 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Differentially Private One Permutation Hashing and Bin-wise Consistent Weighted Sampling
Jun 13, 2023
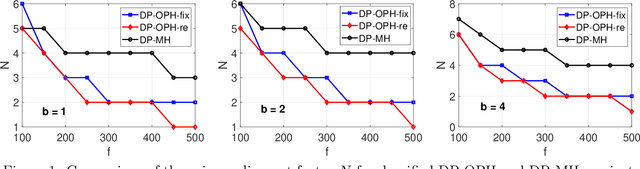
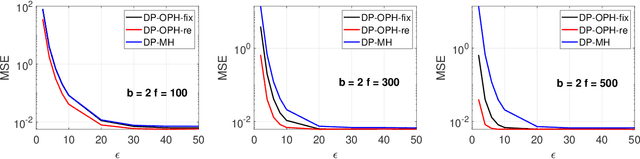
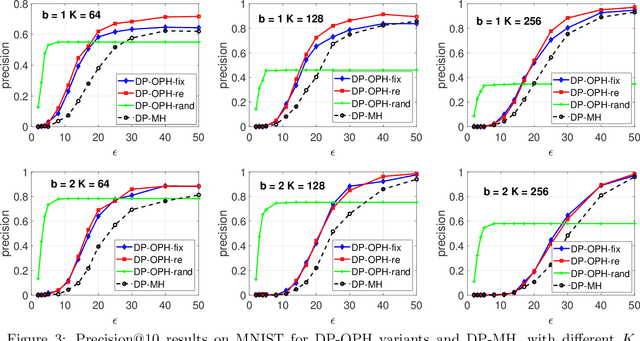
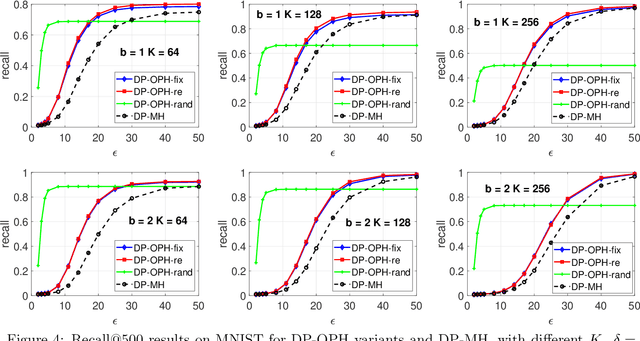
Minwise hashing (MinHash) is a standard algorithm widely used in the industry, for large-scale search and learning applications with the binary (0/1) Jaccard similarity. One common use of MinHash is for processing massive n-gram text representations so that practitioners do not have to materialize the original data (which would be prohibitive). Another popular use of MinHash is for building hash tables to enable sub-linear time approximate near neighbor (ANN) search. MinHash has also been used as a tool for building large-scale machine learning systems. The standard implementation of MinHash requires applying $K$ random permutations. In comparison, the method of one permutation hashing (OPH), is an efficient alternative of MinHash which splits the data vectors into $K$ bins and generates hash values within each bin. OPH is substantially more efficient and also more convenient to use. In this paper, we combine the differential privacy (DP) with OPH (as well as MinHash), to propose the DP-OPH framework with three variants: DP-OPH-fix, DP-OPH-re and DP-OPH-rand, depending on which densification strategy is adopted to deal with empty bins in OPH. A detailed roadmap to the algorithm design is presented along with the privacy analysis. An analytical comparison of our proposed DP-OPH methods with the DP minwise hashing (DP-MH) is provided to justify the advantage of DP-OPH. Experiments on similarity search confirm the merits of DP-OPH, and guide the choice of the proper variant in different practical scenarios. Our technique is also extended to bin-wise consistent weighted sampling (BCWS) to develop a new DP algorithm called DP-BCWS for non-binary data. Experiments on classification tasks demonstrate that DP-BCWS is able to achieve excellent utility at around $\epsilon = 5\sim 10$, where $\epsilon$ is the standard parameter in the language of $(\epsilon, \delta)$-DP.
