 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BIRD-PCC: Bi-directional Range Image-based Deep LiDAR Point Cloud Compression
Mar 09, 2023
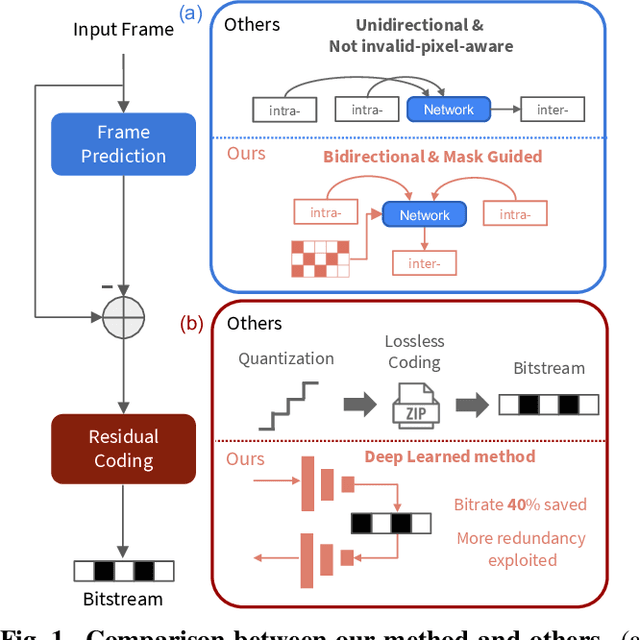
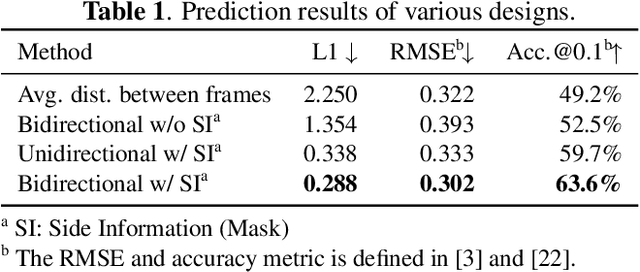
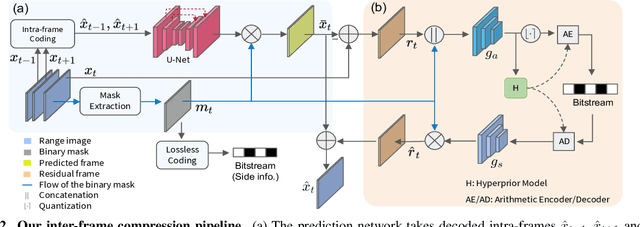
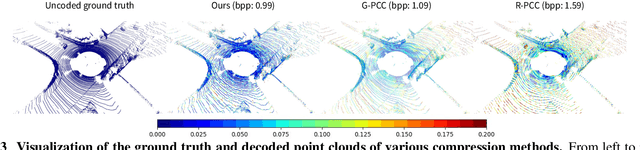
The large amount of data collected by LiDAR sensors brings the issue of LiDAR point cloud compression (PCC). Previous works on LiDAR PCC have used range image representations and followed the predictive coding paradigm to create a basic prototype of a coding framework. However, their prediction methods give an inaccurate result due to the negligence of invalid pixels in range images and the omission of future frames in the time step. Moreover, their handcrafted design of residual coding methods could not fully exploit spatial redundancy. To remedy this, we propose a coding framework BIRD-PCC. Our prediction module is aware of the coordinates of invalid pixels in range images and takes a bidirectional scheme. Also, we introduce a deep-learned residual coding module that can further exploit spatial redundancy within a residual frame. Experiments conducted on SemanticKITTI and KITTI-360 datasets show that BIRD-PCC outperforms other methods in most bitrate conditions and generalizes well to unseen environments.
