 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Directed Chain Generative Adversarial Networks
Apr 25, 2023
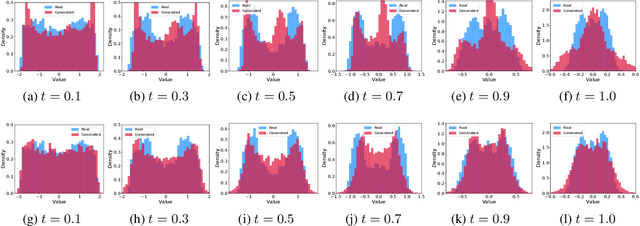
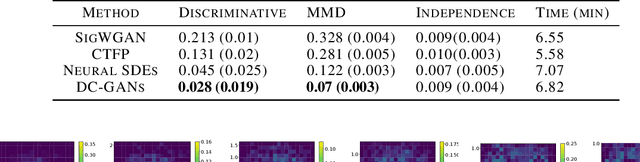
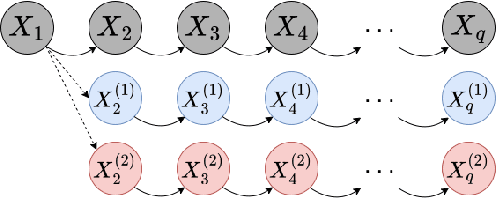

Real-world data can be multimodal distributed, e.g., data describing the opinion divergence in a community, the interspike interval distribution of neurons, and the oscillators natural frequencies. Generating multimodal distributed real-world data has become a challenge to existing generative adversarial networks (GANs). For example, neural stochastic differential equations (Neural SDEs), treated as infinite-dimensional GANs, have demonstrated successful performance mainly in generating unimodal time series data. In this paper, we propose a novel time series generator, named directed chain GANs (DC-GANs), which inserts a time series dataset (called a neighborhood process of the directed chain or input) into the drift and diffusion coefficients of the directed chain SDEs with distributional constraints. DC-GANs can generate new time series of the same distribution as the neighborhood process, and the neighborhood process will provide the key step in learning and generating multimodal distributed time series. The proposed DC-GANs are examined on four datasets, including two stochastic models from social sciences and computational neuroscience, and two real-world datasets on stock prices and energy consumption. To our best knowledge, DC-GANs are the first work that can generate multimodal time series data and consistently outperforms state-of-the-art benchmarks with respect to measures of distribution, data similarity, and predictive ability.
Exploring the Rate-Distortion-Complexity Optimization in Neural Image Compression
May 12, 2023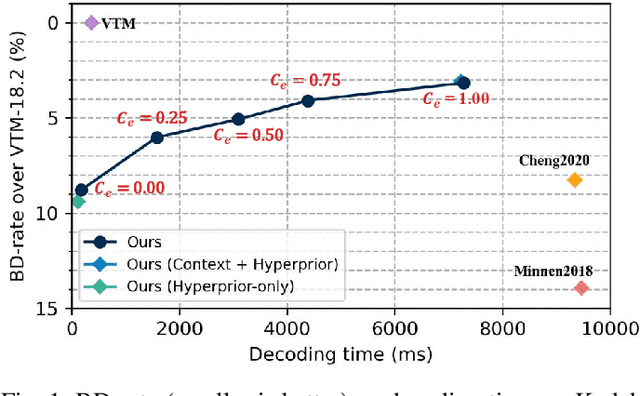
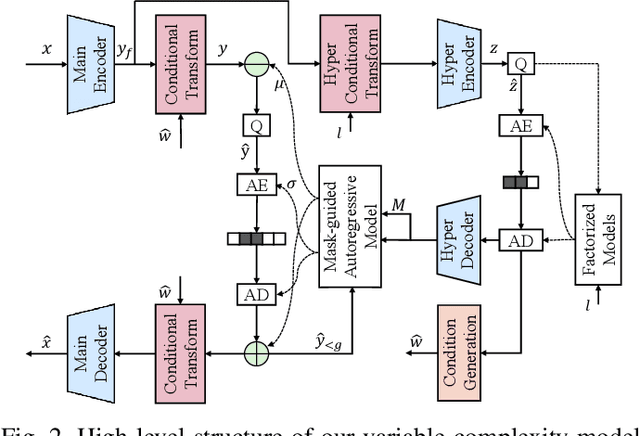
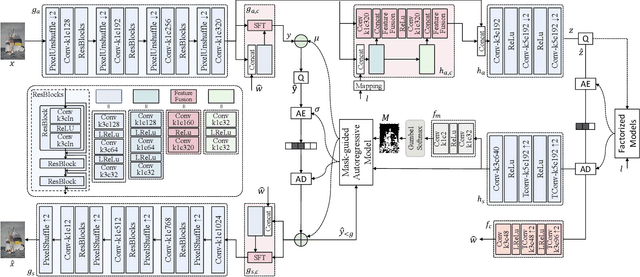
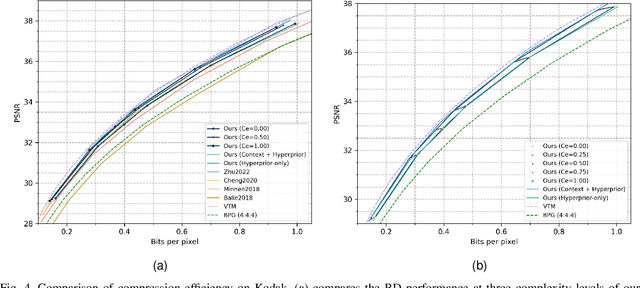
