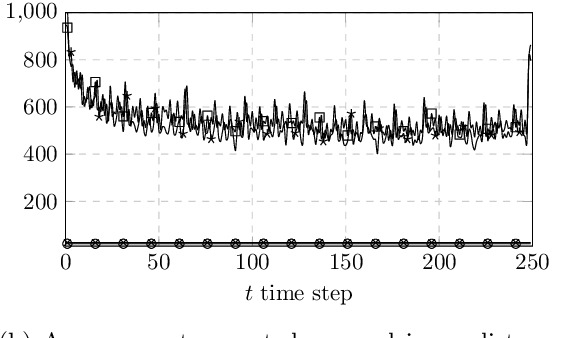
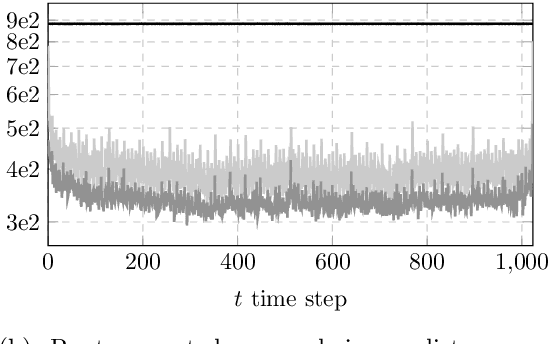
We introduce two new classes of exact Markov chain Monte Carlo (MCMC) samplers for inference in latent dynamical models. The first one, which we coin auxiliary Kalman samplers, relies on finding a linear Gaussian state-space model approximation around the running trajectory corresponding to the state of the Markov chain. The second, that we name auxiliary particle Gibbs samplers corresponds to deriving good local proposals in an auxiliary Feynman--Kac model for use in particle Gibbs. Both samplers are controlled by augmenting the target distribution with auxiliary observations, resulting in an efficient Gibbs sampling routine. We discuss the relative statistical and computational performance of the samplers introduced, and show how to parallelise the auxiliary samplers along the time dimension. We illustrate the respective benefits and drawbacks of the resulting algorithms on classical examples from the particle filtering literature.
Q-Diffusion: Quantizing Diffusion Models
Feb 08, 2023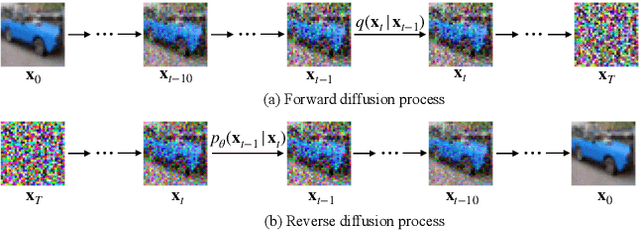

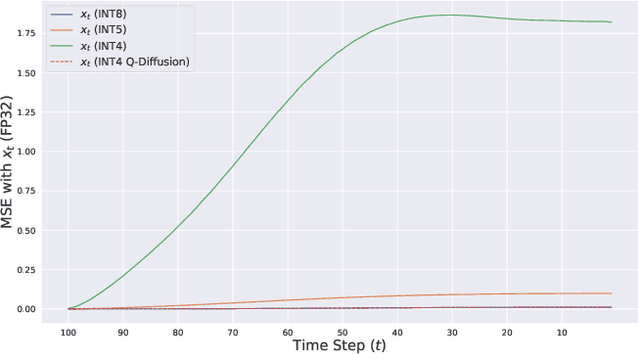
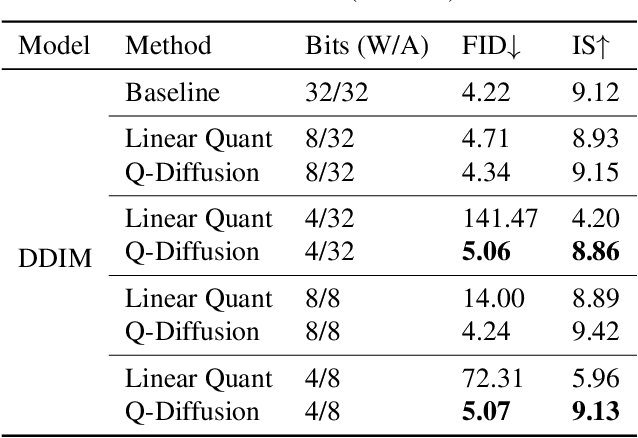
Diffusion models have recently achieved great success in synthesizing diverse and high-fidelity images. However, sampling speed and memory constraints remain a major barrier to the practical adoption of diffusion models as the generation process for these models can be slow due to the need for iterative noise estimation using complex neural networks. We propose a solution to this problem by compressing the noise estimation network to accelerate the generation process using post-training quantization (PTQ). While existing PTQ approaches have not been able to effectively deal with the changing output distributions of noise estimation networks in diffusion models over multiple time steps, we are able to formulate a PTQ method that is specifically designed to handle the unique multi-timestep structure of diffusion models with a data calibration scheme using data sampled from different time steps. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a FID change of at most 1.88. Our approach can also be applied to text-guided image generation, and for the first time we can run stable diffusion in 4-bit weights without losing much perceptual quality, as shown in Figure 5 and Figure 9.
