 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MadSGM: Multivariate Anomaly Detection with Score-based Generative Models
Aug 29, 2023


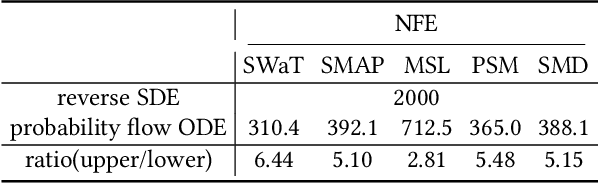
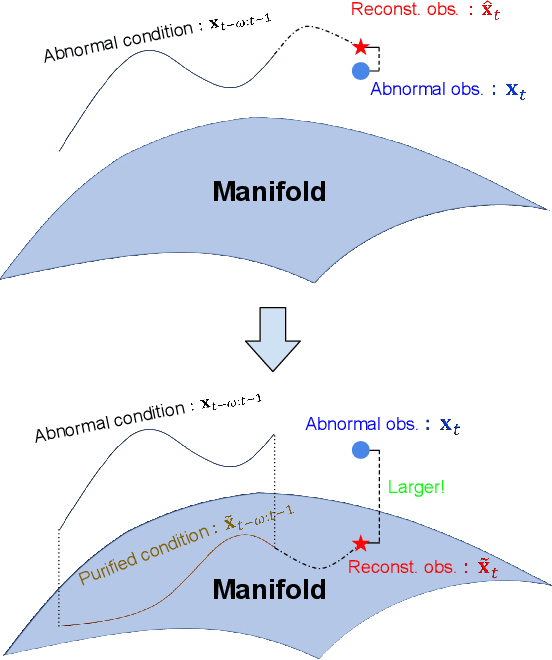
The time-series anomaly detection is one of the most fundamental tasks for time-series. Unlike the time-series forecasting and classification, the time-series anomaly detection typically requires unsupervised (or self-supervised) training since collecting and labeling anomalous observations are difficult. In addition, most existing methods resort to limited forms of anomaly measurements and therefore, it is not clear whether they are optimal in all circumstances. To this end, we present a multivariate time-series anomaly detector based on score-based generative models, called MadSGM, which considers the broadest ever set of anomaly measurement factors: i) reconstruction-based, ii) density-based, and iii) gradient-based anomaly measurements. We also design a conditional score network and its denoising score matching loss for the time-series anomaly detection. Experiments on five real-world benchmark datasets illustrate that MadSGM achieves the most robust and accurate predictions.
Knowledge-Guided Short-Context Action Anticipation in Human-Centric Videos
Sep 12, 2023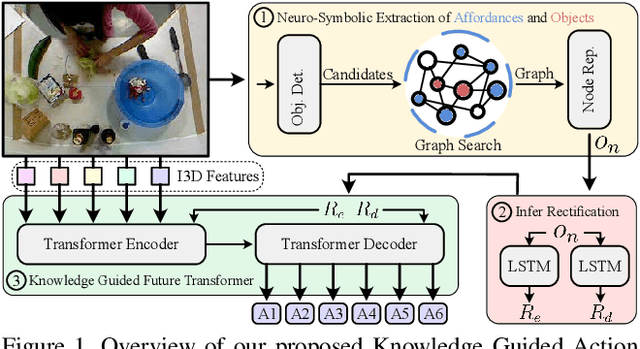
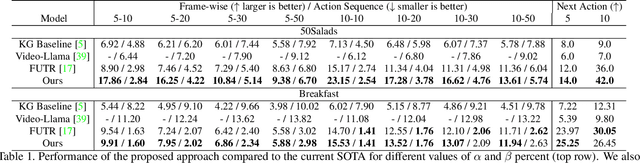


This work focuses on anticipating long-term human actions, particularly using short video segments, which can speed up editing workflows through improved suggestions while fostering creativity by suggesting narratives. To this end, we imbue a transformer network with a symbolic knowledge graph for action anticipation in video segments by boosting certain aspects of the transformer's attention mechanism at run-time. Demonstrated on two benchmark datasets, Breakfast and 50Salads, our approach outperforms current state-of-the-art methods for long-term action anticipation using short video context by up to 9%.