Despite a short history, neural image codecs have been shown to surpass classical image codecs in terms of rate-distortion performance. However, most of them suffer from significantly longer decoding times, which hinders the practical applications of neural image codecs. This issue is especially pronounced when employing an effective yet time-consuming autoregressive context model since it would increase entropy decoding time by orders of magnitude. In this paper, unlike most previous works that pursue optimal RD performance while temporally overlooking the coding complexity, we make a systematical investigation on the rate-distortion-complexity (RDC) optimization in neural image compression. By quantifying the decoding complexity as a factor in the optimization goal, we are now able to precisely control the RDC trade-off and then demonstrate how the rate-distortion performance of neural image codecs could adapt to various complexity demands. Going beyond the investigation of RDC optimization, a variable-complexity neural codec is designed to leverage the spatial dependencies adaptively according to industrial demands, which supports fine-grained complexity adjustment by balancing the RDC tradeoff. By implementing this scheme in a powerful base model, we demonstrate the feasibility and flexibility of RDC optimization for neural image codecs.
MotionBEV: Attention-Aware Online LiDAR Moving Object Segmentation with Bird's Eye View based Appearance and Motion Features
May 12, 2023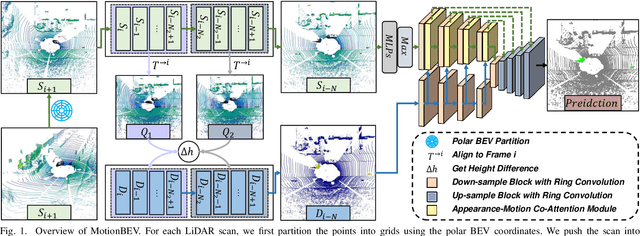
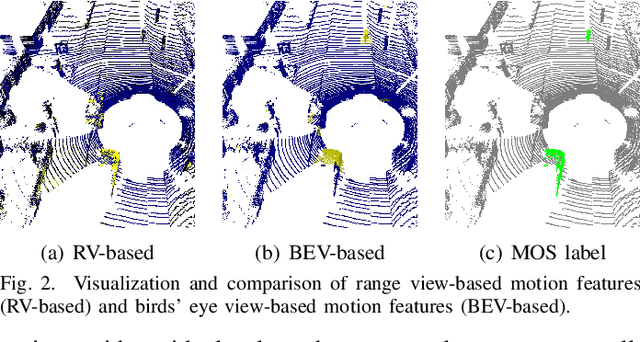
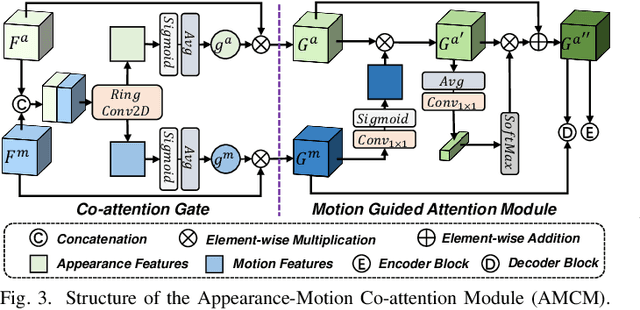
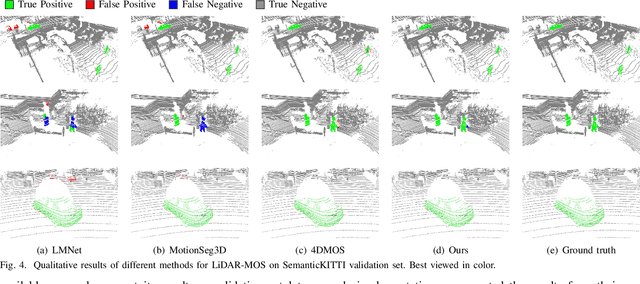
Identifying moving objects is an essential capability for autonomous systems, as it provides critical information for pose estimation, navigation, collision avoidance and static map construction. In this paper, we present MotionBEV, a fast and accurate framework for LiDAR moving object segmentation, which segments moving objects with appearance and motion features in bird's eye view (BEV) domain. Our approach converts 3D LiDAR scans into 2D polar BEV representation to achieve real-time performance. Specifically, we