 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Inverse Universal Traffic Quality -- a Criticality Metric for Crowded Urban Traffic Scenes
Apr 21, 2023
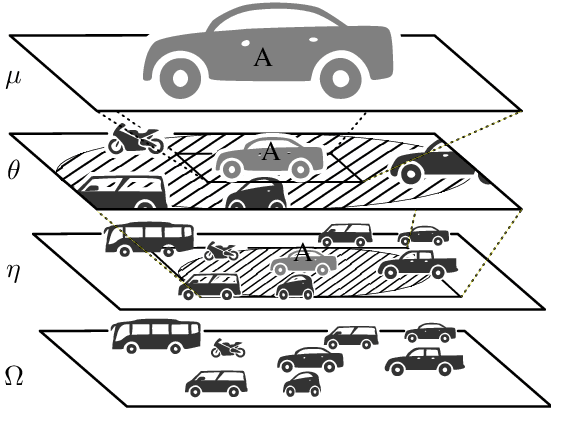
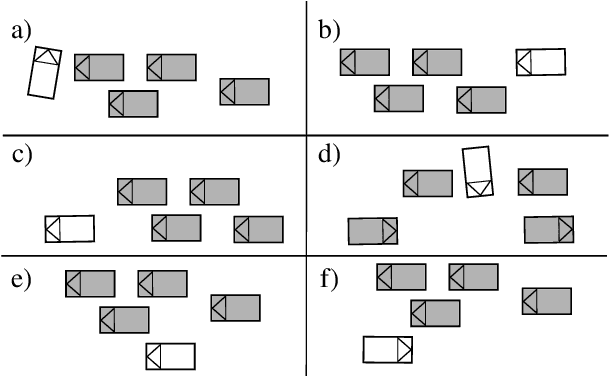
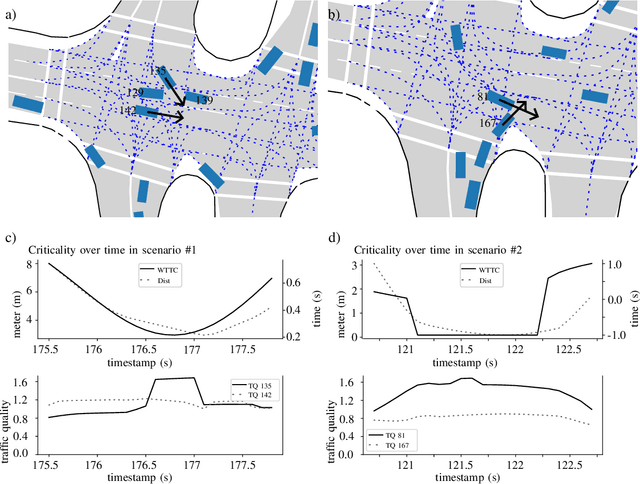
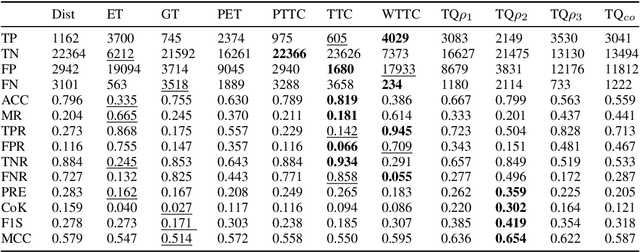
An essential requirement for scenario-based testing the identification of critical scenes and their associated scenarios. However, critical scenes, such as collisions, occur comparatively rarely. Accordingly, large amounts of data must be examined. A further issue is that recorded real-world traffic often consists of scenes with a high number of vehicles, and it can be challenging to determine which are the most critical vehicles regarding the safety of an ego vehicle. Therefore, we present the inverse universal traffic quality, a criticality metric for urban traffic independent of predefined adversary vehicles and vehicle constellations such as intersection trajectories or car-following scenarios. Our metric is universally applicable for different urban traffic situations, e.g., intersections or roundabouts, and can be adjusted to certain situations if needed. Additionally, in this paper, we evaluate the proposed metric and compares its result to other well-known criticality metrics of this field, such as time-to-collision or post-encroachment time.