Fast Linear Model Trees by PILOT
Feb 08, 2023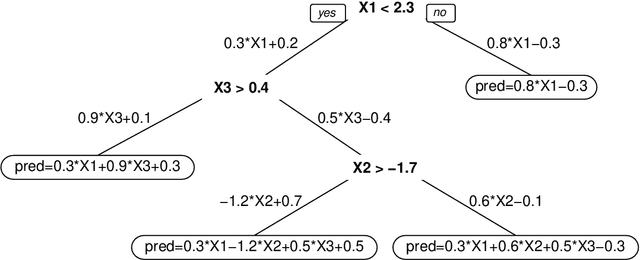
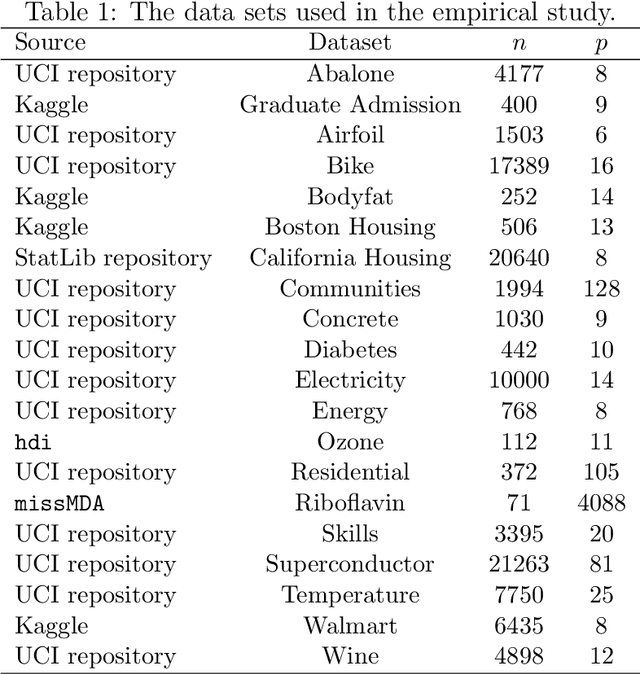
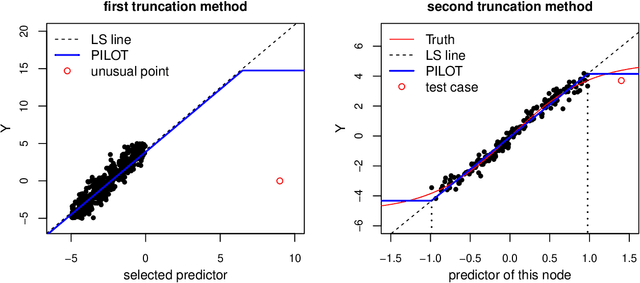
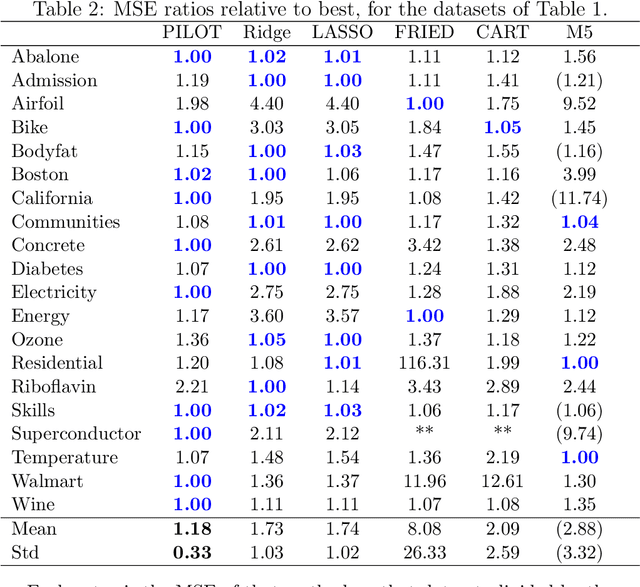
Linear model trees are regression trees that incorporate linear models in the leaf nodes. This preserves the intuitive interpretation of decision trees and at the same time enables them to better capture linear relationships, which is hard for standard decision trees. But most existing methods for fitting linear model trees are time consuming and therefore not scalable to large data sets. In addition, they are more prone to overfitting and extrapolation issues than standard regression trees. In this paper we introduce PILOT, a new algorithm for linear model trees that is fast, regularized, stable and interpretable. PILOT trains in a greedy fashion like classic regression trees, but incorporates an $L^2$ boosting approach and a model selection rule for fitting linear models in the nodes. The abbreviation PILOT stands for $PI$ecewise $L$inear $O$rganic $T$ree, where `organic' refers to the fact that no pruning is carried out. PILOT has the same low time and space complexity as CART without its pruning. An empirical study indicates that PILOT tends to outperform standard decision