 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Instantaneous Wireless Robotic Node Localization Using Collaborative Direction of Arrival
Jul 04, 2023
Localizing mobile robotic nodes in indoor and GPS-denied environments is a complex problem, particularly in dynamic, unstructured scenarios where traditional cameras and LIDAR-based sensing and localization modalities may fail. Alternatively, wireless signal-based localization has been extensively studied in the literature yet primarily focuses on fingerprinting and feature-matching paradigms, requiring dedicated environment-specific offline data collection. We propose an online robot localization algorithm enabled by collaborative wireless sensor nodes to remedy these limitations. Our approach's core novelty lies in obtaining the Collaborative Direction of Arrival (CDOA) of wireless signals by exploiting the geometric features and collaboration between wireless nodes. The CDOA is combined with the Expectation Maximization (EM) and Particle Filter (PF) algorithms to calculate the Gaussian probability of the node's location with high efficiency and accuracy. The algorithm relies on RSSI-only data, making it ubiquitous to resource-constrained devices. We theoretically analyze the approach and extensively validate the proposed method's consistency, accuracy, and computational efficiency in simulations, real-world public datasets, as well as real robot demonstrations. The results validate the method's real-time computational capability and demonstrate considerably-high centimeter-level localization accuracy, outperforming relevant state-of-the-art localization approaches.
Complex Graph Laplacian Regularizer for Inferencing Grid States
Jul 04, 2023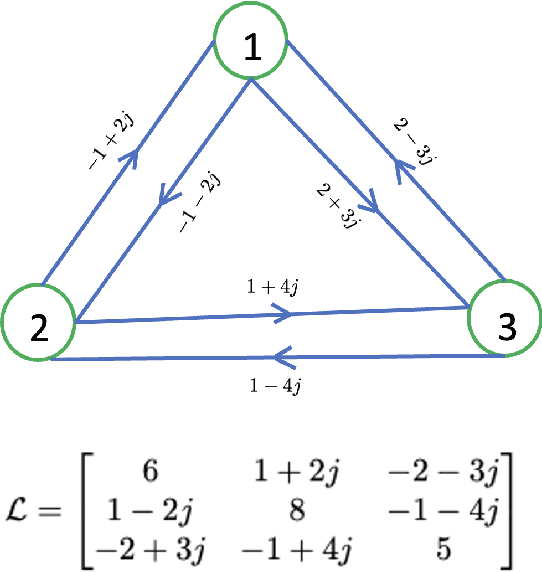
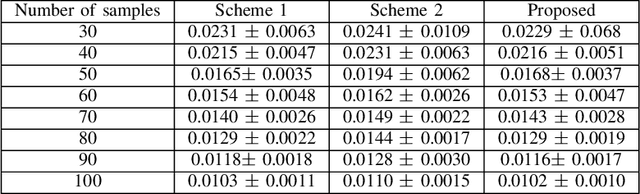
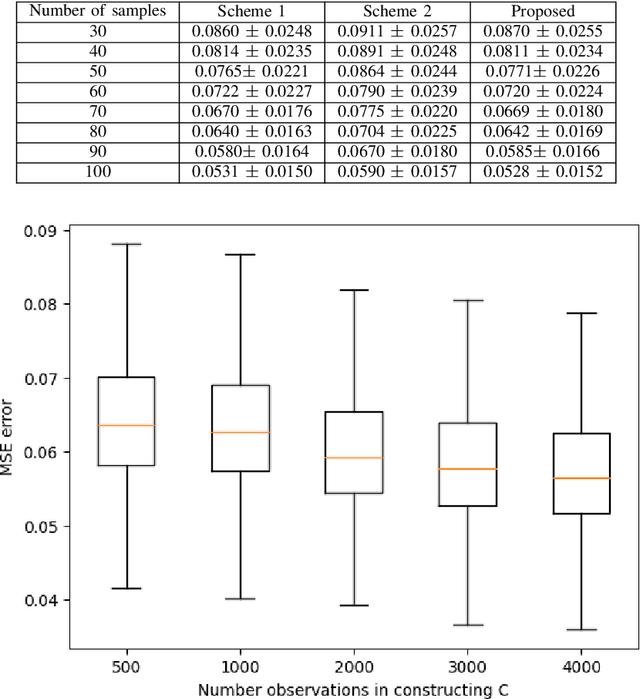
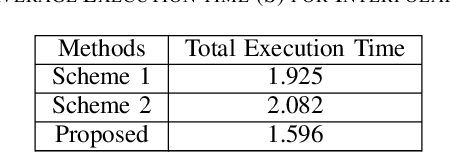
In order to maintain stable grid operations, system monitoring and control processes require the computation of grid states (e.g. voltage magnitude and angles) at high granularity. It is necessary to infer these grid states from measurements generated by a limited number of sensors like phasor measurement units (PMUs) that can be subjected to delays and losses due to channel artefacts, and/or adversarial attacks (e.g. denial of service, jamming, etc.). We propose a novel graph signal processing (GSP) based algorithm to interpolate states of the entire grid from observations of a small number of grid measurements. It is a two-stage process, where first an underlying Hermitian graph is learnt empirically from existing grid datasets. Then, the graph is used to interpolate missing grid signal samples in linear time. With our proposal, we can effectively reconstruct grid signals with significantly smaller number of observations when compared to existing traditional approaches (e.g. state estimation). In contrast to existing GSP approaches, we do not require knowledge of the underlying grid structure and parameters and are able to guarantee fast spectral optimization. We demonstrate the computational efficacy and accuracy of our proposal via practical studies conducted on the IEEE 118 bus system.
CardiGraphormer: Unveiling the Power of Self-Supervised Learning in Revolutionizing Drug Discovery
Jul 04, 2023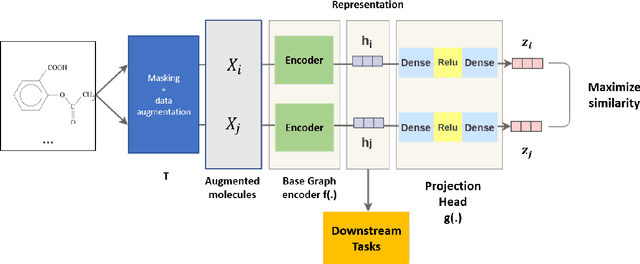
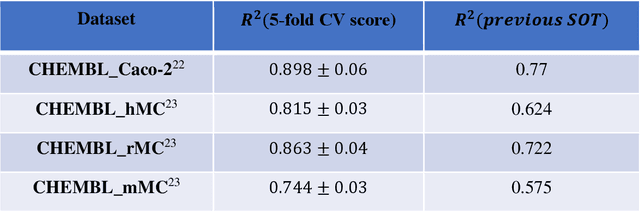
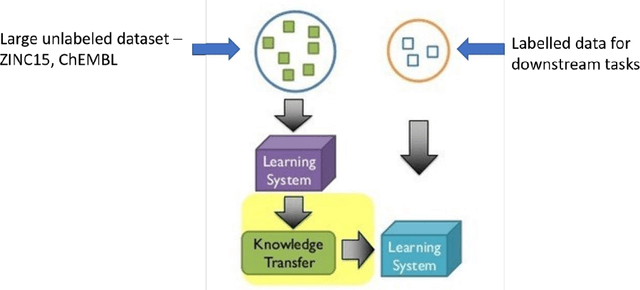
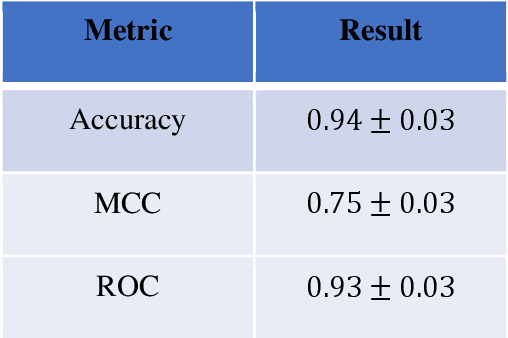
In the expansive realm of drug discovery, with approximately 15,000 known drugs and only around 4,200 approved, the combinatorial nature of the chemical space presents a formidable challenge. While Artificial Intelligence (AI) has emerged as a powerful ally, traditional AI frameworks face significant hurdles. This manuscript introduces CardiGraphormer, a groundbreaking approach that synergizes self-supervised learning (SSL), Graph Neural Networks (GNNs), and Cardinality Preserving Attention to revolutionize drug discovery. CardiGraphormer, a novel combination of Graphormer and Cardinality Preserving Attention, leverages SSL to learn potent molecular representations and employs GNNs to extract molecular fingerprints, enhancing predictive performance and interpretability while reducing computation time. It excels in handling complex data like molecular structures and performs tasks associated with nodes, pairs of nodes, subgraphs, or entire graph structures. CardiGraphormer's potential applications in drug discovery and drug interactions are vast, from identifying new drug targets to predicting drug-to-drug interactions and enabling novel drug discovery. This innovative approach provides an AI-enhanced methodology in drug development, utilizing SSL combined with GNNs to overcome existing limitations and pave the way for a richer exploration of the vast combinatorial chemical space in drug discovery.
