 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Computational models of sound-quality metrics using method for calculating loudness with gammatone/gammachirp auditory filterbank
May 19, 2023
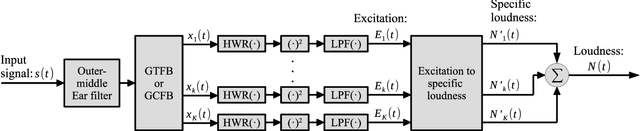
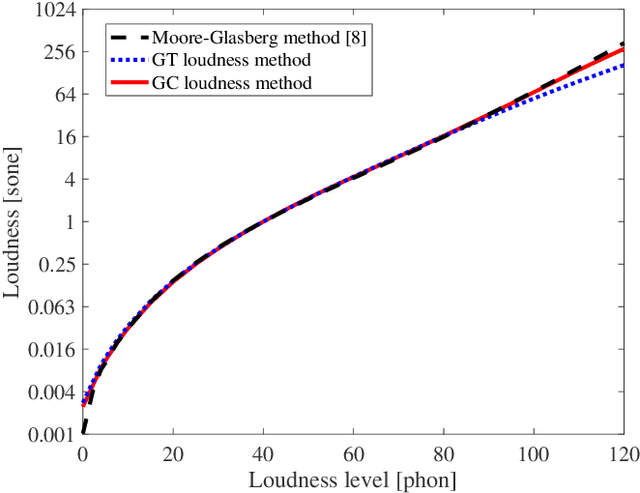


Sound-quality metrics (SQMs), such as sharpness, roughness, and fluctuation strength, are calculated using a standard method for calculating loudness (Zwicker method, ISO532B, 1975). Since ISO 532 had been revised to contain the Zwicker method (ISO 5321) and Moore-Glasberg method (ISO 532-2) in 2017, the classical computational SQM model should also be revised in accordance with these revisions. A roex auditory filterbank used with the Moore-Glasberg method is defined separately in the frequency domain not to have impulse responses. It is therefore difficult to construct a computational SQM model, e.g., the classical computational SQM model, on the basis of ISO 532-2. We propose a method for calculating loudness using the time-domain gammatone or gammachirp auditory filterbank instead of the roex auditory filterbank to solve this problem. We also propose three computational SQM models based on ISO 532-2 to use with the proposed loudness method. We evaluated the root-mean squared errors (RMSEs) of the calculated loudness with the proposed and Moore-Glasberg methods. We then evaluated the RMSEs of the calculated SQMs with the proposed method and human data of SQMs. We found that the proposed method can be considered as a time-domain method for calculating loudness on the basis of ISO 532-2 because the RMSEs are very small. We also found that the proposed computational SQM models can effectively account for the human data of SQMs compared with the classical computational SQM model in terms of RMSEs.
Real-Time Navigation for Autonomous Surface Vehicles In Ice-Covered Waters
Feb 24, 2023
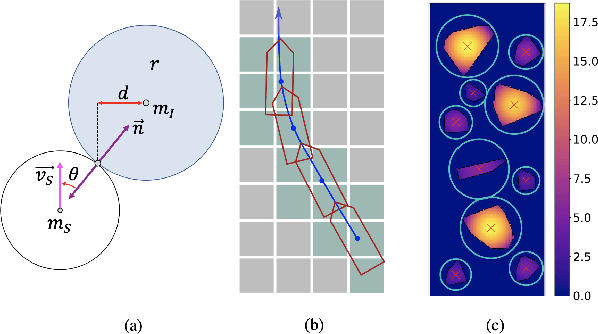
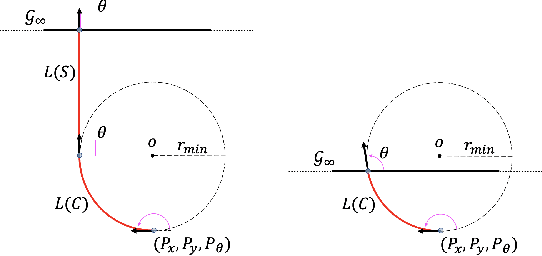
Vessel transit in ice-covered waters poses unique challenges in safe and efficient motion planning. When the concentration of ice is high, it may not be possible to find collision-free trajectories. Instead, ice can be pushed out of the way if it is small or if contact occurs near the edge of the ice. In this work, we propose a real-time navigation framework that minimizes collisions with ice and distance travelled by the vessel. We exploit a lattice-based planner with a cost that captures the ship interaction with ice. To address the dynamic nature of the environment, we plan motion in a receding horizon manner based on updated vessel and ice state information. Further, we present a novel planning heuristic for evaluating the cost-to-go, which is applicable to navigation in a channel without a fixed goal location. The performance of our planner is evaluated across several levels of ice concentration both in simulated and in real-world experiments.
