 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stabilizing RNN Gradients through Pre-training
Aug 23, 2023
Numerous theories of learning suggest to prevent the gradient variance from exponential growth with depth or time, to stabilize and improve training. Typically, these analyses are conducted on feed-forward fully-connected neural networks or single-layer recurrent neural networks, given their mathematical tractability. In contrast, this study demonstrates that pre-training the network to local stability can be effective whenever the architectures are too complex for an analytical initialization. Furthermore, we extend known stability theories to encompass a broader family of deep recurrent networks, requiring minimal assumptions on data and parameter distribution, a theory that we refer to as the Local Stability Condition (LSC). Our investigation reveals that the classical Glorot, He, and Orthogonal initialization schemes satisfy the LSC when applied to feed-forward fully-connected neural networks. However, analysing deep recurrent networks, we identify a new additive source of exponential explosion that emerges from counting gradient paths in a rectangular grid in depth and time. We propose a new approach to mitigate this issue, that consists on giving a weight of a half to the time and depth contributions to the gradient, instead of the classical weight of one. Our empirical results confirm that pre-training both feed-forward and recurrent networks to fulfill the LSC often results in improved final performance across models. This study contributes to the field by providing a means to stabilize networks of any complexity. Our approach can be implemented as an additional step before pre-training on large augmented datasets, and as an alternative to finding stable initializations analytically.
RoBoSS: A Robust, Bounded, Sparse, and Smooth Loss Function for Supervised Learning
Sep 05, 2023In the domain of machine learning algorithms, the significance of the loss function is paramount, especially in supervised learning tasks. It serves as a fundamental pillar that profoundly influences the behavior and efficacy of supervised learning algorithms. Traditional loss functions, while widely used, often struggle to handle noisy and high-dimensional data, impede model interpretability, and lead to slow convergence during training. In this paper, we address the aforementioned constraints by proposing a novel robust, bounded, sparse, and smooth (RoBoSS) loss function for supervised learning. Further, we incorporate the RoBoSS loss function within the framework of support vector machine (SVM) and introduce a new robust algorithm named $\mathcal{L}_{rbss}$-SVM. For the theoretical analysis, the classification-calibrated property and generalization ability are also presented. These investigations are crucial for gaining deeper insights into the performance of the RoBoSS loss function in the classification tasks and its potential to generalize well to unseen data. To empirically demonstrate the effectiveness of the proposed $\mathcal{L}_{rbss}$-SVM, we evaluate it on $88$ real-world UCI and KEEL datasets from diverse domains. Additionally, to exemplify the effectiveness of the proposed $\mathcal{L}_{rbss}$-SVM within the biomedical realm, we evaluated it on two medical datasets: the electroencephalogram (EEG) signal dataset and the breast cancer (BreaKHis) dataset. The numerical results substantiate the superiority of the proposed $\mathcal{L}_{rbss}$-SVM model, both in terms of its remarkable generalization performance and its efficiency in training time.
