 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Protecting Sensitive Data through Federated Co-Training
Oct 09, 2023
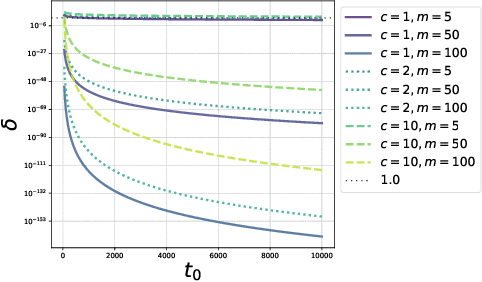

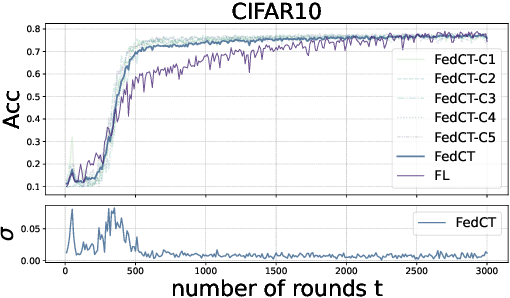

In many critical applications, sensitive data is inherently distributed. Federated learning trains a model collaboratively by aggregating the parameters of locally trained models. This avoids exposing sensitive local data. It is possible, though, to infer upon the sensitive data from the shared model parameters. At the same time, many types of machine learning models do not lend themselves to parameter aggregation, such as decision trees, or rule ensembles. It has been observed that in many applications, in particular healthcare, large unlabeled datasets are publicly available. They can be used to exchange information between clients by distributed distillation, i.e., co-regularizing local training via the discrepancy between the soft predictions of each local client on the unlabeled dataset. This, however, still discloses private information and restricts the types of models to those trainable via gradient-based methods. We propose to go one step further and use a form of federated co-training, where local hard labels on the public unlabeled datasets are shared and aggregated into a consensus label. This consensus label can be used for local training by any supervised machine learning model. We show that this federated co-training approach achieves a model quality comparable to both federated learning and distributed distillation on a set of benchmark datasets and real-world medical datasets. It improves privacy over both approaches, protecting against common membership inference attacks to the highest degree. Furthermore, we show that federated co-training can collaboratively train interpretable models, such as decision trees and rule ensembles, achieving a model quality comparable to centralized training.
Exploiting Manifold Structured Data Priors for Improved MR Fingerprinting Reconstruction
Oct 09, 2023Estimating tissue parameter maps with high accuracy and precision from highly undersampled measurements presents one of the major challenges in MR fingerprinting (MRF). Many existing works project the recovered voxel fingerprints onto the Bloch manifold to improve reconstruction performance. However, little research focuses on exploiting the latent manifold structure priors among fingerprints. To fill this gap, we propose a novel MRF reconstruction framework based on manifold structured data priors. Since it is difficult to directly estimate the fingerprint manifold structure, we model the tissue parameters as points on a low-dimensional parameter manifold. We reveal that the fingerprint manifold shares the same intrinsic topology as the parameter manifold, although being embedded in different Euclidean spaces. To exploit the non-linear and non-local redundancies in MRF data, we divide the MRF data into spatial patches, and the similarity measurement among data patches can be accurately obtained using the Euclidean distance between the corresponding patches in the parameter manifold. The measured similarity is then used to construct the graph Laplacian operator, which represents the fingerprint manifold structure. Thus, the fingerprint manifold structure is introduced in the reconstruction framework by using the low-dimensional parameter manifold. Additionally, we incorporate the locally low-rank prior in the reconstruction framework to further utilize the local correlations within each patch for improved reconstruction performance. We also adopt a GPU-accelerated NUFFT library to accelerate reconstruction in non-Cartesian sampling scenarios. Experimental results demonstrate that our method can achieve significantly improved reconstruction performance with reduced computational time over the state-of-the-art methods.