Vehicle Detection and Classification without Residual Calculation: Accelerating HEVC Image Decoding with Random Perturbation Injection
May 14, 2023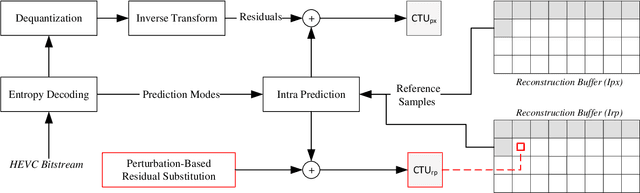


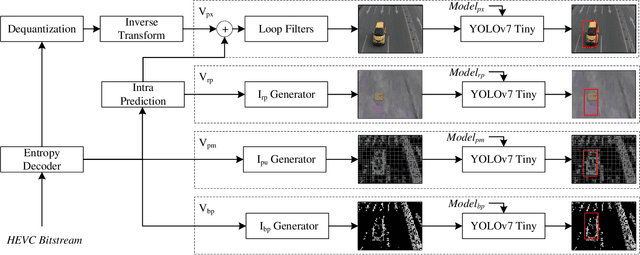
In the field of video analytics, particularly traffic surveillance, there is a growing need for efficient and effective methods for processing and understanding video data. Traditional full video decoding techniques can be computationally intensive and time-consuming, leading researchers to explore alternative approaches in the compressed domain. This study introduces a novel random perturbation-based compressed domain method for reconstructing images from High Efficiency Video Coding (HEVC) bitstreams, specifically designed for traffic surveillance applications. To the best of our knowledge, our method is the first to propose substituting random perturbations for residual values, creating a condensed representation of the original image while retaining information relevant to video understanding tasks, particularly focusing on vehicle detection and classification as key use cases. By not using residual data, our proposed method significantly reduces the data needed in the image reconstruction process, allowing for more efficient storage and transmission of information. This is particularly important when considering the vast amount of video data involved in surveillance applications. Applied to the public BIT-Vehicle dataset, we demonstrate a significant increase in the reconstruction speed compared to the traditional full decoding approach, with our proposed method being approximately 56% faster than the pixel domain method. Additionally, we achieve a detection accuracy of 99.9%, on par with the pixel domain method, and a classification accuracy of 96.84%, only 0.98% lower than the pixel domain method. Furthermore, we showcase the significant reduction in data size, leading to more efficient storage and transmission. Our research establishes the potential of compressed domain methods in traffic surveillance applications, where speed and data size are critical factors.
The Whole Is Greater than the Sum of Its Parts: Improving DNN-based Music Source Separation
May 13, 2023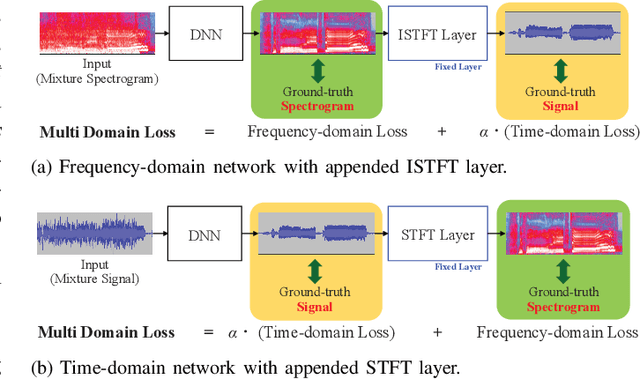
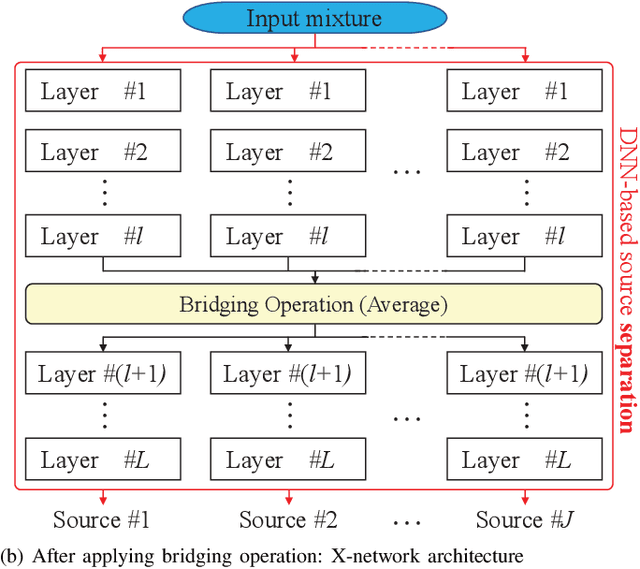
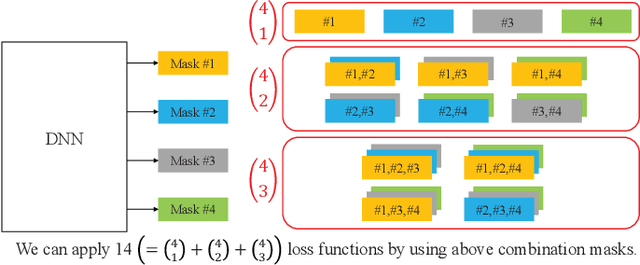

