 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial-temporal Graph Based Multi-channel Speaker Verification With Ad-hoc Microphone Arrays
Jul 03, 2023
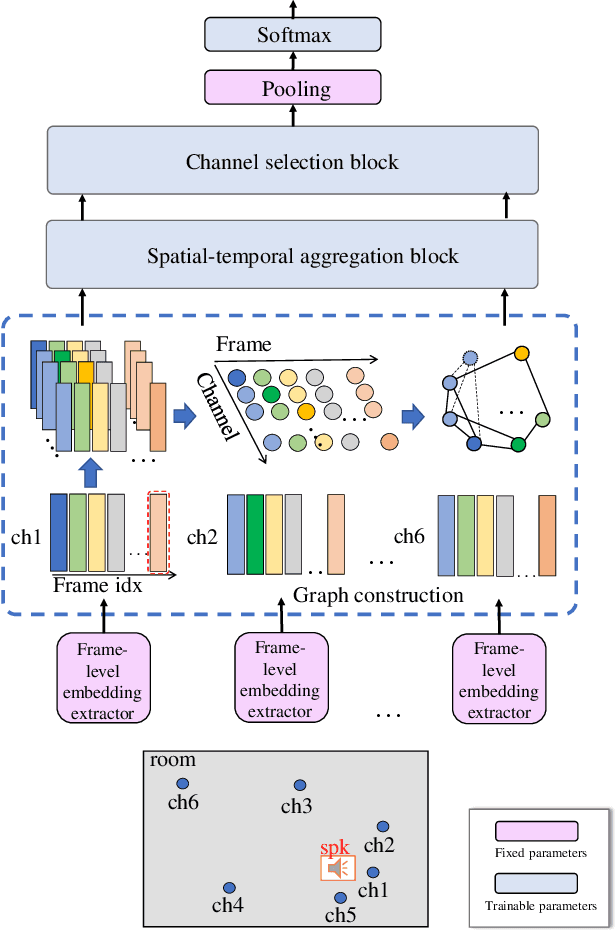
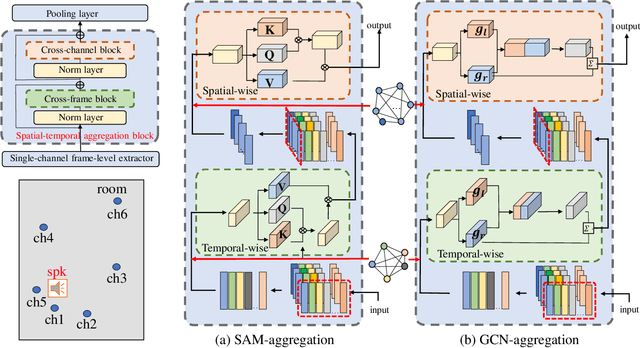
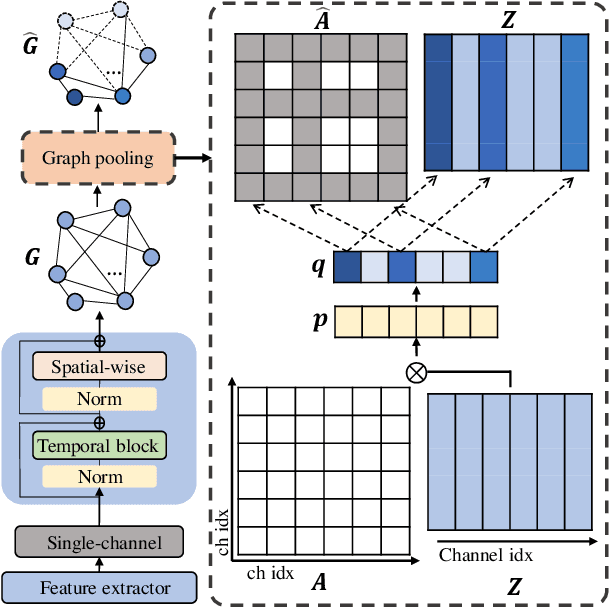
The performance of speaker verification degrades significantly in adverse acoustic environments with strong reverberation and noise. To address this issue, this paper proposes a spatial-temporal graph convolutional network (GCN) method for the multi-channel speaker verification with ad-hoc microphone arrays. It includes a feature aggregation block and a channel selection block, both of which are built on graphs. The feature aggregation block fuses speaker features among different time and channels by a spatial-temporal GCN. The graph-based channel selection block discards the noisy channels that may contribute negatively to the system. The proposed method is flexible in incorporating various kinds of graphs and prior knowledge. We compared the proposed method with six representative methods in both real-world and simulated environments. Experimental results show that the proposed method achieves a relative equal error rate (EER) reduction of $\mathbf{15.39\%}$ lower than the strongest referenced method in the simulated datasets, and $\mathbf{17.70\%}$ lower than the latter in the real datasets. Moreover, its performance is robust across different signal-to-noise ratios and reverberation time.
