 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A CNN regression model to estimate buildings height maps using Sentinel-1 SAR and Sentinel-2 MSI time series
Jul 03, 2023
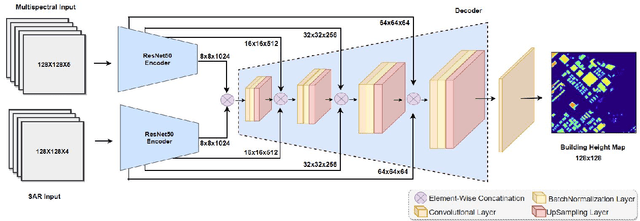
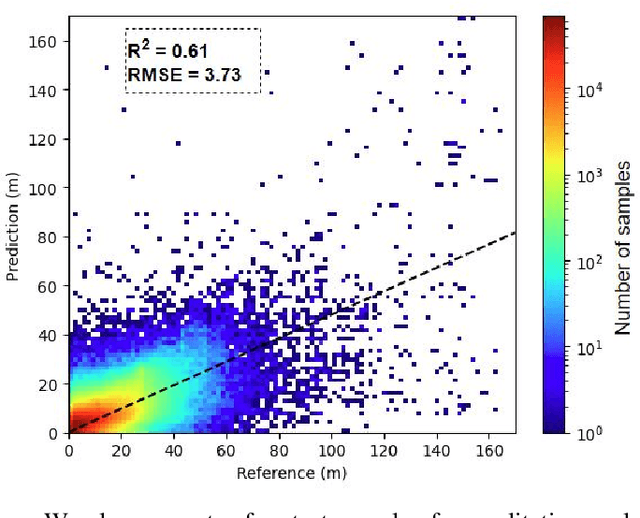

Accurate estimation of building heights is essential for urban planning, infrastructure management, and environmental analysis. In this study, we propose a supervised Multimodal Building Height Regression Network (MBHR-Net) for estimating building heights at 10m spatial resolution using Sentinel-1 (S1) and Sentinel-2 (S2) satellite time series. S1 provides Synthetic Aperture Radar (SAR) data that offers valuable information on building structures, while S2 provides multispectral data that is sensitive to different land cover types, vegetation phenology, and building shadows. Our MBHR-Net aims to extract meaningful features from the S1 and S2 images to learn complex spatio-temporal relationships between image patterns and building heights. The model is trained and tested in 10 cities in the Netherlands. Root Mean Squared Error (RMSE), Intersection over Union (IOU), and R-squared (R2) score metrics are used to evaluate the performance of the model. The preliminary results (3.73m RMSE, 0.95 IoU, 0.61 R2) demonstrate the effectiveness of our deep learning model in accurately estimating building heights, showcasing its potential for urban planning, environmental impact analysis, and other related applications.
Tackling the Curse of Dimensionality in Large-scale Multi-agent LTL Task Planning via Poset Product
Aug 22, 2023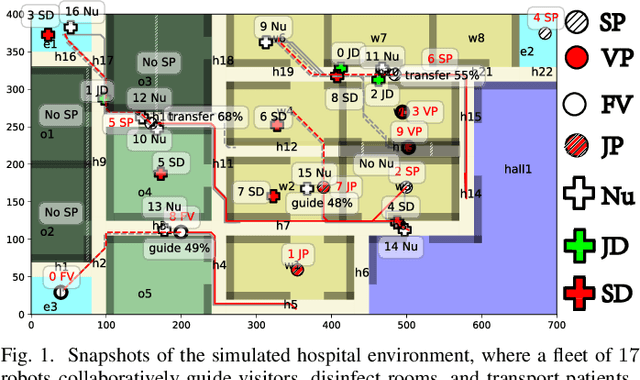
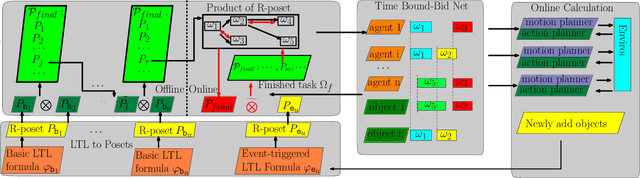
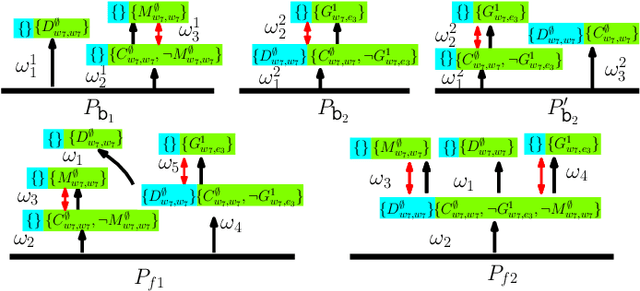
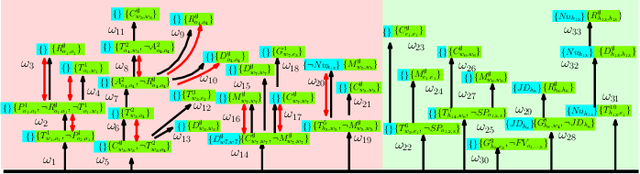
Linear Temporal Logic (LTL) formulas have been used to describe complex tasks for multi-agent systems, with both spatial and temporal constraints. However, since the planning complexity grows exponentially with the number of agents and the length of the task formula, existing applications are mostly limited to small artificial cases. To address this issue, a new planning algorithm is proposed for task formulas specified as sc-LTL formulas. It avoids two common bottlenecks in the model-checking-based planning methods, i.e., (i) the direct translation of the complete task formula to