This paper presents the crossing scheme (X-scheme) for improving the performance of deep neural network (DNN)-based music source separation (MSS) without increasing calculation cost. It consists of three components: (i) multi-domain loss (MDL), (ii) bridging operation, which couples the individual instrument networks, and (iii) combination loss (CL). MDL enables the taking advantage of the frequency- and time-domain representations of audio signals. We modify the target network, i.e., the network architecture of the original DNN-based MSS, by adding bridging paths for each output instrument to share their information. MDL is then applied to the combinations of the output sources as well as each independent source, hence we called it CL. MDL and CL can easily be applied to many DNN-based separation methods as they are merely loss functions that are only used during training and do not affect the inference step. Bridging operation does not increase the number of learnable parameters in the network. Experimental results showed that the validity of Open-Unmix (UMX) and densely connected dilated DenseNet (D3Net) extended with our X-scheme, respectively called X-UMX and X-D3Net, by comparing them with their original versions. We also verified the effectiveness of X-scheme in a large-scale data regime, showing its generality with respect to data size. X-UMX Large (X-UMXL), which was trained on large-scale internal data and used in our experiments, is newly available at https://github.com/asteroid-team/asteroid/tree/master/egs/musdb18/X-UMX.
Grasping Extreme Aerodynamics on a Low-Dimensional Manifold
May 13, 2023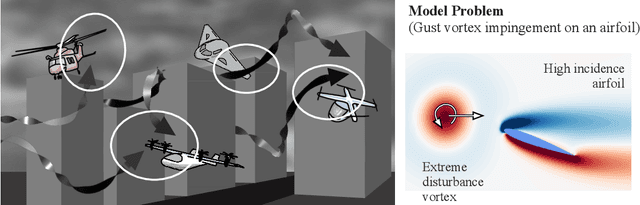
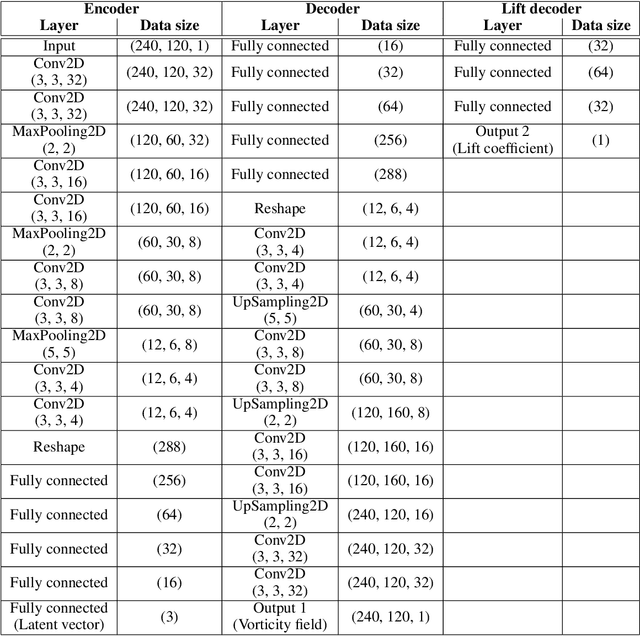
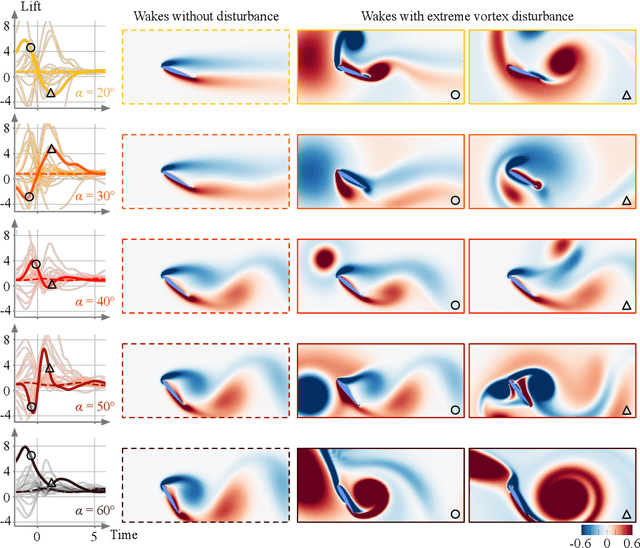
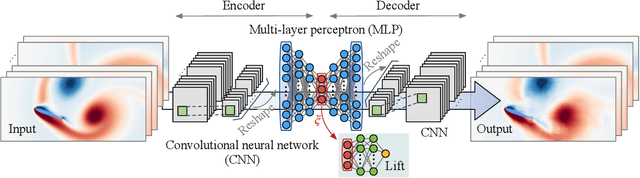
Modern air vehicles perform a wide range of operations, including transportation, defense, surveillance, and rescue. These aircraft can fly in calm conditions but avoid operations in gusty environments, which are seen in urban canyons, over mountainous terrains, and in ship wakes. Smaller aircraft are especially prone to such gust disturbances. With extreme weather becoming ever more frequent due to global warming, it is anticipated that aircraft, especially those that are smaller in size, encounter large-scale atmospheric disturbances and still be expected to manage stable flight. However, there exists virtually no foundation to describe the influence of extreme vortical gusts on flying bodies. To compound on this difficult problem, there is an enormous parameter space for gusty conditions wings encounter. While the interaction between the vortical gusts and wings is seemingly complex and different for each