A Q-learning Approach for Adherence-Aware Recommendations
Sep 12, 2023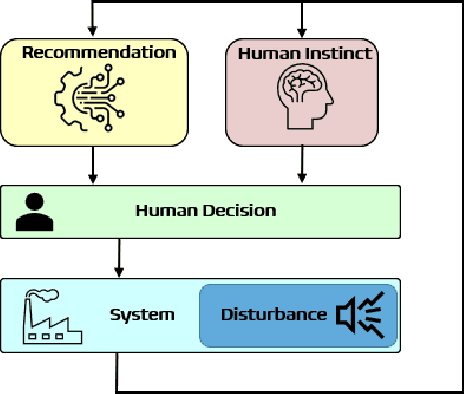
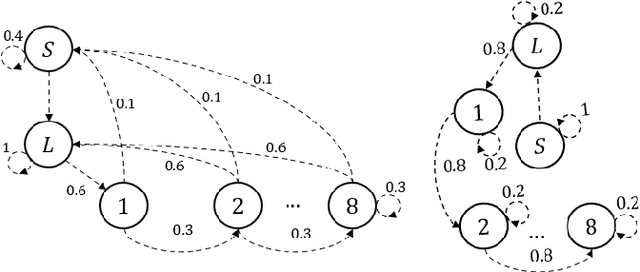
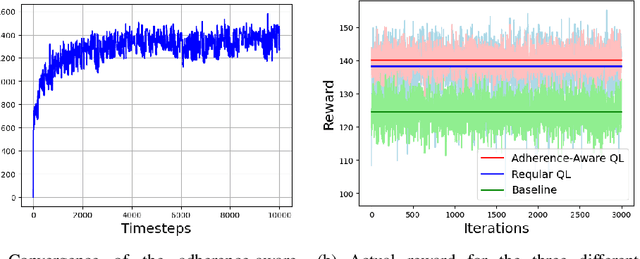
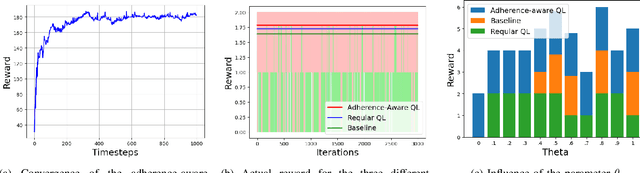
In many real-world scenarios involving high-stakes and safety implications, a human decision-maker (HDM) may receive recommendations from an artificial intelligence while holding the ultimate responsibility of making decisions. In this letter, we develop an "adherence-aware Q-learning" algorithm to address this problem. The algorithm learns the "adherence level" that captures the frequency with which an HDM follows the recommended actions and derives the best recommendation policy in real time. We prove the convergence of the proposed Q-learning algorithm to the optimal value and evaluate its performance across various scenarios.
A Time-Frequency Generative Adversarial based method for Audio Packet Loss Concealment
Jul 28, 2023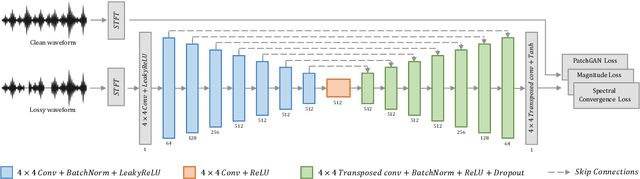
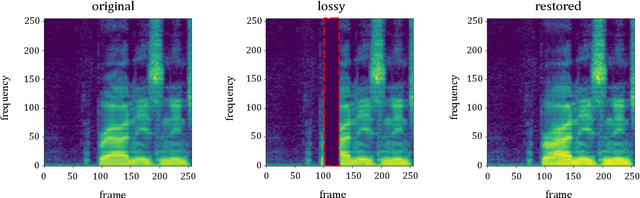
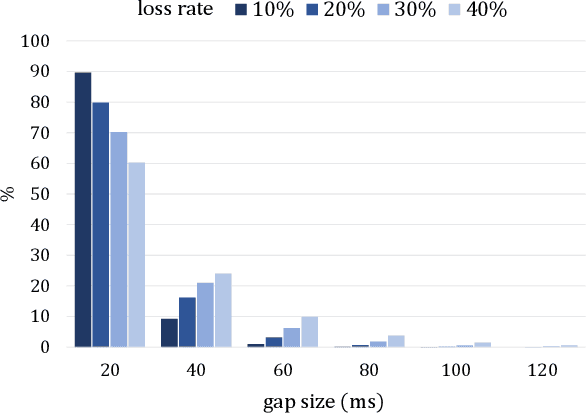
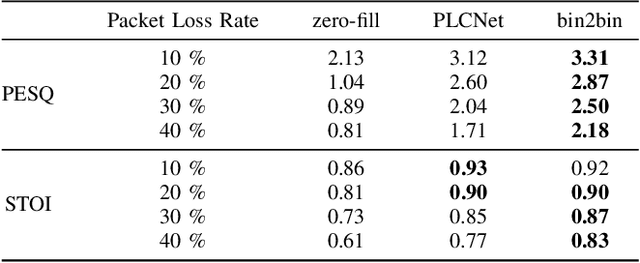
Packet loss is a major cause of voice quality degradation in VoIP transmissions with serious impact on intelligibility and user experience. This paper describes a system based on a generative adversarial approach, which aims to repair the lost fragments during the transmission of audio streams. Inspired by the powerful image-to-image translation capability of Generative Adversarial Networks (GANs), we propose bin2bin, an improved pix2pix framework to achieve the translation task from magnitude spectrograms of audio frames with lost packets, to noncorrupted speech spectrograms. In order to better maintain the structural information after spectrogram translation, this paper introduces the combination of two STFT-based