Utilizing ChatGPT Generated Data to Retrieve Depression Symptoms from Social Media
Jul 06, 2023In this work, we present the contribution of the BLUE team in the eRisk Lab task on searching for symptoms of depression. The task consists of retrieving and ranking Reddit social media sentences that convey symptoms of depression from the BDI-II questionnaire. Given that synthetic data provided by LLMs have been proven to be a reliable method for augmenting data and fine-tuning downstream models, we chose to generate synthetic data using ChatGPT for each of the symptoms of the BDI-II questionnaire. We designed a prompt such that the generated data contains more richness and semantic diversity than the BDI-II responses for each question and, at the same time, contains emotional and anecdotal experiences that are specific to the more intimate way of sharing experiences on Reddit. We perform semantic search and rank the sentences' relevance to the BDI-II symptoms by cosine similarity. We used two state-of-the-art transformer-based models (MentalRoBERTa and a variant of MPNet) for embedding the social media posts, the original and generated responses of the BDI-II. Our results show that using sentence embeddings from a model designed for semantic search outperforms the approach using embeddings from a model pre-trained on mental health data. Furthermore, the generated synthetic data were proved too specific for this task, the approach simply relying on the BDI-II responses had the best performance.
Fourier-Net+: Leveraging Band-Limited Representation for Efficient 3D Medical Image Registration
Jul 06, 2023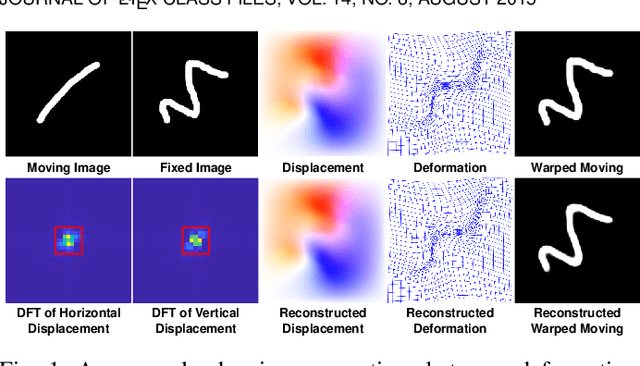
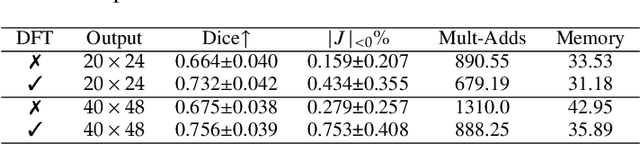
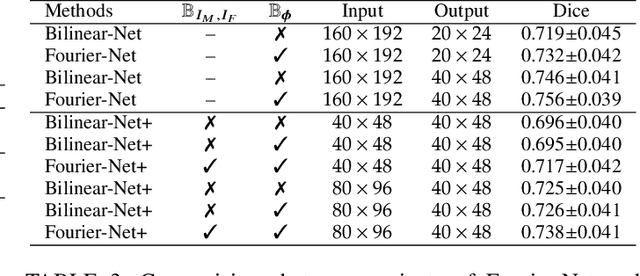