the associated B\"uchi automaton; and (ii) the synchronized product between the B\"uchi automaton and the transition models of all agents. In particular, each conjuncted sub-formula is first converted to the associated R-posets as an abstraction of the temporal dependencies among the subtasks. Then, an efficient algorithm is proposed to compute the product of these R-posets, which retains their dependencies and resolves potential conflicts. Furthermore, the proposed approach is applied to dynamic scenes where new tasks are generated online. It is capable of deriving the first valid plan with a polynomial time and memory complexity w.r.t. the system size and the formula length. Our method can plan for task formulas with a length of more than 60 and a system with more than 35 agents, while most existing methods fail at the formula length of 20. The proposed method is validated on large fleets of service robots in both simulation and hardware experiments.
Distributed Robust Learning-Based Backstepping Control Aided with Neurodynamics for Consensus Formation Tracking of Underwater Vessels
Aug 18, 2023This paper addresses distributed robust learning-based control for consensus formation tracking of multiple underwater vessels, in which the system parameters of the marine vessels are assumed to be entirely unknown and subject to the modeling mismatch, oceanic disturbances, and noises. Towards this end, graph theory is used to allow us to synthesize the distributed controller with a stability guarantee. Due to the fact that the parameter uncertainties only arise in the vessels' dynamic model, the backstepping control technique is then employed. Subsequently, to overcome the difficulties in handling time-varying and unknown systems, an online learning procedure is developed in the proposed distributed formation control protocol. Moreover, modeling errors, environmental disturbances, and measurement noises are considered and tackled by introducing a neurodynamics model in the controller design to obtain a robust solution. Then, the stability analysis of the overall closed-loop system under the proposed scheme is provided to ensure the robust adaptive performance at the theoretical level. Finally, extensive simulation experiments are conducted to further verify the efficacy of the presented distributed control protocol.