SLSSNN: High energy efficiency spike-train level spiking neural networks with spatio-temporal conversion
Jul 14, 2023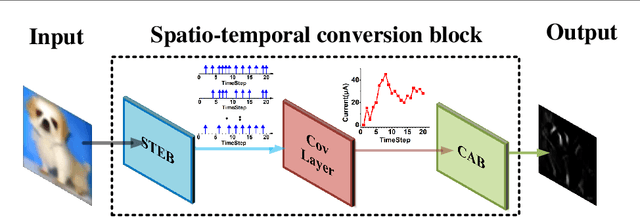
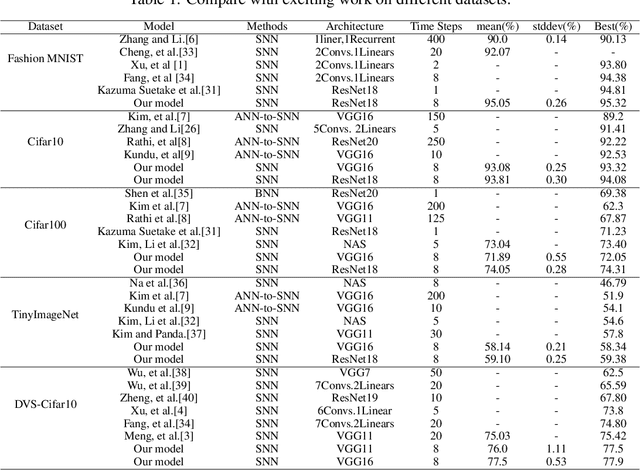
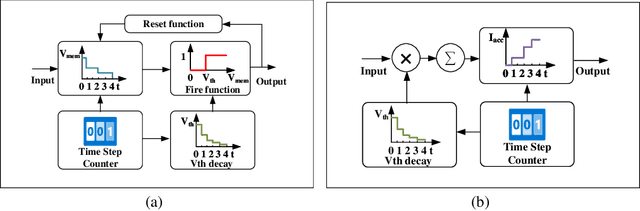
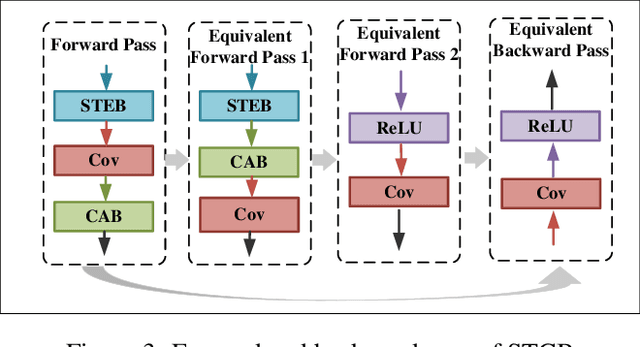
Brain-inspired spiking neuron networks (SNNs) have attracted widespread research interest due to their low power features, high biological plausibility, and strong spatiotemporal information processing capability. Although adopting a surrogate gradient (SG) makes the non-differentiability SNN trainable, achieving comparable accuracy for ANNs and keeping low-power features simultaneously is still tricky. In this paper, we proposed an energy-efficient spike-train level spiking neural network (SLSSNN) with low computational cost and high accuracy. In the SLSSNN, spatio-temporal conversion blocks (STCBs) are applied to replace the convolutional and ReLU layers to keep the low power features of SNNs and improve accuracy. However, SLSSNN cannot adopt backpropagation algorithms directly due to the non-differentiability nature of spike trains. We proposed a suitable learning rule for SLSSNNs by deducing the equivalent gradient of STCB. We evaluate the proposed SLSSNN on static and neuromorphic datasets, including Fashion-Mnist, Cifar10, Cifar100, TinyImageNet, and DVS-Cifar10. The experiment results show that our proposed SLSSNN outperforms the state-of-the-art accuracy on nearly all datasets, using fewer time steps and being highly energy-efficient.