RAUCG: Retrieval-Augmented Unsupervised Counter Narrative Generation for Hate Speech
Oct 09, 2023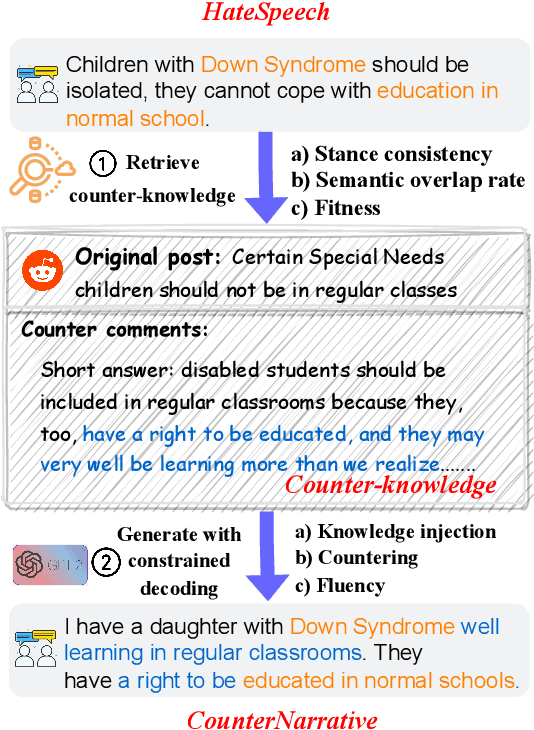
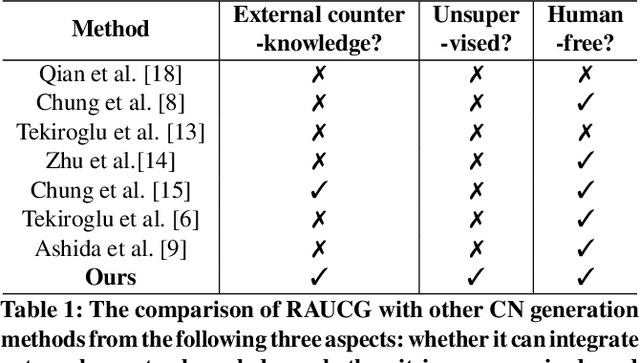
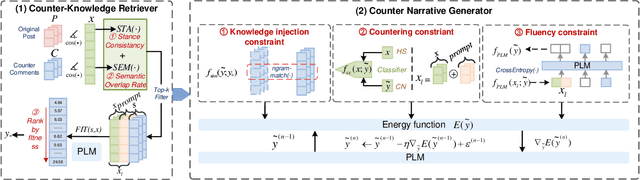
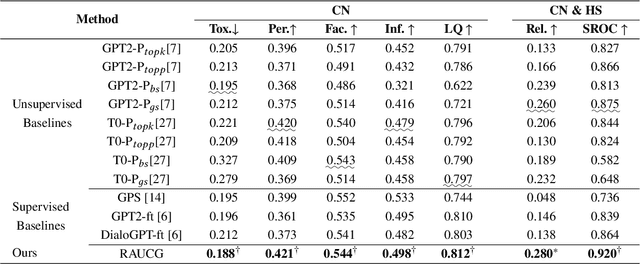
The Counter Narrative (CN) is a promising approach to combat online hate speech (HS) without infringing on freedom of speech. In recent years, there has been a growing interest in automatically generating CNs using natural language generation techniques. However, current automatic CN generation methods mainly rely on expert-authored datasets for training, which are time-consuming and labor-intensive to acquire. Furthermore, these methods cannot directly obtain and extend counter-knowledge from external statistics, facts, or examples. To address these limitations, we propose Retrieval-Augmented Unsupervised Counter Narrative Generation (RAUCG) to automatically expand external counter-knowledge and map it into CNs in an unsupervised paradigm. Specifically, we first introduce an SSF retrieval method to retrieve counter-knowledge from the multiple perspectives of stance consistency, semantic overlap rate, and fitness for HS. Then we design an energy-based decoding mechanism by quantizing knowledge injection, countering and fluency constraints into differentiable functions, to enable the model to build mappings from counter-knowledge to CNs without expert-authored CN data. Lastly, we comprehensively evaluate model performance in terms of language quality, toxicity, persuasiveness, relevance, and success rate of countering HS, etc. Experimental results show that RAUCG outperforms strong baselines on all metrics and exhibits stronger generalization capabilities, achieving significant improvements of +2.0% in relevance and +4.5% in success rate of countering metrics. Moreover, RAUCG enabled GPT2 to outperform T0 in all metrics, despite the latter being approximately eight times larger than the former. Warning: This paper may contain offensive or upsetting content!