learn appearance features with a simplified PointNet, and compute motion features through the height differences of consecutive frames of point clouds projected onto vertical columns in the polar BEV coordinate system. We employ a dual-branch network bridged by the Appearance-Motion Co-attention Module (AMCM) to adaptively fuse the spatio-temporal information from appearance and motion features. Our approach achieves state-of-the-art performance on the SemanticKITTI-MOS benchmark, with an average inference time of 23ms on an RTX 3090 GPU. Furthermore, to demonstrate the practical effectiveness of our method, we provide a LiDAR-MOS dataset recorded by a solid-state LiDAR, which features non-repetitive scanning patterns and small field of view.
Data-efficient Active Learning for Structured Prediction with Partial Annotation and Self-Training
May 22, 2023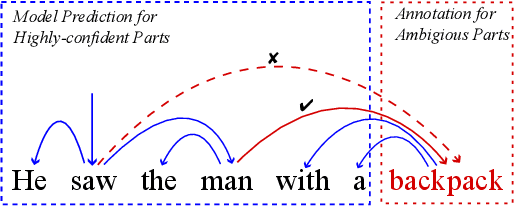
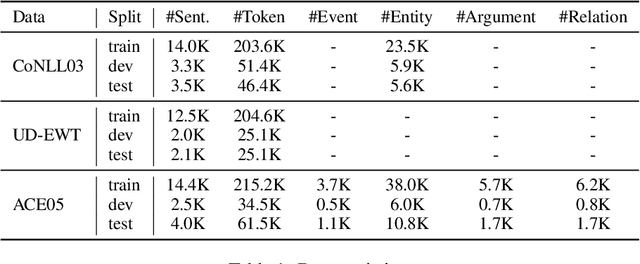
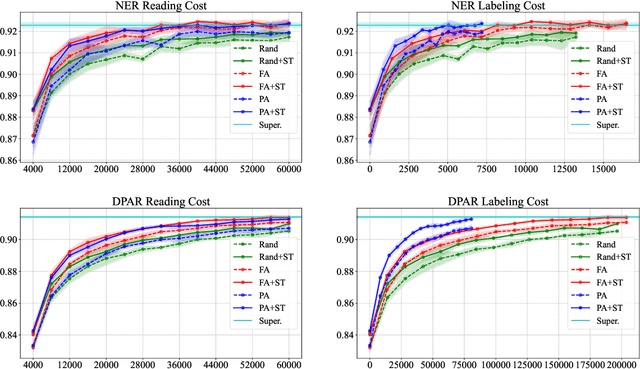
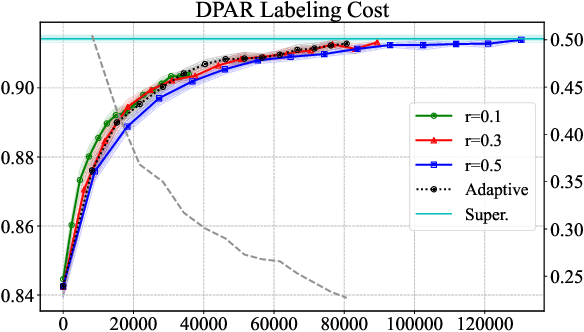
In this work we propose a pragmatic method that reduces the annotation cost for structured label spaces using active learning. Our approach leverages partial annotation, which reduces labeling costs for structured outputs by selecting only the most informative substructures for annotation. We also utilize selftraining to incorporate the current model's automatic predictions as pseudo-labels for unannotated sub-structures. A key challenge in effectively combining partial annotation with self-training to reduce annotation cost is determining which sub-structures to select to label. To address this challenge we adopt an error estimator to decide the partial selection ratio adaptively according to the current model's capability. In evaluations spanning four structured prediction tasks, we show that our combination of partial annotation and self-training using an adaptive selection ratio reduces annotation cost over strong full annotation baselines under a fair comparison scheme that takes reading time into consideration.