Higher-order topological kernels via quantum computation
Jul 14, 2023Topological data analysis (TDA) has emerged as a powerful tool for extracting meaningful insights from complex data. TDA enhances the analysis of objects by embedding them into a simplicial complex and extracting useful global properties such as the Betti numbers, i.e. the number of multidimensional holes, which can be used to define kernel methods that are easily integrated with existing machine-learning algorithms. These kernel methods have found broad applications, as they rely on powerful mathematical frameworks which provide theoretical guarantees on their performance. However, the computation of higher-dimensional Betti numbers can be prohibitively expensive on classical hardware, while quantum algorithms can approximate them in polynomial time in the instance size. In this work, we propose a quantum approach to defining topological kernels, which is based on constructing Betti curves, i.e. topological fingerprint of filtrations with increasing order. We exhibit a working prototype of our approach implemented on a noiseless simulator and show its robustness by means of some empirical results suggesting that topological approaches may offer an advantage in quantum machine learning.
PAC bounds of continuous Linear Parameter-Varying systems related to neural ODEs
Jul 07, 2023We consider the problem of learning Neural Ordinary Differential Equations (neural ODEs) within the context of Linear Parameter-Varying (LPV) systems in continuous-time. LPV systems contain bilinear systems which are known to be universal approximators for non-linear systems. Moreover, a large class of neural ODEs can be embedded into LPV systems. As our main contribution we provide Probably Approximately Correct (PAC) bounds under stability for LPV systems related to neural ODEs. The resulting bounds have the advantage that they do not depend on the integration interval.
SAR ATR under Limited Training Data Via MobileNetV3
Jun 27, 2023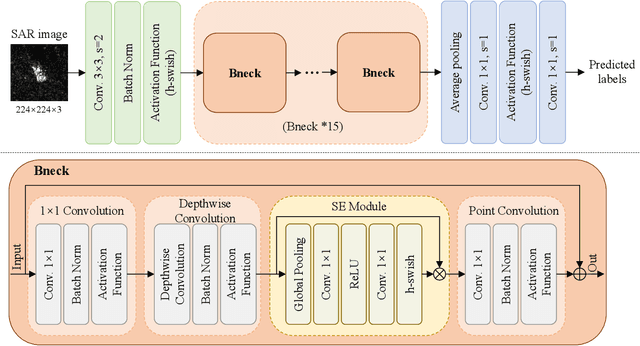
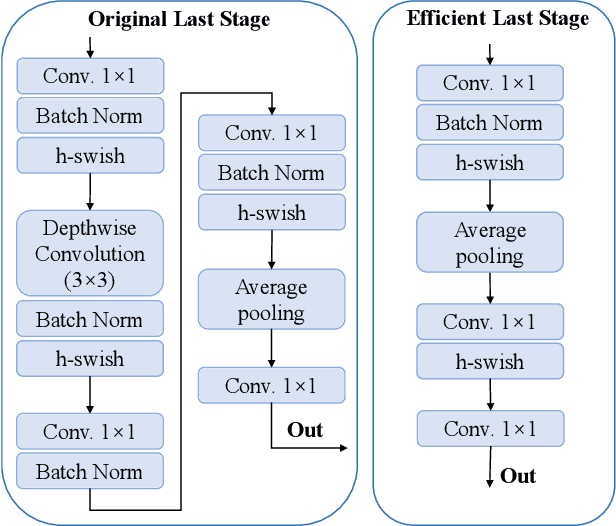