ArtWhisperer: A Dataset for Characterizing Human-AI Interactions in Artistic Creations
Jun 13, 2023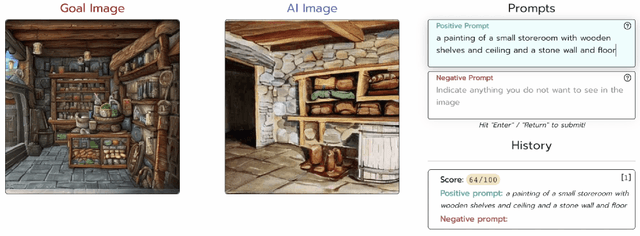
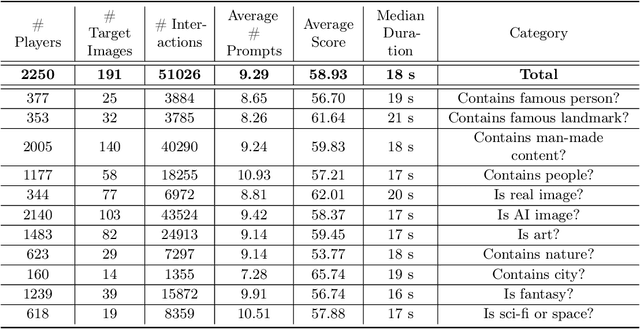
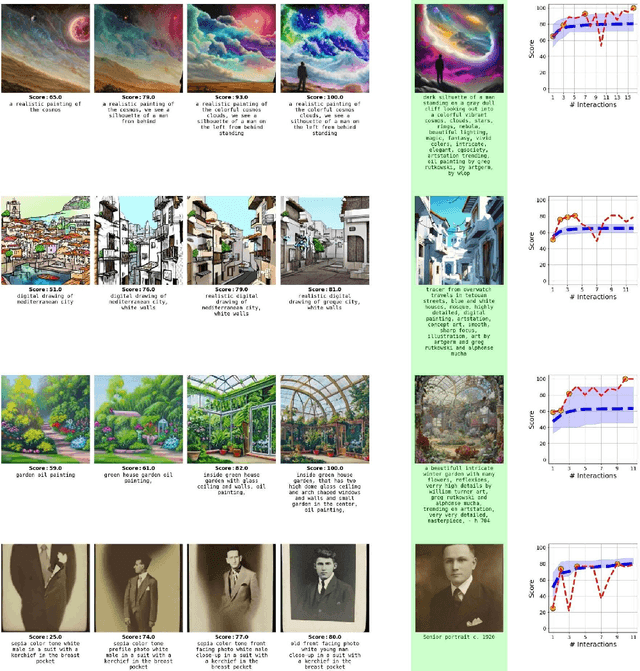
As generative AI becomes more prevalent, it is important to study how human users interact with such models. In this work, we investigate how people use text-to-image models to generate desired target images. To study this interaction, we created ArtWhisperer, an online game where users are given a target image and are tasked with iteratively finding a prompt that creates a similar-looking image as the target. Through this game, we recorded over 50,000 human-AI interactions; each interaction corresponds to one text prompt created by a user and the corresponding generated image. The majority of these are repeated interactions where a user iterates to find the best prompt for their target image, making this a unique sequential dataset for studying human-AI collaborations. In an initial analysis of this dataset, we identify several characteristics of prompt interactions and user strategies. People submit diverse prompts and are able to discover a variety of text descriptions that generate similar images. Interestingly, prompt diversity does not decrease as users find better prompts. We further propose to a new metric the study the steerability of AI using our dataset. We define steerability as the expected number of interactions required to adequately complete a task. We estimate this value by fitting a Markov chain for each target task and calculating the expected time to reach an adequate score in the Markov chain. We quantify and compare AI steerability across different types of target images and two different models, finding that images of cities and natural world images are more steerable than artistic and fantasy images. These findings provide insights into human-AI interaction behavior, present a concrete method of assessing AI steerability, and demonstrate the general utility of the ArtWhisperer dataset.