Multirotor Ensemble Model Predictive Control I: Simulation Experiments
May 22, 2023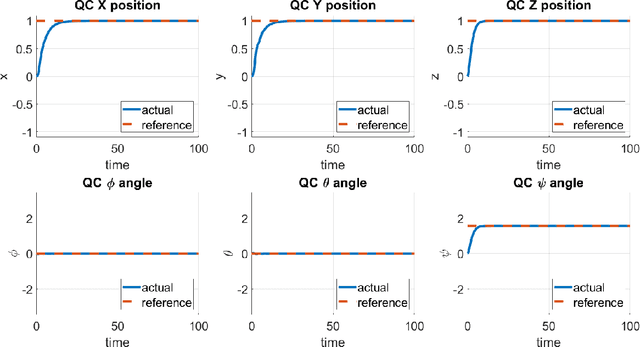
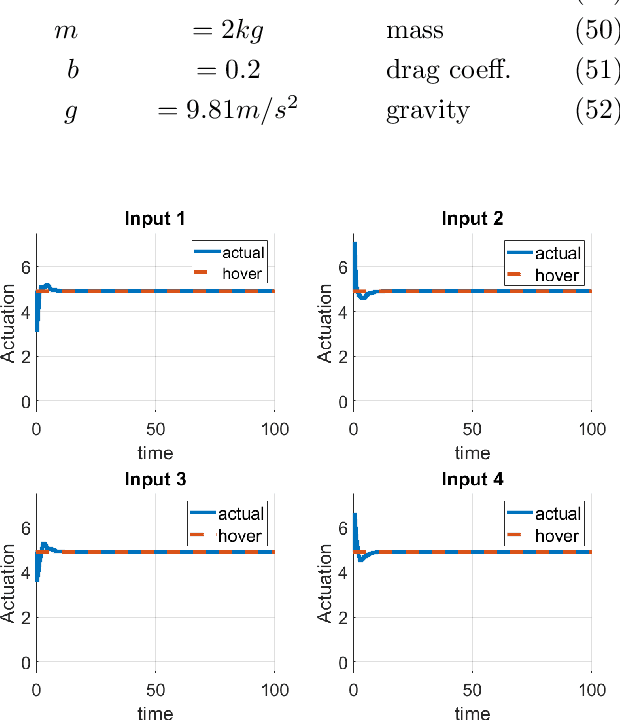
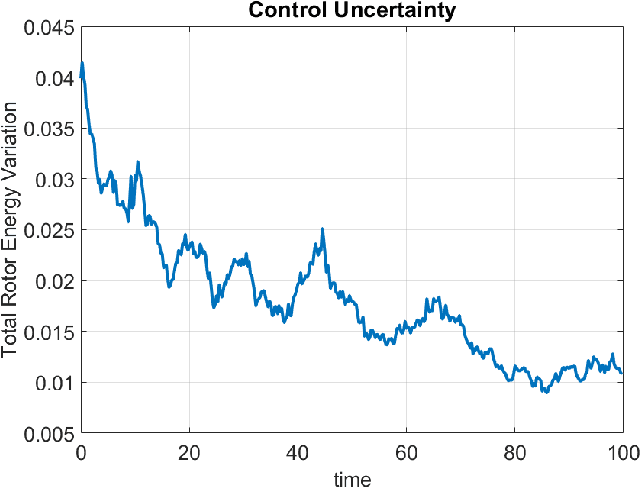
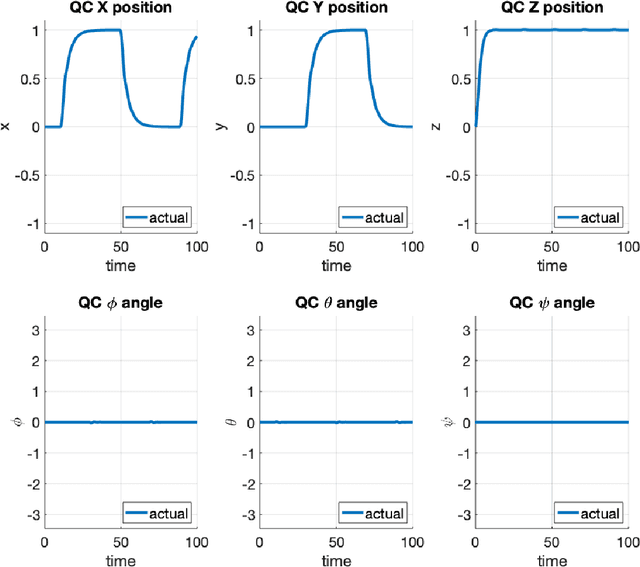
Nonlinear receding horizon model predictive control is a powerful approach to controlling nonlinear dynamical systems. However, typical approaches that use the Jacobian, adjoint, and forward-backward passes may lose fidelity and efficacy for highly nonlinear problems. Here, we develop an Ensemble Model Predictive Control (EMPC) approach wherein the forward model remains fully nonlinear, and an ensemble-represented Gaussian process performs the backward calculations to determine optimal gains for the initial time. EMPC admits black box, possible non-differentiable models, simulations are executable in parallel over long horizons, and control is uncertainty quantifying and applicable to stochastic settings. We construct the EMPC for terminal control and regulation problems and apply it to the control of a quadrotor in a simulated, identical-twin study. Results suggest that the easily implemented approach is promising and amenable to controlling autonomous robotic systems with added state/parameter estimation and parallel computing.
