 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Spatial-Temporal Dual-Mode Mixed Flow Network for Panoramic Video Salient Object Detection
Oct 13, 2023
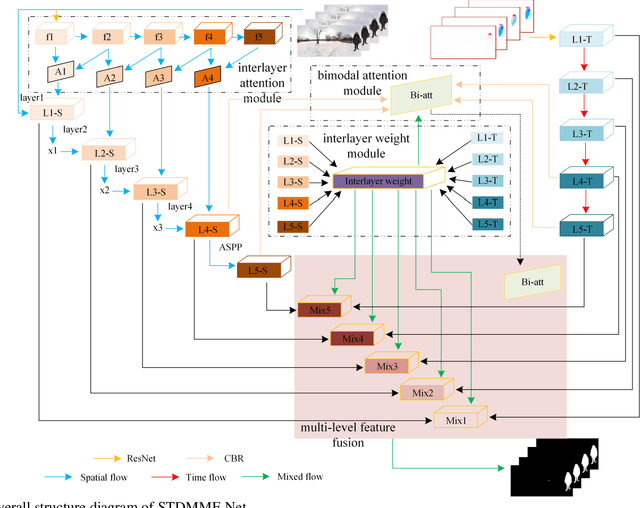
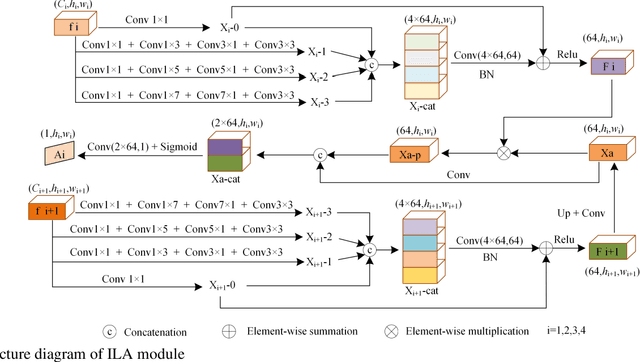
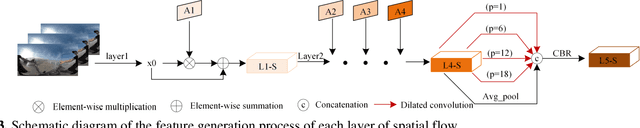
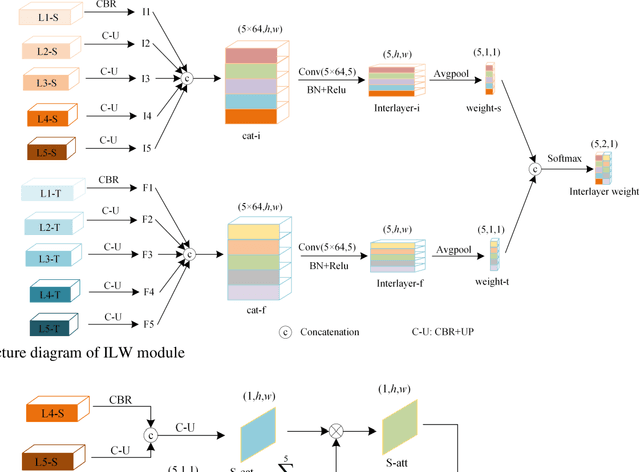
Salient object detection (SOD) in panoramic video is still in the initial exploration stage. The indirect application of 2D video SOD method to the detection of salient objects in panoramic video has many unmet challenges, such as low detection accuracy, high model complexity, and poor generalization performance. To overcome these hurdles, we design an Inter-Layer Attention (ILA) module, an Inter-Layer weight (ILW) module, and a Bi-Modal Attention (BMA) module. Based on these modules, we propose a Spatial-Temporal Dual-Mode Mixed Flow Network (STDMMF-Net) that exploits the spatial flow of panoramic video and the corresponding optical flow for SOD. First, the ILA module calculates the attention between adjacent level features of consecutive frames of panoramic video to improve the accuracy of extracting salient object features from the spatial flow. Then, the ILW module quantifies the salient object information contained in the features of each level to improve the fusion efficiency of the features of each level in the mixed flow. Finally, the BMA module improves the detection accuracy of STDMMF-Net. A large number of subjective and objective experimental results testify that the proposed method demonstrates better detection accuracy than the state-of-the-art (SOTA) methods. Moreover, the comprehensive performance of the proposed method is better in terms of memory required for model inference, testing time, complexity, and generalization performance.
