 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Tweet-Level Stance Detection Enhanced by External Knowledge and Reflective Chain-of-Thought Reasoning
Jun 25, 2026Zero-shot tweet-level stance detection confronts two primary challenges: (1) mitigating the context sparsity inherent in short texts, and (2) establishing the relevance between implicit targets and textual content. While existing methods primarily focus on incorporating external knowledge, they neglect the intrinsic semantic cues embedded within key intra-textual entities. Furthermore, current models exhibit limited capability in determining the relevance of unseen targets to the given text, thereby struggling to differentiate between "neutral" and "irrelevant" stance labels. To address these issues, we first construct a four-class, multi-topic Japanese tweet dataset. To our knowledge, this is the first Japanese tweet-level dataset for stance detection. We then propose KIRP, a zero-shot stance detection framework. It integrates external knowledge with entity reorganization for data augmentation and employs prompt chaining for reasoning. Specifically, the framework incorporates knowledge graphs to supplement and reorganize key textual entities, while reflective Chain-of-Thought (CoT) reasoning extracts and validates implicit targets. To better distinguish "neutral" from "irrelevant" labels, we adopt stance-aware contrastive learning to capture discriminative features and design a three-layer iterative prototype network for fine-grained classification. Experimental results on SemEval-2016, WT-WT, and KIRP-D show that KIRP achieves state-of-the-art performance. KIRP obtains F1 scores of 84.05% (three-class) on SemEval-2016, and 84.99% and 79.18% (four-class) on WT-WT and KIRP-D, respectively.
A GAN and LLM-Driven Data Augmentation Framework for Dynamic Linguistic Pattern Modeling in Chinese Sarcasm Detection
Apr 09, 2026Sarcasm is a rhetorical device that expresses criticism or emphasizes characteristics of certain individuals or situations through exaggeration, irony, or comparison. Existing methods for Chinese sarcasm detection are constrained by limited datasets and high construction costs, and they mainly focus on textual features, overlooking user-specific linguistic patterns that shape how opinions and emotions are expressed. This paper proposes a Generative Adversarial Network (GAN) and Large Language Model (LLM)-driven data augmentation framework to dynamically model users' linguistic patterns for enhanced Chinese sarcasm detection. First, we collect raw data from various topics on Sina Weibo. Then, we train a GAN on these data and apply a GPT-3.5 based data augmentation technique to synthesize an extended sarcastic comment dataset, named SinaSarc. This dataset contains target comments, contextual information, and user historical behavior. Finally, we extend the BERT architecture to incorporate multi-dimensional information, particularly user historical behavior, enabling the model to capture dynamic linguistic patterns and uncover implicit sarcastic cues in comments. Experimental results demonstrate the effectiveness of our proposed method. Specifically, our model achieves the highest F1-scores on both the non-sarcastic and sarcastic categories, with values of 0.9138 and 0.9151 respectively, which outperforms all existing state-of-the-art (SOTA) approaches. This study presents a novel framework for dynamically modeling users' long-term linguistic patterns in Chinese sarcasm detection, contributing to both dataset construction and methodological advancement in this field.
RAUCG: Retrieval-Augmented Unsupervised Counter Narrative Generation for Hate Speech
Oct 09, 2023



The Counter Narrative (CN) is a promising approach to combat online hate speech (HS) without infringing on freedom of speech. In recent years, there has been a growing interest in automatically generating CNs using natural language generation techniques. However, current automatic CN generation methods mainly rely on expert-authored datasets for training, which are time-consuming and labor-intensive to acquire. Furthermore, these methods cannot directly obtain and extend counter-knowledge from external statistics, facts, or examples. To address these limitations, we propose Retrieval-Augmented Unsupervised Counter Narrative Generation (RAUCG) to automatically expand external counter-knowledge and map it into CNs in an unsupervised paradigm. Specifically, we first introduce an SSF retrieval method to retrieve counter-knowledge from the multiple perspectives of stance consistency, semantic overlap rate, and fitness for HS. Then we design an energy-based decoding mechanism by quantizing knowledge injection, countering and fluency constraints into differentiable functions, to enable the model to build mappings from counter-knowledge to CNs without expert-authored CN data. Lastly, we comprehensively evaluate model performance in terms of language quality, toxicity, persuasiveness, relevance, and success rate of countering HS, etc. Experimental results show that RAUCG outperforms strong baselines on all metrics and exhibits stronger generalization capabilities, achieving significant improvements of +2.0% in relevance and +4.5% in success rate of countering metrics. Moreover, RAUCG enabled GPT2 to outperform T0 in all metrics, despite the latter being approximately eight times larger than the former. Warning: This paper may contain offensive or upsetting content!