Temporal Network Creation Games
May 21, 2023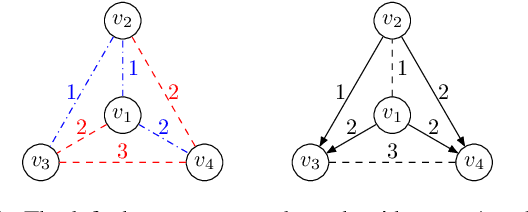
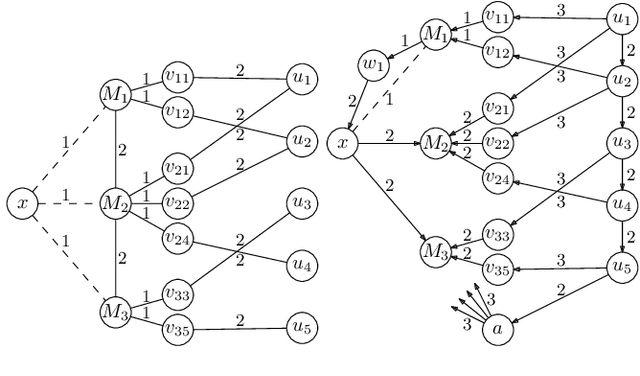
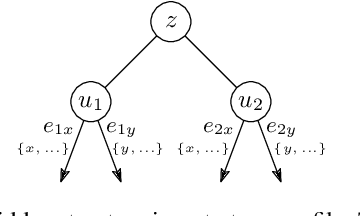
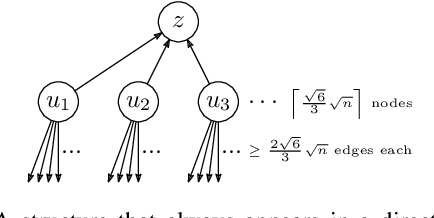
Most networks are not static objects, but instead they change over time. This observation has sparked rigorous research on temporal graphs within the last years. In temporal graphs, we have a fixed set of nodes and the connections between them are only available at certain time steps. This gives rise to a plethora of algorithmic problems on such graphs, most prominently the problem of finding temporal spanners, i.e., the computation of subgraphs that guarantee all pairs reachability via temporal paths. To the best of our knowledge, only centralized approaches for the solution of this problem are known. However, many real-world networks are not shaped by a central designer but instead they emerge and evolve by the interaction of many strategic agents. This observation is the driving force of the recent intensive research on game-theoretic network formation models. In this work we bring together these two recent research directions: temporal graphs and game-theoretic network formation. As a first step into this new realm, we focus on a simplified setting where a complete temporal host graph is given and the agents, corresponding to its nodes, selfishly create incident edges to ensure that they can reach all other nodes via temporal paths in the created network. This yields temporal spanners as equilibria of our game. We prove results on the convergence to and the existence of equilibrium networks, on the complexity of finding best agent strategies, and on the quality of the equilibria. By taking these first important steps, we uncover challenging open problems that call for an in-depth exploration of the creation of temporal graphs by strategic agents.