trees and other linear model trees on a variety of data sets. Moreover, we prove its consistency in an additive model setting under weak assumptions. When the data is generated by a linear model, the convergence rate is polynomial.
Controlling mean exit time of stochastic dynamical systems based on quasipotential and machine learning
Sep 27, 2022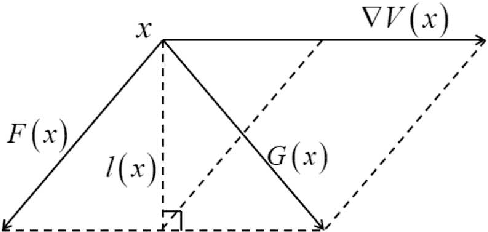
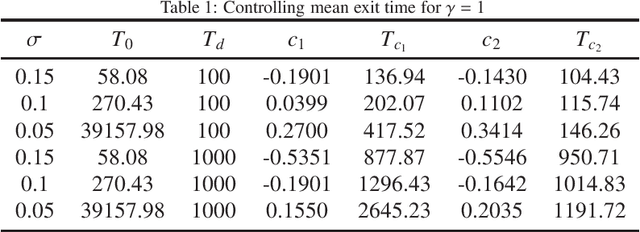
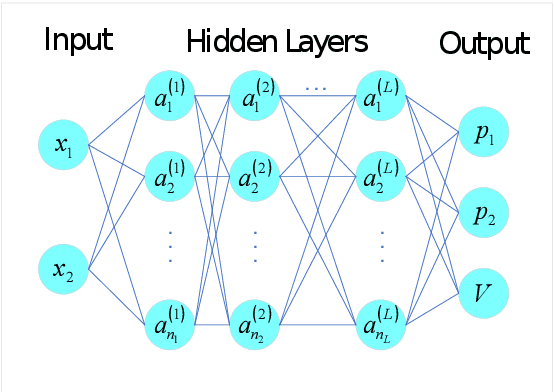
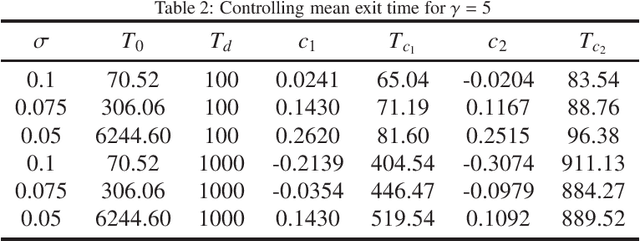
The mean exit time escaping basin of attraction in the presence of white noise is of practical importance in various scientific fields. In this work, we propose a strategy to control mean exit time of general stochastic dynamical systems to achieve a desired value based on the quasipotential concept and machine learning. Specifically, we develop a neural network architecture to compute the global quasipotential function. Then we design a systematic iterated numerical algorithm to calculate the controller for a given mean exit time. Moreover, we identify the most probable path between metastable attractors with help of the effective Hamilton-Jacobi scheme and the trained neural network. Numerical experiments demonstrate that our control strategy is effective and sufficiently accurate.