Active Learning Based Domain Adaptation for Tissue Segmentation of Histopathological Images
Mar 09, 2023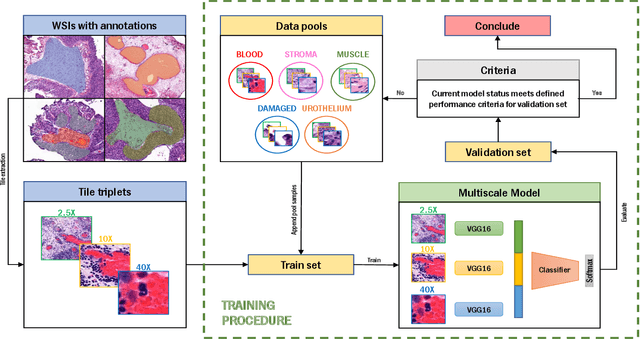
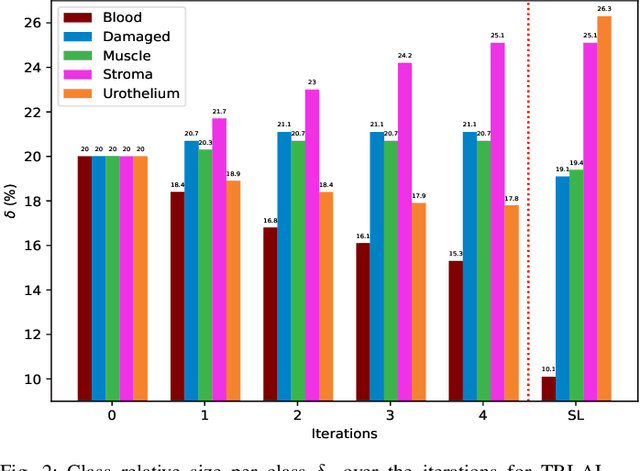
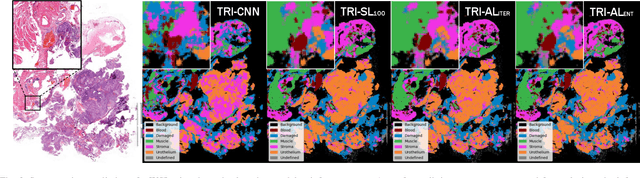
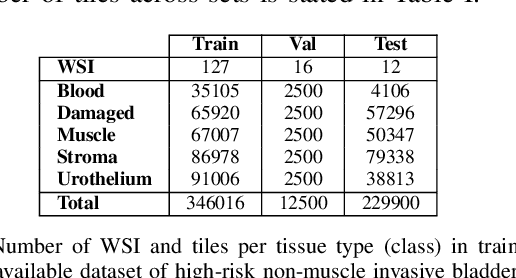
Accurate segmentation of tissue in histopathological images can be very beneficial for defining regions of interest (ROI) for streamline of diagnostic and prognostic tasks. Still, adapting to different domains is essential for histopathology image analysis, as the visual characteristics of tissues can vary significantly across datasets. Yet, acquiring sufficient annotated data in the medical domain is cumbersome and time-consuming. The labeling effort can be significantly reduced by leveraging active learning, which enables the selective annotation of the most informative samples. Our proposed method allows for fine-tuning a pre-trained deep neural network using a small set of labeled data from the target domain, while also actively selecting the most informative samples to label next. We demonstrate that our approach performs with significantly fewer labeled samples compared to traditional supervised learning approaches for similar F1-scores, using barely a 59\% of the training set. We also investigate the distribution of class balance to establish annotation guidelines.
Taming Local Effects in Graph-based Spatiotemporal Forecasting
Feb 08, 2023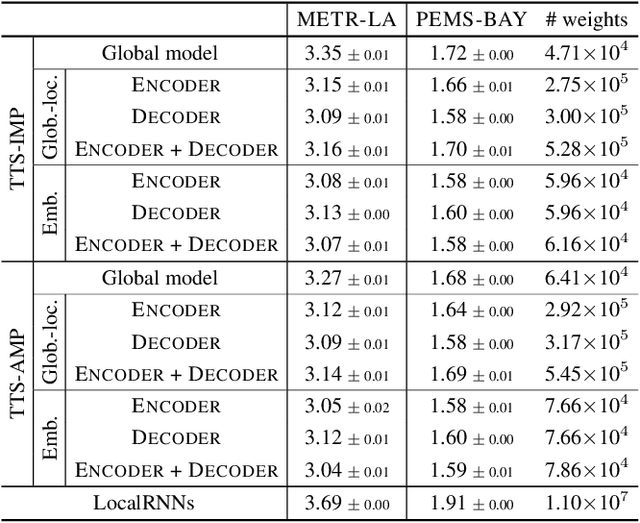
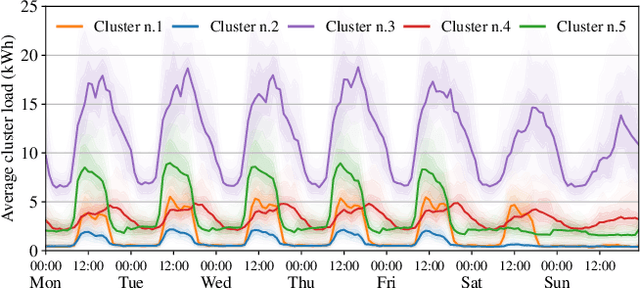
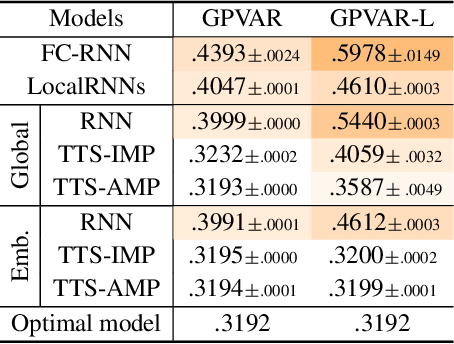
Spatiotemporal graph neural networks have shown to be effective in time series forecasting applications, achieving better performance than standard univariate predictors in several settings. These architectures take advantage of a graph structure and relational inductive biases to learn a single (global) inductive model to predict any number of the input time series, each associated with a graph node. Despite the gain achieved in computational and data efficiency w.r.t. fitting a set of local models, relying on a single global model can be a limitation whenever some of the time series are generated by a different spatiotemporal