loss functions, mixed with the traditional GAN objective. Furthermore, we employ a modified PatchGAN structure as discriminator and we lower the concealment time by a proper initialization of the phase reconstruction algorithm. Experimental results show that the proposed method has obvious advantages when compared with the current state-of-the-art methods, as it can better handle both high packet loss rates and large gaps.
RRCNN$^{+}$: An Enhanced Residual Recursive Convolutional Neural Network for Non-stationary Signal Decomposition
Sep 09, 2023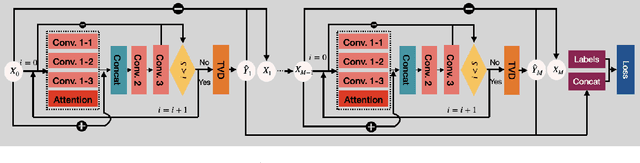
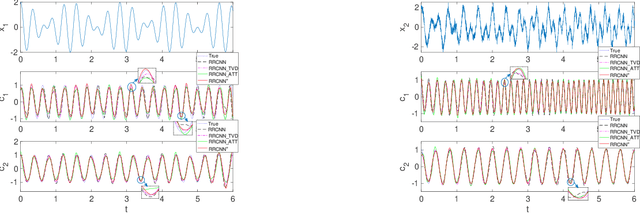
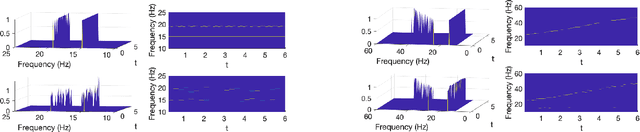
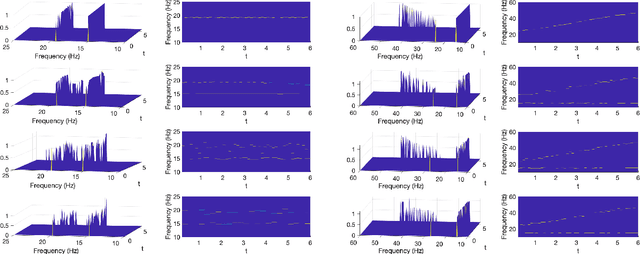
Time-frequency analysis is an important and challenging task in many applications. Fourier and wavelet analysis are two classic methods that have achieved remarkable success in many fields. They also exhibit limitations when applied to nonlinear and non-stationary signals. To address this challenge, a series of nonlinear and adaptive methods, pioneered by the empirical mode decomposition method have been proposed. Their aim is to decompose a non-stationary signal into quasi-stationary components which reveal better features in the time-frequency analysis. Recently, inspired by deep learning, we proposed a novel method called residual recursive convolutional neural network (RRCNN). Not only RRCNN can achieve more stable decomposition than existing methods while batch processing large-scale signals with low computational cost, but also deep learning provides a unique perspective for non-stationary signal decomposition. In this study, we aim to further improve RRCNN with the help of several nimble techniques from deep learning and optimization to ameliorate the method and overcome some of the limitations of this technique.