U-Net style networks are commonly utilized in unsupervised image registration to predict dense displacement fields, which for high-resolution volumetric image data is a resource-intensive and time-consuming task. To tackle this challenge, we first propose Fourier-Net, which replaces the costly U-Net style expansive path with a parameter-free model-driven decoder. Instead of directly predicting a full-resolution displacement field, our Fourier-Net learns a low-dimensional representation of the displacement field in the band-limited Fourier domain which our model-driven decoder converts to a full-resolution displacement field in the spatial domain. Expanding upon Fourier-Net, we then introduce Fourier-Net+, which additionally takes the band-limited spatial representation of the images as input and further reduces the number of convolutional layers in the U-Net style network's contracting path. Finally, to enhance the registration performance, we propose a cascaded version of Fourier-Net+. We evaluate our proposed methods on three datasets, on which our proposed Fourier-Net and its variants achieve comparable results with current state-of-the art methods, while exhibiting faster inference speeds, lower memory footprint, and fewer multiply-add operations. With such small computational cost, our Fourier-Net+ enables the efficient training of large-scale 3D registration on low-VRAM GPUs. Our code is publicly available at \url{https://github.com/xi-jia/Fourier-Net}.
Recursive Algorithmic Reasoning
Jul 01, 2023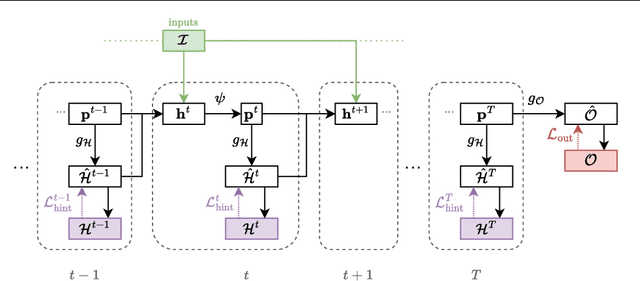

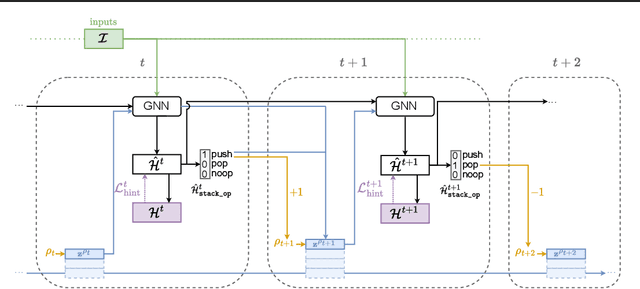
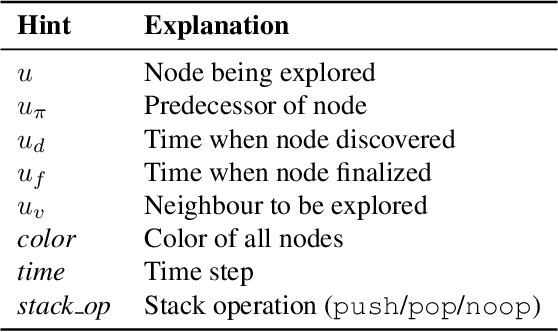
Learning models that execute algorithms can enable us to address a key problem in deep learning: generalizing to out-of-distribution data. However, neural networks are currently unable to execute recursive algorithms because they do not have arbitrarily large memory to store and recall state. To address this, we (1) propose a way to augment graph neural networks (GNNs) with a stack, and (2) develop an approach for capturing intermediate algorithm trajectories that improves algorithmic alignment with recursive algorithms over previous methods. The stack allows the network to learn to store and recall a portion of the state of the network at a particular time, analogous to the action of a call stack in a recursive algorithm. This augmentation permits the network to reason recursively. We empirically demonstrate that our proposals significantly improve generalization to larger input graphs over prior work on depth-first search (DFS).
