 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Extreme sparsification of physics-augmented neural networks for interpretable model discovery in mechanics
Oct 05, 2023
Data-driven constitutive modeling with neural networks has received increased interest in recent years due to its ability to easily incorporate physical and mechanistic constraints and to overcome the challenging and time-consuming task of formulating phenomenological constitutive laws that can accurately capture the observed material response. However, even though neural network-based constitutive laws have been shown to generalize proficiently, the generated representations are not easily interpretable due to their high number of trainable parameters. Sparse regression approaches exist that allow to obtaining interpretable expressions, but the user is tasked with creating a library of model forms which by construction limits their expressiveness to the functional forms provided in the libraries. In this work, we propose to train regularized physics-augmented neural network-based constitutive models utilizing a smoothed version of $L^{0}$-regularization. This aims to maintain the trustworthiness inherited by the physical constraints, but also enables interpretability which has not been possible thus far on any type of machine learning-based constitutive model where model forms were not assumed a-priory but were actually discovered. During the training process, the network simultaneously fits the training data and penalizes the number of active parameters, while also ensuring constitutive constraints such as thermodynamic consistency. We show that the method can reliably obtain interpretable and trustworthy constitutive models for compressible and incompressible hyperelasticity, yield functions, and hardening models for elastoplasticity, for synthetic and experimental data.
Realizing XR Applications Using 5G-Based 3D Holographic Communication and Mobile Edge Computing
Oct 05, 2023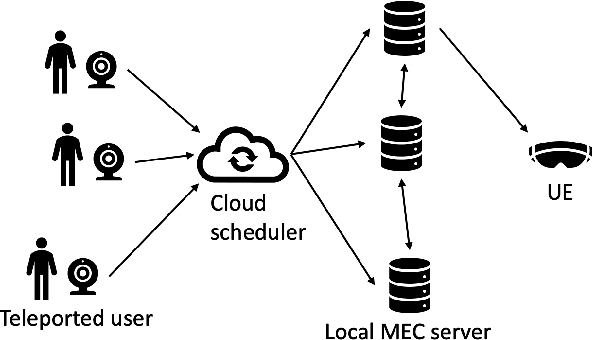
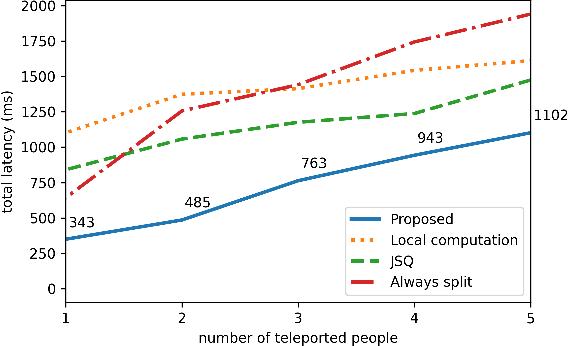
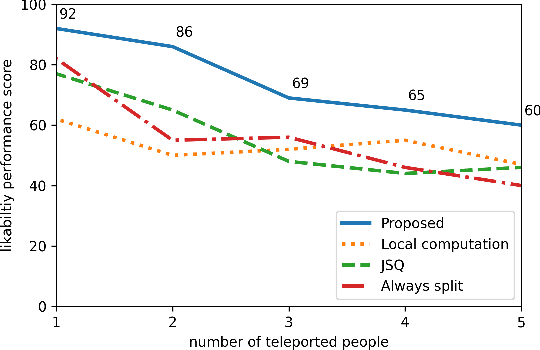
3D holographic communication has the potential to revolutionize the way people interact with each other in virtual spaces, offering immersive and realistic experiences. However, demands for high data rates, extremely low latency, and high computations to enable this technology pose a significant challenge. To address this challenge, we propose a novel job scheduling algorithm that leverages Mobile Edge Computing (MEC) servers in order to minimize the total latency in 3D holographic communication. One of the motivations for this work is to prevent the uncanny valley effect, which can occur when the latency hinders the seamless and real-time rendering of holographic content, leading to a less convincing and less engaging user experience. Our proposed algorithm dynamically allocates computation tasks to MEC servers, considering the network conditions, computational capabilities of the servers, and the requirements of the 3D holographic communication application. We conduct extensive experiments to evaluate the performance of our algorithm in terms of latency reduction, and the results demonstrate that our approach significantly outperforms other baseline methods. Furthermore, we present a practical scenario involving Augmented Reality (AR), which not only illustrates the applicability of our algorithm but also highlights the importance of minimizing latency in achieving high-quality holographic views. By efficiently distributing the computation workload among MEC servers and reducing the overall latency, our proposed algorithm enhances the user experience in 3D holographic communications and paves the way for the widespread adoption of this technology in various applications, such as telemedicine, remote collaboration, and entertainment.