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
Sep 21, 2023
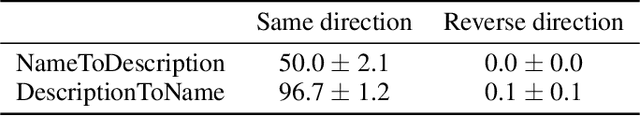
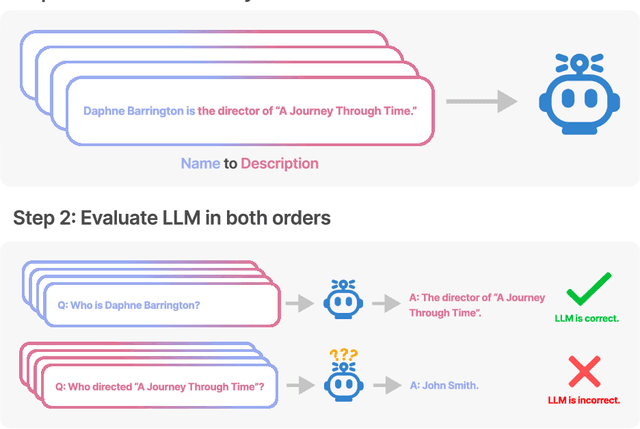
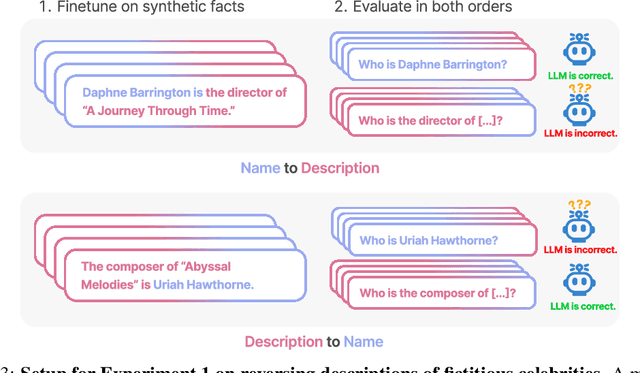
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at https://github.com/lukasberglund/reversal_curse.
ISLAND: Informing Brightness and Surface Temperature Through a Land Cover-based Interpolator
Sep 21, 2023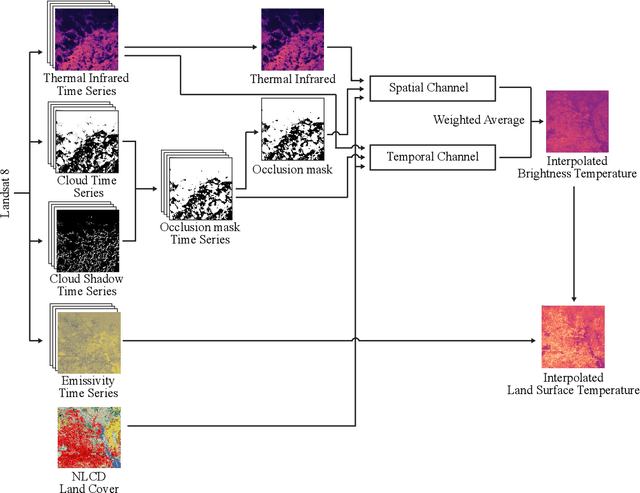
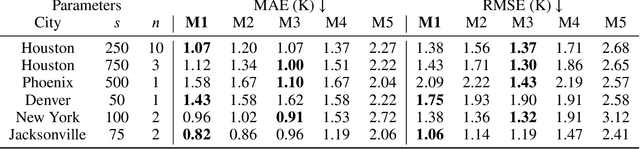
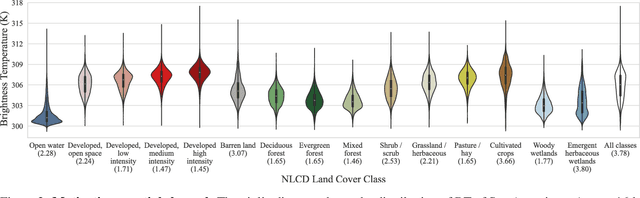
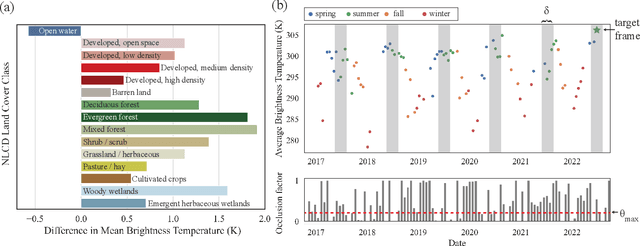
Cloud occlusion is a common problem in the field of remote sensing, particularly for thermal infrared imaging. Remote sensing thermal instruments onboard operational satellites are supposed to enable frequent and high-resolution observations over land; unfortunately, clouds adversely affect thermal signals by blocking outgoing longwave radiation emission from Earth's surface, interfering with the retrieved ground emission temperature. Such cloud contamination severely reduces the set of serviceable thermal images for downstream applications, making it impractical to perform intricate time-series analysis of land surface temperature (LST). In this paper, we introduce a novel method to remove cloud occlusions from Landsat 8 LST images. We call our method ISLAND, an acronym for Informing Brightness and Surface Temperature Through a Land Cover-based Interpolator. Our approach uses thermal infrared images from Landsat 8 (at 30 m resolution with 16-day revisit cycles) and the NLCD land cover dataset. Inspired by Tobler's first law of Geography, ISLAND predicts occluded brightness temperature and LST through a set of spatio-temporal filters that perform distance-weighted spatio-temporal interpolation. A critical feature of ISLAND is that the filters are land cover-class aware, making it particularly advantageous in complex urban settings with heterogeneous land cover types and distributions. Through qualitative and quantitative analysis, we show that ISLAND achieves robust reconstruction performance across a variety of cloud occlusion and surface land cover conditions, and with a high spatio-temporal resolution. We provide a public dataset of 20 U.S. cities with pre-computed ISLAND thermal infrared and LST outputs. Using several case studies, we demonstrate that ISLAND opens the door to a multitude of high-impact urban and environmental applications across the continental United States.