Natural Language Deduction with Incomplete Information
Jul 05, 2023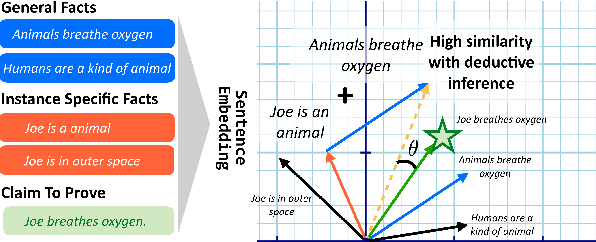
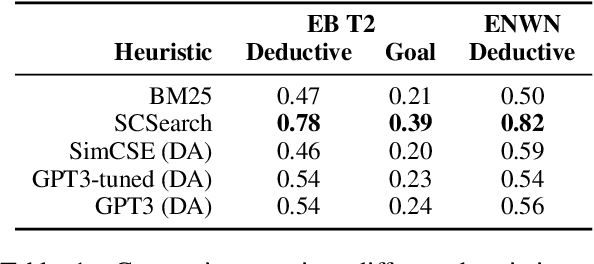
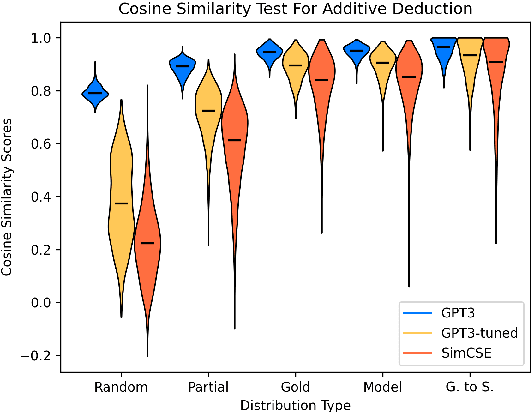
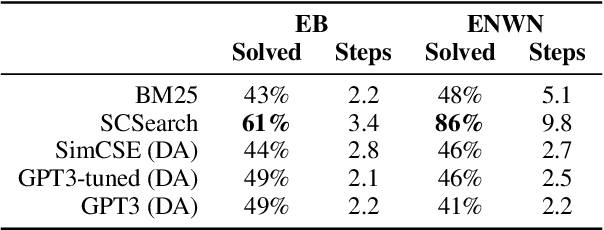
A growing body of work studies how to answer a question or verify a claim by generating a natural language "proof": a chain of deductive inferences yielding the answer based on a set of premises. However, these methods can only make sound deductions when they follow from evidence that is given. We propose a new system that can handle the underspecified setting where not all premises are stated at the outset; that is, additional assumptions need to be materialized to prove a claim. By using a natural language generation model to abductively infer a premise given another premise and a conclusion, we can impute missing pieces of evidence needed for the conclusion to be true. Our system searches over two fringes in a bidirectional fashion, interleaving deductive (forward-chaining) and abductive (backward-chaining) generation steps. We sample multiple possible outputs for each step to achieve coverage of the search space, at the same time ensuring correctness by filtering low-quality generations with a round-trip validation procedure. Results on a modified version of the EntailmentBank dataset and a new dataset called Everyday Norms: Why Not? show that abductive generation with validation can recover premises across in- and out-of-domain settings
Prompting Diffusion Representations for Cross-Domain Semantic Segmentation
Jul 05, 2023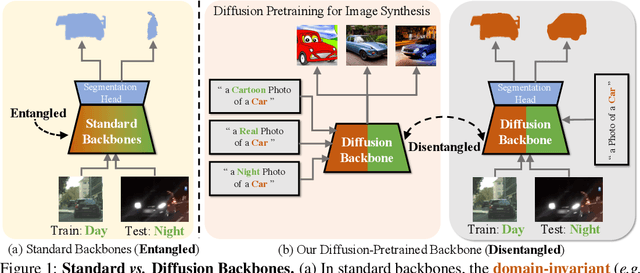