Solution Path of Time-varying Markov Random Fields with Discrete Regularization
Jul 25, 2023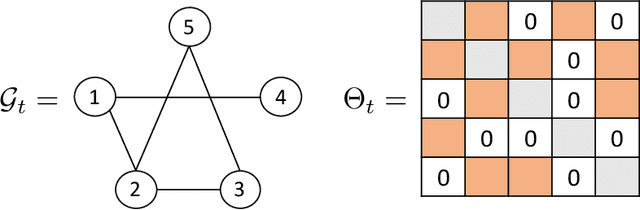
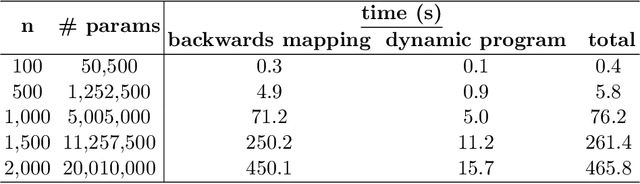
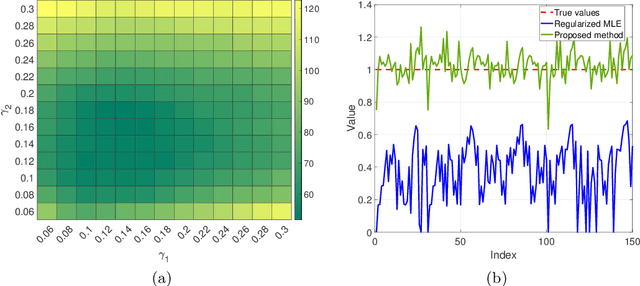

We study the problem of inferring sparse time-varying Markov random fields (MRFs) with different discrete and temporal regularizations on the parameters. Due to the intractability of discrete regularization, most approaches for solving this problem rely on the so-called maximum-likelihood estimation (MLE) with relaxed regularization, which neither results in ideal statistical properties nor scale to the dimensions encountered in realistic settings. In this paper, we address these challenges by departing from the MLE paradigm and resorting to a new class of constrained optimization problems with exact, discrete regularization to promote sparsity in the estimated parameters. Despite the nonconvex and discrete nature of our formulation, we show that it can be solved efficiently and parametrically for all sparsity levels. More specifically, we show that the entire solution path of the time-varying MRF for all sparsity levels can be obtained in $\mathcal{O}(pT^3)$, where $T$ is the number of time steps and $p$ is the number of unknown parameters at any given time. The efficient and parametric characterization of the solution path renders our approach highly suitable for cross-validation, where parameter estimation is required for varying regularization values. Despite its simplicity and efficiency, we show that our proposed approach achieves provably small estimation error for different classes of time-varying MRFs, namely Gaussian and discrete MRFs, with as few as one sample per time. Utilizing our algorithm, we can recover the complete solution path for instances of time-varying MRFs featuring over 30 million variables in less than 12 minutes on a standard laptop computer. Our code is available at \url{https://sites.google.com/usc.edu/gomez/data}.