stochastic process. The main objective of this paper is to understand the interplay between globality and locality in graph-based spatiotemporal forecasting, while contextually proposing a methodological framework to rationalize the practice of including trainable node embeddings in such architectures. We ascribe to trainable node embeddings the role of amortizing the learning of specialized components. Moreover, embeddings allow for 1) effectively combining the advantages of shared message-passing layers with node-specific parameters and 2) efficiently transferring the learned model to new node sets. Supported by strong empirical evidence, we provide insights and guidelines for specializing graph-based models to the dynamics of each time series and show how this aspect plays a crucial role in obtaining accurate predictions.
SGD learning on neural networks: leap complexity and saddle-to-saddle dynamics
Feb 21, 2023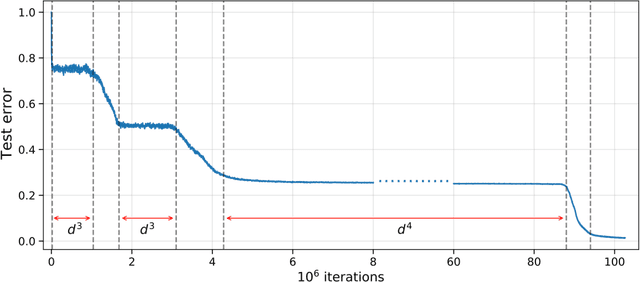
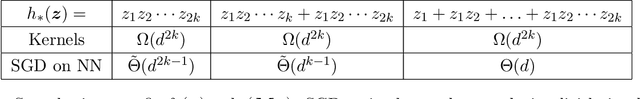
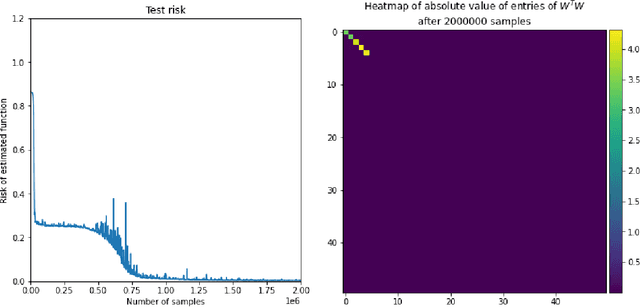
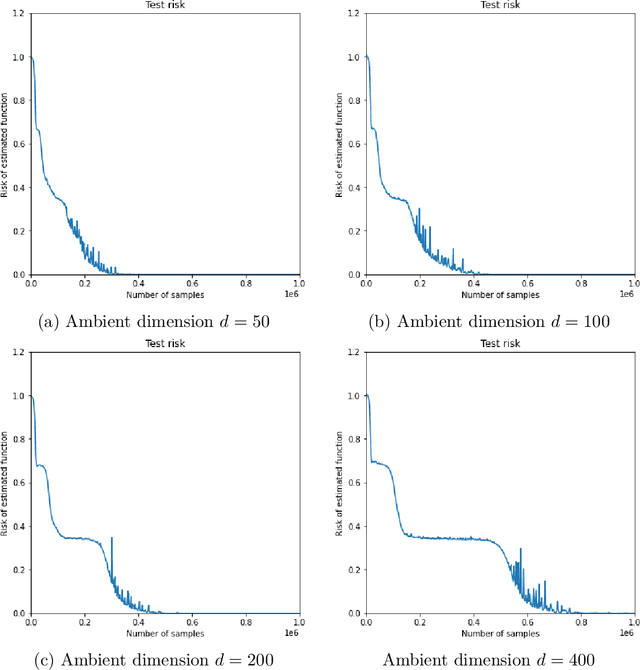
We investigate the time complexity of SGD learning on fully-connected neural networks with isotropic data. We put forward a complexity measure -- the leap -- which measures how "hierarchical" target functions are. For $d$-dimensional uniform Boolean or isotropic Gaussian data, our main conjecture states that the time complexity to learn a function $f$ with low-dimensional support is $\tilde\Theta (d^{\max(\mathrm{Leap}(f),2)})$. We prove a version of this conjecture for a class of functions on Gaussian isotropic data and 2-layer neural networks, under additional technical assumptions on how SGD is run. We show that the training sequentially learns the function support with a saddle-to-saddle dynamic. Our result departs from [Abbe et al. 2022] by going beyond leap 1 (merged-staircase functions), and by going beyond the mean-field and gradient flow approximations that prohibit the full complexity control obtained here. Finally, we note that this gives an SGD complexity for the full training trajectory that matches that of Correlational Statistical Query (CSQ) lower-bounds.