Practice with Graph-based ANN Algorithms on Sparse Data: Chi-square Two-tower model, HNSW, Sign Cauchy Projections
Jun 13, 2023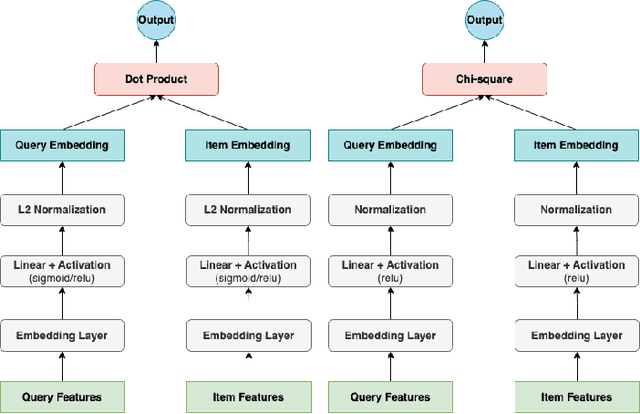
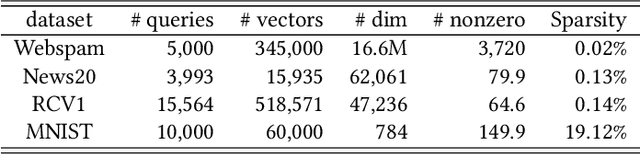
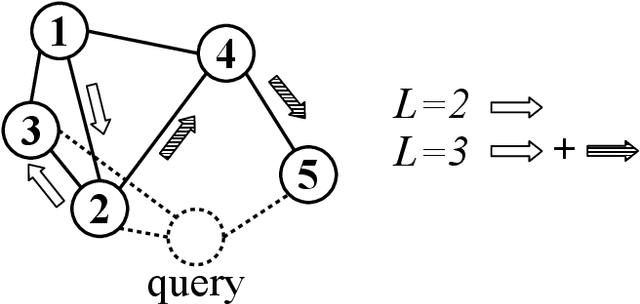
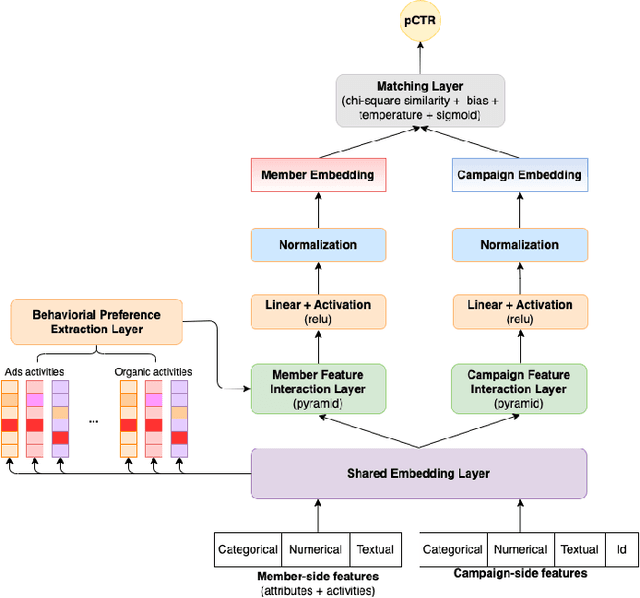
Sparse data are common. The traditional ``handcrafted'' features are often sparse. Embedding vectors from trained models can also be very sparse, for example, embeddings trained via the ``ReLu'' activation function. In this paper, we report our exploration of efficient search in sparse data with graph-based ANN algorithms (e.g., HNSW, or SONG which is the GPU version of HNSW), which are popular in industrial practice, e.g., search and ads (advertising). We experiment with the proprietary ads targeting application, as well as benchmark public datasets. For ads targeting, we train embeddings with the standard ``cosine two-tower'' model and we also develop the ``chi-square two-tower'' model. Both models produce (highly) sparse embeddings when they are integrated with the ``ReLu'' activation function. In EBR (embedding-based retrieval) applications, after we the embeddings are trained, the next crucial task is the approximate near neighbor (ANN) search for serving. While there are many ANN algorithms we can choose from, in this study, we focus on the graph-based ANN algorithm (e.g., HNSW-type). Sparse embeddings should help improve the efficiency of EBR. One benefit is the reduced memory cost for the embeddings. The other obvious benefit is the reduced computational time for evaluating similarities, because, for graph-based ANN algorithms such as HNSW, computing similarities is often the dominating cost. In addition to the effort on leveraging data sparsity for storage and computation, we also integrate ``sign cauchy random projections'' (SignCRP) to hash vectors to bits, to further reduce the memory cost and speed up the ANN search. In NIPS'13, SignCRP was proposed to hash the chi-square similarity, which is a well-adopted nonlinear kernel in NLP and computer vision. Therefore, the chi-square two-tower model, SignCRP, and HNSW are now tightly integrated.