Offline Reinforcement Learning for Optimizing Production Bidding Policies
Oct 13, 2023The online advertising market, with its thousands of auctions run per second, presents a daunting challenge for advertisers who wish to optimize their spend under a budget constraint. Thus, advertising platforms typically provide automated agents to their customers, which act on their behalf to bid for impression opportunities in real time at scale. Because these proxy agents are owned by the platform but use advertiser funds to operate, there is a strong practical need to balance reliability and explainability of the agent with optimizing power. We propose a generalizable approach to optimizing bidding policies in production environments by learning from real data using offline reinforcement learning. This approach can be used to optimize any differentiable base policy (practically, a heuristic policy based on principles which the advertiser can easily understand), and only requires data generated by the base policy itself. We use a hybrid agent architecture that combines arbitrary base policies with deep neural networks, where only the optimized base policy parameters are eventually deployed, and the neural network part is discarded after training. We demonstrate that such an architecture achieves statistically significant performance gains in both simulated and at-scale production bidding environments. Our approach does not incur additional infrastructure, safety, or explainability costs, as it directly optimizes parameters of existing production routines without replacing them with black box-style models like neural networks.
Computing Marginal and Conditional Divergences between Decomposable Models with Applications
Oct 13, 2023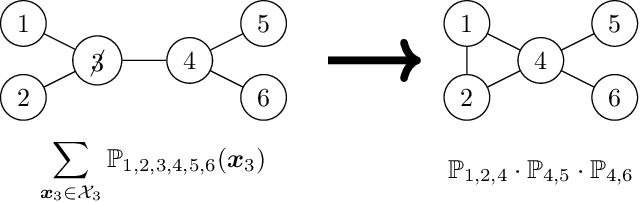
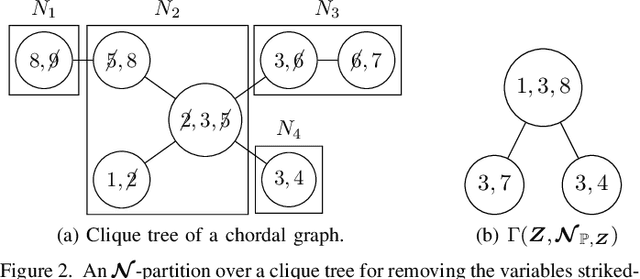


The ability to compute the exact divergence between two high-dimensional distributions is useful in many applications but doing so naively is intractable. Computing the alpha-beta divergence -- a family of divergences that includes the Kullback-Leibler divergence and Hellinger distance -- between the joint distribution of two decomposable models, i.e chordal Markov networks, can be done in time exponential in the treewidth of these models. However, reducing the dissimilarity between two high-dimensional objects to a single scalar value can be uninformative. Furthermore, in applications such as supervised learning, the divergence over a conditional distribution might be of more interest. Therefore, we propose an approach to compute