DeepAxe: A Framework for Exploration of Approximation and Reliability Trade-offs in DNN Accelerators
Mar 14, 2023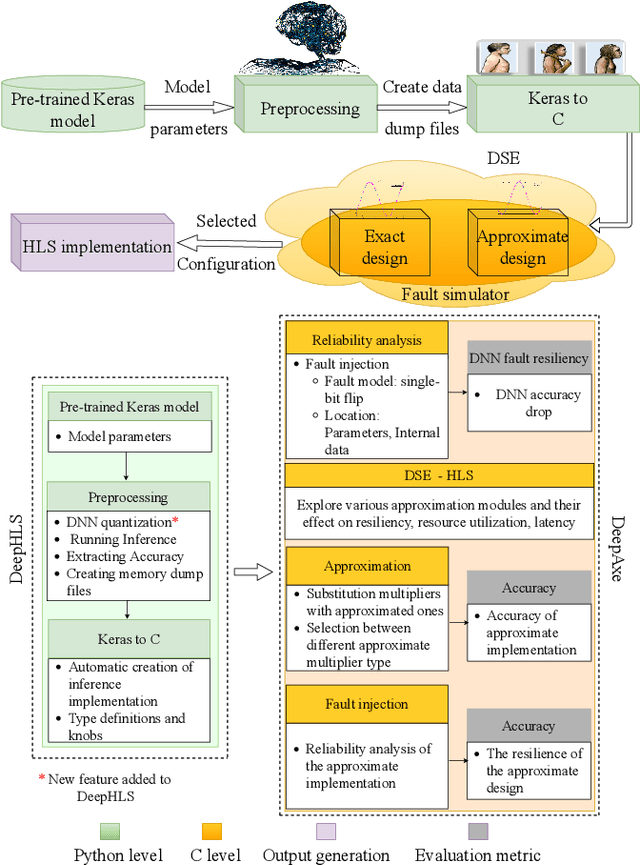
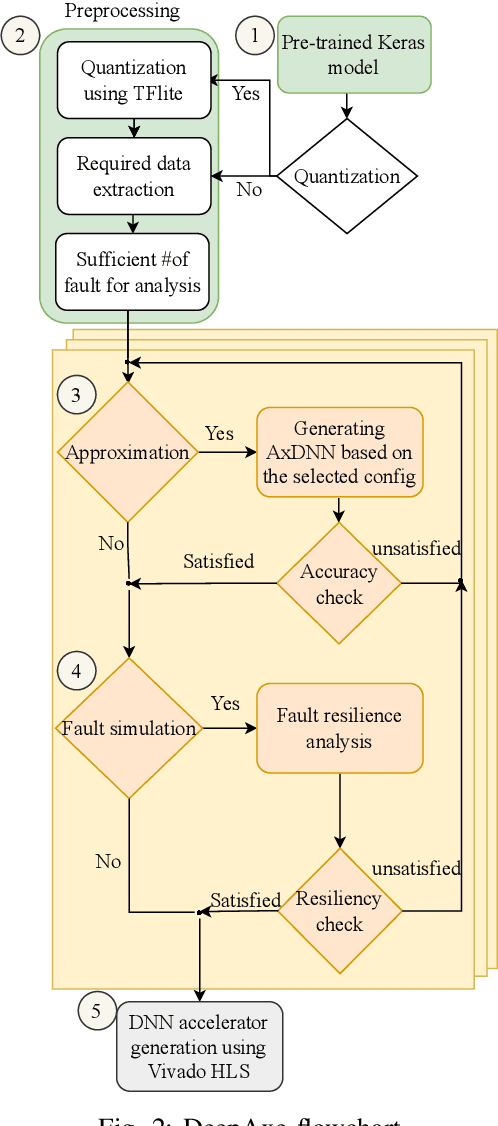
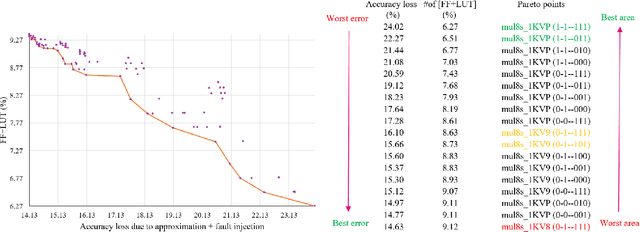
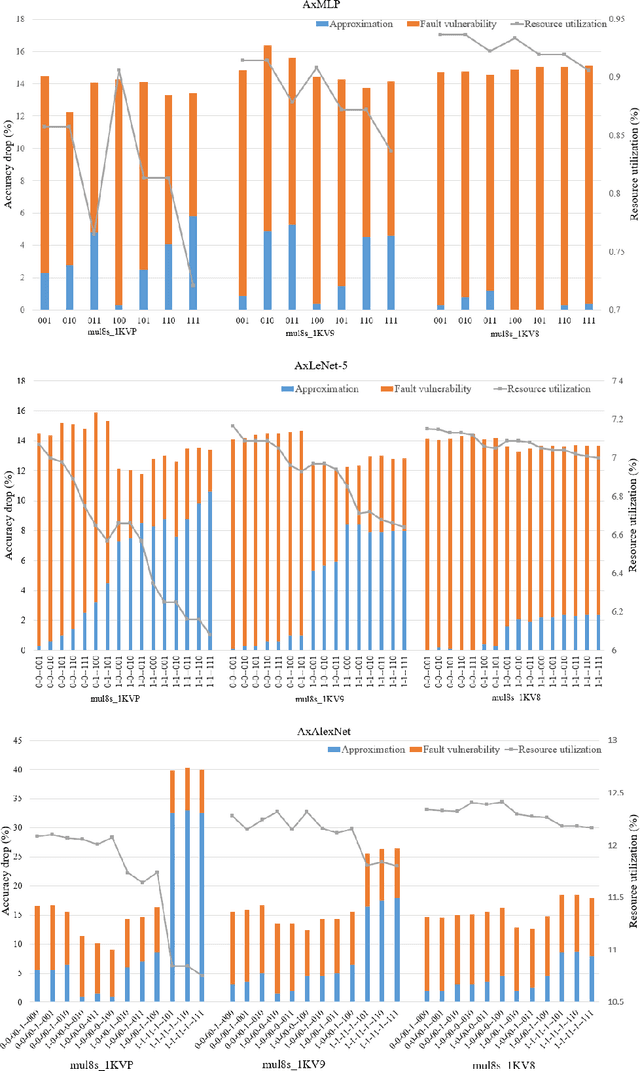
While the role of Deep Neural Networks (DNNs) in a wide range of safety-critical applications is expanding, emerging DNNs experience massive growth in terms of computation power. It raises the necessity of improving the reliability of DNN accelerators yet reducing the computational burden on the hardware platforms, i.e. reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators. Therefore, the trade-off between hardware performance, i.e. area, power and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis. In this paper, we propose a framework DeepAxe for design space exploration for FPGA-based implementation of DNNs by considering the trilateral impact of applying functional approximation on accuracy, reliability and hardware performance. The framework enables selective approximation of reliability-critical DNNs, providing a set of Pareto-optimal DNN implementation design space points for the target resource utilization requirements. The design flow starts with a pre-trained network in Keras, uses an innovative high-level synthesis environment DeepHLS and results in a set of Pareto-optimal design space points as a guide for the designer. The framework is demonstrated in a case study of custom and state-of-the-art DNNs and datasets.