Blackwell's Approachability with Time-Dependent Outcome Functions and Dot Products. Application to the Big Match
Mar 09, 2023Blackwell's approachability is a very general sequential decision framework where a Decision Maker obtains vector-valued outcomes, and aims at the convergence of the average outcome to a given "target" set. Blackwell gave a sufficient condition for the decision maker having a strategy guaranteeing such a convergence against an adversarial environment, as well as what we now call the Blackwell's algorithm, which then ensures convergence. Blackwell's approachability has since been applied to numerous problems, in online learning and game theory, in particular. We extend this framework by allowing the outcome function and the dot product to be time-dependent. We establish a general guarantee for the natural extension to this framework of Blackwell's algorithm. In the case where the target set is an orthant, we present a family of time-dependent dot products which yields different convergence speeds for each coordinate of the average outcome. We apply this framework to the Big Match (one of the most important toy examples of stochastic games) where an $\epsilon$-uniformly optimal strategy for Player I is given by Blackwell's algorithm in a well-chosen auxiliary approachability problem.
ERSAM: Neural Architecture Search For Energy-Efficient and Real-Time Social Ambiance Measurement
Mar 24, 2023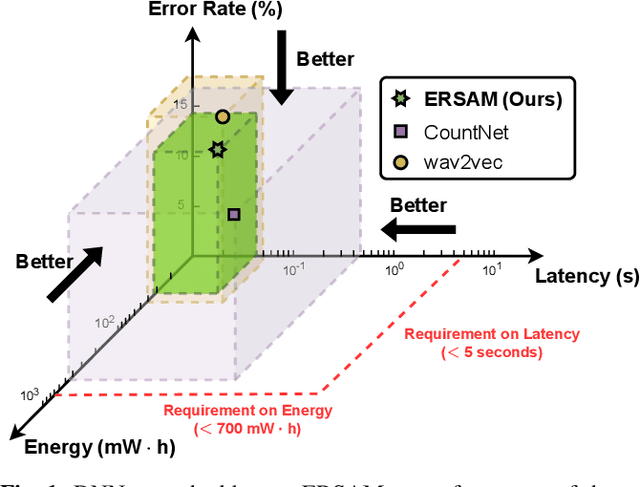
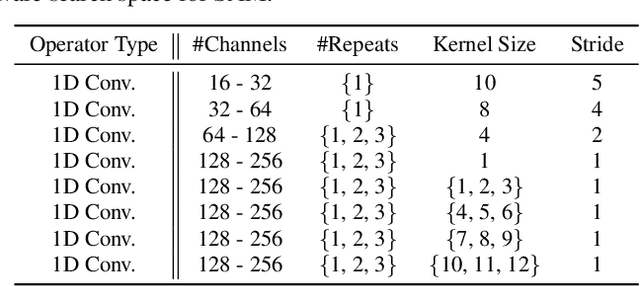
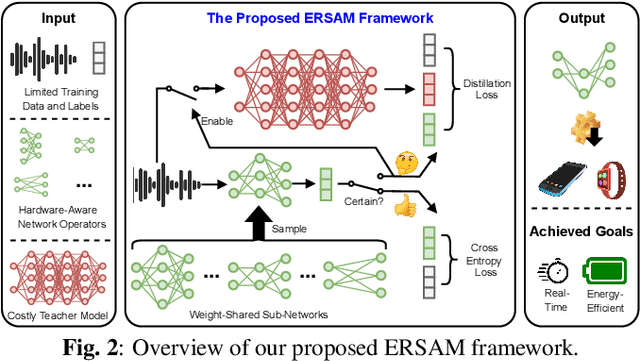

Social ambiance describes the context in which social interactions happen, and can be measured using speech audio by counting the number of concurrent speakers. This measurement has enabled various mental health tracking and human-centric IoT applications. While on-device Socal Ambiance Measure (SAM) is highly desirable to ensure user privacy and thus facilitate wide adoption of the aforementioned applications, the required computational complexity of state-of-the-art deep neural networks (DNNs) powered SAM solutions stands at odds with the often constrained resources on mobile devices. Furthermore, only limited labeled data is available or