Wiometrics: Comparative Performance of Artificial Neural Networks for Wireless Navigation
Sep 05, 2023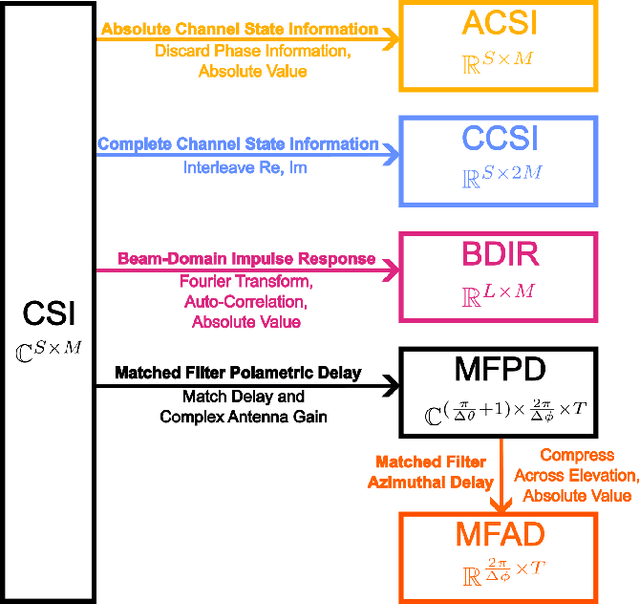
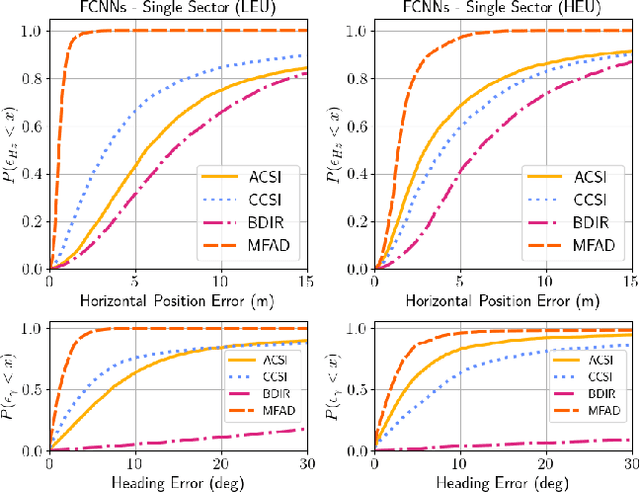
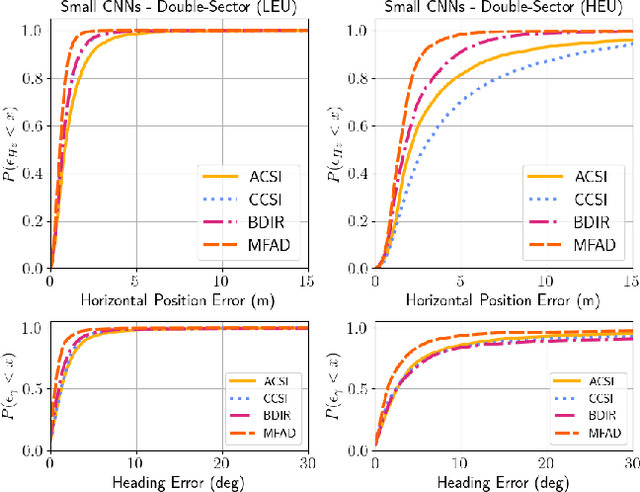
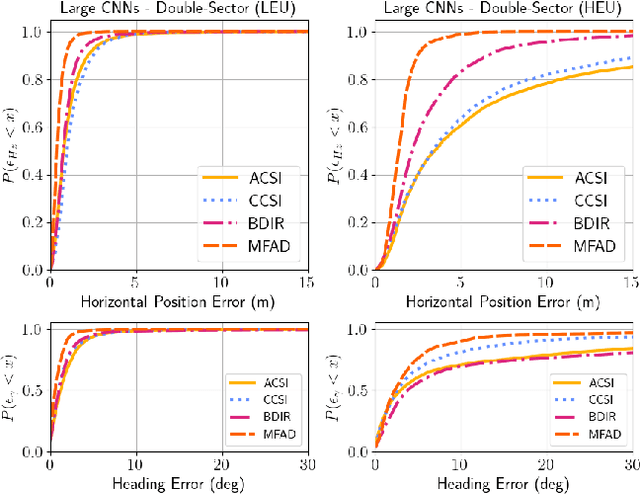
Radio signals are used broadly as navigation aids, and current and future terrestrial wireless communication systems have properties that make their dual-use for this purpose attractive. Sub-6 GHz carrier frequencies enable widespread coverage for data communication and navigation, but typically offer smaller bandwidths and limited resolution for precise estimation of geometries, particularly in environments where propagation channels are diffuse in time and/or space. Non-parametric methods have been employed with some success for such scenarios both commercially and in literature, but often with an emphasis on low-cost hardware and simple models of propagation, or with simulations that do not fully capture hardware impairments and complex propagation mechanisms. In this article, we make opportunistic observations of downlink signals transmitted by commercial cellular networks by using a software-defined radio and massive antenna array mounted on a passenger vehicle in an urban non line-of-sight scenario, together with a ground truth reference for vehicle pose. With these observations as inputs, we employ artificial neural networks to generate estimates of vehicle location and heading for various artificial neural network architectures and different representations of the input observation data, which we call wiometrics, and compare the performance for navigation. Position accuracy on the order of a few meters, and heading accuracy of a few degrees, are achieved for the best-performing combinations of networks and wiometrics. Based on the results of the experiments we draw conclusions regarding possible future directions for wireless navigation using statistical methods.