Improving Convergence and Generalization Using Parameter Symmetries
May 22, 2023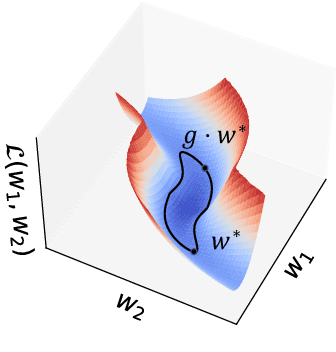

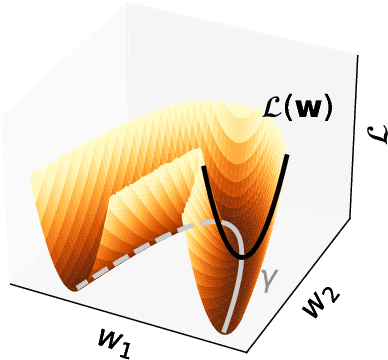
In overparametrized models, different values of the parameters may result in the same loss value. Parameter space symmetries are transformations that change the model parameters but leave the loss invariant. Teleportation applies such transformations to accelerate optimization. However, the exact mechanism behind this algorithm's success is not well understood. In this paper, we show that teleportation not only speeds up optimization in the short-term, but gives overall faster time to convergence. Additionally, we show that teleporting to minima with different curvatures improves generalization and provide insights on the connection between the curvature of the minima and generalization ability. Finally, we show that integrating teleportation into a wide range of optimization algorithms and optimization-based meta-learning improves convergence.
Fast Convergence in Learning Two-Layer Neural Networks with Separable Data
May 22, 2023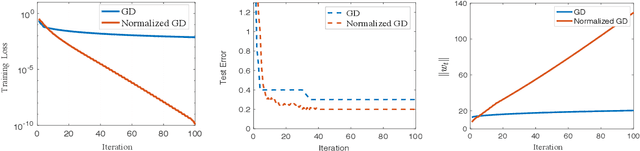
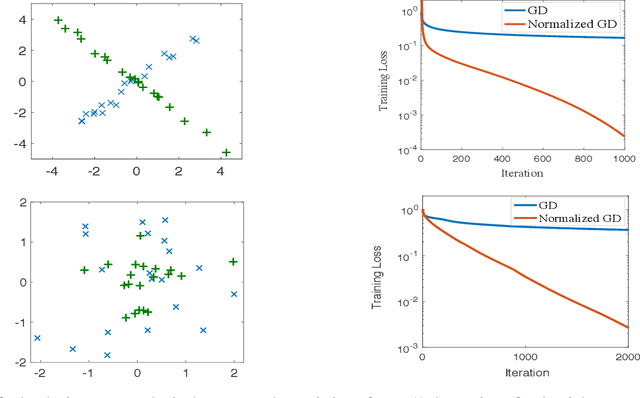
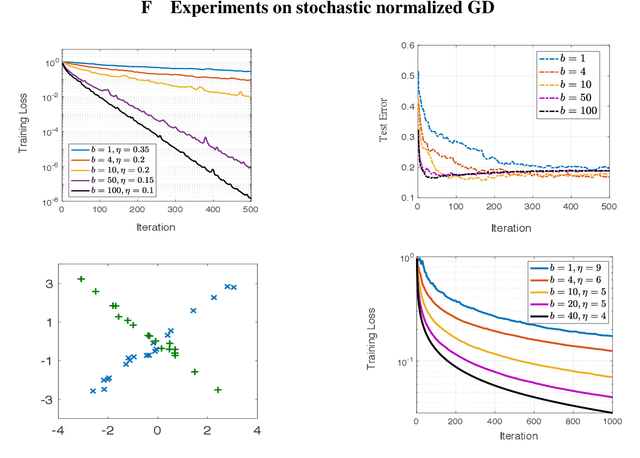
Normalized gradient descent has shown substantial success in speeding up the convergence of exponentially-tailed loss functions (which includes exponential and logistic losses) on linear classifiers with separable data. In this paper, we go beyond linear models by studying normalized GD on two-layer neural nets. We prove for exponentially-tailed losses that using normalized GD leads to linear rate of convergence of the training loss to the global optimum. This is made possible by showing certain gradient self-boundedness conditions and a log-Lipschitzness property. We also study generalization of normalized GD for convex objectives via an algorithmic-stability analysis. In particular, we show that normalized GD does not overfit during training by establishing finite-time generalization bounds.
