 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMBRELLA: Uncertainty-aware Multi-robot Reactive Coordination under Dynamic Temporal Logic Tasks
Mar 26, 2026Multi-robot systems can be extremely efficient for accomplishing team-wise tasks by acting concurrently and collaboratively. However, most existing methods either assume static task features or simply replan when environmental changes occur. This paper addresses the challenging problem of coordinating multi-robot systems for collaborative tasks involving dynamic and moving targets. We explicitly model the uncertainty in target motion prediction via Conformal Prediction(CP), while respecting the spatial-temporal constraints specified by Linear Temporal Logic (LTL). The proposed framework (UMBRELLA) combines the Monte Carlo Tree Search (MCTS) over partial plans with uncertainty-aware rollouts, and introduces a CP-based metric to guide and accelerate the search. The objective is to minimize the Conditional Value at Risk (CVaR) of the average makespan. For tasks released online, a receding-horizon planning scheme dynamically adjusts the assignments based on updated task specifications and motion predictions. Spatial and temporal constraints among the tasks are always ensured, and only partial synchronization is required for the collaborative tasks during online execution. Extensive large-scale simulations and hardware experiments demonstrate substantial reductions in both the average makespan and its variance by 23% and 71%, compared with static baselines.
DEXTER-LLM: Dynamic and Explainable Coordination of Multi-Robot Systems in Unknown Environments via Large Language Models
Aug 20, 2025



Online coordination of multi-robot systems in open and unknown environments faces significant challenges, particularly when semantic features detected during operation dynamically trigger new tasks. Recent large language model (LLMs)-based approaches for scene reasoning and planning primarily focus on one-shot, end-to-end solutions in known environments, lacking both dynamic adaptation capabilities for online operation and explainability in the processes of planning. To address these issues, a novel framework (DEXTER-LLM) for dynamic task planning in unknown environments, integrates four modules: (i) a mission comprehension module that resolves partial ordering of tasks specified by natural languages or linear temporal logic formulas (LTL); (ii) an online subtask generator based on LLMs that improves the accuracy and explainability of task decomposition via multi-stage reasoning; (iii) an optimal subtask assigner and scheduler that allocates subtasks to robots via search-based optimization; and (iv) a dynamic adaptation and human-in-the-loop verification module that implements multi-rate, event-based updates for both subtasks and their assignments, to cope with new features and tasks detected online. The framework effectively combines LLMs' open-world reasoning capabilities with the optimality of model-based assignment methods, simultaneously addressing the critical issue of online adaptability and explainability. Experimental evaluations demonstrate exceptional performances, with 100% success rates across all scenarios, 160 tasks and 480 subtasks completed on average (3 times the baselines), 62% less queries to LLMs during adaptation, and superior plan quality (2 times higher) for compound tasks. Project page at https://tcxm.github.io/DEXTER-LLM/
Asynchronous Spatial Allocation Protocol for Trajectory Planning of Heterogeneous Multi-Agent Systems
Oct 02, 2023



To plan the trajectories of a large and heterogeneous swarm, sequential or synchronous distributed methods usually become intractable, due to the lack of global connectivity and clock synchronization, Moreover, the existing asynchronously distributed schemes usually require recheck-like mechanisms instead of inherently considering the other' moving tendency. To this end, we propose a novel asynchronous protocol to allocate the agents' derivable space in a distributed way, by which each agent can replan trajectory depending on its own timetable. Properties such as collision avoidance and recursive feasibility are theoretically shown and a lower bound of protocol updating is provided. Comprehensive simulations and comparisons with five state-of-the-art methods validate the effectiveness of our method and illustrate the improvement in both the completion time and the moving distance. Finally, hardware experiments are carried out, where 8 heterogeneous unmanned ground vehicles with onboard computation navigate in cluttered scenarios at a high agility.
Multi-agent Coordination Under Temporal Logic Tasks and Team-Wise Intermittent Communication
Sep 06, 2023

Multi-agent systems outperform single agent in complex collaborative tasks. However, in large-scale scenarios, ensuring timely information exchange during decentralized task execution remains a challenge. This work presents an online decentralized coordination scheme for multi-agent systems under complex local tasks and intermittent communication constraints. Unlike existing strategies that enforce all-time or intermittent connectivity, our approach allows agents to join or leave communication networks at aperiodic intervals, as deemed optimal by their online task execution. This scheme concurrently determines local plans and refines the communication strategy, i.e., where and when to communicate as a team. A decentralized potential game is modeled among agents, for which a Nash equilibrium is generated iteratively through online local search. It guarantees local task completion and intermittent communication constraints. Extensive numerical simulations are conducted against several strong baselines.
Tackling the Curse of Dimensionality in Large-scale Multi-agent LTL Task Planning via Poset Product
Aug 22, 2023