the exact alpha-beta divergence between any marginal or conditional distribution of two decomposable models. Doing so tractably is non-trivial as we need to decompose the divergence between these distributions and therefore, require a decomposition over the marginal and conditional distributions of these models. Consequently, we provide such a decomposition and also extend existing work to compute the marginal and conditional alpha-beta divergence between these decompositions. We then show how our method can be used to analyze distributional changes by first applying it to a benchmark image dataset. Finally, based on our framework, we propose a novel way to quantify the error in contemporary superconducting quantum computers. Code for all experiments is available at: https://lklee.dev/pub/2023-icdm/code
SiamAF: Learning Shared Information from ECG and PPG Signals for Robust Atrial Fibrillation Detection
Oct 13, 2023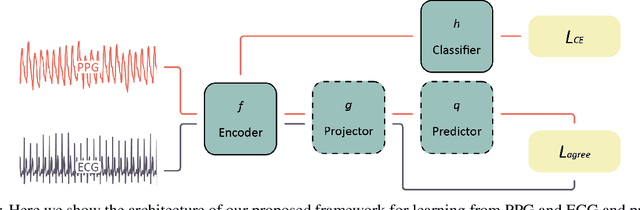

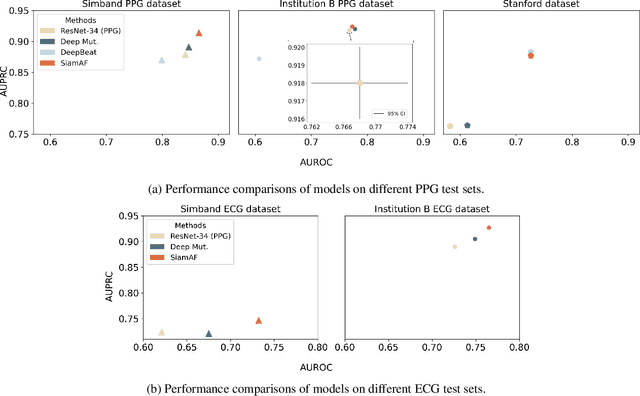
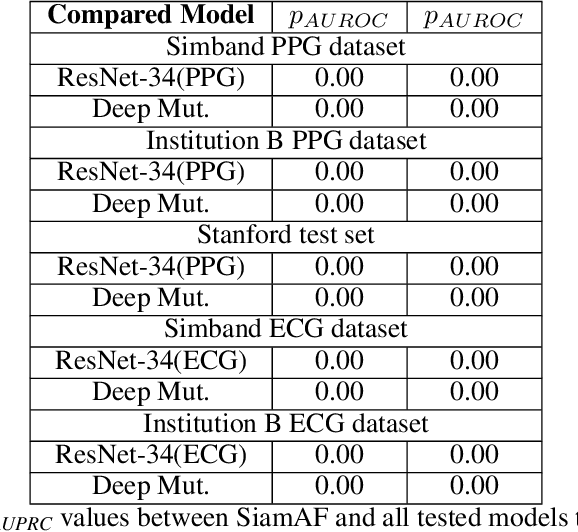
Atrial fibrillation (AF) is the most common type of cardiac arrhythmia. It is associated with an increased risk of stroke, heart failure, and other cardiovascular complications, but can be clinically silent. Passive AF monitoring with wearables may help reduce adverse clinical outcomes related to AF. Detecting AF in noisy wearable data poses a significant challenge, leading to the emergence of various deep learning techniques. Previous deep learning models learn from a single modality, either electrocardiogram (ECG) or photoplethysmography (PPG) signals. However, deep learning models often struggle to learn generalizable features and rely on features that are more susceptible to corruption from noise, leading to sub-optimal performances in certain scenarios, especially with low-quality signals. Given the increasing availability of ECG and PPG signal pairs from wearables and bedside monitors, we propose a new approach, SiamAF, leveraging a novel Siamese network architecture and joint learning loss function to learn shared information from both ECG and PPG signals. At inference time, the proposed model is able to predict AF from either PPG or ECG and outperforms baseline methods on three external test sets. It learns medically relevant features as a result of our novel architecture design. The proposed model also achieves comparable performance to traditional learning regimes while requiring much fewer training labels, providing a potential approach to reduce future reliance on manual labeling.