combination of gust parameters, we show in this study that the fundamental physics behind extreme aerodynamics is far simpler and low-rank than traditionally expected. It is revealed that the nonlinear vortical flow field over time and parameter space can be compressed to only three variables with a lift-augmented autoencoder while holding the essence of the original high-dimensional physics. Extreme aerodynamic flows can be optimally compressed through machine learning into a low-dimensional manifold, implying that the identification of appropriate coordinates facilitates analyses, modeling, and control of extremely unsteady gusty flows. The present findings support the stable flight of next-generation small air vehicles in atmosphere conditions traditionally considered unflyable.
Training Strategies for Vision Transformers for Object Detection
Apr 05, 2023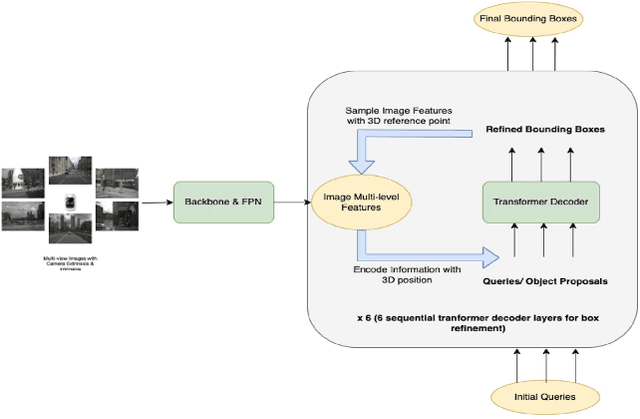


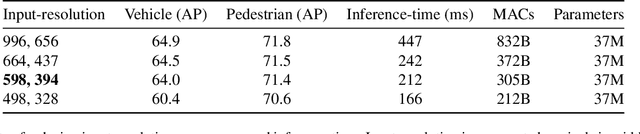
Vision-based Transformer have shown huge application in the perception module of autonomous driving in terms of predicting accurate 3D bounding boxes, owing to their strong capability in modeling long-range dependencies between the visual features. However Transformers, initially designed for language models, have mostly focused on the performance accuracy, and not so much on the inference-time budget. For a safety critical system like autonomous driving, real-time inference at the on-board compute is an absolute necessity. This keeps our object detection algorithm under a very tight run-time budget. In this paper, we evaluated a variety of strategies to optimize on the inference-time of vision transformers based object detection methods keeping a close-watch on any performance variations. Our chosen metric for these strategies is accuracy-runtime joint optimization. Moreover, for actual inference-time analysis we profile our strategies with float32 and float16 precision with TensorRT module. This is the most common format used by the industry for deployment of their Machine Learning networks on the edge devices. We showed that our strategies are able to improve inference-time by 63% at the cost of performance drop of mere 3% for our problem-statement defined in evaluation section. These strategies brings down Vision Transformers detectors inference-time even less than traditional single-image based CNN detectors like FCOS. We recommend practitioners use these techniques to deploy Transformers based hefty multi-view networks on a budge-constrained robotic platform.