Towards generalizing deep-audio fake detection networks
May 22, 2023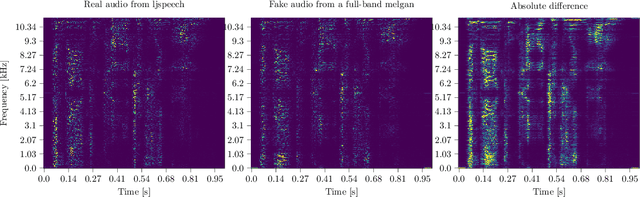
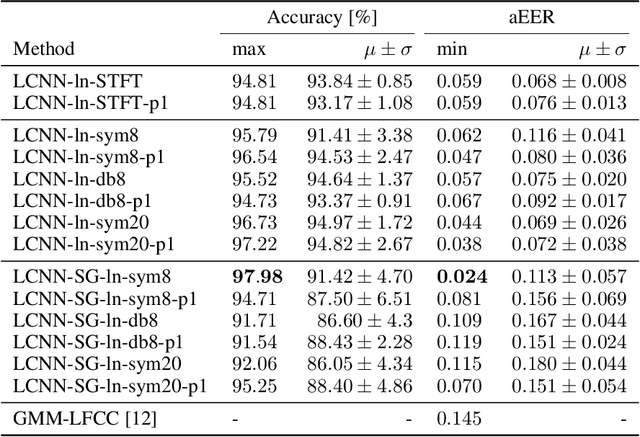
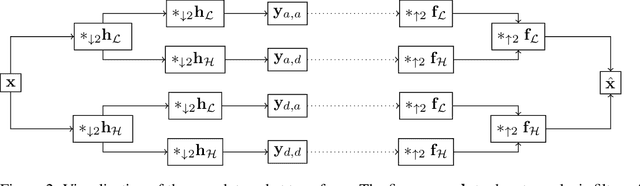
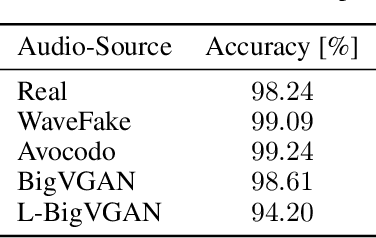
Today's generative neural networks allow the creation of high-quality synthetic speech at scale. While we welcome the creative use of this new technology, we must also recognize the risks. As synthetic speech is abused for both monetary and identity theft, we require a broad set of deep fake identification tools. Furthermore, previous work reported a limited ability of deep classifiers to generalize to unseen audio generators. By leveraging the wavelet-packet and short-time Fourier transform, we train excellent lightweight detectors that generalize. We report improved results on an extension of the WaveFake dataset. To account for the rapid progress in the field, we additionally consider samples drawn from the novel Avocodo and BigVGAN networks.