Efficient Apple Maturity and Damage Assessment: A Lightweight Detection Model with GAN and Attention Mechanism
Oct 13, 2023This study proposes a method based on lightweight convolutional neural networks (CNN) and generative adversarial networks (GAN) for apple ripeness and damage level detection tasks. Initially, a lightweight CNN model is designed by optimizing the model's depth and width, as well as employing advanced model compression techniques, successfully reducing the model's parameter and computational requirements, thus enhancing real-time performance in practical applications. Simultaneously, attention mechanisms are introduced, dynamically adjusting the importance of different feature layers to improve the performance in object detection tasks. To address the issues of sample imbalance and insufficient sample size, GANs are used to generate realistic apple images, expanding the training dataset and enhancing the model's recognition capability when faced with apples of varying ripeness and damage levels. Furthermore, by applying the object detection network for damage location annotation on damaged apples, the accuracy of damage level detection is improved, providing a more precise basis for decision-making. Experimental results show that in apple ripeness grading detection, the proposed model achieves 95.6\%, 93.8\%, 95.0\%, and 56.5 in precision, recall, accuracy, and FPS, respectively. In apple damage level detection, the proposed model reaches 95.3\%, 93.7\%, and 94.5\% in precision, recall, and mAP, respectively. In both tasks, the proposed method outperforms other mainstream models, demonstrating the excellent performance and high practical value of the proposed method in apple ripeness and damage level detection tasks.
OTFS based Joint Radar and Communication: Signal Analysis using the Ambiguity Function
Oct 07, 2023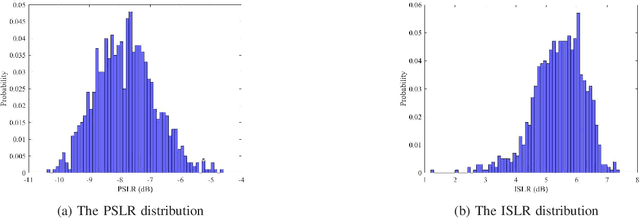
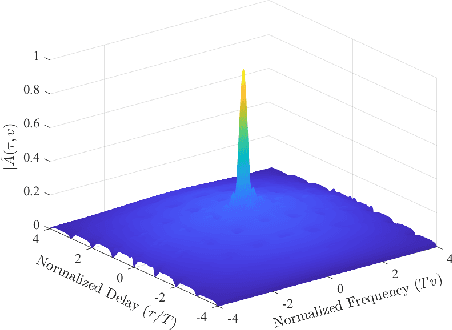
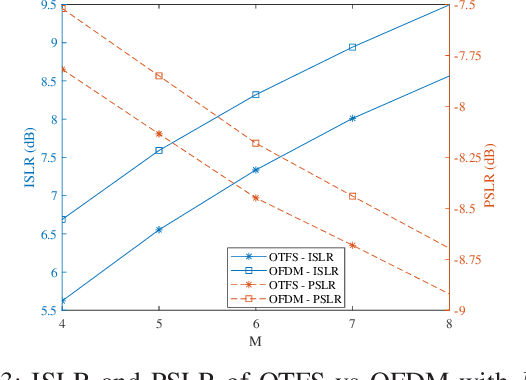
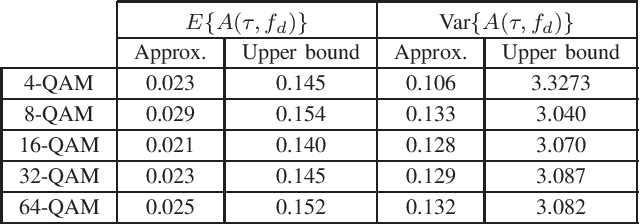
Orthogonal time frequency space (OTFS) modulation has recently been identified as a suitable waveform for joint radar and communication systems. Focusing on the effect of data modulation on the radar sensing performance, we derive the ambiguity function (AF) of the OTFS waveform and characterize the radar global accuracy. We evaluate the behavior of the AF with respect to the distribution of the modulated data and derive an accurate approximation for the mean and variance of the AF, thus, approximating its distribution by a Rice distribution. Finally, we evaluate the global radar performance of the OTFS waveform with the OFDM waveform.