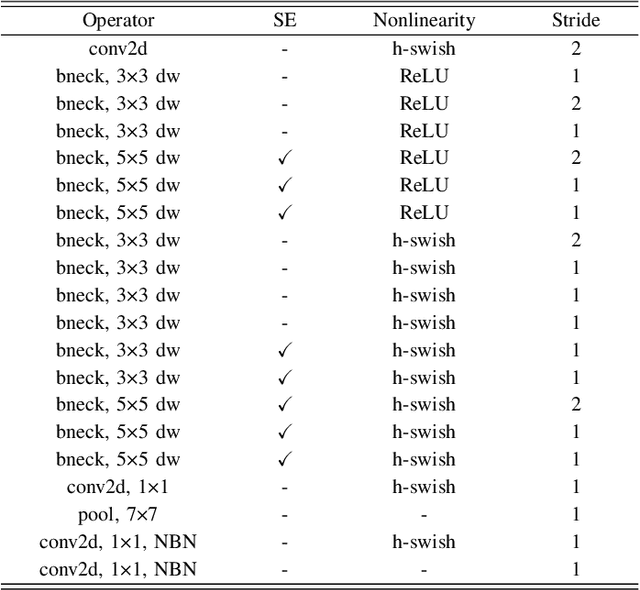
In recent years, deep learning has been widely used to solve the bottleneck problem of synthetic aperture radar (SAR) automatic target recognition (ATR). However, most current methods rely heavily on a large number of training samples and have many parameters which lead to failure under limited training samples. In practical applications, the SAR ATR method needs not only superior performance under limited training data but also real-time performance. Therefore, we try to use a lightweight network for SAR ATR under limited training samples, which has fewer parameters, less computational effort, and shorter inference time than normal networks. At the same time, the lightweight network combines the advantages of existing lightweight networks and uses a combination of MnasNet and NetAdapt algorithms to find the optimal neural network architecture for a given problem. Through experiments and comparisons under the moving and stationary target acquisition and recognition (MSTAR) dataset, the lightweight network is validated to have excellent recognition performance for SAR ATR on limited training samples and be very computationally small, reflecting the great potential of this network structure for practical applications.
Bridge the Performance Gap in Peak-hour Series Forecasting: The Seq2Peak Framework
Jul 04, 2023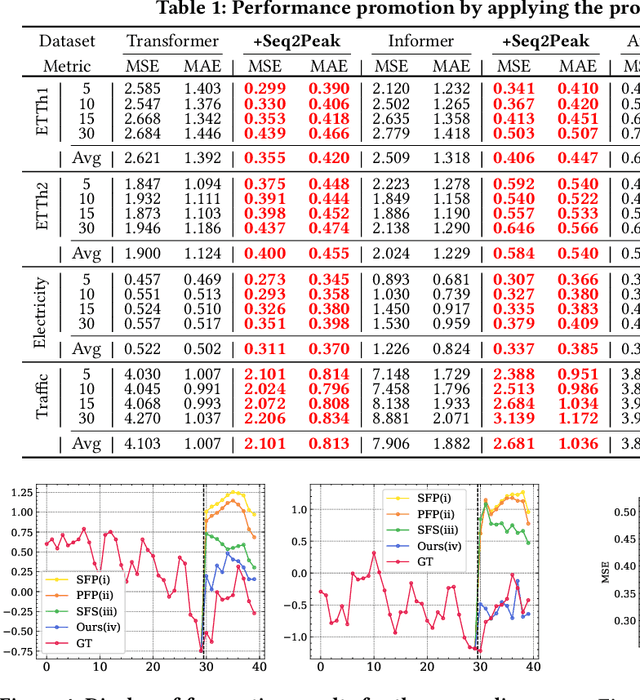
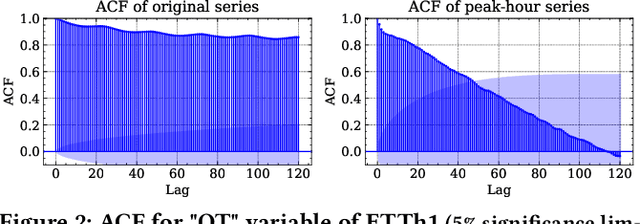
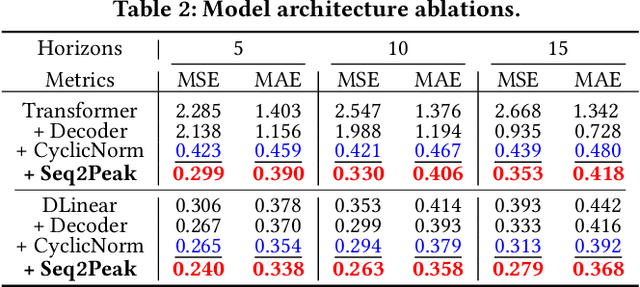
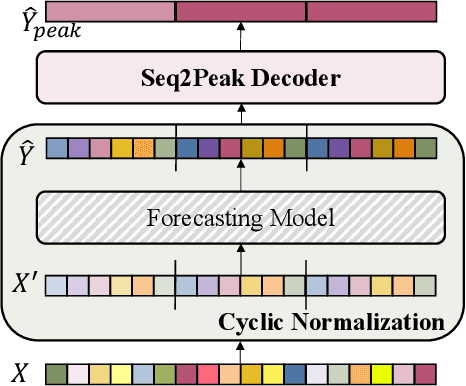
Peak-Hour Series Forecasting (PHSF) is a crucial yet underexplored task in various domains. While state-of-the-art deep learning models excel in regular Time Series Forecasting (TSF), they struggle to achieve comparable results in PHSF. This can be attributed to the challenges posed by the high degree of non-stationarity in peak-hour series, which makes direct forecasting more difficult than standard TSF. Additionally, manually extracting the maximum value from regular forecasting results leads to suboptimal performance due to models minimizing the mean