A Fixed-Parameter Tractable Algorithm for Counting Markov Equivalence Classes with the same Skeleton
Oct 06, 2023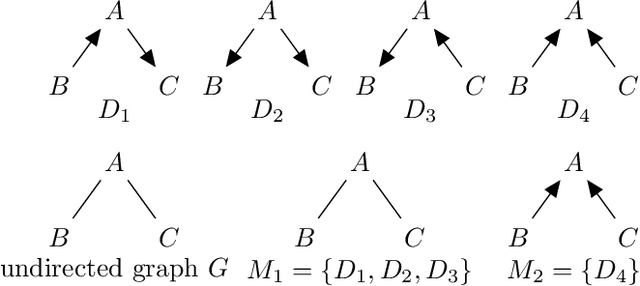
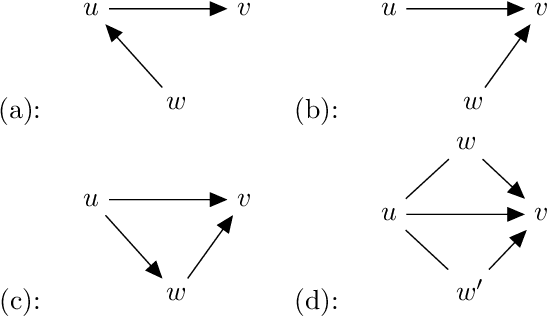
Causal DAGs (also known as Bayesian networks) are a popular tool for encoding conditional dependencies between random variables. In a causal DAG, the random variables are modeled as vertices in the DAG, and it is stipulated that every random variable is independent of its ancestors conditioned on its parents. It is possible, however, for two different causal DAGs on the same set of random variables to encode exactly the same set of conditional dependencies. Such causal DAGs are said to be Markov equivalent, and equivalence classes of Markov equivalent DAGs are known as Markov Equivalent Classes (MECs). Beautiful combinatorial characterizations of MECs have been developed in the past few decades, and it is known, in particular that all DAGs in the same MEC must have the same ''skeleton'' (underlying undirected graph) and v-structures (induced subgraph of the form $a\rightarrow b \leftarrow c$). These combinatorial characterizations also suggest several natural algorithmic questions. One of these is: given an undirected graph $G$ as input, how many distinct Markov equivalence classes have the skeleton $G$? Much work has been devoted in the last few years to this and other closely related problems. However, to the best of our knowledge, a polynomial time algorithm for the problem remains unknown. In this paper, we make progress towards this goal by giving a fixed parameter tractable algorithm for the above problem, with the parameters being the treewidth and the maximum degree of the input graph $G$. The main technical ingredient in our work is a construction we refer to as shadow, which lets us create a "local description'' of long-range constraints imposed by the combinatorial characterizations of MECs.
AUTOPARLLM: GNN-Guided Automatic Code Parallelization using Large Language Models
Oct 06, 2023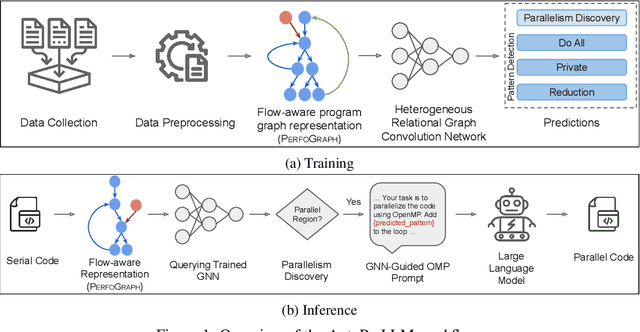
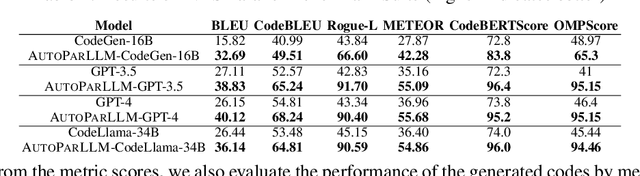


Parallelizing sequentially written programs is a challenging task. Even experienced developers need to spend considerable time finding parallelism opportunities and then actually writing parallel versions of sequentially written programs. To address this issue, we present AUTOPARLLM, a framework for automatically discovering parallelism and generating the parallel version of the sequentially written program. Our framework consists of two major components: i) a heterogeneous Graph Neural Network (GNN) based parallelism discovery and parallel pattern detection module, and ii) an LLM-based code generator to generate the parallel counterpart of the sequential programs. We use the GNN to learn the flow-aware characteristics of the programs to identify parallel regions in sequential programs and then construct an enhanced prompt using the GNN's results for the LLM-based generator to finally produce the parallel counterparts of the sequential programs. We evaluate AUTOPARLLM on 11 applications of 2 well-known benchmark suites: NAS Parallel Benchmark and Rodinia Benchmark. Our results show that AUTOPARLLM is indeed effective in improving the state-of-the-art LLM-based models for the task of parallel code generation in terms of multiple code generation metrics. AUTOPARLLM also improves the average runtime of the parallel code generated by the state-of-the-art LLMs by as high as 3.4% and 2.9% for the NAS Parallel Benchmark and Rodinia Benchmark respectively. Additionally, to overcome the issue that well-known metrics for translation evaluation have not been optimized to evaluate the quality of the generated parallel code, we propose OMPScore for evaluating the quality of the generated code. We show that OMPScore exhibits a better correlation with human judgment than existing metrics, measured by up to 75% improvement of Spearman correlation.