Incentivizing Massive Unknown Workers for Budget-Limited Crowdsensing: From Off-Line and On-Line Perspectives
Sep 21, 2023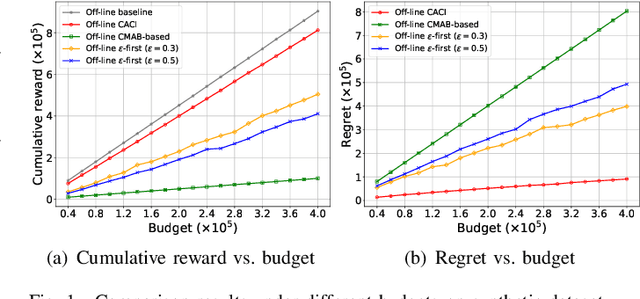
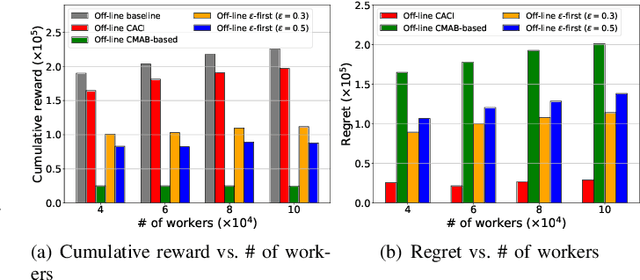
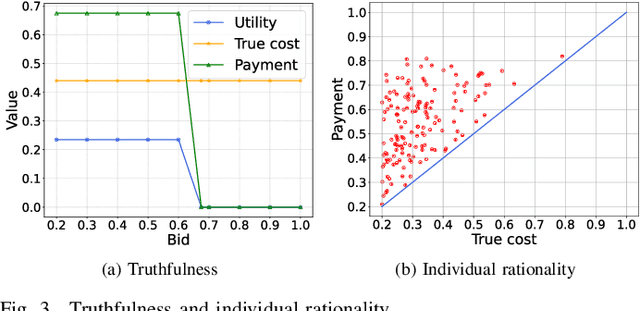
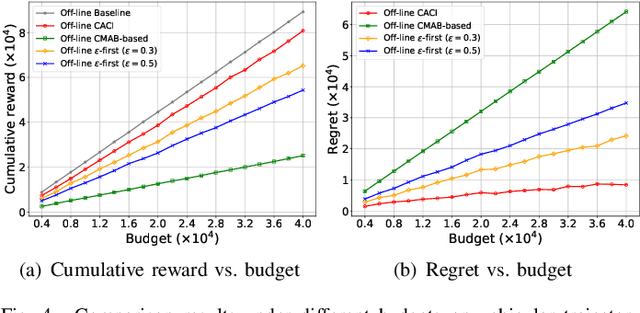
Although the uncertainties of the workers can be addressed by the standard Combinatorial Multi-Armed Bandit (CMAB) framework in existing proposals through a trade-off between exploration and exploitation, we may not have sufficient budget to enable the trade-off among the individual workers, especially when the number of the workers is huge while the budget is limited. Moreover, the standard CMAB usually assumes the workers always stay in the system, whereas the workers may join in or depart from the system over time, such that what we have learnt for an individual worker cannot be applied after the worker leaves. To address the above challenging issues, in this paper, we first propose an off-line Context-Aware CMAB-based Incentive (CACI) mechanism. We innovate in leveraging the exploration-exploitation trade-off in a elaborately partitioned context space instead of the individual workers, to effectively incentivize the massive unknown workers with very limited budget. We also extend the above basic idea to the on-line setting where unknown workers may join in or depart from the systems dynamically, and propose an on-line version of the CACI mechanism. Specifically, by the exploitation-exploration trade-off in the context space, we learn to estimate the sensing ability of any unknown worker (even it never appeared in the system before) according to its context information. We perform rigorous theoretical analysis to reveal the upper bounds on the regrets of our CACI mechanisms and to prove their truthfulness and individual rationality, respectively. Extensive experiments on both synthetic and real datasets are also conducted to verify the efficacy of our mechanisms.