Generation-Guided Multi-Level Unified Network for Video Grounding
Mar 14, 2023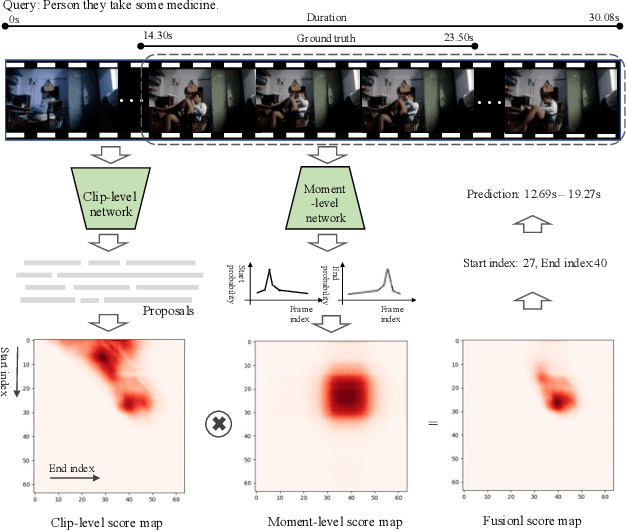
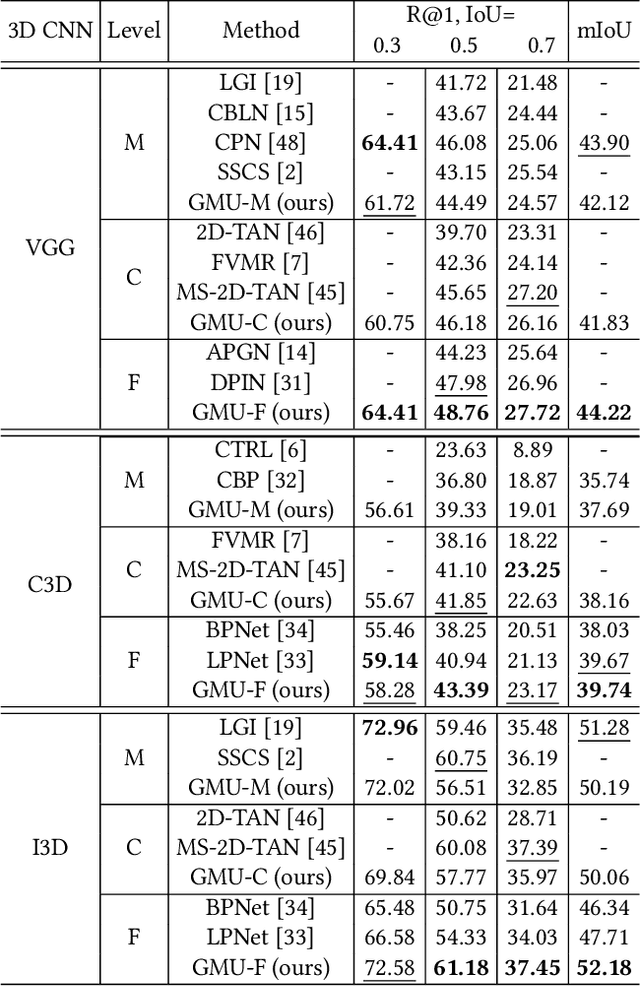

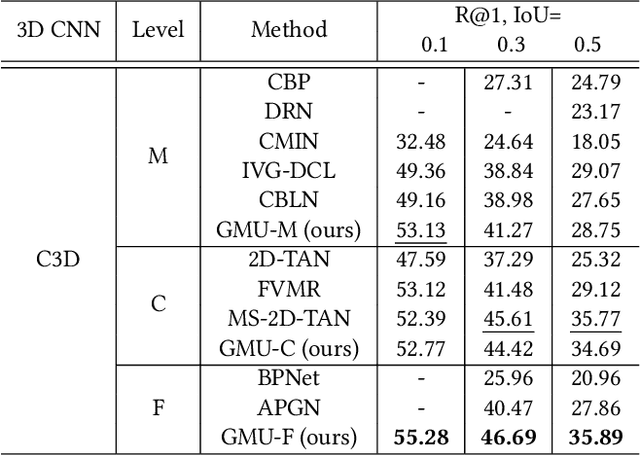
Video grounding aims to locate the timestamps best matching the query description within an untrimmed video. Prevalent methods can be divided into moment-level and clip-level frameworks. Moment-level approaches directly predict the probability of each transient moment to be the boundary in a global perspective, and they usually perform better in coarse grounding. On the other hand, clip-level ones aggregate the moments in different time windows into proposals and then deduce the most similar one, leading to its advantage in fine-grained grounding. In this paper, we propose a multi-level unified framework to enhance performance by leveraging the merits of both moment-level and clip-level methods. Moreover, a novel generation-guided paradigm in both levels is adopted. It introduces a multi-modal generator to produce the implicit boundary feature and clip feature, later regarded as queries to calculate the boundary scores by a discriminator. The generation-guided solution enhances video grounding from a two-unique-modals' match task to a cross-modal attention task, which steps out of the previous framework and obtains notable gains. The proposed Generation-guided Multi-level Unified network (GMU) surpasses previous methods and reaches State-Of-The-Art on various benchmarks with disparate features, e.g., Charades-STA, ActivityNet captions.