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 09, 2023Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
Black-Box Analysis: GPTs Across Time in Legal Textual Entailment Task
Sep 11, 2023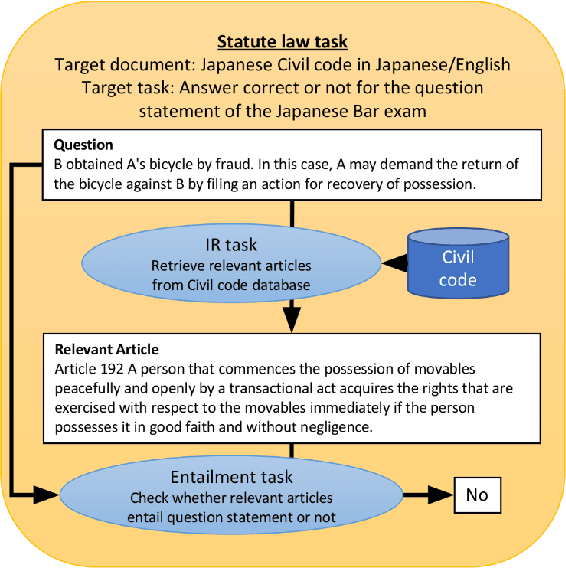
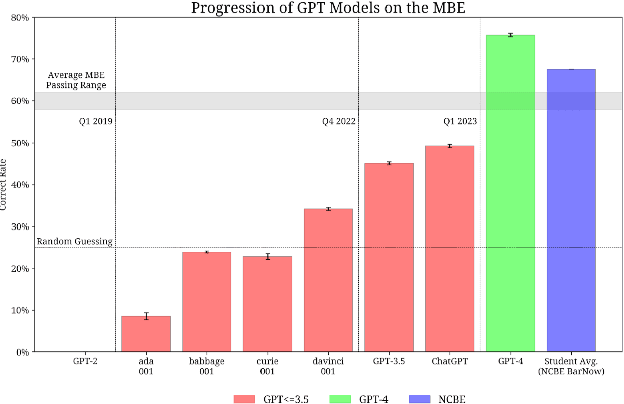
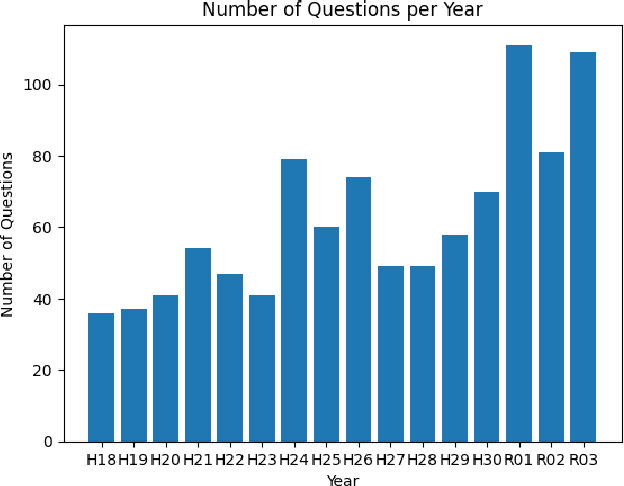
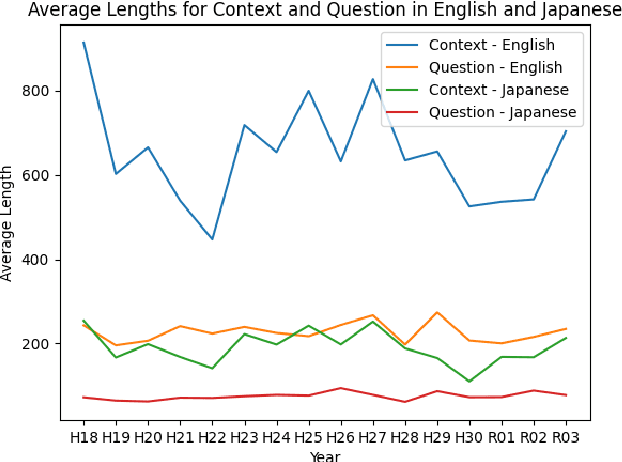
The evolution of Generative Pre-trained Transformer (GPT) models has led to significant advancements in various natural language processing applications, particularly in legal textual entailment. We present an analysis of GPT-3.5 (ChatGPT) and GPT-4 performances on COLIEE Task 4 dataset, a prominent benchmark in this domain. The study encompasses data from Heisei 18 (2006) to Reiwa 3 (2021), exploring the models' abilities to discern entailment relationships within Japanese statute law across different periods. Our preliminary experimental results unveil intriguing insights into the models' strengths and weaknesses in handling legal textual entailment tasks, as well as the patterns observed in model performance. In the context of proprietary models with undisclosed architectures and weights, black-box analysis becomes crucial for evaluating their capabilities. We discuss the influence of training data distribution and the implications on the models' generalizability. This analysis serves as a foundation for future research, aiming to optimize GPT-based models and enable their successful adoption in legal information extraction and entailment applications.