practical when it comes to SAM under clinical settings due to various privacy constraints and the required human effort, further challenging the achievable accuracy of on-device SAM solutions. To this end, we propose a dedicated neural architecture search framework for Energy-efficient and Real-time SAM (ERSAM). Specifically, our ERSAM framework can automatically search for DNNs that push forward the achievable accuracy vs. hardware efficiency frontier of mobile SAM solutions. For example, ERSAM-delivered DNNs only consume 40 mW x 12 h energy and 0.05 seconds processing latency for a 5 seconds audio segment on a Pixel 3 phone, while only achieving an error rate of 14.3% on a social ambiance dataset generated by LibriSpeech. We can expect that our ERSAM framework can pave the way for ubiquitous on-device SAM solutions which are in growing demand.
PathRTM: Real-time prediction of KI-67 and tumor-infiltrated lymphocytes
Apr 23, 2023
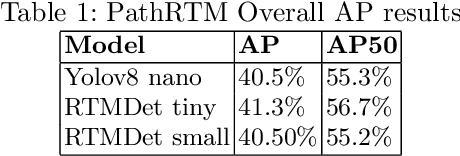
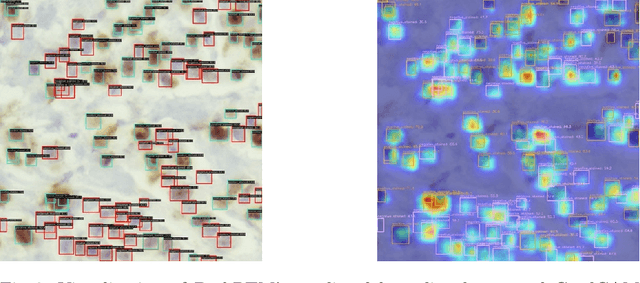

In this paper, we introduce PathRTM, a novel deep neural network detector based on RTMDet, for automated KI-67 proliferation and tumor-infiltrated lymphocyte estimation. KI-67 proliferation and tumor-infiltrated lymphocyte estimation play a crucial role in cancer diagnosis and treatment. PathRTM is an extension of the PathoNet work, which uses single pixel keypoints for within each cell. We demonstrate that PathRTM, with higher-level supervision in the form of bounding box labels generated automatically from the keypoints using NuClick, can significantly improve KI-67 proliferation and tumorinfiltrated lymphocyte estimation. Experiments on our custom dataset show that PathRTM achieves state-of-the-art performance in KI-67 immunopositive, immunonegative, and lymphocyte detection, with an average precision (AP) of 41.3%. Our results suggest that PathRTM is a promising approach for accurate KI-67 proliferation and tumor-infiltrated lymphocyte estimation, offering annotation efficiency, accurate predictive capabilities, and improved runtime. The method also enables estimation of cell sizes of interest, which was previously unavailable, through the bounding box predictions.