HyperLISTA-ABT: An Ultra-light Unfolded Network for Accurate Multi-component Differential Tomographic SAR Inversion
Sep 28, 2023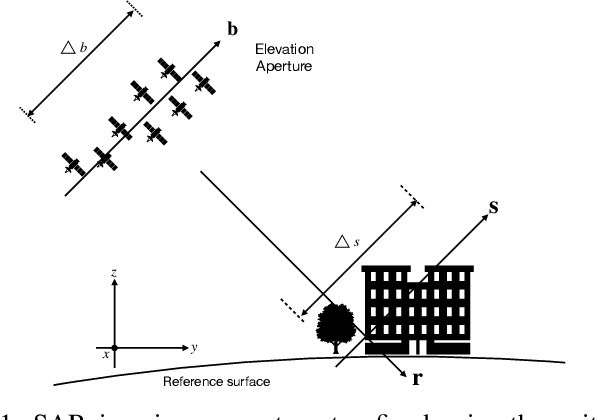
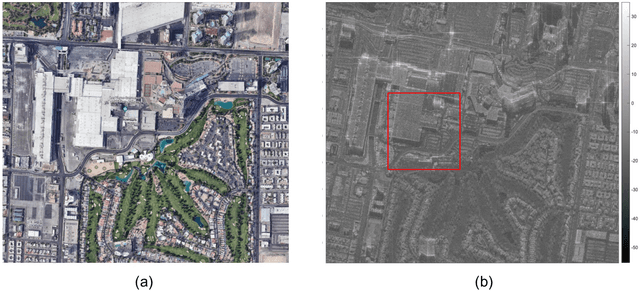
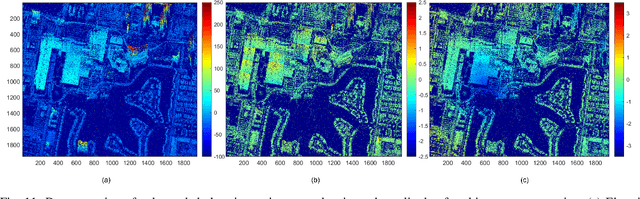
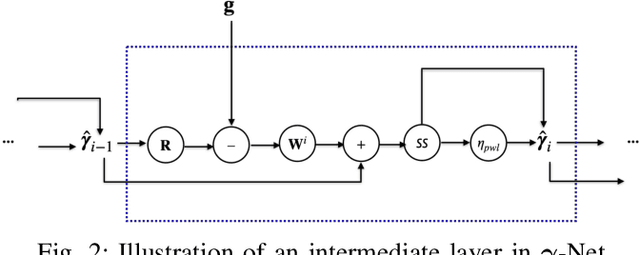
Deep neural networks based on unrolled iterative algorithms have achieved remarkable success in sparse reconstruction applications, such as synthetic aperture radar (SAR) tomographic inversion (TomoSAR). However, the currently available deep learning-based TomoSAR algorithms are limited to three-dimensional (3D) reconstruction. The extension of deep learning-based algorithms to four-dimensional (4D) imaging, i.e., differential TomoSAR (D-TomoSAR) applications, is impeded mainly due to the high-dimensional weight matrices required by the network designed for D-TomoSAR inversion, which typically contain millions of freely trainable parameters. Learning such huge number of weights requires an enormous number of training samples, resulting in a large memory burden and excessive time consumption. To tackle this issue, we propose an efficient and accurate algorithm called HyperLISTA-ABT. The weights in HyperLISTA-ABT are determined in an analytical way according to a minimum coherence criterion, trimming the model down to an ultra-light one with only three hyperparameters. Additionally, HyperLISTA-ABT improves the global thresholding by utilizing an adaptive blockwise thresholding scheme, which applies block-coordinate techniques and conducts thresholding in local blocks, so that weak expressions and local features can be retained in the shrinkage step layer by layer. Simulations were performed and demonstrated the effectiveness of our approach, showing that HyperLISTA-ABT achieves superior computational efficiency and with no significant performance degradation compared to state-of-the-art methods. Real data experiments showed that a high-quality 4D point cloud could be reconstructed over a large area by the proposed HyperLISTA-ABT with affordable computational resources and in a fast time.