Multi-Temporal Lip-Audio Memory for Visual Speech Recognition
May 08, 2023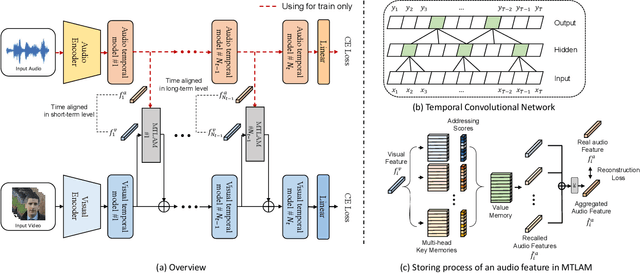
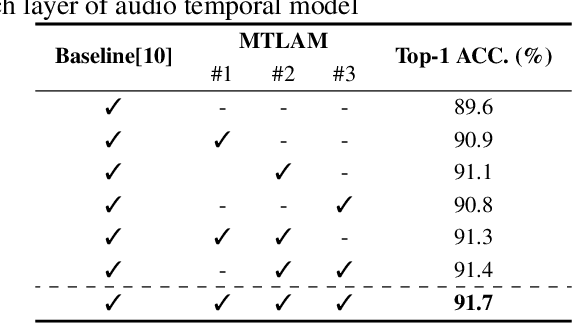
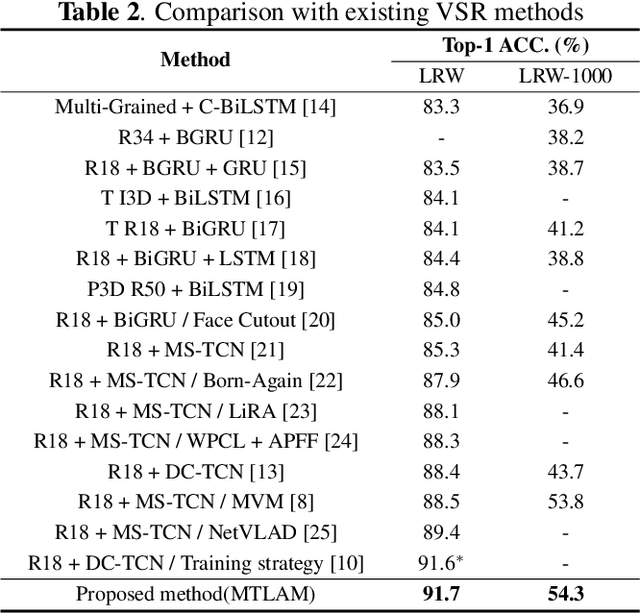
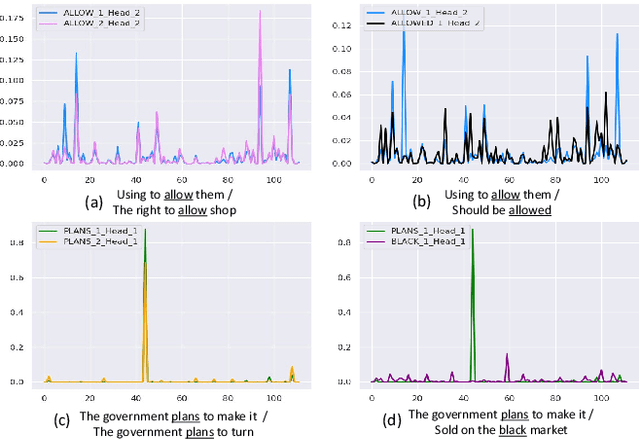
Visual Speech Recognition (VSR) is a task to predict a sentence or word from lip movements. Some works have been recently presented which use audio signals to supplement visual information. However, existing methods utilize only limited information such as phoneme-level features and soft labels of Automatic Speech Recognition (ASR) networks. In this paper, we present a Multi-Temporal Lip-Audio Memory (MTLAM) that makes the best use of audio signals to complement insufficient information of lip movements. The proposed method is mainly composed of two parts: 1) MTLAM saves multi-temporal audio features produced from short- and long-term audio signals, and the MTLAM memorizes a visual-to-audio mapping to load stored multi-temporal audio features from visual features at the inference phase. 2) We design an audio temporal model to produce multi-temporal audio features capturing the context of neighboring words. In addition, to construct effective visual-to-audio mapping, the audio temporal models can generate audio features time-aligned with visual features. Through extensive experiments, we validate the effectiveness of the MTLAM achieving state-of-the-art performances on two public VSR datasets.