NeMO: Neural Map Growing System for Spatiotemporal Fusion in Bird's-Eye-View and BDD-Map Benchmark
Jun 07, 2023
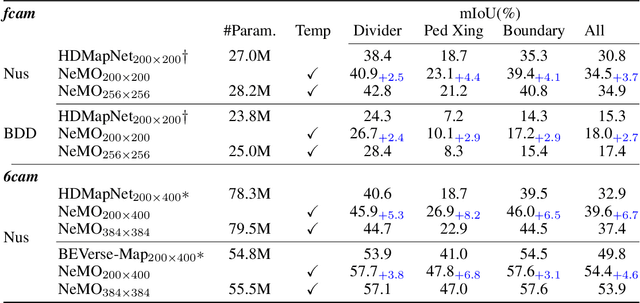
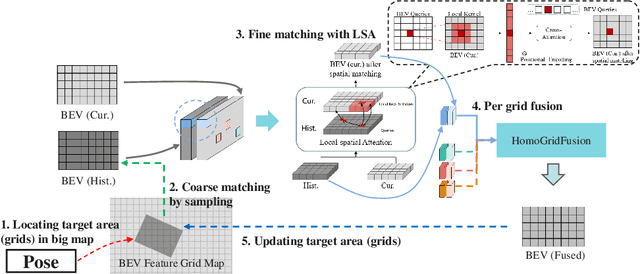
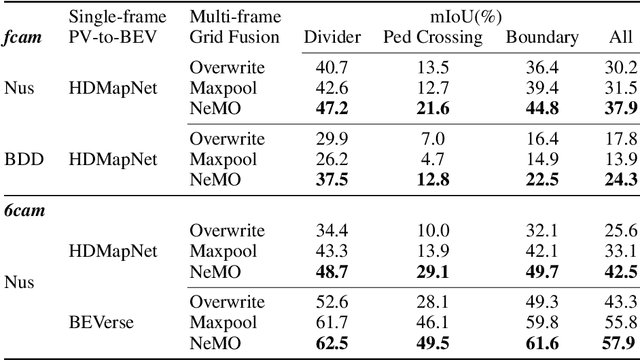
Vision-centric Bird's-Eye View (BEV) representation is essential for autonomous driving systems (ADS). Multi-frame temporal fusion which leverages historical information has been demonstrated to provide more comprehensive perception results. While most research focuses on ego-centric maps of fixed settings, long-range local map generation remains less explored. This work outlines a new paradigm, named NeMO, for generating local maps through the utilization of a readable and writable big map, a learning-based fusion module, and an interaction mechanism between the two. With an assumption that the feature distribution of all BEV grids follows an identical pattern, we adopt a shared-weight neural network for all grids to update the big map. This paradigm supports the fusion of longer time series and the generation of long-range BEV local maps. Furthermore, we release BDD-Map, a BDD100K-based dataset incorporating map element annotations, including lane lines, boundaries, and pedestrian crossing. Experiments on the NuScenes and BDD-Map datasets demonstrate that NeMO outperforms state-of-the-art map segmentation methods. We also provide a new scene-level BEV map evaluation setting along with the corresponding baseline for a more comprehensive comparison.