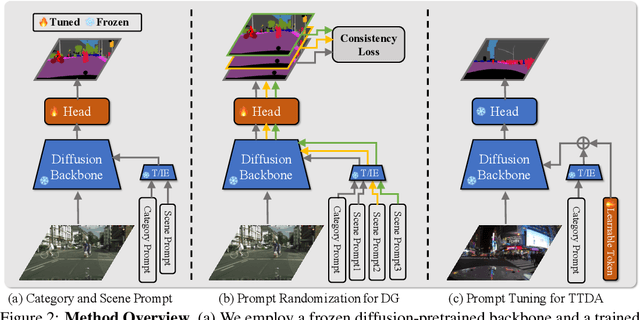
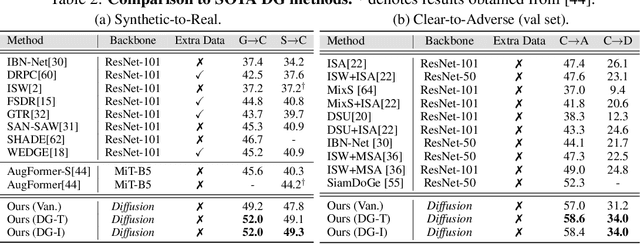
While originally designed for image generation, diffusion models have recently shown to provide excellent pretrained feature representations for semantic segmentation. Intrigued by this result, we set out to explore how well diffusion-pretrained representations generalize to new domains, a crucial ability for any representation. We find that diffusion-pretraining achieves extraordinary domain generalization results for semantic segmentation, outperforming both supervised and self-supervised backbone networks. Motivated by this, we investigate how to utilize the model's unique ability of taking an input prompt, in order to further enhance its cross-domain performance. We introduce a scene prompt and a prompt randomization strategy to help further disentangle the domain-invariant information when training the segmentation head. Moreover, we propose a simple but highly effective approach for test-time domain adaptation, based on learning a scene prompt on the target domain in an unsupervised manner. Extensive experiments conducted on four synthetic-to-real and clear-to-adverse weather benchmarks demonstrate the effectiveness of our approaches. Without resorting to any complex techniques, such as image translation, augmentation, or rare-class sampling, we set a new state-of-the-art on all benchmarks. Our implementation will be publicly available at \url{https://github.com/ETHRuiGong/PTDiffSeg}.
Phase Unwrapping of Color Doppler Echocardiography using Deep Learning
Jul 05, 2023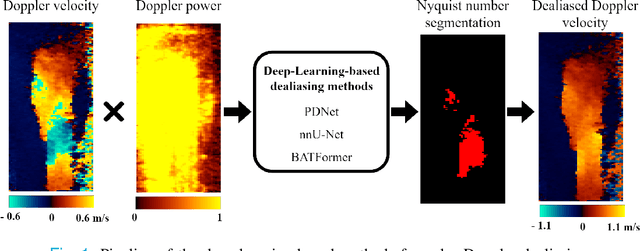