Linear Temporal Logic (LTL) formulas have been used to describe complex tasks for multi-agent systems, with both spatial and temporal constraints. However, since the planning complexity grows exponentially with the number of agents and the length of the task formula, existing applications are mostly limited to small artificial cases. To address this issue, a new planning algorithm is proposed for task formulas specified as sc-LTL formulas. It avoids two common bottlenecks in the model-checking-based planning methods, i.e., (i) the direct translation of the complete task formula to the associated B\"uchi automaton; and (ii) the synchronized product between the B\"uchi automaton and the transition models of all agents. In particular, each conjuncted sub-formula is first converted to the associated R-posets as an abstraction of the temporal dependencies among the subtasks. Then, an efficient algorithm is proposed to compute the product of these R-posets, which retains their dependencies and resolves potential conflicts. Furthermore, the proposed approach is applied to dynamic scenes where new tasks are generated online. It is capable of deriving the first valid plan with a polynomial time and memory complexity w.r.t. the system size and the formula length. Our method can plan for task formulas with a length of more than 60 and a system with more than 35 agents, while most existing methods fail at the formula length of 20. The proposed method is validated on large fleets of service robots in both simulation and hardware experiments.
Observation of Periodic Systems: Bridge Centralized Kalman Filtering and Consensus-Based Distributed Filtering
Mar 15, 2023Compared with linear time invariant systems, linear periodic system can describe the periodic processes arising from nature and engineering more precisely. However, the time-varying system parameters increase the difficulty of the research on periodic system, such as stabilization and observation. This paper aims to consider the observation problem of periodic systems by bridging two fundamental filtering algorithms for periodic systems with a sensor network: consensus-on-measurement-based distributed filtering (CMDF) and centralized Kalman filtering (CKF). Firstly, one mild convergence condition based on uniformly collective observability is established for CMDF, under which the filtering performance of CMDF can be formulated as a symmetric periodic positive semidefinite (SPPS) solution to a discrete-time periodic Lyapunov equation. Then, the closed form of the performance gap between CMDF and CKF is presented in terms of the information fusion steps and the consensus weights of the network. Moreover, it is pointed out that the estimation error covariance of CMDF exponentially converges to the centralized one with the fusion steps tending to infinity. Altogether, these new results establish a concise and specific relationship between distributed and centralized filterings, and formulate the trade-off between the communication cost and distributed filtering performance on periodic systems. Finally, the theoretical results are verified with numerical experiments.
A Novel Vector-Field-Based Motion Planning for 3D Nonholonomic Robots
Feb 22, 2023This paper focuses on the motion planning for mobile robots in 3D, which are modelled by 6-DOF rigid body systems with nonholonomic constraints. We not only specify the target position, but also bring in the requirement of the heading direction at the terminal time, which gives rise to a new and more challenging 3D motion planning problem. The proposed planning algorithm involves a novel velocity vector field (VF) over the workspace, and by following the VF, the robot can be navigated to the destination with the specified heading direction. In order to circumvent potential collisions with obstacles and other robots, a composite VF is presented by composing the navigation VF and an additional VF tangential to the boundary of the dangerous area. Moreover, we propose a priority-based algorithm to deal with the motion coupling among multiple robots. Finally, numerical simulations are conducted to verify the theoretical results.
Hierarchical Motion Planning under Probabilistic Temporal Tasks and Safe-Return Constraints
Feb 10, 2023



Safety is crucial for robotic missions within an uncertain environment. Common safety requirements such as collision avoidance are only state-dependent, which can be restrictive for complex missions. In this work, we address a more general formulation as safe-return constraints, which require the existence of a return-policy to drive the system back to a set of safe states with high probability. The robot motion is modeled as a Markov Decision Process (MDP) with probabilistic labels, which can be highly non-ergodic. The robotic task is specified as Linear Temporal Logic (LTL) formulas over these labels, such as surveillance and transportation. We first provide theoretical guarantees on the re-formulation of such safe-return constraints, and a baseline solution based on computing two complete product automata. Furthermore, to tackle the computational complexity, we propose a hierarchical planning algorithm that combines the feature-based symbolic and temporal abstraction with constrained optimization. It synthesizes simultaneously two dependent motion policies: the outbound policy minimizes the overall cost of satisfying the task with a high probability, while the return policy ensures the safe-return constraints. The problem formulation is versatile regarding the robot model, task specifications and safety constraints. The proposed hierarchical algorithm is more efficient and can solve much larger problems than the baseline solution, with only a slight loss of optimality. Numerical validations include simulations and hardware experiments of a search-and-rescue mission and a planetary exploration mission over various system sizes.
DiscreteCommunication and ControlUpdating in Event-Triggered Consensus
Oct 26, 2022