PlaneRecTR: Unified Query Learning for 3D Plane Recovery from a Single View
Aug 17, 2023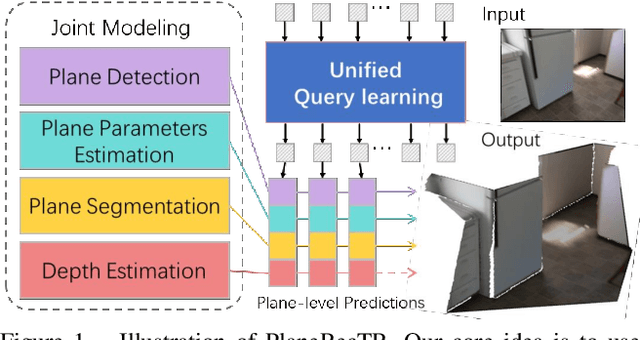
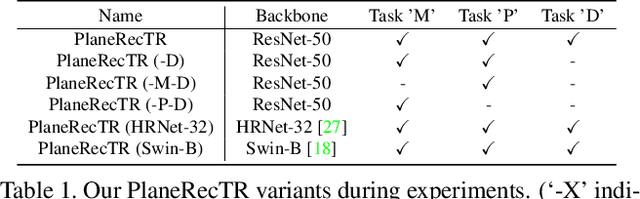
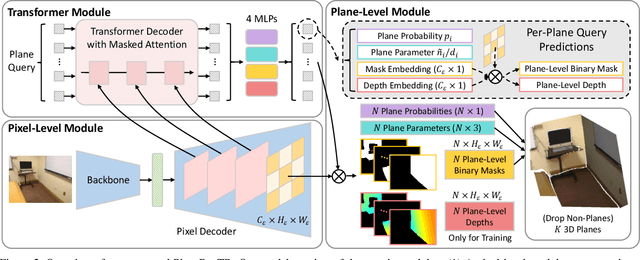
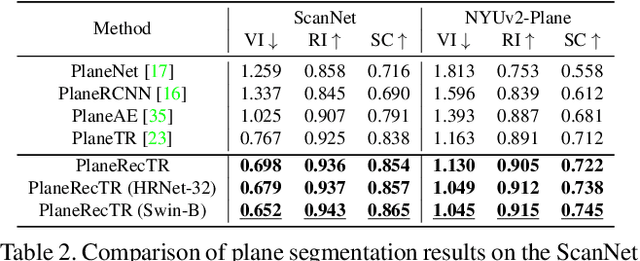
3D plane recovery from a single image can usually be divided into several subtasks of plane detection, segmentation, parameter estimation and possibly depth estimation. Previous works tend to solve this task by either extending the RCNN-based segmentation network or the dense pixel embedding-based clustering framework. However, none of them tried to integrate above related subtasks into a unified framework but treat them separately and sequentially, which we suspect is potentially a main source of performance limitation for existing approaches. Motivated by this finding and the success of query-based learning in enriching reasoning among semantic entities, in this paper, we propose PlaneRecTR, a Transformer-based architecture, which for the first time unifies all subtasks related to single-view plane recovery with a single compact model. Extensive quantitative and qualitative experiments demonstrate that our proposed unified learning achieves mutual benefits across subtasks, obtaining a new state-of-the-art performance on public ScanNet and NYUv2-Plane datasets. Codes are available at https://github.com/SJingjia/PlaneRecTR.
Bag of Tricks for Long-Tailed Multi-Label Classification on Chest X-Rays
Aug 17, 2023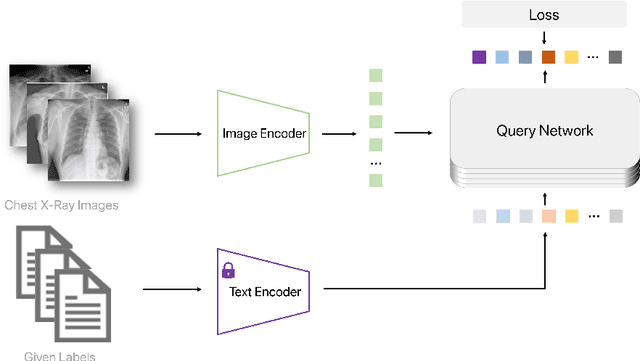
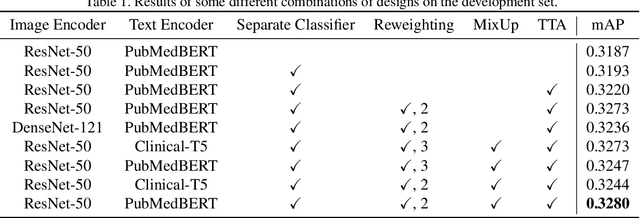

Clinical classification of chest radiography is particularly challenging for standard machine learning algorithms due to its inherent long-tailed and multi-label nature. However, few attempts take into account the coupled challenges posed by both the class imbalance and label co-occurrence, which hinders their value to boost the diagnosis on chest X-rays (CXRs) in the real-world scenarios. Besides, with the prevalence of pretraining techniques, how to incorporate these new paradigms into the current framework lacks of the systematical study. This technical report presents a brief description of our solution in the ICCV CVAMD 2023 CXR-LT Competition. We empirically explored the effectiveness for CXR diagnosis with the integration of several advanced designs about data augmentation, feature extractor, classifier design, loss function reweighting, exogenous data replenishment, etc. In addition, we improve the performance through simple test-time data augmentation and ensemble. Our framework finally achieves 0.349 mAP on the competition test set, ranking in the top five.