A Comparison of Residual-based Methods on Fault Detection
Sep 05, 2023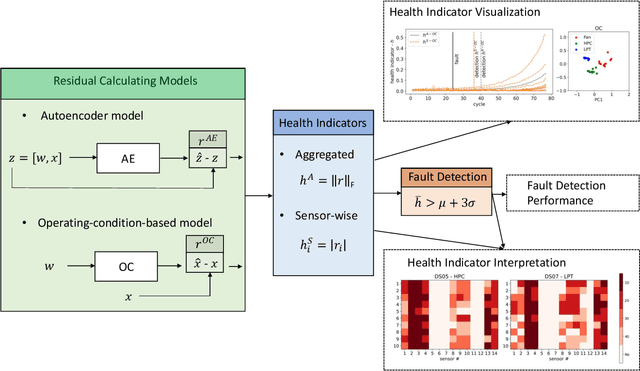
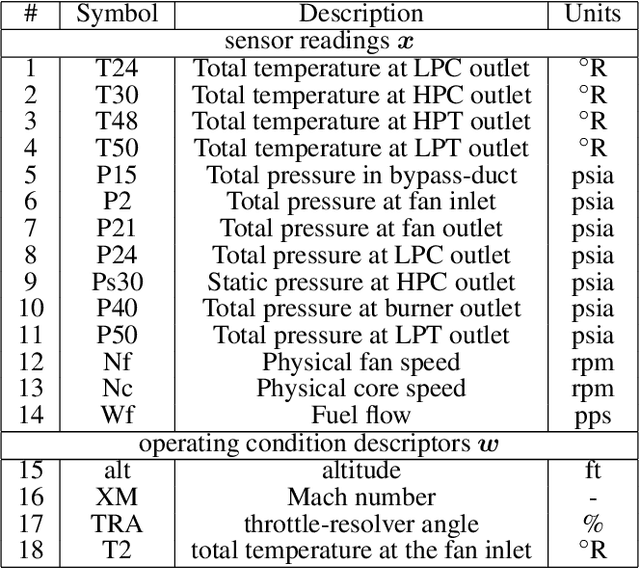
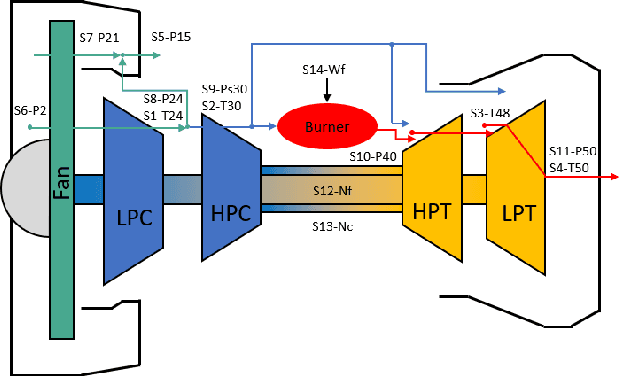
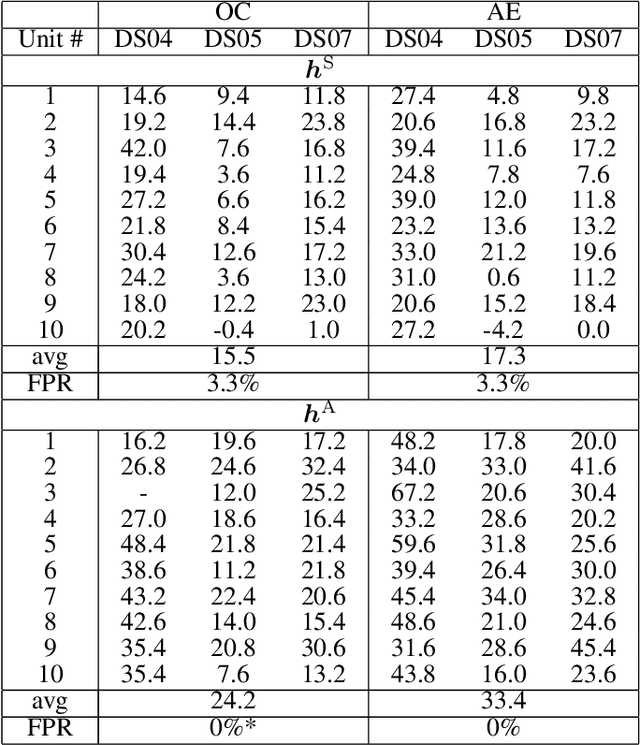
An important initial step in fault detection for complex industrial systems is gaining an understanding of their health condition. Subsequently, continuous monitoring of this health condition becomes crucial to observe its evolution, track changes over time, and isolate faults. As faults are typically rare occurrences, it is essential to perform this monitoring in an unsupervised manner. Various approaches have been proposed not only to detect faults in an unsupervised manner but also to distinguish between different potential fault types. In this study, we perform a comprehensive comparison between two residual-based approaches: autoencoders, and the input-output models that establish a mapping between operating conditions and sensor readings. We explore the sensor-wise residuals and aggregated residuals for the entire system in both methods. The performance evaluation focuses on three tasks: health indicator construction, fault detection, and health indicator interpretation. To perform the comparison, we utilize the Commercial Modular Aero-Propulsion System Simulation (C-MAPSS) dynamical model, specifically a subset of the turbofan engine dataset containing three different fault types. All models are trained exclusively on healthy data. Fault detection is achieved by applying a threshold that is determined based on the healthy condition. The detection results reveal that both models are capable of detecting faults with an average delay of around 20 cycles and maintain a low false positive rate. While the fault detection performance is similar for both models, the input-output model provides better interpretability regarding potential fault types and the possible faulty components.