deficit. To address these issues, this paper presents Seq2Peak, a novel framework designed specifically for PHSF tasks, bridging the performance gap observed in TSF models. Seq2Peak offers two key components: the CyclicNorm pipeline to mitigate the non-stationarity issue, and a simple yet effective trainable-parameter-free peak-hour decoder with a hybrid loss function that utilizes both the original series and peak-hour series as supervised signals. Extensive experimentation on publicly available time series datasets demonstrates the effectiveness of the proposed framework, yielding a remarkable average relative improvement of 37.7\% across four real-world datasets for both transformer- and non-transformer-based TSF models.
Localized Text-to-Image Generation for Free via Cross Attention Control
Jun 26, 2023
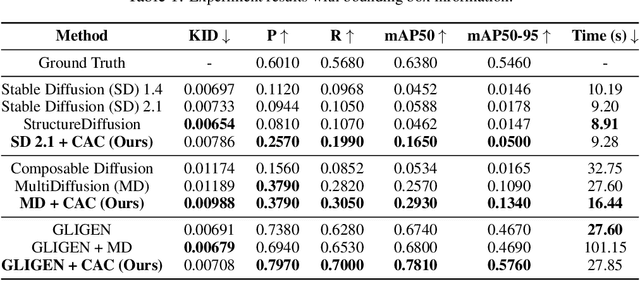
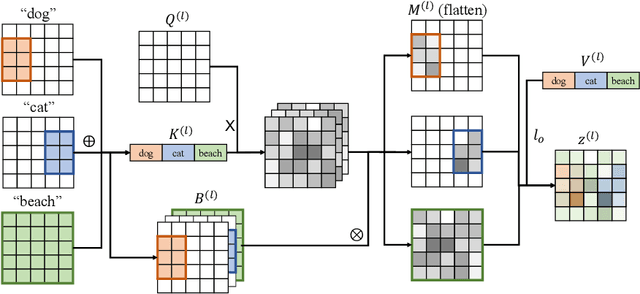

Despite the tremendous success in text-to-image generative models, localized text-to-image generation (that is, generating objects or features at specific locations in an image while maintaining a consistent overall generation) still requires either explicit training or substantial additional inference time. In this work, we show that localized generation can be achieved by simply controlling cross attention maps during inference. With no additional training, model architecture modification or inference time, our proposed cross attention control (CAC) provides new open-vocabulary localization abilities to standard text-to-image models. CAC also enhances models that are already trained for localized generation when deployed at inference time. Furthermore, to assess localized text-to-image generation performance automatically, we develop a standardized suite of evaluations using large pretrained recognition models. Our experiments show that CAC improves localized generation performance with various types of location information ranging from bounding boxes to semantic segmentation maps, and enhances the compositional capability of state-of-the-art text-to-image generative models.