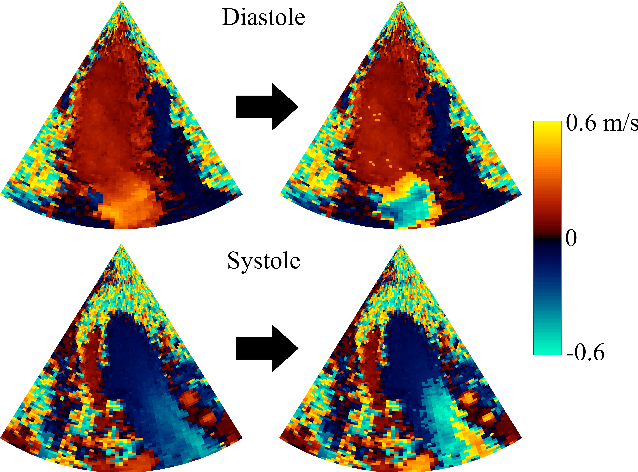

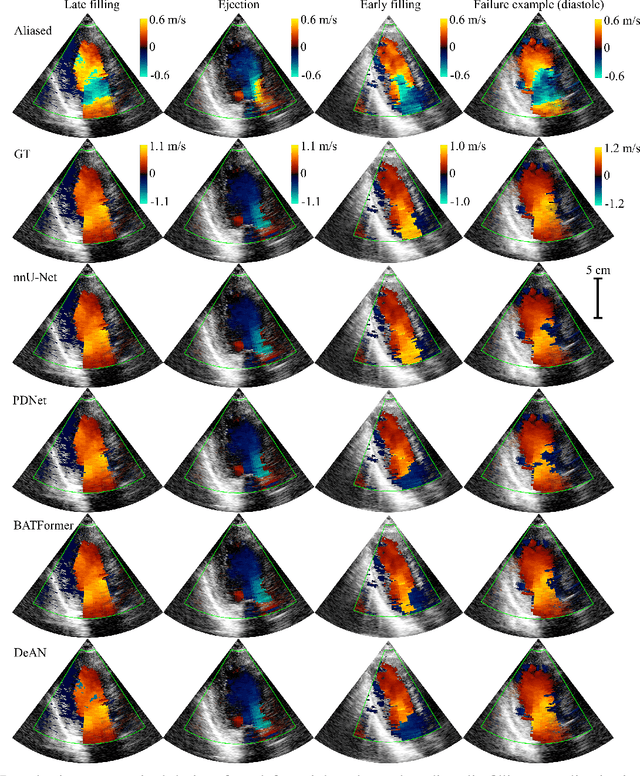
Color Doppler echocardiography is a widely used non-invasive imaging modality that provides real-time information about the intracardiac blood flow. In an apical long-axis view of the left ventricle, color Doppler is subject to phase wrapping, or aliasing, especially during cardiac filling and ejection. When setting up quantitative methods based on color Doppler, it is necessary to correct this wrapping artifact. We developed an unfolded primal-dual network to unwrap (dealias) color Doppler echocardiographic images and compared its effectiveness against two state-of-the-art segmentation approaches based on nnU-Net and transformer models. We trained and evaluated the performance of each method on an in-house dataset and found that the nnU-Net-based method provided the best dealiased results, followed by the primal-dual approach and the transformer-based technique. Noteworthy, the primal-dual network, which had significantly fewer trainable parameters, performed competitively with respect to the other two methods, demonstrating the high potential of deep unfolding methods. Our results suggest that deep learning-based methods can effectively remove aliasing artifacts in color Doppler echocardiographic images, outperforming DeAN, a state-of-the-art semi-automatic technique. Overall, our results show that deep learning-based methods have the potential to effectively preprocess color Doppler images for downstream quantitative analysis.
Rethinking Multiple Instance Learning for Whole Slide Image Classification: A Good Instance Classifier is All You Need