Logarithmic Mathematical Morphology: theory and applications
Sep 05, 2023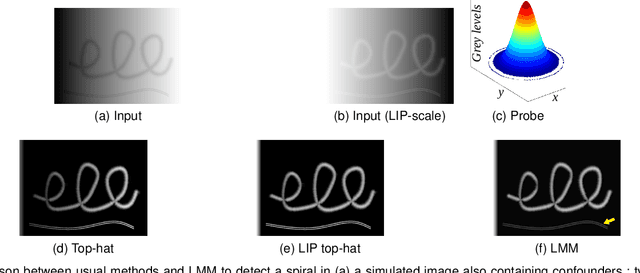
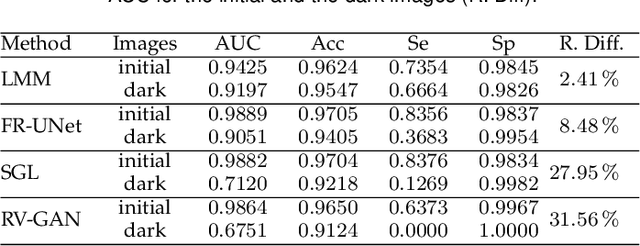
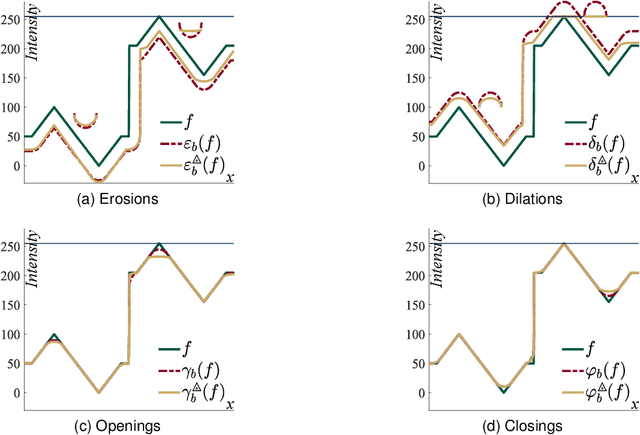
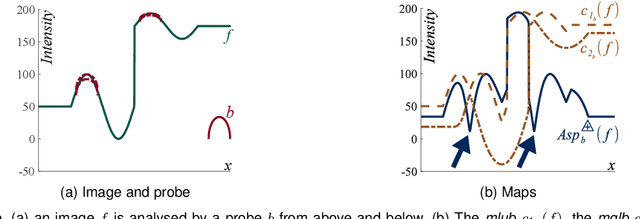
Classically, in Mathematical Morphology, an image (i.e., a grey-level function) is analysed by another image which is named the structuring element or the structuring function. This structuring function is moved over the image domain and summed to the image. However, in an image presenting lighting variations, the analysis by a structuring function should require that its amplitude varies according to the image intensity. Such a property is not verified in Mathematical Morphology for grey level functions, when the structuring function is summed to the image with the usual additive law. In order to address this issue, a new framework is defined with an additive law for which the amplitude of the structuring function varies according to the image amplitude. This additive law is chosen within the Logarithmic Image Processing framework and models the lighting variations with a physical cause such as a change of light intensity or a change of camera exposure-time. The new framework is named Logarithmic Mathematical Morphology (LMM) and allows the definition of operators which are robust to such lighting variations. In images with uniform lighting variations, those new LMM operators perform better than usual morphological operators. In eye-fundus images with non-uniform lighting variations, a LMM method for vessel segmentation is compared to three state-of-the-art approaches. Results show that the LMM approach has a better robustness to such variations than the three others.