Deep Learning and Image Super-Resolution-Guided Beam and Power Allocation for mmWave Networks
May 08, 2023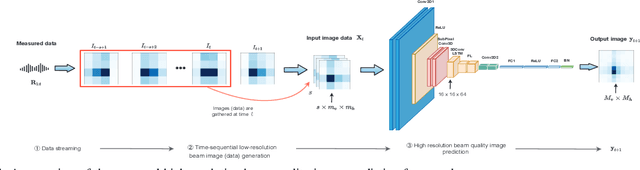
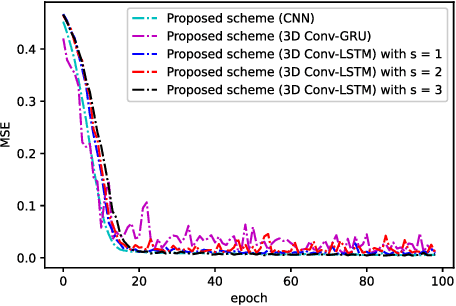
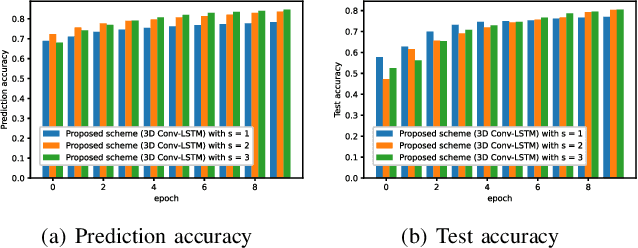
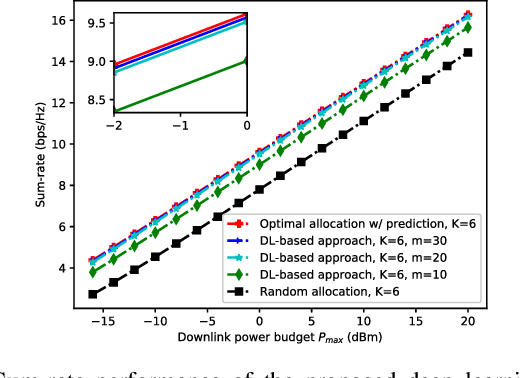
In this paper, we develop a deep learning (DL)-guided hybrid beam and power allocation approach for multiuser millimeter-wave (mmWave) networks, which facilitates swift beamforming at the base station (BS). The following persisting challenges motivated our research: (i) User and vehicular mobility, as well as redundant beam-reselections in mmWave networks, degrade the efficiency; (ii) Due to the large beamforming dimension at the BS, the beamforming weights predicted by the cutting-edge DL-based methods often do not suit the channel distributions; (iii) Co-located user devices may cause a severe beam conflict, thus deteriorating system performance. To address the aforementioned challenges, we exploit the synergy of supervised learning and super-resolution technology to enable low-overhead beam- and power allocation. In the first step, we propose a method for beam-quality prediction. It is based on deep learning and explores the relationship between high- and low-resolution beam images (energy). Afterward, we develop a DL-based allocation approach, which enables high-accuracy beam and power allocation with only a portion of the available time-sequential low-resolution images. Theoretical and numerical results verify the effectiveness of our proposed