SDDNet: Style-guided Dual-layer Disentanglement Network for Shadow Detection
Aug 17, 2023
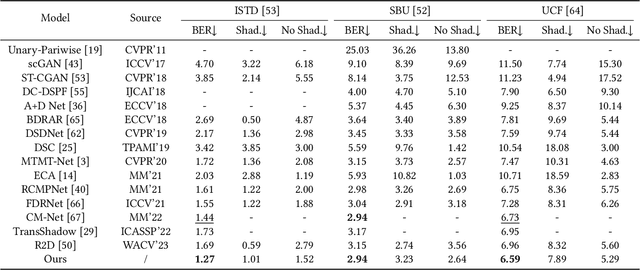
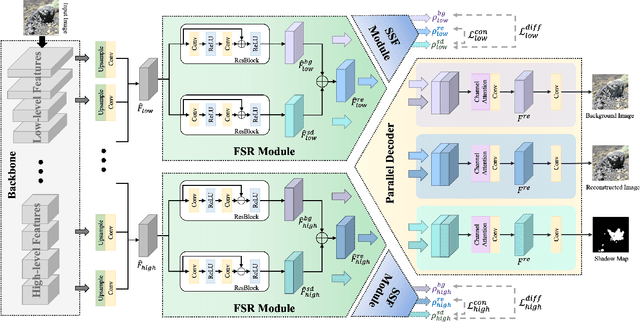
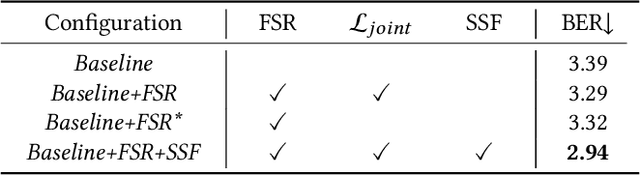
Despite significant progress in shadow detection, current methods still struggle with the adverse impact of background color, which may lead to errors when shadows are present on complex backgrounds. Drawing inspiration from the human visual system, we treat the input shadow image as a composition of a background layer and a shadow layer, and design a Style-guided Dual-layer Disentanglement Network (SDDNet) to model these layers independently. To achieve this, we devise a Feature Separation and Recombination (FSR) module that decomposes multi-level features into shadow-related and background-related components by offering specialized supervision for each component, while preserving information integrity and avoiding redundancy through the reconstruction constraint. Moreover, we propose a Shadow Style Filter (SSF) module to guide the feature disentanglement by focusing on style differentiation and uniformization. With these two modules and our overall pipeline, our model effectively minimizes the detrimental effects of background color, yielding superior performance on three public datasets with a real-time inference speed of 32 FPS.
A Comparative Study of Text Embedding Models for Semantic Text Similarity in Bug Reports
Aug 17, 2023Bug reports are an essential aspect of software development, and it is crucial to identify and resolve them quickly to ensure the consistent functioning of software systems. Retrieving similar bug reports from an existing database can help reduce the time and effort required to resolve bugs. In this paper, we compared the effectiveness of semantic textual similarity methods for retrieving similar bug reports based on a similarity score. We explored several embedding models such as TF-IDF (Baseline), FastText, Gensim, BERT, and ADA. We used the Software Defects Data containing bug reports for various software projects to evaluate the performance of these models. Our experimental results showed that BERT generally outperformed the rest of the models regarding recall, followed by ADA, Gensim, FastText, and TFIDF. Our study provides insights into the effectiveness of different embedding methods for retrieving similar bug reports and highlights the impact of selecting the appropriate one for this task. Our code is available on GitHub.
Learning the hub graphical Lasso model with the structured sparsity via an efficient algorithm
Aug 17, 2023Graphical models have exhibited their performance in numerous tasks ranging from biological analysis to recommender systems. However, graphical models with hub nodes are computationally difficult to fit, particularly when the dimension of the data is large. To efficiently estimate the hub graphical models, we introduce a two-phase algorithm. The proposed algorithm first generates a good initial point via a dual alternating direction method of multipliers (ADMM), and then warm starts a semismooth Newton (SSN) based augmented Lagrangian method (ALM) to compute a solution that is accurate enough for practical tasks. The sparsity structure of the generalized Jacobian ensures that the algorithm can obtain a nice solution very efficiently. Comprehensive experiments on both synthetic data and real data show that it obviously outperforms the existing state-of-the-art algorithms. In particular, in some high dimensional tasks, it can save more than 70\% of the execution time, meanwhile still achieves a high-quality estimation.