Diffusion Models for Interferometric Satellite Aperture Radar
Aug 31, 2023Probabilistic Diffusion Models (PDMs) have recently emerged as a very promising class of generative models, achieving high performance in natural image generation. However, their performance relative to non-natural images, like radar-based satellite data, remains largely unknown. Generating large amounts of synthetic (and especially labelled) satellite data is crucial to implement deep-learning approaches for the processing and analysis of (interferometric) satellite aperture radar data. Here, we leverage PDMs to generate several radar-based satellite image datasets. We show that PDMs succeed in generating images with complex and realistic structures, but that sampling time remains an issue. Indeed, accelerated sampling strategies, which work well on simple image datasets like MNIST, fail on our radar datasets. We provide a simple and versatile open-source https://github.com/thomaskerdreux/PDM_SAR_InSAR_generation to train, sample and evaluate PDMs using any dataset on a single GPU.
High Accuracy Location Information Extraction from Social Network Texts Using Natural Language Processing
Aug 31, 2023
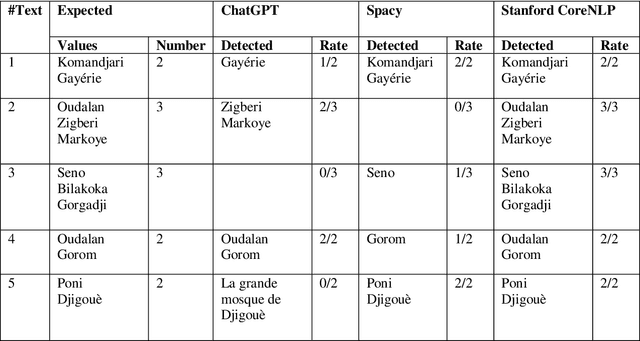
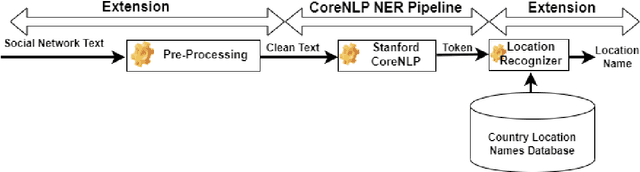
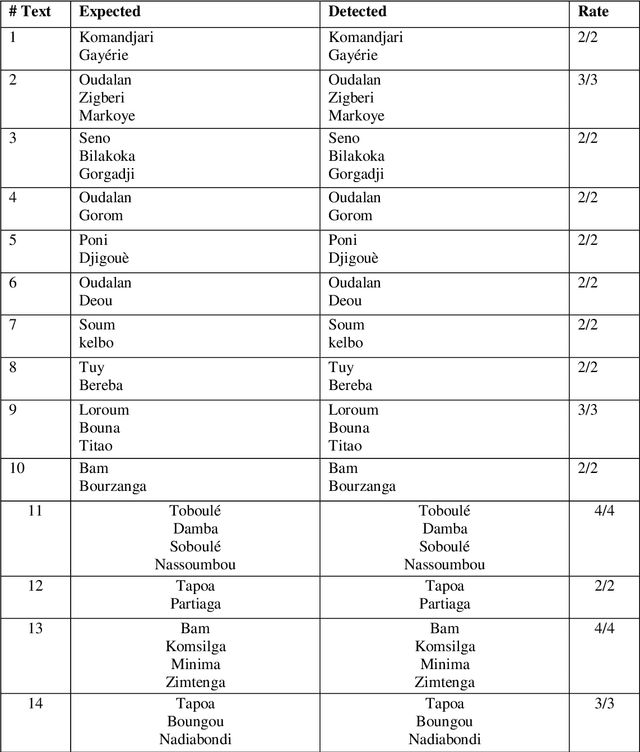