On the Connection between Concept Drift and Uncertainty in Industrial Artificial Intelligence
Mar 14, 2023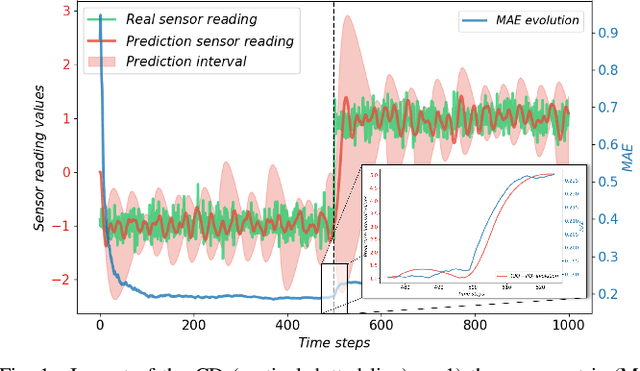
AI-based digital twins are at the leading edge of the Industry 4.0 revolution, which are technologically empowered by the Internet of Things and real-time data analysis. Information collected from industrial assets is produced in a continuous fashion, yielding data streams that must be processed under stringent timing constraints. Such data streams are usually subject to non-stationary phenomena, causing that the data distribution of the streams may change, and thus the knowledge captured by models used for data analysis may become obsolete (leading to the so-called concept drift effect). The early detection of the change (drift) is crucial for updating the model's knowledge, which is challenging especially in scenarios where the ground truth associated to the stream data is not readily available. Among many other techniques, the estimation of the model's confidence has been timidly suggested in a few studies as a criterion for detecting drifts in unsupervised settings. The goal of this manuscript is to confirm and expose solidly the connection between the model's confidence in its output and the presence of a concept drift, showcasing it experimentally and advocating for a major consideration of uncertainty estimation in comparative studies to be reported in the future.
Data-Free Sketch-Based Image Retrieval
Mar 14, 2023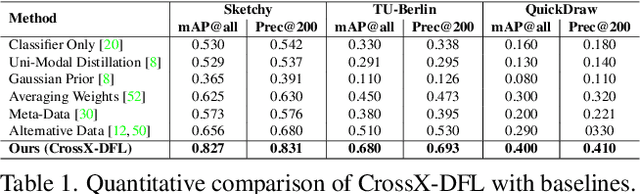

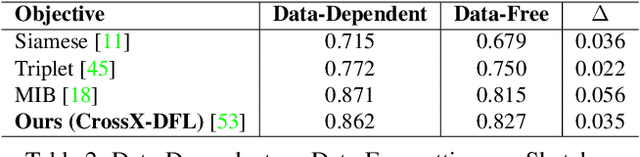
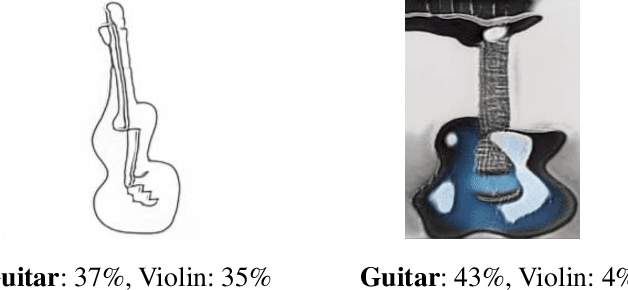
Rising concerns about privacy and anonymity preservation of deep learning models have facilitated research in data-free learning (DFL). For the first time, we identify that for data-scarce tasks like Sketch-Based Image Retrieval (SBIR), where the difficulty in acquiring paired photos and hand-drawn sketches limits data-dependent cross-modal learning algorithms, DFL can prove to be a much more practical paradigm. We thus propose Data-Free (DF)-SBIR, where, unlike existing DFL problems, pre-trained, single-modality classification models have to be leveraged to learn a cross-modal metric-space for retrieval without access to any training data. The widespread availability of pre-trained classification models, along with the difficulty in acquiring paired photo-sketch datasets for SBIR justify the practicality of this setting. We present a methodology for DF-SBIR, which can leverage knowledge from models independently trained to perform classification on photos and sketches. We evaluate our model on the Sketchy, TU-Berlin, and QuickDraw benchmarks, designing a variety of baselines based on state-of-the-art DFL literature, and observe that our method surpasses all of them by significant margins. Our method also achieves mAPs competitive with data-dependent approaches, all the while requiring no training data. Implementation is available at \url{https://github.com/abhrac/data-free-sbir}.