Physics-informed neural networks for solving forward and inverse problems in complex beam systems
Mar 02, 2023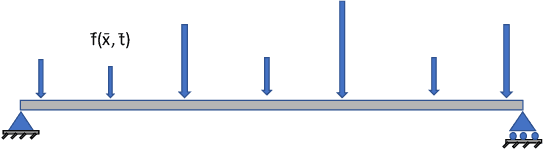
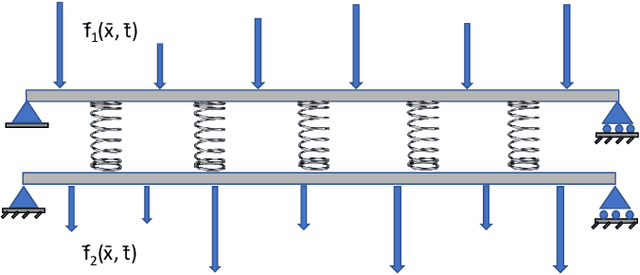
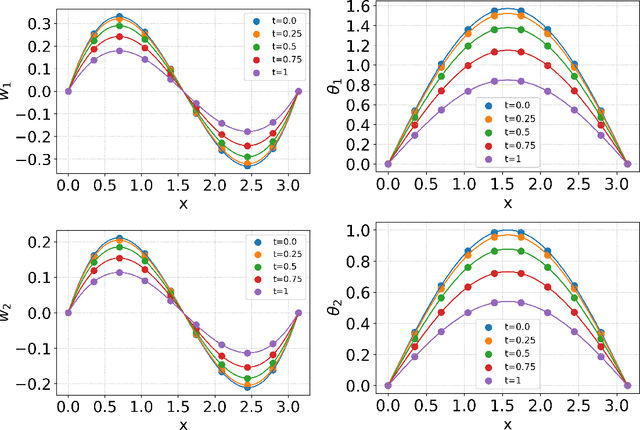
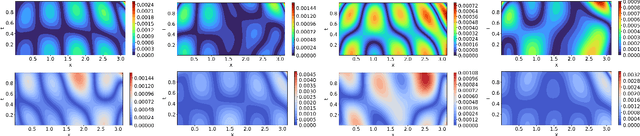
This paper proposes a new framework using physics-informed neural networks (PINNs) to simulate complex structural systems that consist of single and double beams based on Euler-Bernoulli and Timoshenko theory, where the double beams are connected with a Winkler foundation. In particular, forward and inverse problems for the Euler-Bernoulli and Timoshenko partial differential equations (PDEs) are solved using nondimensional equations with the physics-informed loss function. Higher-order complex beam PDEs are efficiently solved for forward problems to compute the transverse displacements and cross-sectional rotations with less than 1e-3 percent error. Furthermore, inverse problems are robustly solved to determine the unknown dimensionless model parameters and applied force in the entire space-time domain, even in the case of noisy data. The results suggest that PINNs are a promising strategy for solving problems in engineering structures and machines involving beam systems.