GPU Accelerated Color Correction and Frame Warping for Real-time Video Stitching
Aug 17, 2023
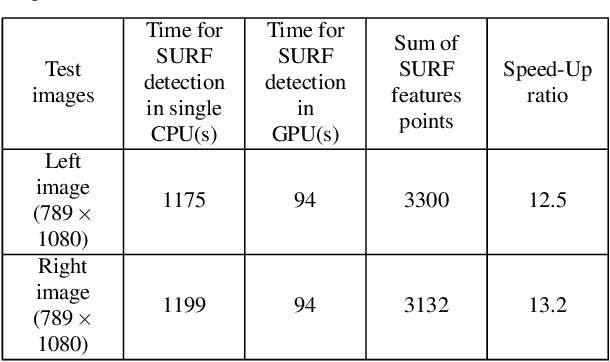
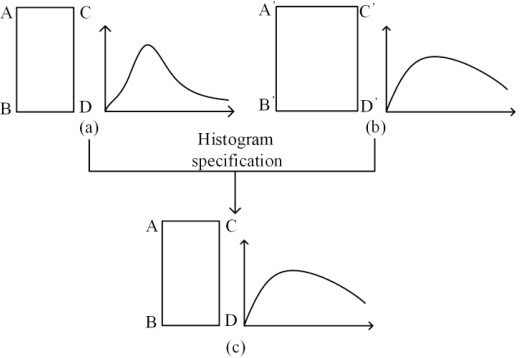
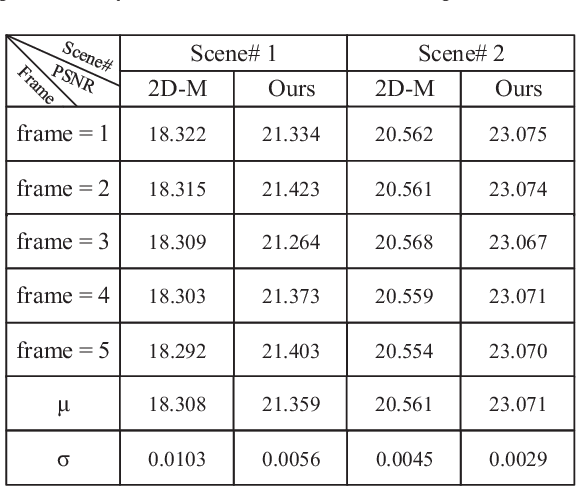
Traditional image stitching focuses on a single panorama frame without considering the spatial-temporal consistency in videos. The straightforward image stitching approach will cause temporal flicking and color inconstancy when it is applied to the video stitching task. Besides, inaccurate camera parameters will cause artifacts in the image warping. In this paper, we propose a real-time system to stitch multiple video sequences into a panoramic video, which is based on GPU accelerated color correction and frame warping without accurate camera parameters. We extend the traditional 2D-Matrix (2D-M) color correction approach and a present spatio-temporal 3D-Matrix (3D-M) color correction method for the overlap local regions with online color balancing using a piecewise function on global frames. Furthermore, we use pairwise homography matrices given by coarse camera calibration for global warping followed by accurate local warping based on the optical flow. Experimental results show that our system can generate highquality panorama videos in real time.