Towards Real-Time Text2Video via CLIP-Guided, Pixel-Level Optimization
Oct 23, 2022


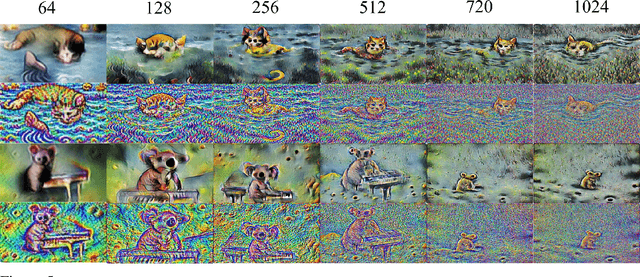
We introduce an approach to generating videos based on a series of given language descriptions. Frames of the video are generated sequentially and optimized by guidance from the CLIP image-text encoder; iterating through language descriptions, weighting the current description higher than others. As opposed to optimizing through an image generator model itself, which tends to be computationally heavy, the proposed approach computes the CLIP loss directly at the pixel level, achieving general content at a speed suitable for near real-time systems. The approach can generate videos in up to 720p resolution, variable frame-rates, and arbitrary aspect ratios at a rate of 1-2 frames per second. Please visit our website to view videos and access our open-source code: https://pschaldenbrand.github.io/text2video/ .
Pseudo Supervised Metrics: Evaluating Unsupervised Image to Image Translation Models In Unsupervised Cross-Domain Classification Frameworks
Mar 18, 2023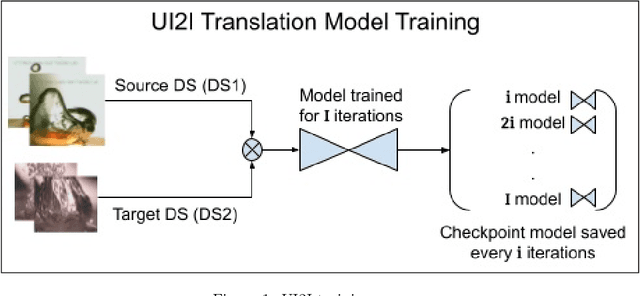

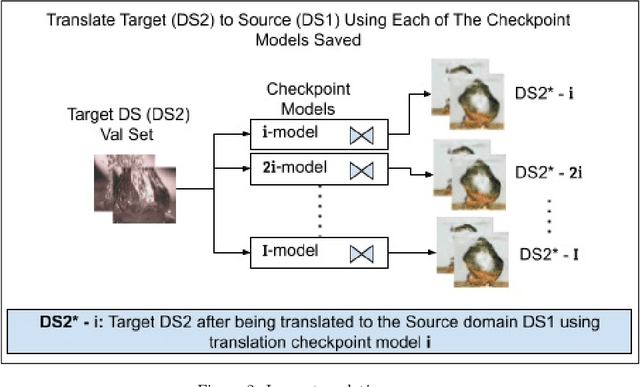
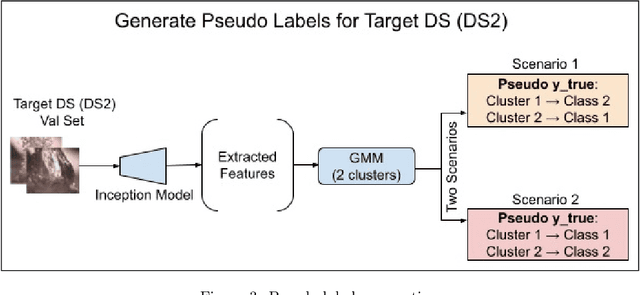
The ability to classify images accurately and efficiently is dependent on having access to large labeled datasets and testing on data from the same domain that the model is trained on. Classification becomes more challenging when dealing with new data from a different domain, where collecting a large labeled dataset and training a new classifier from scratch is time-consuming, expensive, and sometimes infeasible or impossible. Cross-domain classification frameworks were developed to handle this data domain shift problem by utilizing unsupervised image-to-image (UI2I) translation models to translate an input image from the unlabeled domain to the labeled domain. The problem with these unsupervised models lies in their unsupervised nature. For lack of annotations, it is not possible to use the traditional supervised metrics to evaluate these translation models to pick the best-saved checkpoint model. In this paper, we introduce a new method called Pseudo Supervised Metrics that was designed specifically to support cross-domain classification applications contrary to other typically used metrics such as the FID which was designed to evaluate the model in terms of the quality of the generated image from a human-eye perspective. We show that our metric not only outperforms unsupervised metrics such as the FID, but is also highly correlated with the true supervised metrics, robust, and explainable. Furthermore, we demonstrate that it can be used as a standard metric for future research in this field by applying it to a critical real-world problem (the boiling crisis problem).