Approximating a RUM from Distributions on k-Slates
May 22, 2023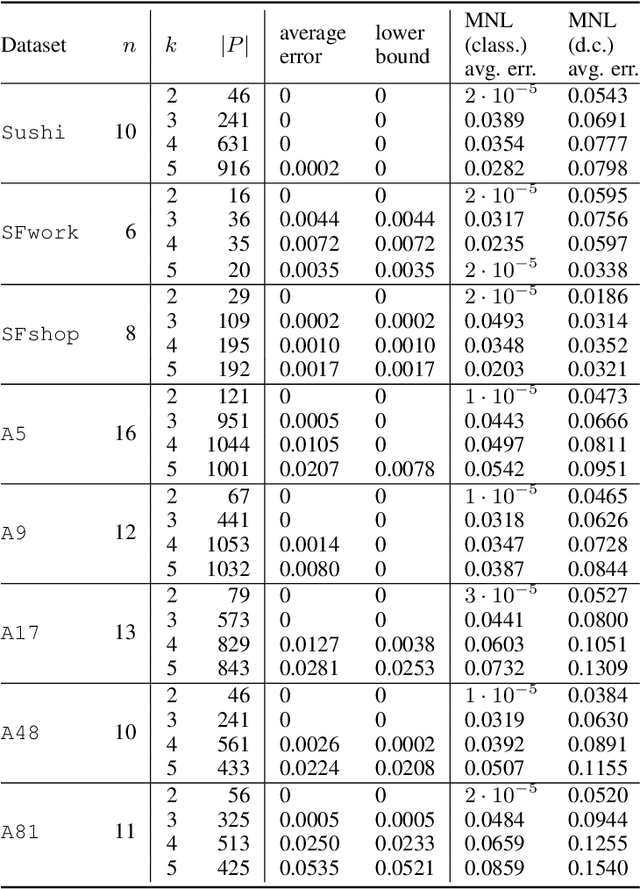
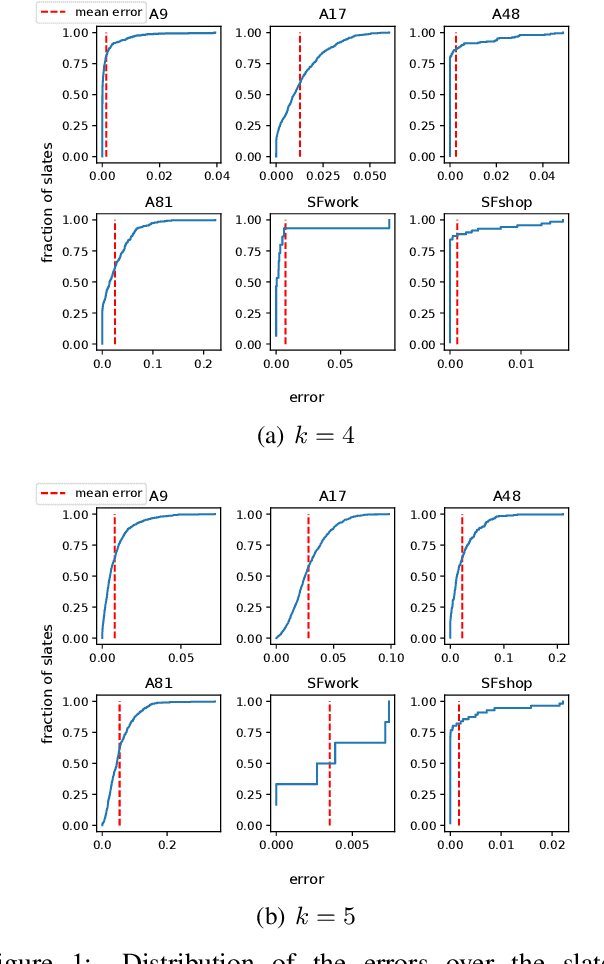
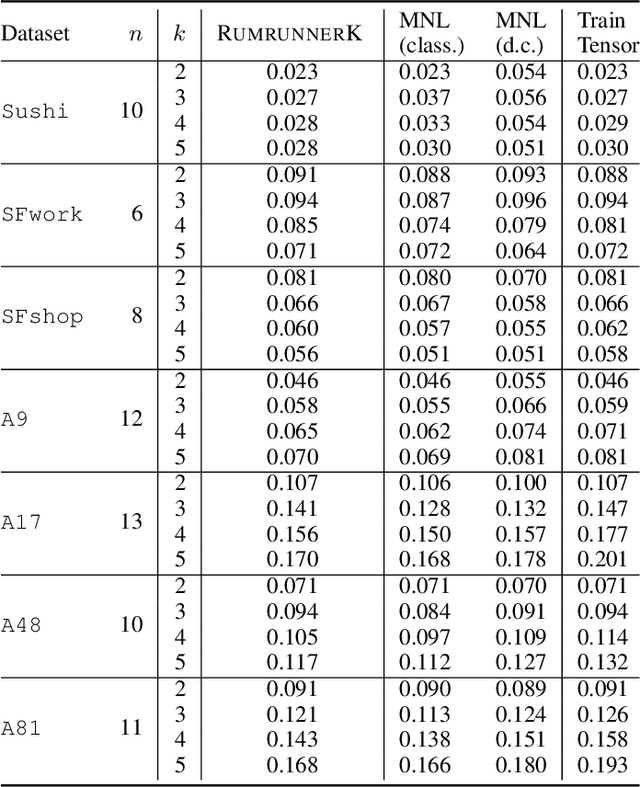
In this work we consider the problem of fitting Random Utility Models (RUMs) to user choices. Given the winner distributions of the subsets of size $k$ of a universe, we obtain a polynomial-time algorithm that finds the RUM that best approximates the given distribution on average. Our algorithm is based on a linear program that we solve using the ellipsoid method. Given that its corresponding separation oracle problem is NP-hard, we devise an approximate separation oracle that can be viewed as a generalization of the weighted feedback arc set problem to hypergraphs. Our theoretical result can also be made practical: we obtain a heuristic that is effective and scales to real-world datasets.