Effective Visualization and Analysis of Recommender Systems
Mar 02, 2023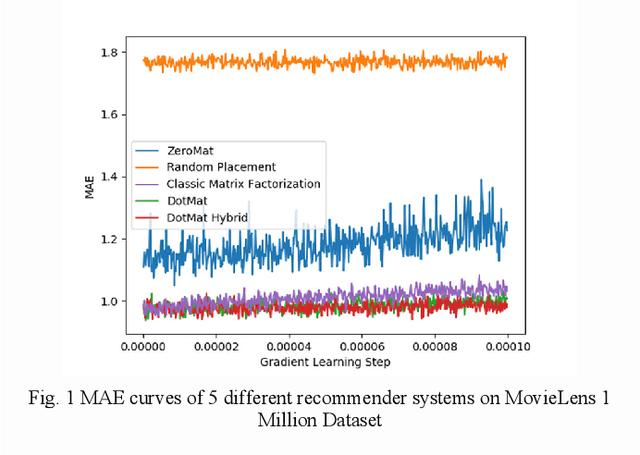
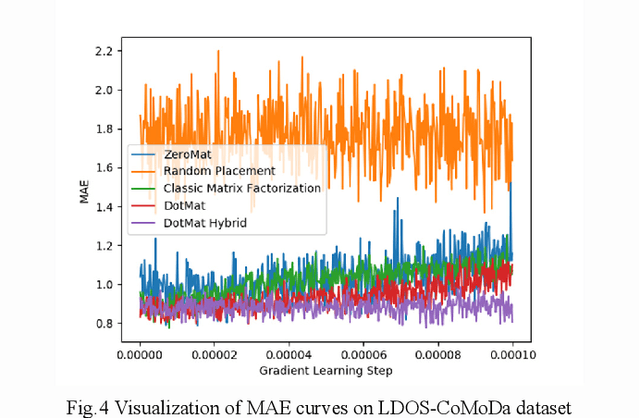
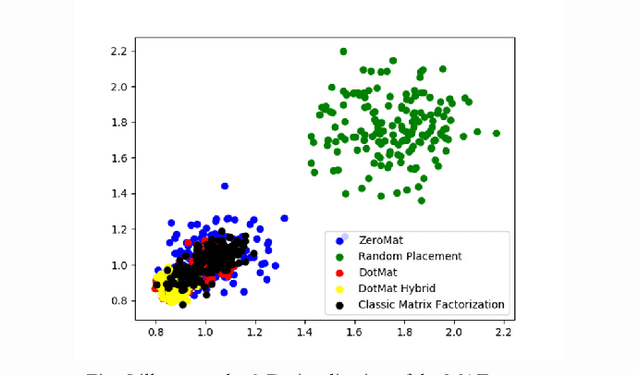
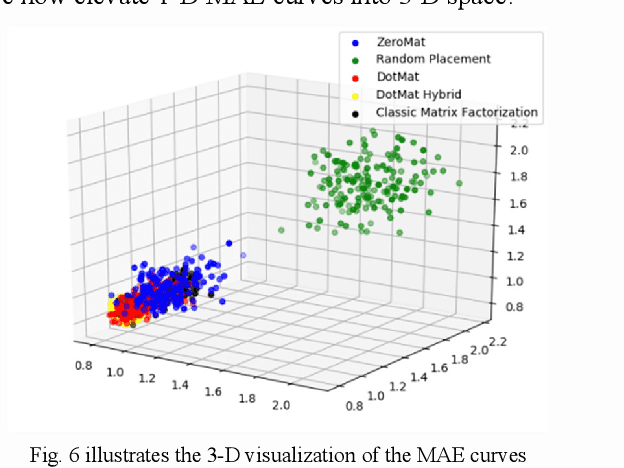
Recommender system exists everywhere in the business world. From Goodreads to TikTok, customers of internet products become more addicted to the products thanks to the technology. Industrial practitioners focus on increasing the technical accuracy of recommender systems while at same time balancing other factors such as diversity and serendipity. In spite of the length of the research and development history of recommender systems, there has been little discussion on how to take advantage of visualization techniques to facilitate the algorithmic design of the technology. In this paper, we use a series of data analysis and visualization techniques such as Takens Embedding, Determinantal Point Process and Social Network Analysis to help people develop effective recommender systems by predicting intermediate computational cost and output performance. Our work is pioneering in the field, as to our limited knowledge, there have been few publications (if any) on visualization of recommender systems.