Absolute integrability of Mercer kernels is only sufficient for RKHS stability
May 02, 2023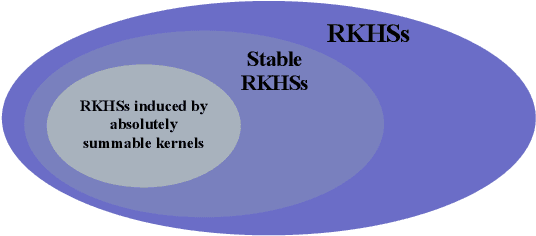
Reproducing kernel Hilbert spaces (RKHSs) are special Hilbert spaces in one-to-one correspondence with positive definite maps called kernels. They are widely employed in machine learning to reconstruct unknown functions from sparse and noisy data. In the last two decades, a subclass known as stable RKHSs has been also introduced in the setting of linear system identification. Stable RKHSs contain only absolutely integrable impulse responses over the positive real line. Hence, they can be adopted as hypothesis spaces to estimate linear, time-invariant and BIBO stable dynamic systems from input-output data. Necessary and sufficient conditions for RKHS stability are available in the literature and it is known that kernel absolute integrability implies stability. Working in discrete-time, in a recent work we have proved that this latter condition is only sufficient. Working in continuous-time, it is the purpose of this note to prove that the same result holds also for Mercer kernels.