Trend Investigation of Biopotential Recording Front-End Channels for Invasive and Non-Invasive Applications
May 22, 2023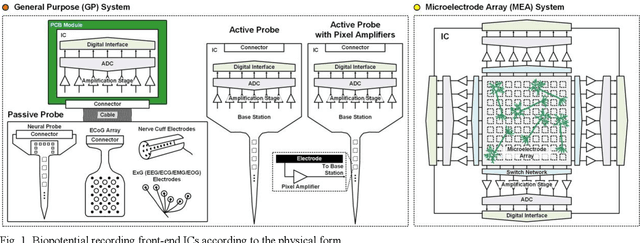
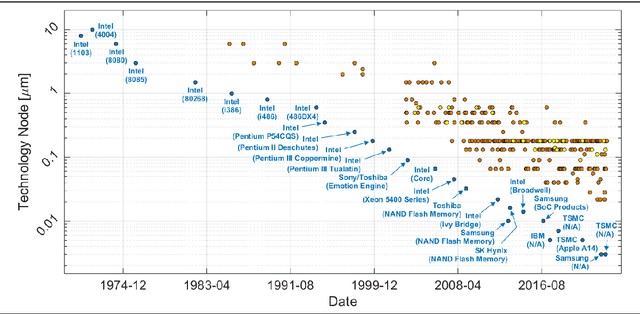
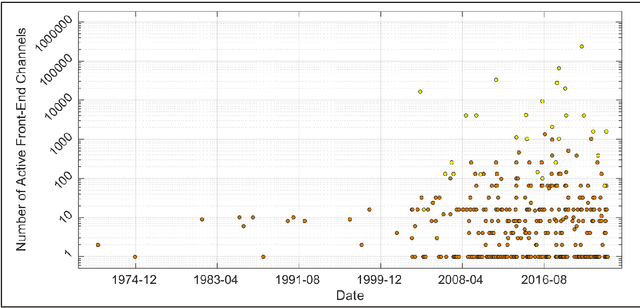
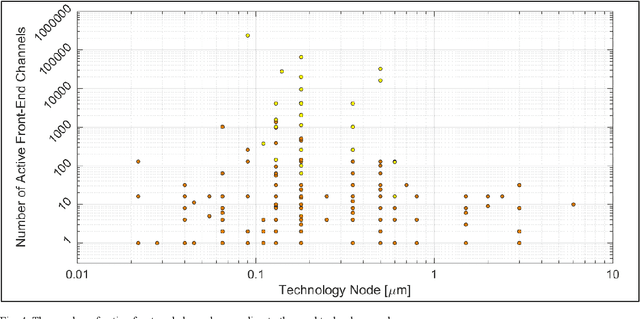
This paper presents the trend of biopotential recording front-end channels developed from the 1970s to the 2020s while describing a basic background on the front-end channel design. Only the front-end channels that conduct electrical recording invasively and non-invasively are addressed. The front-end channels are investigated in terms of technology node, number of channels, supply voltage, noise efficiency factor, and power efficiency factor. Also, multi-faceted comparisons are made to figure out the correlation between these five categories. In each category, the design trend is presented over time, and related circuit techniques are discussed. While addressing the characteristics of circuit techniques used to improve the channel performance, what needs to be improved is also suggested.