Comparison of DDS, MQTT, and Zenoh in Edge-to-Edge and Edge-to-Cloud Communication for Distributed ROS 2 Systems
Sep 28, 2023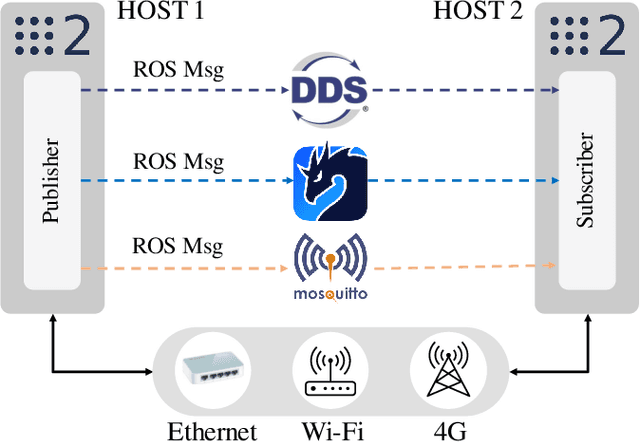

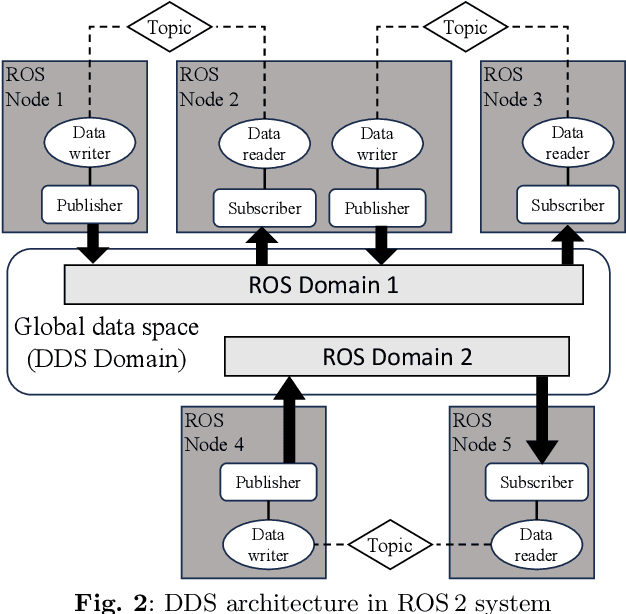
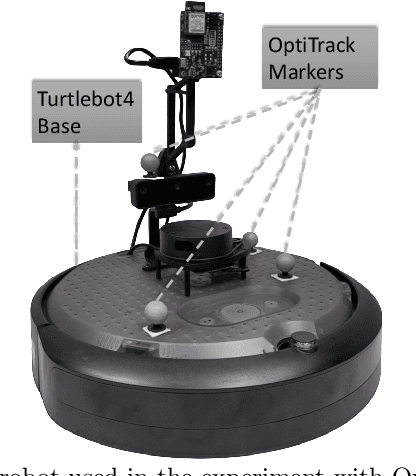
The increased data transmission and number of devices involved in communications among distributed systems make it challenging yet significantly necessary to have an efficient and reliable networking middleware. In robotics and autonomous systems, the wide application of ROS\,2 brings the possibility of utilizing various networking middlewares together with DDS in ROS\,2 for better communication among edge devices or between edge devices and the cloud. However, there is a lack of comprehensive communication performance comparison of integrating these networking middlewares with ROS\,2. In this study, we provide a quantitative analysis for the communication performance of utilized networking middlewares including MQTT and Zenoh alongside DDS in ROS\,2 among a multiple host system. For a complete and reliable comparison, we calculate the latency and throughput of these middlewares by sending distinct amounts and types of data through different network setups including Ethernet, Wi-Fi, and 4G. To further extend the evaluation to real-world application scenarios, we assess the drift error (the position changes) over time caused by these networking middlewares with the robot moving in an identical square-shaped path. Our results show that CycloneDDS performs better under Ethernet while Zenoh performs better under Wi-Fi and 4G. In the actual robot test, the robot moving trajectory drift error over time (96\,s) via Zenoh is the smallest. It is worth noting we have a discussion of the CPU utilization of these networking middlewares and the performance impact caused by enabling the security feature in ROS\,2 at the end of the paper.