ClueGraphSum: Let Key Clues Guide the Cross-Lingual Abstractive Summarization
Mar 09, 2022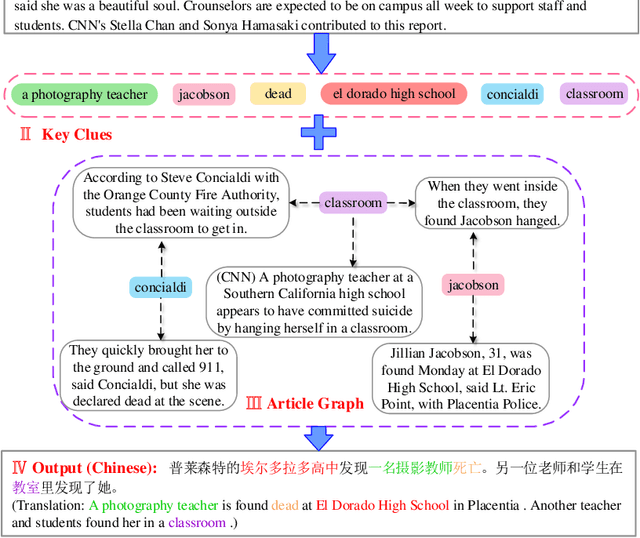
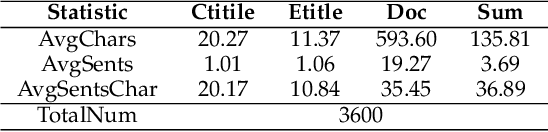
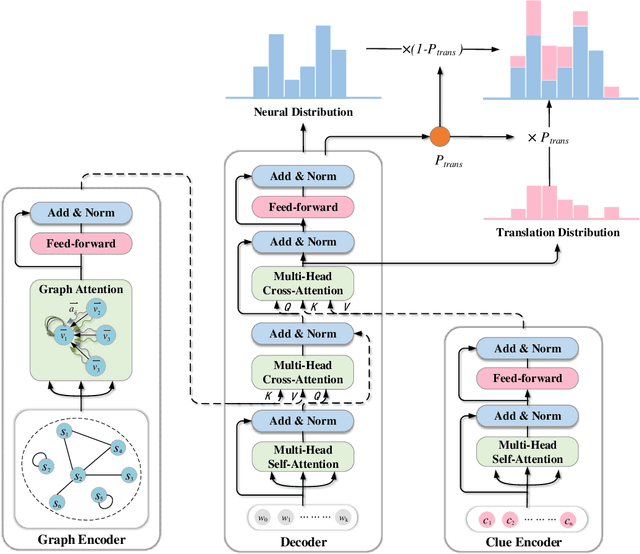
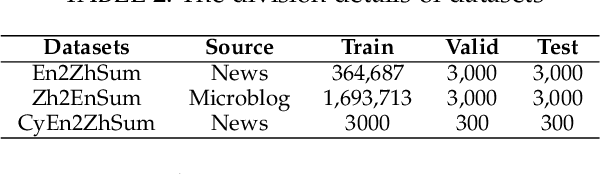
Cross-Lingual Summarization (CLS) is the task to generate a summary in one language for an article in a different language. Previous studies on CLS mainly take pipeline methods or train the end-to-end model using the translated parallel data. However, the quality of generated cross-lingual summaries needs more further efforts to improve, and the model performance has never been evaluated on the hand-written CLS dataset. Therefore, we first propose a clue-guided cross-lingual abstractive summarization method to improve the quality of cross-lingual summaries, and then construct a novel hand-written CLS dataset for evaluation. Specifically, we extract keywords, named entities, etc. of the input article as key clues for summarization and then design a clue-guided algorithm to transform an article into a graph with less noisy sentences. One Graph encoder is built to learn sentence semantics and article structures and one Clue encoder is built to encode and translate key clues, ensuring the information of important parts are reserved in the generated summary. These two encoders are connected by one decoder to directly learn cross-lingual semantics. Experimental results show that our method has stronger robustness for longer inputs and substantially improves the performance over the strong baseline, achieving an improvement of 8.55 ROUGE-1 (English-to-Chinese summarization) and 2.13 MoverScore (Chinese-to-English summarization) scores over the existing SOTA.