Jul 05, 2023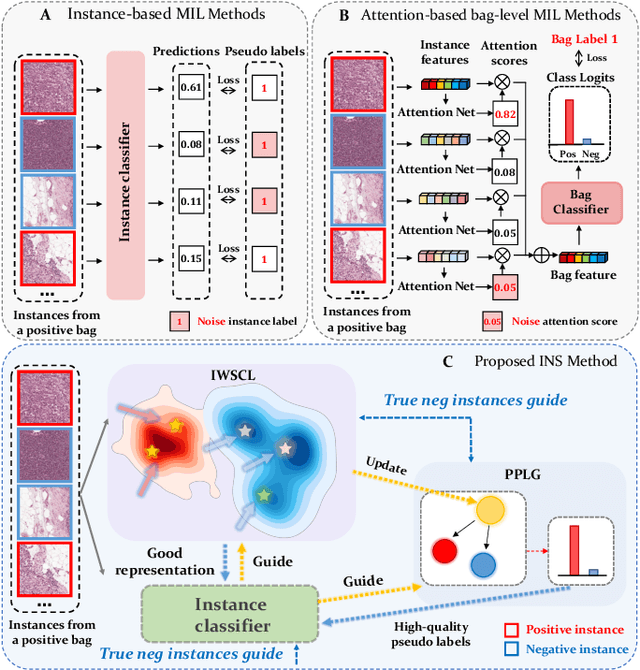
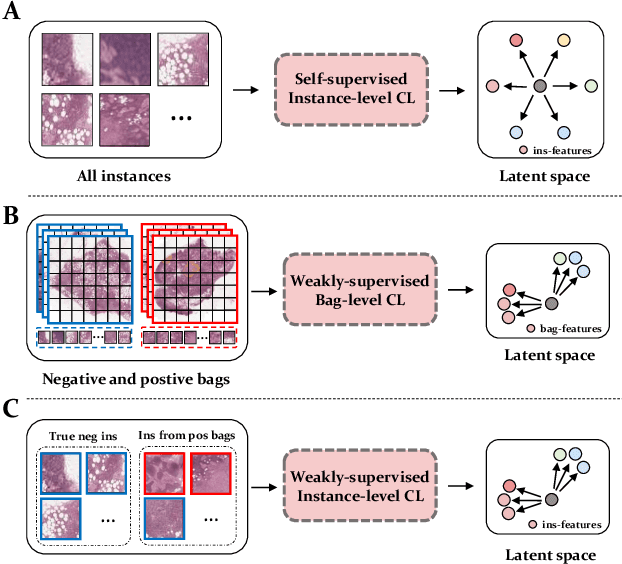
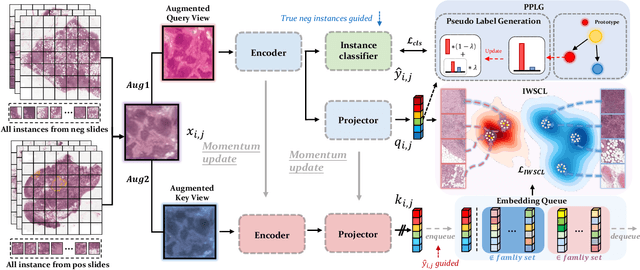
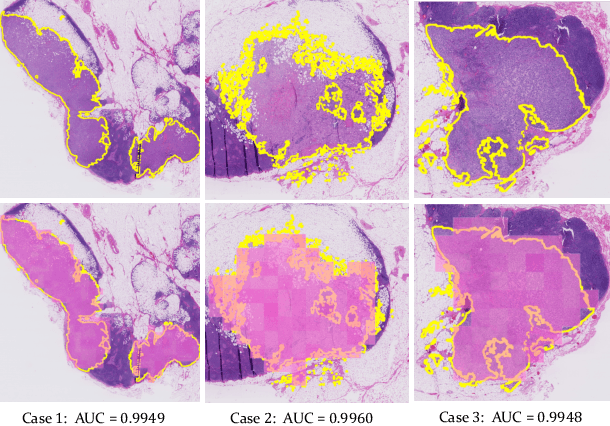
Weakly supervised whole slide image classification is usually formulated as a multiple instance learning (MIL) problem, where each slide is treated as a bag, and the patches cut out of it are treated as instances. Existing methods either train an instance classifier through pseudo-labeling or aggregate instance features into a bag feature through attention mechanisms and then train a bag classifier, where the attention scores can be used for instance-level classification. However, the pseudo instance labels constructed by the former usually contain a lot of noise, and the attention scores constructed by the latter are not accurate enough, both of which affect their performance. In this paper, we propose an instance-level MIL framework based on contrastive learning and prototype learning to effectively accomplish both instance classification and bag classification tasks. To this end, we propose an instance-level weakly supervised contrastive learning algorithm for the first time under the MIL setting to effectively learn instance feature representation. We also propose an accurate pseudo label generation method through prototype learning. We then develop a joint training strategy for weakly supervised contrastive learning, prototype learning, and instance classifier training. Extensive experiments and visualizations on four datasets demonstrate the powerful performance of our method. Codes will be available.