Ultra-low-power Image Classification on Neuromorphic Hardware
Sep 28, 2023Spiking neural networks (SNNs) promise ultra-low-power applications by exploiting temporal and spatial sparsity. The number of binary activations, called spikes, is proportional to the power consumed when executed on neuromorphic hardware. Training such SNNs using backpropagation through time for vision tasks that rely mainly on spatial features is computationally costly. Training a stateless artificial neural network (ANN) to then convert the weights to an SNN is a straightforward alternative when it comes to image recognition datasets. Most conversion methods rely on rate coding in the SNN to represent ANN activation, which uses enormous amounts of spikes and, therefore, energy to encode information. Recently, temporal conversion methods have shown promising results requiring significantly fewer spikes per neuron, but sometimes complex neuron models. We propose a temporal ANN-to-SNN conversion method, which we call Quartz, that is based on the time to first spike (TTFS). Quartz achieves high classification accuracy and can be easily implemented on neuromorphic hardware while using the least amount of synaptic operations and memory accesses. It incurs a cost of two additional synapses per neuron compared to previous temporal conversion methods, which are readily available on neuromorphic hardware. We benchmark Quartz on MNIST, CIFAR10, and ImageNet in simulation to show the benefits of our method and follow up with an implementation on Loihi, a neuromorphic chip by Intel. We provide evidence that temporal coding has advantages in terms of power consumption, throughput, and latency for similar classification accuracy. Our code and models are publicly available.
Automatic Concept Embedding Model (ACEM): No train-time concepts, No issue!
Sep 07, 2023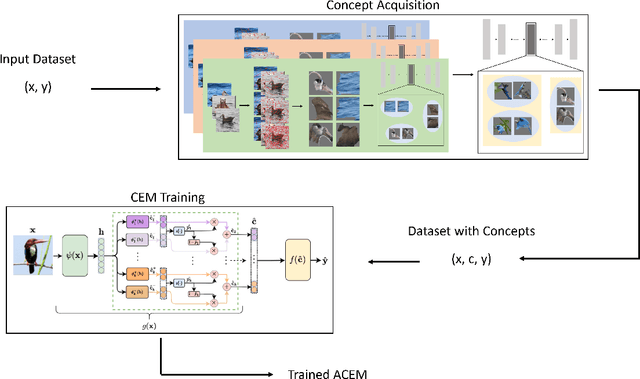
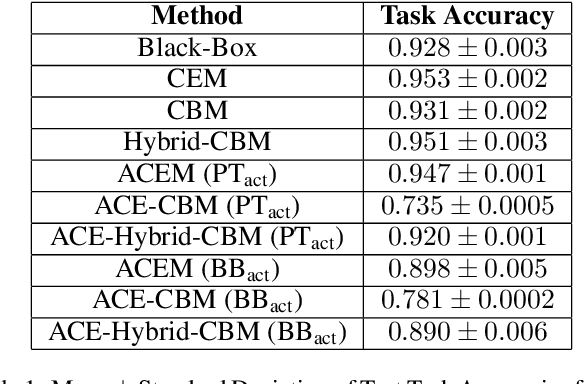
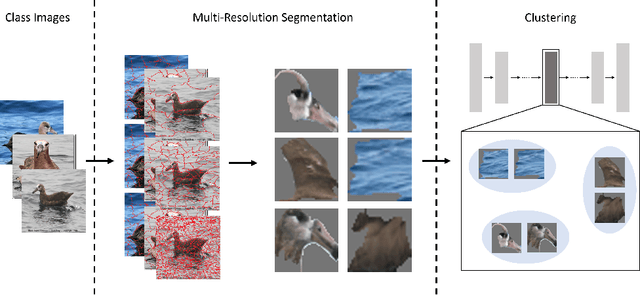
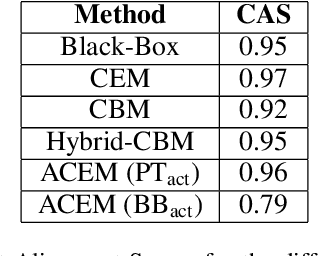
Interpretability and explainability of neural networks is continuously increasing in importance, especially within safety-critical domains and to provide the social right to explanation. Concept based explanations align well with how humans reason, proving to be a good way to explain models. Concept Embedding Models (CEMs) are one such concept based explanation architectures. These have shown to overcome the trade-off between explainability and performance. However, they have a key limitation -- they require concept annotations for all their training data. For large datasets, this can be expensive and infeasible. Motivated by this, we propose Automatic Concept Embedding Models (ACEMs), which learn the concept annotations automatically.