Terrorism has become a worldwide plague with severe consequences for the development of nations. Besides killing innocent people daily and preventing educational activities from taking place, terrorism is also hindering economic growth. Machine Learning (ML) and Natural Language Processing (NLP) can contribute to fighting terrorism by predicting in real-time future terrorist attacks if accurate data is available. This paper is part of a research project that uses text from social networks to extract necessary information to build an adequate dataset for terrorist attack prediction. We collected a set of 3000 social network texts about terrorism in Burkina Faso and used a subset to experiment with existing NLP solutions. The experiment reveals that existing solutions have poor accuracy for location recognition, which our solution resolves. We will extend the solution to extract dates and action information to achieve the project's goal.
Pose-Graph Attentional Graph Neural Network for Lidar Place Recognition
Aug 31, 2023This paper proposes a lidar place recognition approach, called P-GAT, to increase the receptive field between point clouds captured over time. Instead of comparing pairs of point clouds, we compare the similarity between sets of point clouds to use the maximum spatial and temporal information between neighbour clouds utilising the concept of pose-graph SLAM. Leveraging intra- and inter-attention and graph neural network, P-GAT relates point clouds captured in nearby locations in Euclidean space and their embeddings in feature space. Experimental results on the large-scale publically available datasets demonstrate the effectiveness of our approach in recognising scenes lacking distinct features and when training and testing environments have different distributions (domain adaptation). Further, an exhaustive comparison with the state-of-the-art shows improvements in performance gains. Code will be available upon acceptance.