Analysis of business process automation as linear time-invariant system network
Feb 09, 2023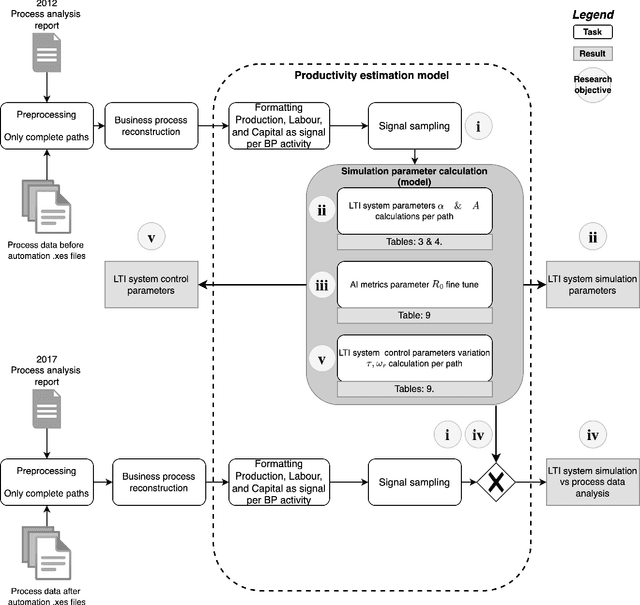
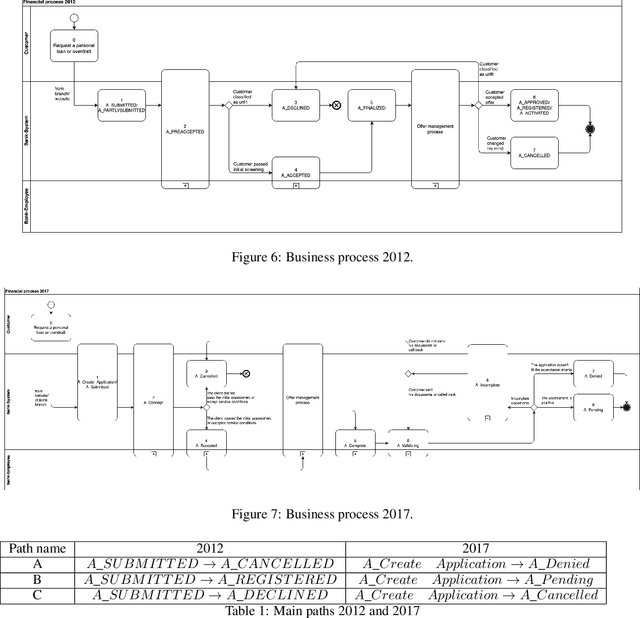
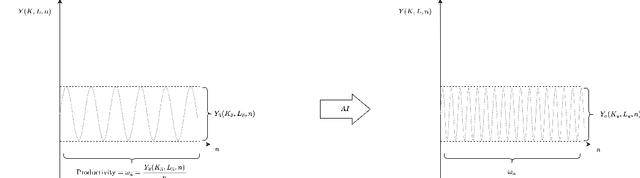

In this work, we examined Business Process (BP) production as a signal; this novel approach explores a BP workflow as a linear time-invariant (LTI) system. We analysed BP productivity in the frequency domain; this standpoint examines how labour and capital act as BP input signals and how their fundamental frequencies affect BP production. Our research also proposes a simulation framework of a BP in the frequency domain for estimating productivity gains due to the introduction of automation steps. Our ultimate goal was to supply evidence to address Solow's Paradox.
Real-Time Simultaneous Localization and Mapping with LiDAR intensity
Jan 23, 2023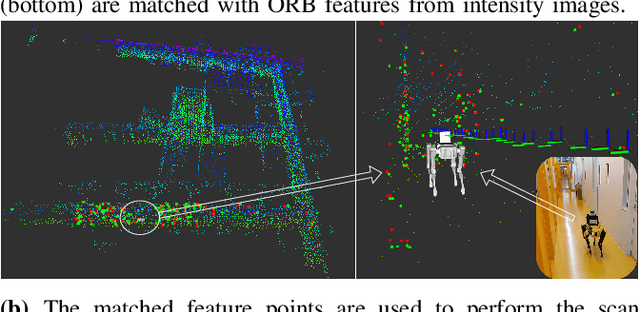
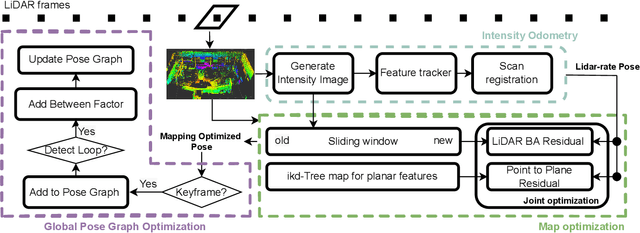
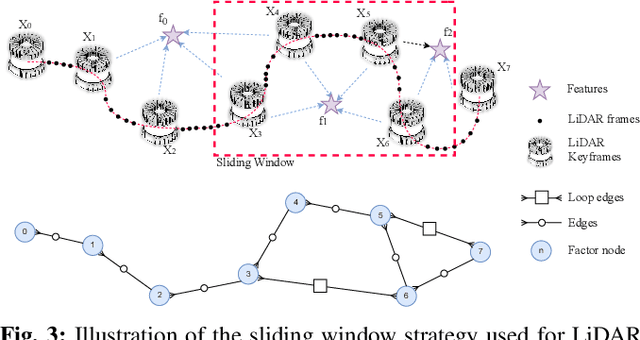
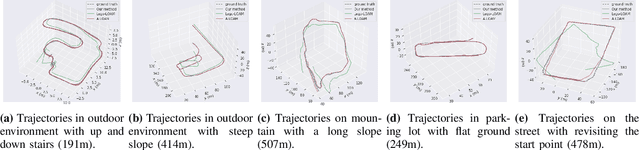
We propose a novel real-time LiDAR intensity image-based simultaneous localization and mapping method , which addresses the geometry degeneracy problem in unstructured environments. Traditional LiDAR-based front-end odometry mostly relies on geometric features such as points, lines and planes. A lack of these features in the environment can lead to the failure of the entire odometry system. To avoid this problem, we extract feature points from the LiDAR-generated point cloud that match features identified in LiDAR intensity images. We then use the extracted feature points to perform scan registration and estimate the robot ego-movement. For the back-end, we jointly optimize the distance between