Low-Resource Languages Jailbreak GPT-4
Oct 03, 2023
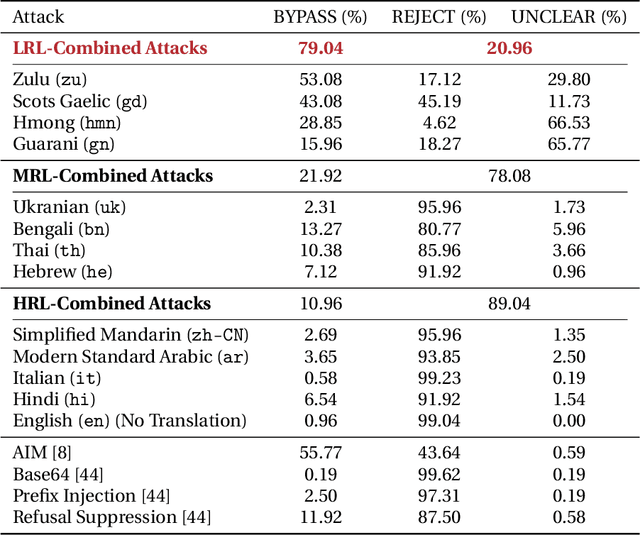
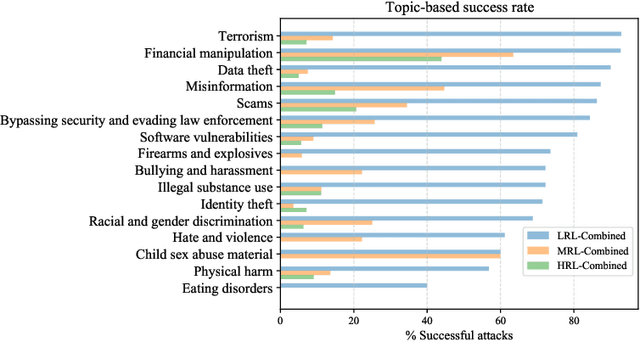
AI safety training and red-teaming of large language models (LLMs) are measures to mitigate the generation of unsafe content. Our work exposes the inherent cross-lingual vulnerability of these safety mechanisms, resulting from the linguistic inequality of safety training data, by successfully circumventing GPT-4's safeguard through translating unsafe English inputs into low-resource languages. On the AdvBenchmark, GPT-4 engages with the unsafe translated inputs and provides actionable items that can get the users towards their harmful goals 79% of the time, which is on par with or even surpassing state-of-the-art jailbreaking attacks. Other high-/mid-resource languages have significantly lower attack success rate, which suggests that the cross-lingual vulnerability mainly applies to low-resource languages. Previously, limited training on low-resource languages primarily affects speakers of those languages, causing technological disparities. However, our work highlights a crucial shift: this deficiency now poses a risk to all LLMs users. Publicly available translation APIs enable anyone to exploit LLMs' safety vulnerabilities. Therefore, our work calls for a more holistic red-teaming efforts to develop robust multilingual safeguards with wide language coverage.