This paper studies the consensus control problem faced with three essential demands, namely, discrete control updating for each agent, discrete-time communications among neighboring agents, and the fully distributed fashion of the controller implementation without requiring any global information of the whole network topology. Noting that the existing related results only meeting one or two demands at most are essentially not applicable, in this paper we establish a novel framework to solve the problem of fully distributed consensus with discrete communication and control. The first key point in this framework is the design of controllers that are only updated at discrete event instants and do not depend on global information by introducing time-varying gains inspired by the adaptive control technique. Another key point is the invention of novel dynamic triggering functions that are independent of relative information among neighboring agents. Under the established framework, we propose fully distributed state-feedback event-triggered protocols for undirected graphs and also further study the more complexed cases of output-feedback control and directed graphs. Finally, numerical examples are provided to verify the effectiveness of the proposed event-triggered protocols.
Multi-Robot Trajectory Planning with Feasibility Guarantee and Deadlock Resolution: An Obstacle-Dense Environment
Oct 09, 2022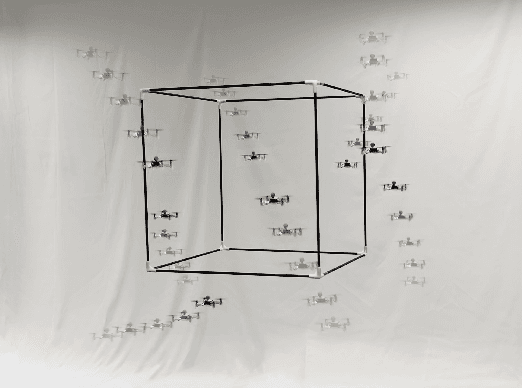
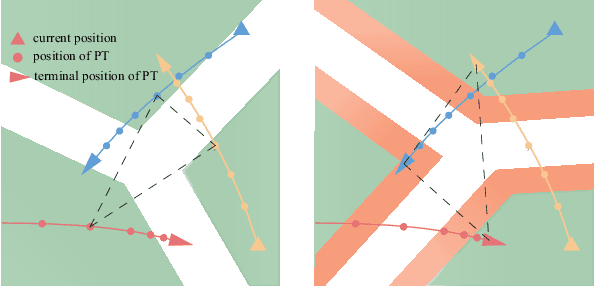
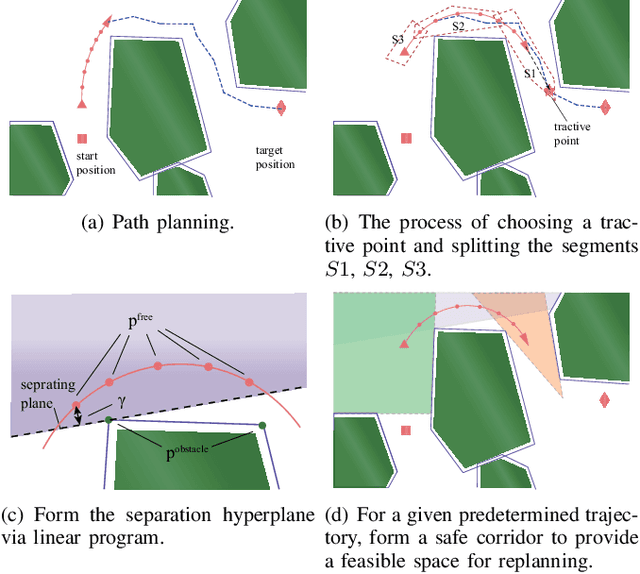
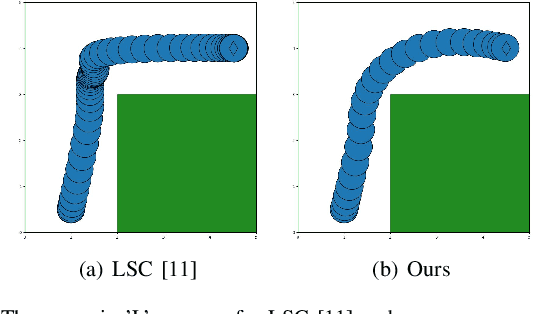
This article presents a multi-robot trajectory planning method which guarantees optimization feasibility and resolves deadlocks in an obstacle-dense environment. The method is proposed via formulating an optimization problem, where the modified buffered Voronoi cell with warning band is utilized to avoid the inter-robot collision and the deadlock is resolved by an adaptive right-hand rule. Meanwhile, a novel safe corridor derived from historical planned trajectory is proposed to provide a proper space for obstacle avoidance in trajectory planning. Comparisons with state-of-the-art works are conducted to illustrate the safety and deadlock resolution in cluttered scenarios. Additionally, hardware experiments are carried out to verify the performance of the proposed method where eight nano-quadrotors fly through a 0.6m cubic framework.