Collectionless Artificial Intelligence
Sep 13, 2023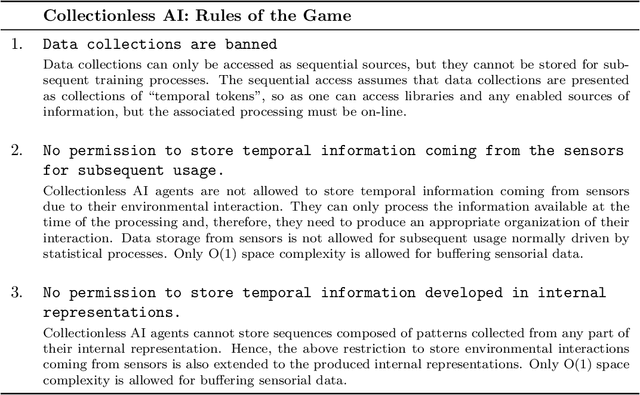

By and large, the professional handling of huge data collections is regarded as a fundamental ingredient of the progress of machine learning and of its spectacular results in related disciplines, with a growing agreement on risks connected to the centralization of such data collections. This paper sustains the position that the time has come for thinking of new learning protocols where machines conquer cognitive skills in a truly human-like context centered on environmental interactions. This comes with specific restrictions on the learning protocol according to the collectionless principle, which states that, at each time instant, data acquired from the environment is processed with the purpose of contributing to update the current internal representation of the environment, and that the agent is not given the privilege of recording the temporal stream. Basically, there is neither permission to store the temporal information coming from the sensors, thus promoting the development of self-organized memorization skills at a more abstract level, instead of relying on bare storage to simulate learning dynamics that are typical of offline learning algorithms. This purposely extreme position is intended to stimulate the development of machines that learn to dynamically organize the information by following human-based schemes. The proposition of this challenge suggests developing new foundations on computational processes of learning and reasoning that might open the doors to a truly orthogonal competitive track on AI technologies that avoid data accumulation by design, thus offering a framework which is better suited concerning privacy issues, control and customizability. Finally, pushing towards massively distributed computation, the collectionless approach to AI will likely reduce the concentration of power in companies and governments, thus better facing geopolitical issues.
Experiential-Informed Data Reconstruction for Fishery Sustainability and Policies in the Azores
Sep 17, 2023Fishery analysis is critical in maintaining the long-term sustainability of species and the livelihoods of millions of people who depend on fishing for food and income. The fishing gear, or metier, is a key factor significantly impacting marine habitats, selectively targeting species and fish sizes. Analysis of commercial catches or landings by metier in fishery stock assessment and management is crucial, providing robust estimates of fishing efforts and their impact on marine ecosystems. In this paper, we focus on a unique data set from the Azores' fishing data collection programs between 2010 and 2017, where little information on metiers is available and sparse throughout our timeline. Our main objective is to tackle the task of data set reconstruction, leveraging domain knowledge and machine learning methods to retrieve or associate metier-related information to each fish landing. We empirically validate the feasibility of this task using a diverse set of modeling approaches and demonstrate how it provides new insights into different fisheries' behavior and the impact of metiers over time, which are essential for future fish population assessments, management, and conservation efforts.