Generate then Select: Open-ended Visual Question Answering Guided by World Knowledge
May 30, 2023

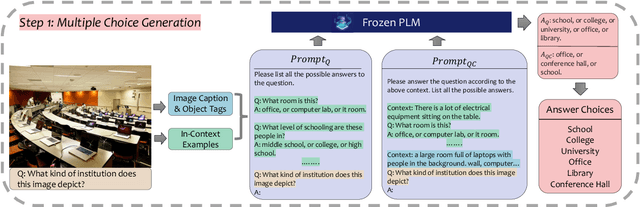
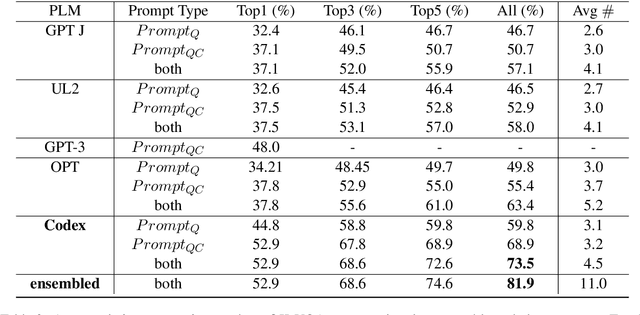
The open-ended Visual Question Answering (VQA) task requires AI models to jointly reason over visual and natural language inputs using world knowledge. Recently, pre-trained Language Models (PLM) such as GPT-3 have been applied to the task and shown to be powerful world knowledge sources. However, these methods suffer from low knowledge coverage caused by PLM bias -- the tendency to generate certain tokens over other tokens regardless of prompt changes, and high dependency on the PLM quality -- only models using GPT-3 can achieve the best result. To address the aforementioned challenges, we propose RASO: a new VQA pipeline that deploys a generate-then-select strategy guided by world knowledge for the first time. Rather than following the de facto standard to train a multi-modal model that directly generates the VQA answer, RASO first adopts PLM to generate all the possible answers, and then trains a lightweight answer selection model for the correct answer. As proved in our analysis, RASO expands the knowledge coverage from in-domain training data by a large margin. We provide extensive experimentation and show the effectiveness of our pipeline by advancing the state-of-the-art by 4.1% on OK-VQA, without additional computation cost. Code and models are released at http://cogcomp.org/page/publication_view/1010
Less Likely Brainstorming: Using Language Models to Generate Alternative Hypotheses
May 30, 2023


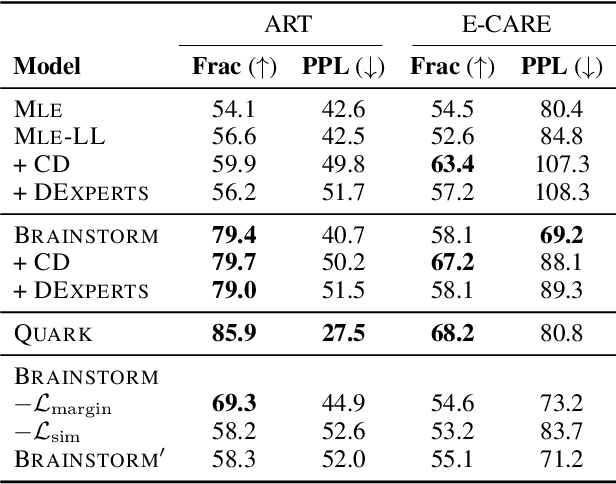
A human decision-maker benefits the most from an AI assistant that corrects for their biases. For problems such as generating interpretation of a radiology report given findings, a system predicting only highly likely outcomes may be less useful, where such outcomes are already obvious to the user. To alleviate biases in human decision-making, it is worth considering a broad differential diagnosis, going beyond the most likely options. We introduce a new task, "less likely brainstorming," that asks a model to generate outputs that humans think are relevant but less likely to happen. We explore the task in two settings: a brain MRI interpretation generation setting and an everyday commonsense reasoning setting. We found that a baseline approach of training with less likely hypotheses as targets generates outputs that humans evaluate as either likely or irrelevant nearly half of the time; standard MLE training is not effective. To tackle this problem, we propose a controlled text generation method that uses a novel contrastive learning strategy to encourage models to differentiate between generating likely and less likely outputs according to humans. We compare our method with several state-of-the-art controlled text generation models via automatic and human evaluations and show that our models' capability of generating less likely outputs is improved.