QUANT: A Minimalist Interval Method for Time Series Classification
Aug 02, 2023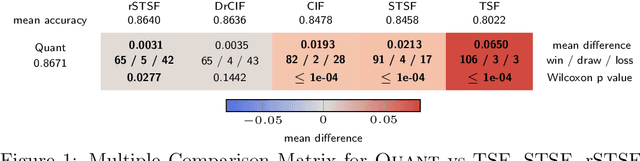
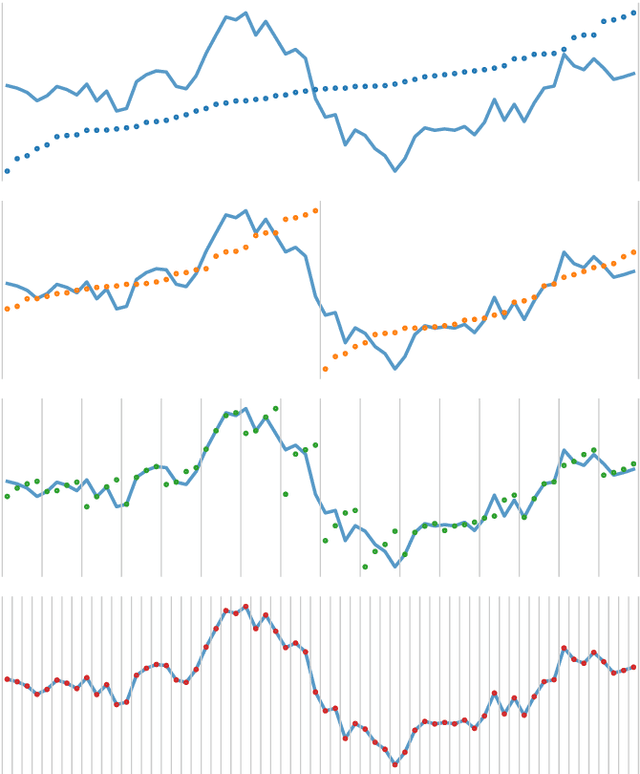
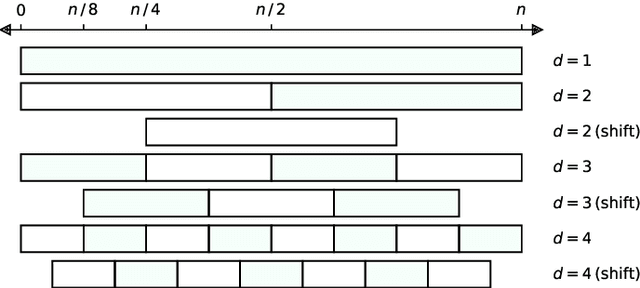
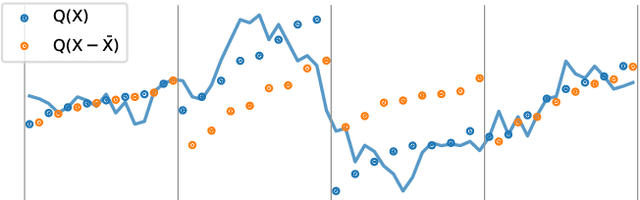
We show that it is possible to achieve the same accuracy, on average, as the most accurate existing interval methods for time series classification on a standard set of benchmark datasets using a single type of feature (quantiles), fixed intervals, and an 'off the shelf' classifier. This distillation of interval-based approaches represents a fast and accurate method for time series classification, achieving state-of-the-art accuracy on the expanded set of 142 datasets in the UCR archive with a total compute time (training and inference) of less than 15 minutes using a single CPU core.
Tempo Adaption in Non-stationary Reinforcement Learning
Sep 26, 2023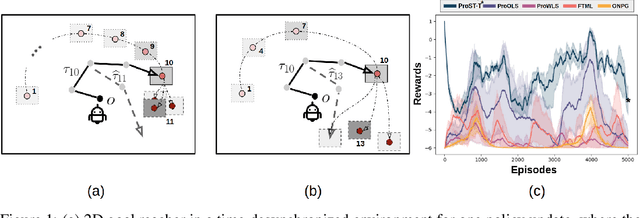

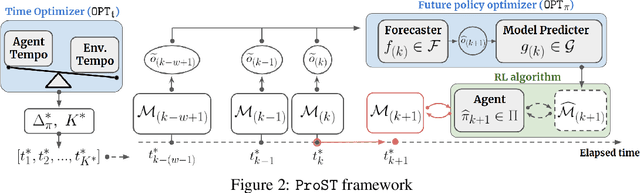
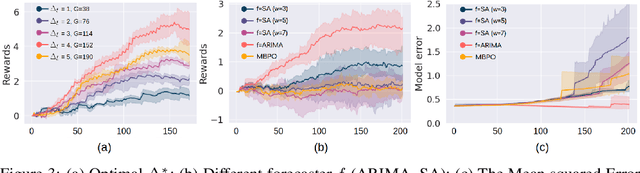
We first raise and tackle ``time synchronization'' issue between the agent and the environment in non-stationary reinforcement learning (RL), a crucial factor hindering its real-world applications. In reality, environmental changes occur over wall-clock time ($\mathfrak{t}$) rather than episode progress ($k$), where wall-clock time signifies the actual elapsed time within the fixed duration $\mathfrak{t} \in [0, T]$. In existing works, at episode $k$, the agent rollouts a trajectory and trains a policy before transitioning to episode $k+1$. In the context of the time-desynchronized environment, however, the agent at time $\mathfrak{t}_k$ allocates $\Delta \mathfrak{t}$ for trajectory generation and training, subsequently moves to the next episode at $\mathfrak{t}_{k+1}=\mathfrak{t}_{k}+\Delta \mathfrak{t}$. Despite a fixed total episode ($K$), the agent accumulates different trajectories influenced by the choice of \textit{interaction times} ($\mathfrak{t}_1,\mathfrak{t}_2,...,\mathfrak{t}_K$), significantly impacting the sub-optimality gap of policy. We propose a Proactively Synchronizing Tempo (ProST) framework that computes optimal $\{ \mathfrak{t}_1,\mathfrak{t}_2,...,\mathfrak{t}_K \} (= \{ \mathfrak{t} \}_{1:K})$. Our main contribution is that we show optimal $\{ \mathfrak{t} \}_{1:K}$ trades-off between the policy training time (agent tempo) and how fast the environment changes (environment tempo). Theoretically, this work establishes an optimal $\{ \mathfrak{t} \}_{1:K}$ as a function of the degree of the environment's non-stationarity while also achieving a sublinear dynamic regret. Our experimental evaluation on various high dimensional non-stationary environments shows that the ProST framework achieves a higher online return at optimal $\{ \mathfrak{t} \}_{1:K}$ than the existing methods.
Efficient Integrators for Diffusion Generative Models
Oct 11, 2023
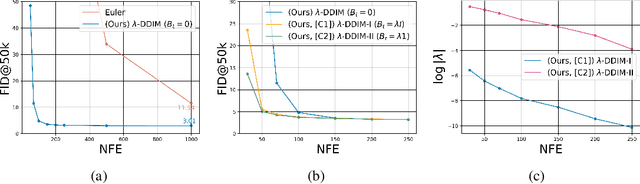

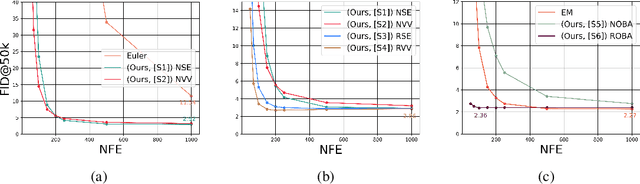
Diffusion models suffer from slow sample generation at inference time. Therefore, developing a principled framework for fast deterministic/stochastic sampling for a broader class of diffusion models is a promising direction. We propose two complementary frameworks for accelerating sample generation in pre-trained models: Conjugate Integrators and Splitting Integrators. Conjugate integrators generalize DDIM, mapping the reverse diffusion dynamics to a more amenable space for sampling. In contrast, splitting-based integrators, commonly used in molecular dynamics, reduce the numerical simulation error by cleverly alternating between numerical updates involving the data and auxiliary variables. After extensively studying these methods empirically and theoretically, we present a hybrid method that leads to the best-reported performance for diffusion models in augmented spaces. Applied to Phase Space Langevin Diffusion [Pandey & Mandt, 2023] on CIFAR-10, our deterministic and stochastic samplers achieve FID scores of 2.11 and 2.36 in only 100 network function evaluations (NFE) as compared to 2.57 and 2.63 for the best-performing baselines, respectively. Our code and model checkpoints will be made publicly available at \url{https://github.com/mandt-lab/PSLD}.