Distilling Multi-Level X-vector Knowledge for Small-footprint Speaker Verification
Mar 02, 2023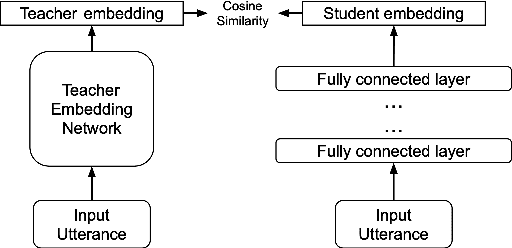
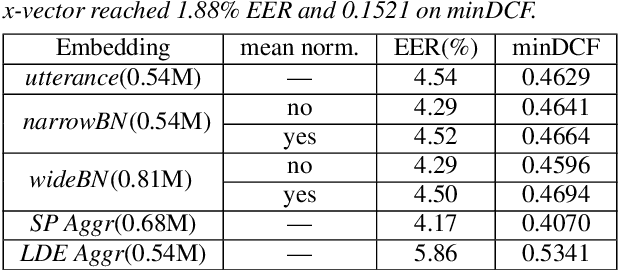
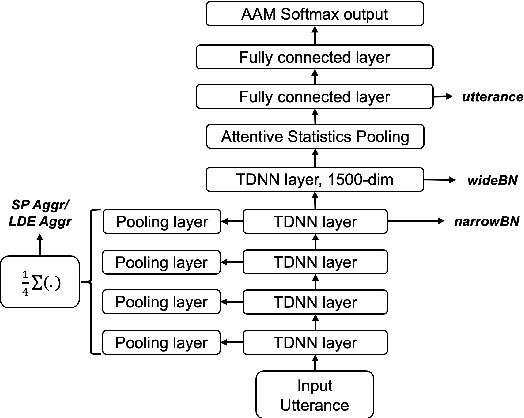

Deep speaker models yield low error rates in speaker verification. Nonetheless, the high performance tends to be exchanged for model size and computation time, making these models challenging to run under limited conditions. We focus on small-footprint deep speaker embedding extraction, leveraging knowledge distillation. While prior work on this topic has addressed speaker embedding extraction at the utterance level, we propose to combine embeddings from various levels of the x-vector model (teacher network) to train small-footprint student networks. Results indicate the usefulness of frame-level information, with the student models being 85%-91% smaller than their teacher, depending on the size of the teacher embeddings. Concatenation of teacher embeddings results in student networks that reach comparable performance along with the teacher while utilizing a 75% relative size reduction from the teacher. The findings and analogies are furthered to other x-vector variants.
Parameter Sharing with Network Pruning for Scalable Multi-Agent Deep Reinforcement Learning
Mar 02, 2023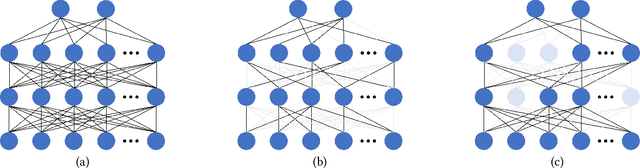
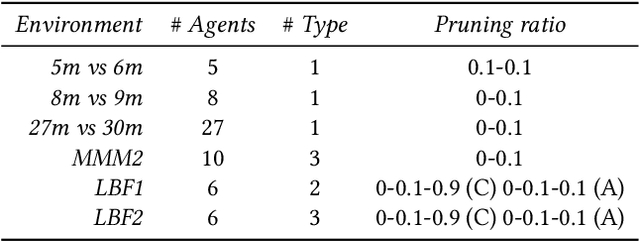
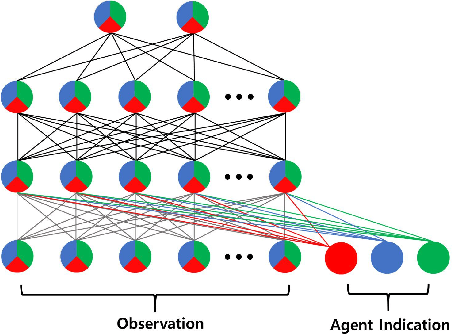
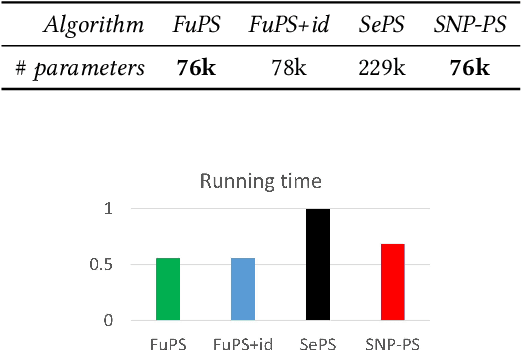
Handling the problem of scalability is one of the essential issues for multi-agent reinforcement learning (MARL) algorithms to be applied to real-world problems typically involving massively many agents. For this, parameter sharing across multiple agents has widely been used since it reduces the training time by decreasing the number of parameters and increasing the sample efficiency. However, using the same parameters across agents limits the representational capacity of the joint policy and consequently, the performance can be degraded in multi-agent tasks that require different behaviors for different agents. In this paper, we propose a simple method that adopts structured pruning for a deep neural network to increase the representational capacity of the joint policy without introducing additional parameters. We evaluate the proposed method on several benchmark tasks, and numerical results show that the proposed method significantly outperforms other parameter-sharing methods.