A Unified Evaluation Framework for Novelty Detection and Accommodation in NLP with an Instantiation in Authorship Attribution
May 08, 2023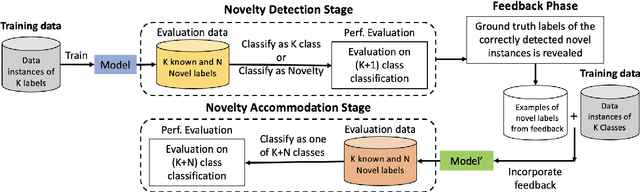
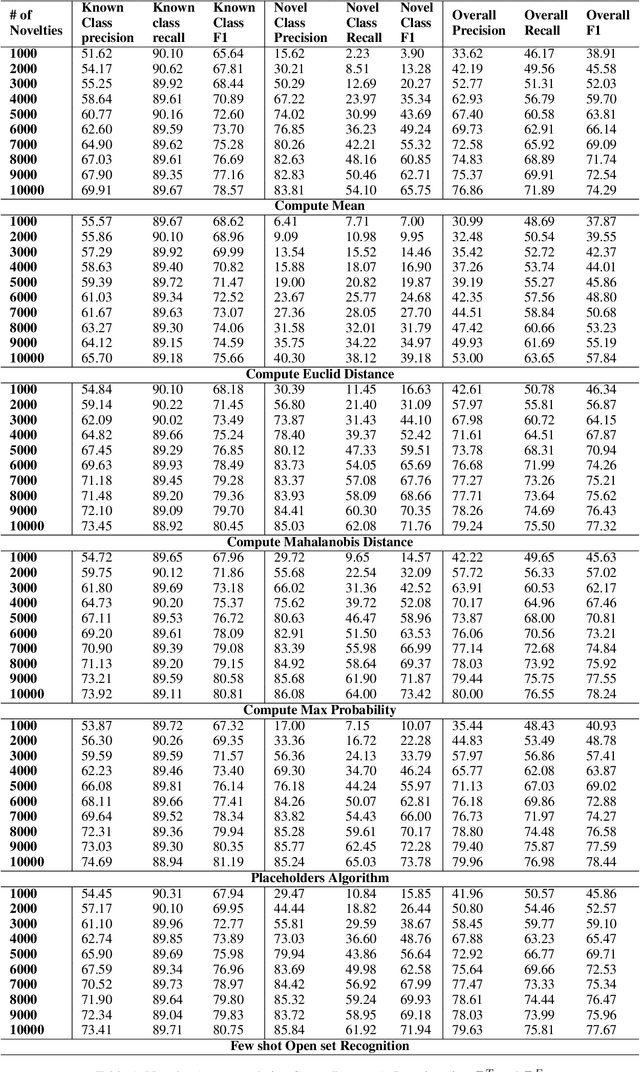
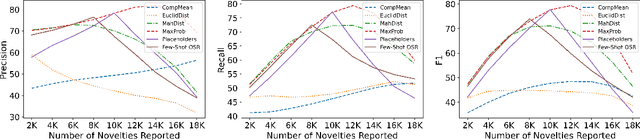
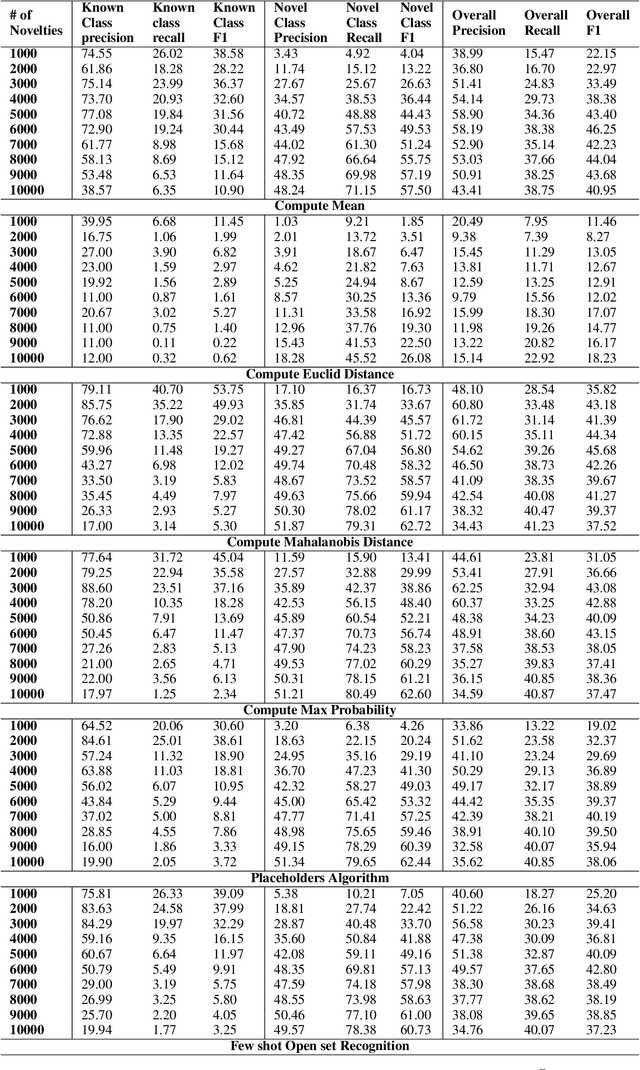
State-of-the-art natural language processing models have been shown to achieve remarkable performance in 'closed-world' settings where all the labels in the evaluation set are known at training time. However, in real-world settings, 'novel' instances that do not belong to any known class are often observed. This renders the ability to deal with novelties crucial. To initiate a systematic research in this important area of 'dealing with novelties', we introduce 'NoveltyTask', a multi-stage task to evaluate a system's performance on pipelined novelty 'detection' and 'accommodation' tasks. We provide mathematical formulation of NoveltyTask and instantiate it with the authorship attribution task that pertains to identifying the correct author of a given text. We use Amazon reviews corpus and compile a large dataset (consisting of 250k instances across 200 authors/labels) for NoveltyTask. We conduct comprehensive experiments and explore several baseline methods for the task. Our results show that the methods achieve considerably low performance making the task challenging and leaving sufficient room for improvement. Finally, we believe our work will encourage research in this underexplored area of dealing with novelties, an important step en route to developing robust systems.