the corresponding feature points, and the point to plane distance for planes identified in the map. In addition, we use the features extracted from intensity images to detect loop closure candidates from previous scans and perform pose graph optimization. Our experiments show that our method can run in real time with high accuracy and works well with illumination changes, low-texture, and unstructured environments.
Interpretable by Design Visual Question Answering
May 24, 2023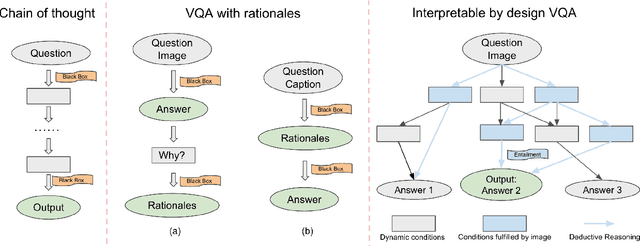
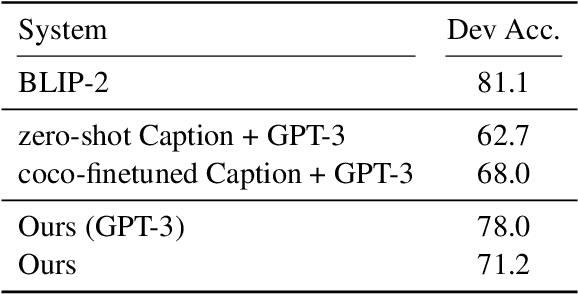
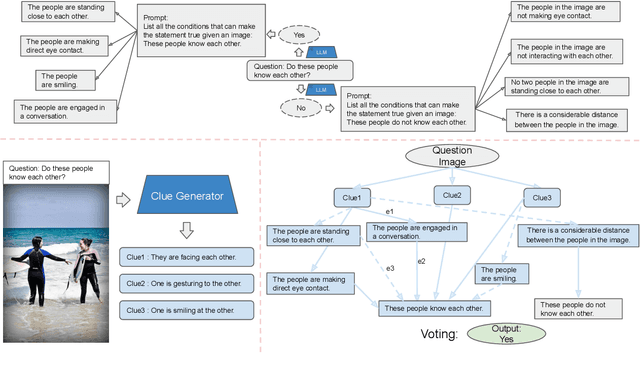
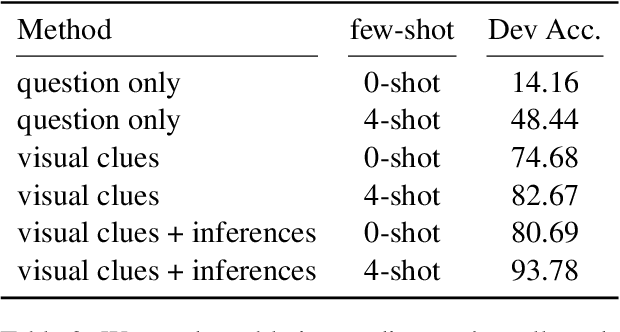
Model interpretability has long been a hard problem for the AI community especially in the multimodal setting, where vision and language need to be aligned and reasoned at the same time. In this paper, we specifically focus on the problem of Visual Question Answering (VQA). While previous researches try to probe into the network structures of black-box multimodal models, we propose to tackle the problem from a different angle -- to treat interpretability as an explicit additional goal. Given an image and question, we argue that an interpretable VQA model should be able to tell what conclusions it can get from which part of the image, and show how each statement help to arrive at an answer. We introduce InterVQA: Interpretable-by-design VQA, where we design an explicit intermediate dynamic reasoning structure for VQA problems and enforce symbolic reasoning that only use the structure for final answer prediction to take place. InterVQA produces high-quality explicit intermediate reasoning steps, while maintaining similar to the state-of-the-art (sota) end-task performance.