Case Studies on X-Ray Imaging, MRI and Nuclear Imaging
Jun 07, 2023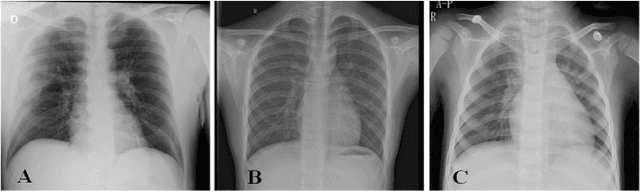
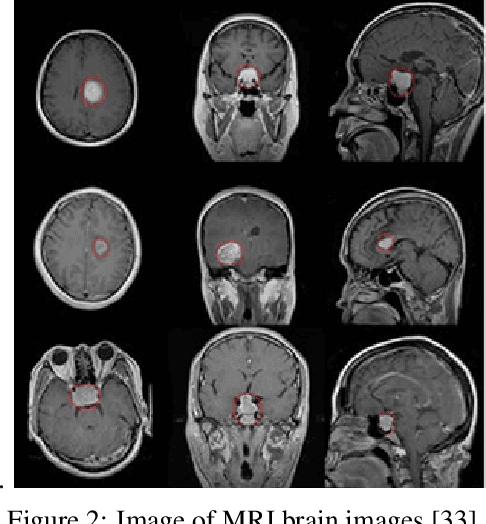
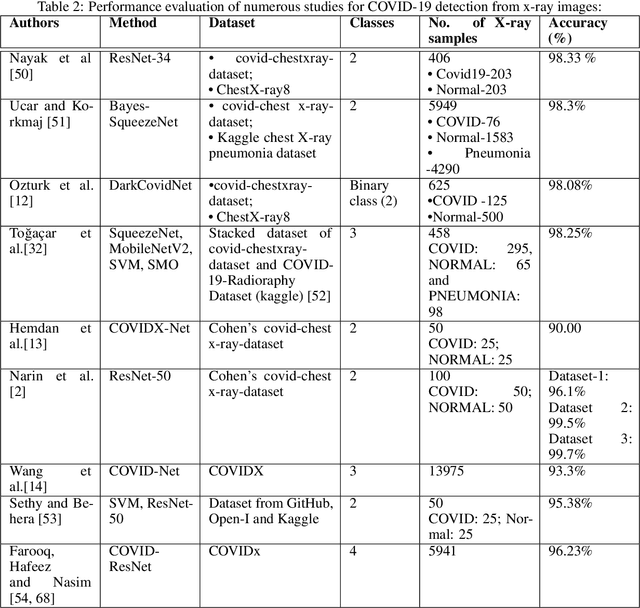
The field of medical imaging is an essential aspect of the medical sciences, involving various forms of radiation to capture images of the internal tissues and organs of the body. These images provide vital information for clinical diagnosis, and in this chapter, we will explore the use of X-ray, MRI, and nuclear imaging in detecting severe illnesses. However, manual evaluation and storage of these images can be a challenging and time-consuming process. To address this issue, artificial intelligence (AI)-based techniques, particularly deep learning (DL), have become increasingly popular for systematic feature extraction and classification from imaging modalities, thereby aiding doctors in making rapid and accurate diagnoses. In this review study, we will focus on how AI-based approaches, particularly the use of Convolutional Neural Networks (CNN), can assist in disease detection through medical imaging technology. CNN is a commonly used approach for image analysis due to its ability to extract features from raw input images, and as such, will be the primary area of discussion in this study. Therefore, we have considered CNN as our discussion area in this study to diagnose ailments using medical imaging technology.
A Linearly Convergent GAN Inversion-based Algorithm for Reverse Engineering of Deceptions
Jun 07, 2023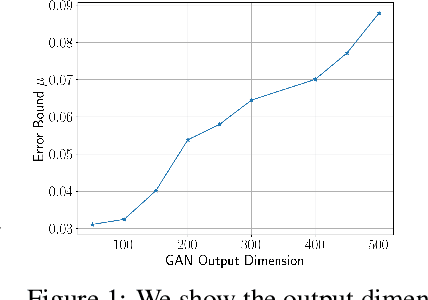

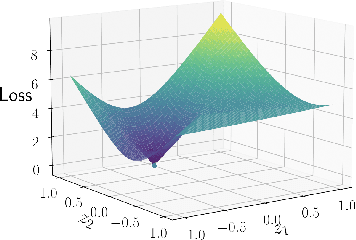
An important aspect of developing reliable deep learning systems is devising strategies that make these systems robust to adversarial attacks. There is a long line of work that focuses on developing defenses against these attacks, but recently, researchers have began to study ways to reverse engineer the attack process. This allows us to not only defend against several attack models, but also classify the threat model. However, there is still a lack of theoretical guarantees for the reverse engineering process. Current approaches that give any guarantees are based on the assumption that the data lies in a union of linear subspaces, which is not a valid assumption for more complex datasets. In this paper, we build on prior work and propose a novel framework for reverse engineering of deceptions which supposes that the clean data lies in the range of a GAN. To classify the signal and attack, we jointly solve a GAN inversion problem and a block-sparse recovery problem. For the first time in the literature, we provide deterministic linear convergence guarantees for this problem. We also empirically demonstrate the merits of the proposed approach on several nonlinear datasets as compared to state-of-the-art methods.