CGI-Stereo: Accurate and Real-Time Stereo Matching via Context and Geometry Interaction
Jan 07, 2023
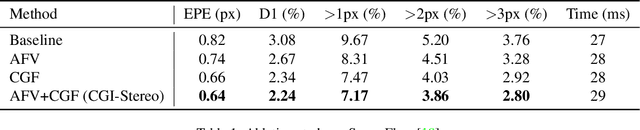
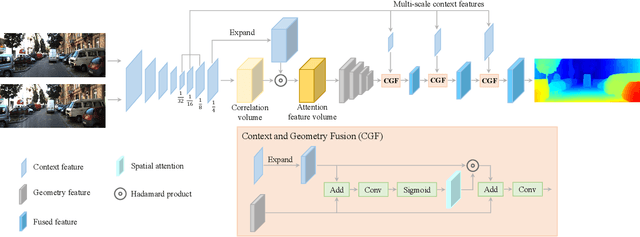
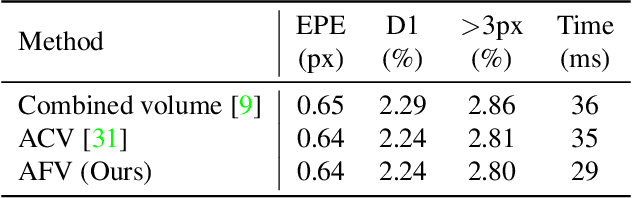
In this paper, we propose CGI-Stereo, a novel neural network architecture that can concurrently achieve real-time performance, state-of-the-art accuracy, and strong generalization ability. The core of our CGI-Stereo is a Context and Geometry Fusion (CGF) block which adaptively fuses context and geometry information for more accurate and efficient cost aggregation and meanwhile provides feedback to feature learning to guide more effective contextual feature extraction. The proposed CGF can be easily embedded into many existing stereo matching networks, such as PSMNet, GwcNet and ACVNet. The resulting networks are improved in accuracy by a large margin. Specially, the model which integrates our CGF with ACVNet could rank 1st on the KITTI 2012 leaderboard among all the published methods. We further propose an informative and concise cost volume, named Attention Feature Volume (AFV), which exploits a correlation volume as attention weights to filter a feature volume. Based on CGF and AFV, the proposed CGI-Stereo outperforms all other published real-time methods on KITTI benchmarks and shows better generalization ability than other real-time methods. The code is available at https://github.com/gangweiX/CGI-Stereo.
Physics-Informed Localized Learning for Advection-Diffusion-Reaction Systems
May 05, 2023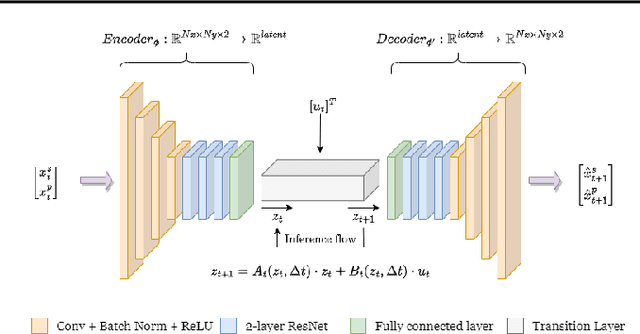
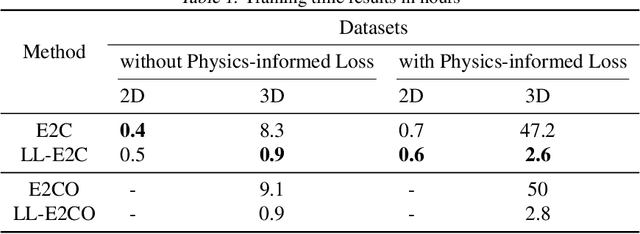

The global push for new energy solutions, such as Geothermal, and Carbon Capture and Sequestration initiatives has thrust new demands upon the current state-of the-art subsurface fluid simulators. The requirement to be able to simulate a large order of reservoir states simultaneously in a short period of time has opened the door of opportunity for the application of machine learning techniques for surrogate modelling. We propose a novel physics-informed and boundary conditions-aware Localized Learning method which extends the Embed-to-Control (E2C) and Embed-to-Control and Observed (E2CO) models to learn local representations of global state variables in an Advection-Diffusion Reaction system. We show that our model trained on reservoir simulation data is able to predict future states of the system, given a set of controls, to a great deal of accuracy with only a fraction of the available information, while also reducing training times significantly compared to the original E2C and E2CO models.