Leveraging Denoised Abstract Meaning Representation for Grammatical Error Correction
Jul 05, 2023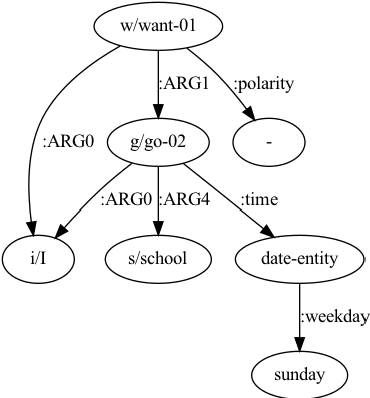
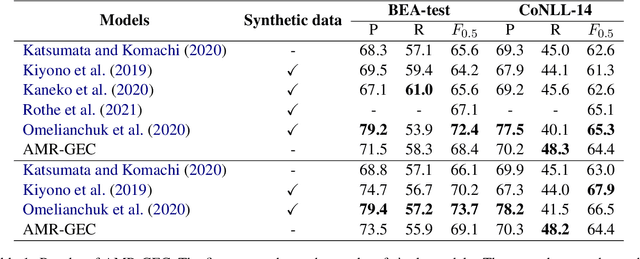
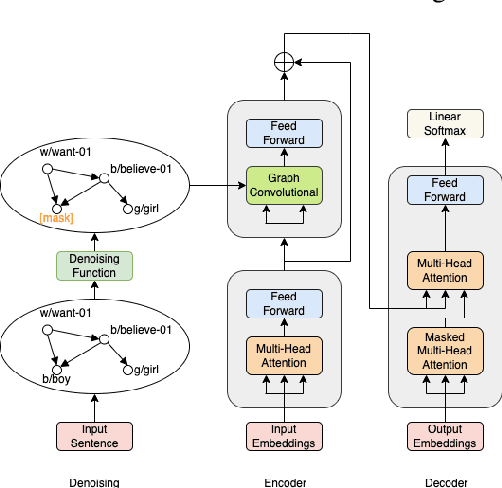
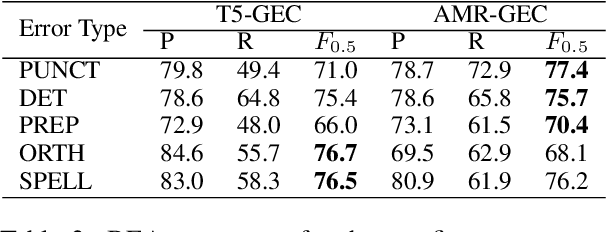
Grammatical Error Correction (GEC) is the task of correcting errorful sentences into grammatically correct, semantically consistent, and coherent sentences. Popular GEC models either use large-scale synthetic corpora or use a large number of human-designed rules. The former is costly to train, while the latter requires quite a lot of human expertise. In recent years, AMR, a semantic representation framework, has been widely used by many natural language tasks due to its completeness and flexibility. A non-negligible concern is that AMRs of grammatically incorrect sentences may not be exactly reliable. In this paper, we propose the AMR-GEC, a seq-to-seq model that incorporates denoised AMR as additional knowledge. Specifically, We design a semantic aggregated GEC model and explore denoising methods to get AMRs more reliable. Experiments on the BEA-2019 shared task and the CoNLL-2014 shared task have shown that AMR-GEC performs comparably to a set of strong baselines with a large number of synthetic data. Compared with the T5 model with synthetic data, AMR-GEC can reduce the training time by 32\% while inference time is comparable. To the best of our knowledge, we are the first to incorporate AMR for grammatical error correction.