Vid2Act: Activate Offline Videos for Visual RL
Jun 07, 2023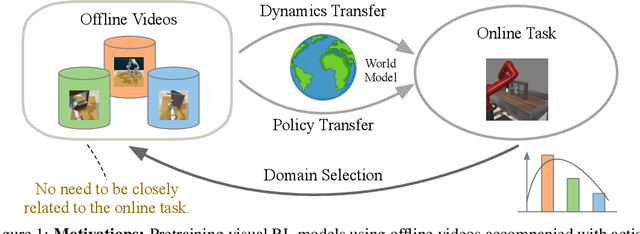
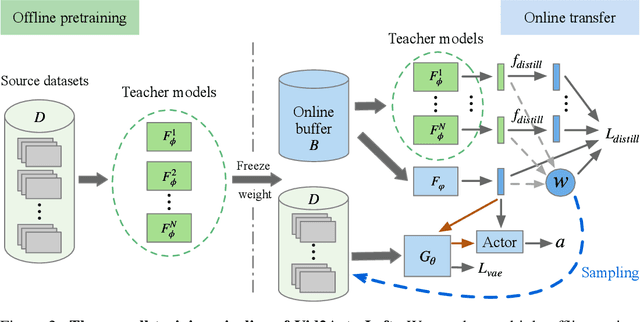
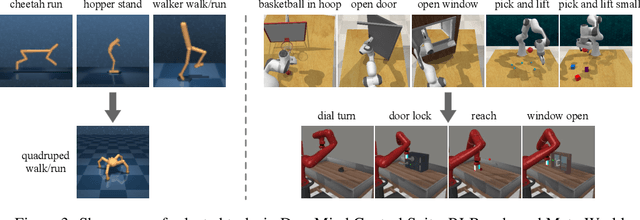
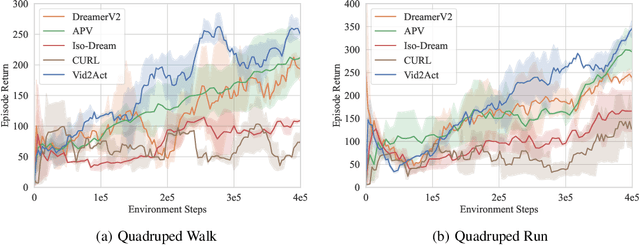
Pretraining RL models on offline video datasets is a promising way to improve their training efficiency in online tasks, but challenging due to the inherent mismatch in tasks, dynamics, and behaviors across domains. A recent model, APV, sidesteps the accompanied action records in offline datasets and instead focuses on pretraining a task-irrelevant, action-free world model within the source domains. We present Vid2Act, a model-based RL method that learns to transfer valuable action-conditioned dynamics and potentially useful action demonstrations from offline to online settings. The main idea is to use the world models not only as simulators for behavior learning but also as tools to measure the domain relevance for both dynamics representation transfer and policy transfer. Specifically, we train the world models to generate a set of time-varying task similarities using a domain-selective knowledge distillation loss. These similarities serve two purposes: (i) adaptively transferring the most useful source knowledge to facilitate dynamics learning, and (ii) learning to replay the most relevant source actions to guide the target policy. We demonstrate the advantages of Vid2Act over the action-free visual RL pretraining method in both Meta-World and DeepMind Control Suite.