Severity Classification of Parkinson's Disease from Speech using Single Frequency Filtering-based Features
Aug 17, 2023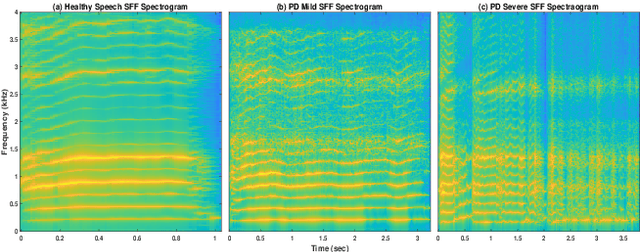
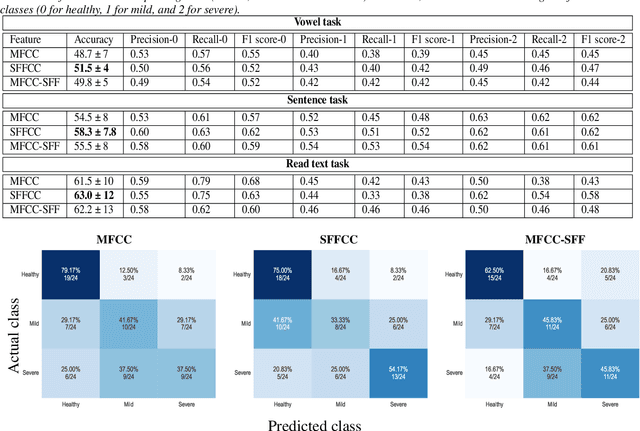
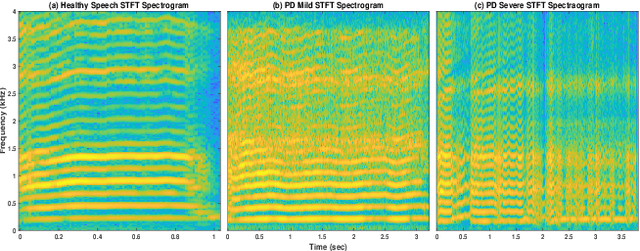
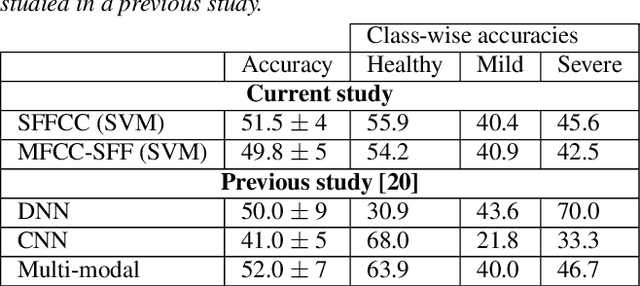
Developing objective methods for assessing the severity of Parkinson's disease (PD) is crucial for improving the diagnosis and treatment. This study proposes two sets of novel features derived from the single frequency filtering (SFF) method: (1) SFF cepstral coefficients (SFFCC) and (2) MFCCs from the SFF (MFCC-SFF) for the severity classification of PD. Prior studies have demonstrated that SFF offers greater spectro-temporal resolution compared to the short-time Fourier transform. The study uses the PC-GITA database, which includes speech of PD patients and healthy controls produced in three speaking tasks (vowels, sentences, text reading). Experiments using the SVM classifier revealed that the proposed features outperformed the conventional MFCCs in all three speaking tasks. The proposed SFFCC and MFCC-SFF features gave a relative improvement of 5.8% and 2.3% for the vowel task, 7.0% & 1.8% for the sentence task, and 2.4% and 1.1% for the read text task, in comparison to MFCC features.