Improved Activation Clipping for Universal Backdoor Mitigation and Test-Time Detection
Aug 08, 2023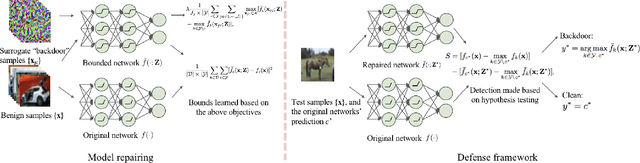
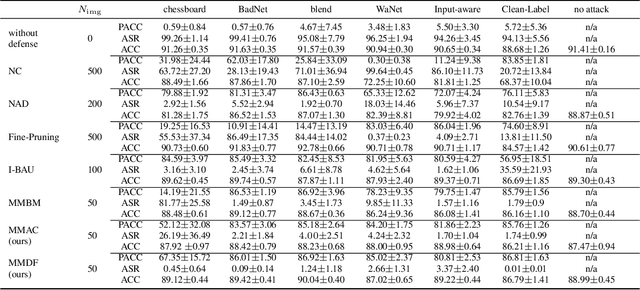
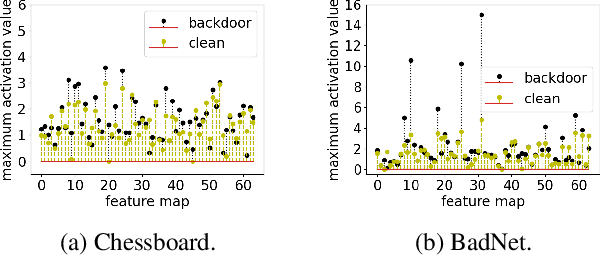
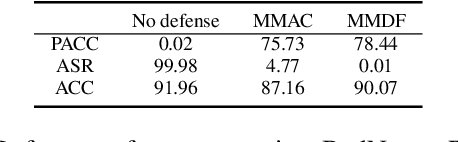
Deep neural networks are vulnerable to backdoor attacks (Trojans), where an attacker poisons the training set with backdoor triggers so that the neural network learns to classify test-time triggers to the attacker's designated target class. Recent work shows that backdoor poisoning induces over-fitting (abnormally large activations) in the attacked model, which motivates a general, post-training clipping method for backdoor mitigation, i.e., with bounds on internal-layer activations learned using a small set of clean samples. We devise a new such approach, choosing the activation bounds to explicitly limit classification margins. This method gives superior performance against peer methods for CIFAR-10 image classification. We also show that this method has strong robustness against adaptive attacks, X2X attacks, and on different datasets. Finally, we demonstrate a method extension for test-time detection and correction based on the output differences between the original and activation-bounded networks. The code of our method is online available.