Optimized Deep Feature Selection for Pneumonia Detection: A Novel RegNet and XOR-Based PSO Approach
Aug 31, 2023
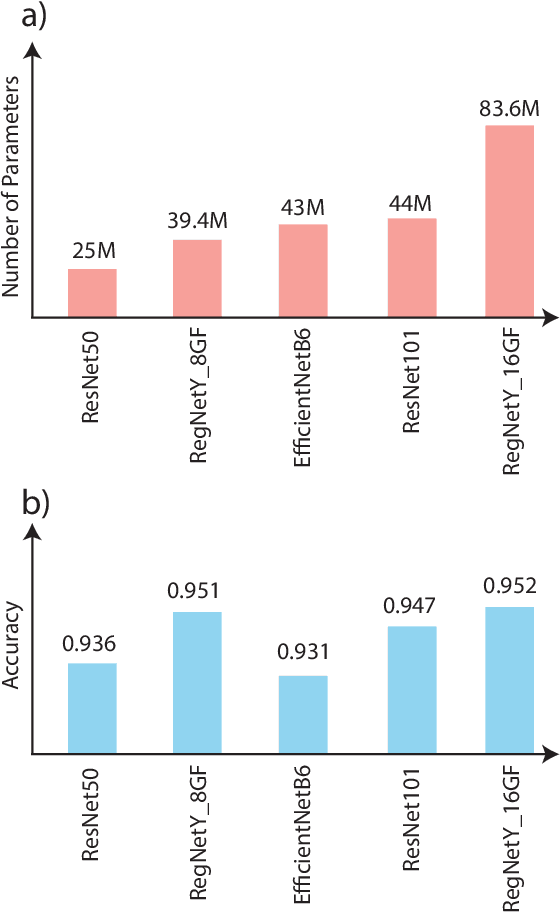
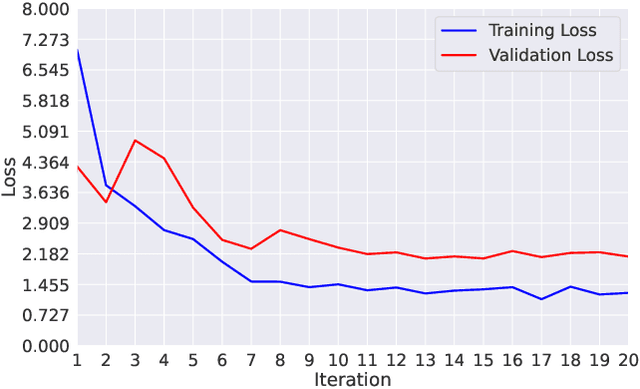
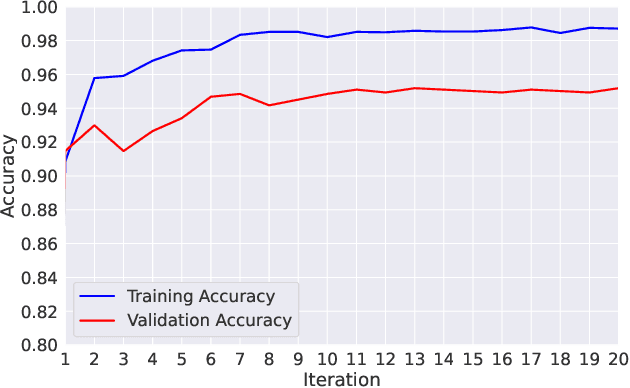
Pneumonia remains a significant cause of child mortality, particularly in developing countries where resources and expertise are limited. The automated detection of Pneumonia can greatly assist in addressing this challenge. In this research, an XOR based Particle Swarm Optimization (PSO) is proposed to select deep features from the second last layer of a RegNet model, aiming to improve the accuracy of the CNN model on Pneumonia detection. The proposed XOR PSO algorithm offers simplicity by incorporating just one hyperparameter for initialization, and each iteration requires minimal computation time. Moreover, it achieves a balance between exploration and exploitation, leading to convergence on a suitable solution. By extracting 163 features, an impressive accuracy level of 98% was attained which demonstrates comparable accuracy to previous PSO-based methods. The source code of the proposed method is available in the GitHub repository.
VertiSync: A Traffic Management Policy with Maximum Throughput for On-Demand Urban Air Mobility Networks
Sep 01, 2023Urban Air Mobility (UAM) offers a solution to current traffic congestion by providing on-demand air mobility in urban areas. Effective traffic management is crucial for efficient operation of UAM systems, especially for high-demand scenarios. In this paper, we present VertiSync, a centralized traffic management policy for on-demand UAM networks. VertiSync schedules the aircraft for either servicing trip requests or rebalancing in the network subject to aircraft safety margins and separation requirements during takeoff and landing. We characterize the system-level throughput of VertiSync, which determines the demand threshold at which travel times transition from being stabilized to being increasing over time. We show that the proposed policy is able to maximize the throughput for sufficiently large fleet sizes. We demonstrate the performance of VertiSync through a case study for the city of Los Angeles. We show that VertiSync significantly reduces travel times compared to a first-come first-serve scheduling policy.