Interpretable Graph Neural Networks for Tabular Data
Aug 17, 2023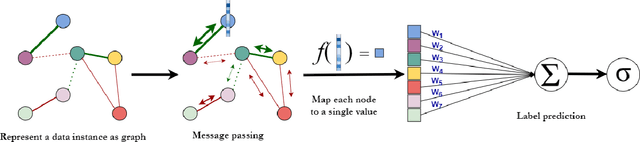
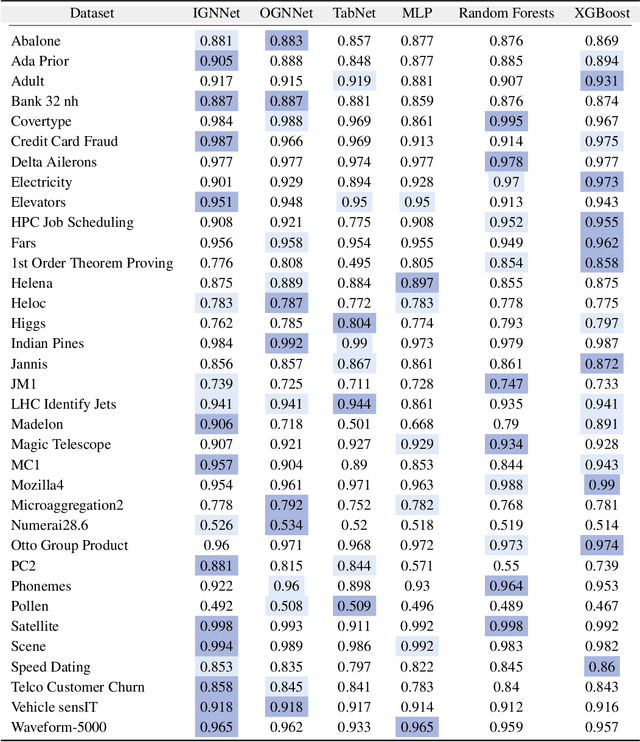
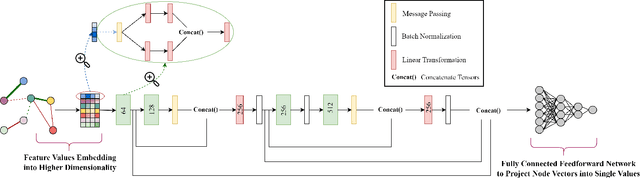
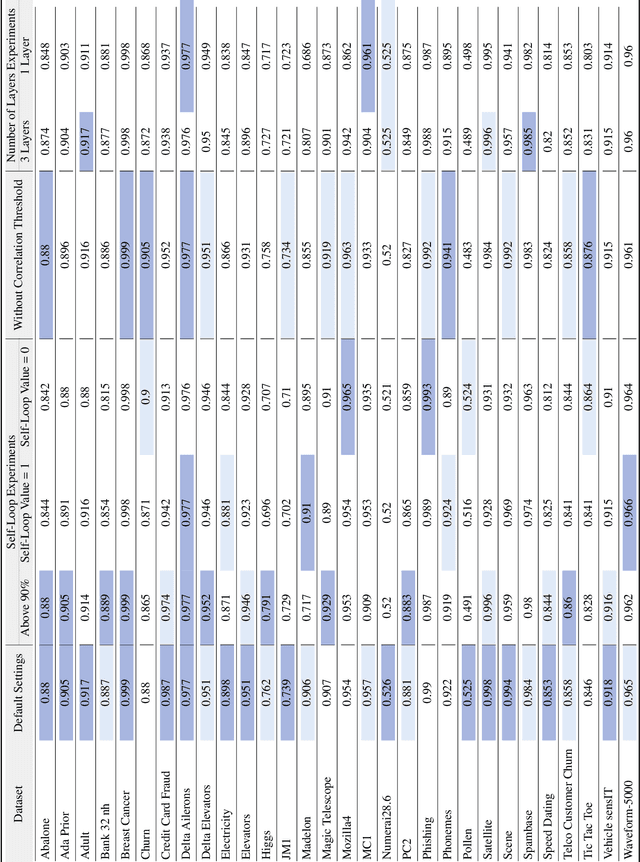
Data in tabular format is frequently occurring in real-world applications. Graph Neural Networks (GNNs) have recently been extended to effectively handle such data, allowing feature interactions to be captured through representation learning. However, these approaches essentially produce black-box models, in the form of deep neural networks, precluding users from following the logic behind the model predictions. We propose an approach, called IGNNet (Interpretable Graph Neural Network for tabular data), which constrains the learning algorithm to produce an interpretable model, where the model shows how the predictions are exactly computed from the original input features. A large-scale empirical investigation is presented, showing that IGNNet is performing on par with state-of-the-art machine-learning algorithms that target tabular data, including XGBoost, Random Forests, and TabNet. At the same time, the results show that the explanations obtained from IGNNet are aligned with the true Shapley values of the features without incurring any additional computational overhead.