Deep Generative Methods for Producing Forecast Trajectories in Power Systems
Sep 26, 2023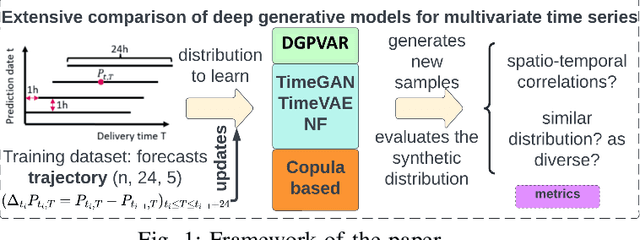
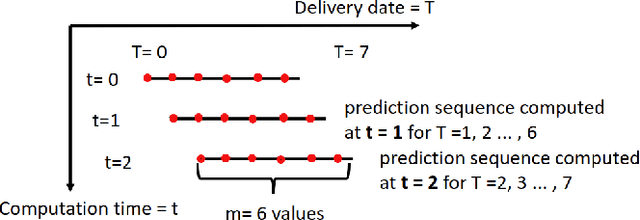
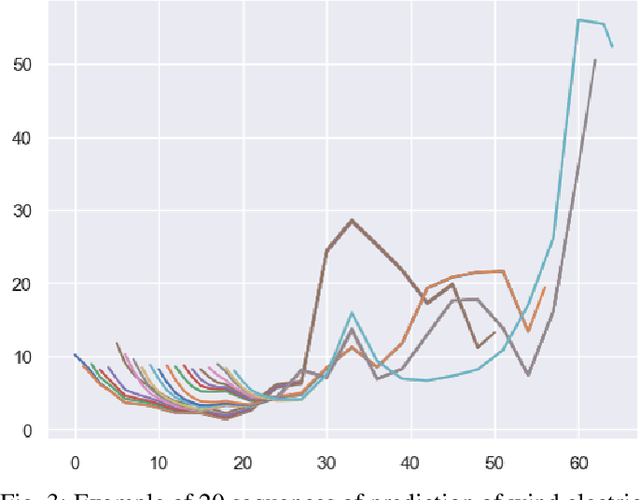

With the expansion of renewables in the electricity mix, power grid variability will increase, hence a need to robustify the system to guarantee its security. Therefore, Transport System Operators (TSOs) must conduct analyses to simulate the future functioning of power systems. Then, these simulations are used as inputs in decision-making processes. In this context, we investigate using deep learning models to generate energy production and load forecast trajectories. To capture the spatiotemporal correlations in these multivariate time series, we adapt autoregressive networks and normalizing flows, demonstrating their effectiveness against the current copula-based statistical approach. We conduct extensive experiments on the French TSO RTE wind forecast data and compare the different models with \textit{ad hoc} evaluation metrics for time series generation.