Self-Checker: Plug-and-Play Modules for Fact-Checking with Large Language Models
May 24, 2023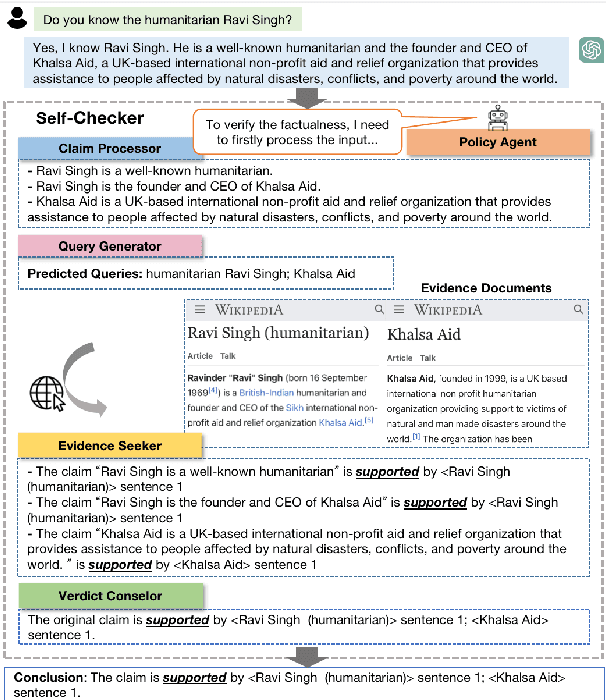

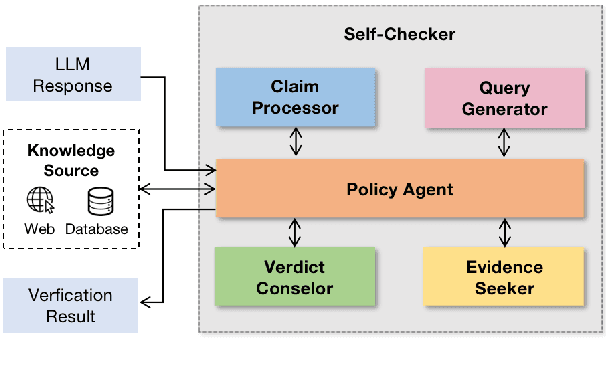
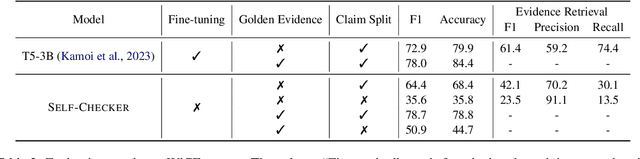
Fact-checking is an essential task in NLP that is commonly utilized for validating the factual accuracy of claims. Prior work has mainly focused on fine-tuning pre-trained languages models on specific datasets, which can be computationally intensive and time-consuming. With the rapid development of large language models (LLMs), such as ChatGPT and GPT-3, researchers are now exploring their in-context learning capabilities for a wide range of tasks. In this paper, we aim to assess the capacity of LLMs for fact-checking by introducing Self-Checker, a framework comprising a set of plug-and-play modules that facilitate fact-checking by purely prompting LLMs in an almost zero-shot setting. This framework provides a fast and efficient way to construct fact-checking systems in low-resource environments. Empirical results demonstrate the potential of Self-Checker in utilizing LLMs for fact-checking. However, there is still significant room for improvement compared to SOTA fine-tuned models, which suggests that LLM adoption could be a promising approach for future fact-checking research.