HRHD-HK: A benchmark dataset of high-rise and high-density urban scenes for 3D semantic segmentation of photogrammetric point clouds
Jul 16, 2023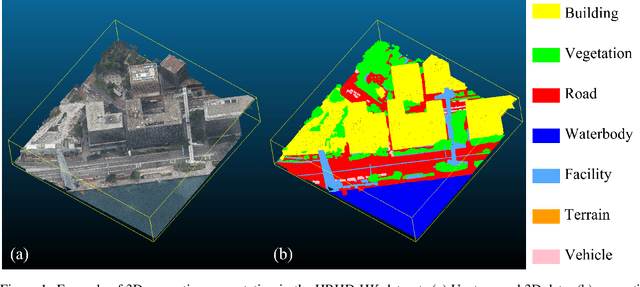
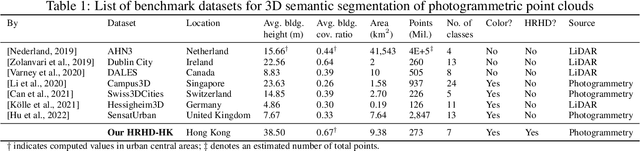
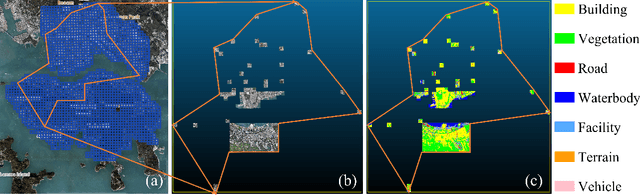

Many existing 3D semantic segmentation methods, deep learning in computer vision notably, claimed to achieve desired results on urban point clouds, in which the city objects are too many and diverse for people to judge qualitatively. Thus, it is significant to assess these methods quantitatively in diversified real-world urban scenes, encompassing high-rise, low-rise, high-density, and low-density urban areas. However, existing public benchmark datasets primarily represent low-rise scenes from European cities and cannot assess the methods comprehensively. This paper presents a benchmark dataset of high-rise urban point clouds, namely High-Rise, High-Density urban scenes of Hong Kong (HRHD-HK), which has been vacant for a long time. HRHD-HK arranged in 150 tiles contains 273 million colorful photogrammetric 3D points from diverse urban settings. The semantic labels of HRHD-HK include building, vegetation, road, waterbody, facility, terrain, and vehicle. To the best of our knowledge, HRHD-HK is the first photogrammetric dataset that focuses on HRHD urban areas. This paper also comprehensively evaluates eight popular semantic segmentation methods on the HRHD-HK dataset. Experimental results confirmed plenty of room for enhancing the current 3D semantic segmentation of point clouds, especially for city objects with small volumes. Our dataset is publicly available at: https://github.com/LuZaiJiaoXiaL/HRHD-HK.
Untrained neural network embedded Fourier phase retrieval from few measurements
Jul 16, 2023Fourier phase retrieval (FPR) is a challenging task widely used in various applications. It involves recovering an unknown signal from its Fourier phaseless measurements. FPR with few measurements is important for reducing time and hardware costs, but it suffers from serious ill-posedness. Recently, untrained neural networks have offered new approaches by introducing learned priors to alleviate the ill-posedness without requiring any external data. However, they may not be ideal for reconstructing fine details in images and can be computationally expensive. This paper proposes an untrained neural network (NN) embedded algorithm based on the alternating direction method of multipliers (ADMM) framework to solve FPR with few measurements. Specifically, we use a generative network to represent the image to be recovered, which confines the image to the space defined by the network structure. To improve the ability to represent high-frequency information, total variation (TV) regularization is imposed to facilitate the recovery of local structures in the image. Furthermore, to reduce the computational cost mainly caused by the parameter updates of the untrained NN, we develop an accelerated algorithm that adaptively trades off between explicit and implicit regularization. Experimental results indicate that the proposed algorithm outperforms existing untrained NN-based algorithms with fewer computational resources and even performs competitively against trained NN-based algorithms.