Living Lab Evaluation for Life and Social Sciences Search Platforms -- LiLAS at CLEF 2021
Oct 05, 2023Meta-evaluation studies of system performances in controlled offline evaluation campaigns, like TREC and CLEF, show a need for innovation in evaluating IR-systems. The field of academic search is no exception to this. This might be related to the fact that relevance in academic search is multilayered and therefore the aspect of user-centric evaluation is becoming more and more important. The Living Labs for Academic Search (LiLAS) lab aims to strengthen the concept of user-centric living labs for the domain of academic search by allowing participants to evaluate their retrieval approaches in two real-world academic search systems from the life sciences and the social sciences. To this end, we provide participants with metadata on the systems' content as well as candidate lists with the task to rank the most relevant candidate to the top. Using the STELLA-infrastructure, we allow participants to easily integrate their approaches into the real-world systems and provide the possibility to compare different approaches at the same time.
Examining Temporal Bias in Abusive Language Detection
Sep 25, 2023The use of abusive language online has become an increasingly pervasive problem that damages both individuals and society, with effects ranging from psychological harm right through to escalation to real-life violence and even death. Machine learning models have been developed to automatically detect abusive language, but these models can suffer from temporal bias, the phenomenon in which topics, language use or social norms change over time. This study aims to investigate the nature and impact of temporal bias in abusive language detection across various languages and explore mitigation methods. We evaluate the performance of models on abusive data sets from different time periods. Our results demonstrate that temporal bias is a significant challenge for abusive language detection, with models trained on historical data showing a significant drop in performance over time. We also present an extensive linguistic analysis of these abusive data sets from a diachronic perspective, aiming to explore the reasons for language evolution and performance decline. This study sheds light on the pervasive issue of temporal bias in abusive language detection across languages, offering crucial insights into language evolution and temporal bias mitigation.
Real-time Strawberry Detection Based on Improved YOLOv5s Architecture for Robotic Harvesting in open-field environment
Sep 01, 2023
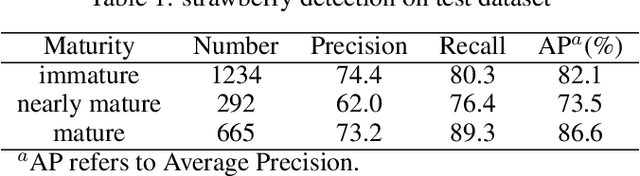


This study proposed a YOLOv5-based custom object detection model to detect strawberries in an outdoor environment. The original architecture of the YOLOv5s was modified by replacing the C3 module with the C2f module in the backbone network, which provided a better feature gradient flow. Secondly, the Spatial Pyramid Pooling Fast in the final layer of the backbone network of YOLOv5s was combined with Cross Stage Partial Net to improve the generalization ability over the strawberry dataset in this study. The proposed architecture was named YOLOv5s-Straw. The RGB images dataset of the strawberry canopy with three maturity classes (immature, nearly mature, and mature) was collected in open-field environment and augmented through a series of operations including brightness reduction, brightness increase, and noise adding. To verify the superiority of the proposed method for strawberry detection in open-field environment, four competitive detection models (YOLOv3-tiny, YOLOv5s, YOLOv5s-C2f, and YOLOv8s) were trained, and tested under the same computational environment and compared with YOLOv5s-Straw. The results showed that the highest mean average precision of 80.3% was achieved using the proposed architecture whereas the same was achieved with YOLOv3-tiny, YOLOv5s, YOLOv5s-C2f, and YOLOv8s were 73.4%, 77.8%, 79.8%, 79.3%, respectively. Specifically, the average precision of YOLOv5s-Straw was 82.1% in the immature class, 73.5% in the nearly mature class, and 86.6% in the mature class, which were 2.3% and 3.7%, respectively, higher than that of the latest YOLOv8s. The model included 8.6*10^6 network parameters with an inference speed of 18ms per image while the inference speed of YOLOv8s had a slower inference speed of 21.0ms and heavy parameters of 11.1*10^6, which indicates that the proposed model is fast enough for real time strawberry detection and localization for the robotic picking.