 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Adiabatic Generation of Human-Like Passwords
Jun 10, 2025Generative Artificial Intelligence (GenAI) for Natural Language Processing (NLP) is the predominant AI technology to date. An important perspective for Quantum Computing (QC) is the question whether QC has the potential to reduce the vast resource requirements for training and operating GenAI models. While large-scale generative NLP tasks are currently out of reach for practical quantum computers, the generation of short semantic structures such as passwords is not. Generating passwords that mimic real user behavior has many applications, for example to test an authentication system against realistic threat models. Classical password generation via deep learning have recently been investigated with significant progress in their ability to generate novel, realistic password candidates. In the present work we investigate the utility of adiabatic quantum computers for this task. More precisely, we study different encodings of token strings and propose novel approaches based on the Quadratic Unconstrained Binary Optimization (QUBO) and the Unit-Disk Maximum Independent Set (UD-MIS) problems. Our approach allows us to estimate the token distribution from data and adiabatically prepare a quantum state from which we eventually sample the generated passwords via measurements. Our results show that relatively small samples of 128 passwords, generated on the QuEra Aquila 256-qubit neutral atom quantum computer, contain human-like passwords such as "Tunas200992" or "teedem28iglove".
Standardization of Multi-Objective QUBOs
Apr 16, 2025Multi-objective optimization involving Quadratic Unconstrained Binary Optimization (QUBO) problems arises in various domains. A fundamental challenge in this context is the effective balancing of multiple objectives, each potentially operating on very different scales. This imbalance introduces complications such as the selection of appropriate weights when scalarizing multiple objectives into a single objective function. In this paper, we propose a novel technique for scaling QUBO objectives that uses an exact computation of the variance of each individual QUBO objective. By scaling each objective to have unit variance, we align all objectives onto a common scale, thereby allowing for more balanced solutions to be found when scalarizing the objectives with equal weights, as well as potentially assisting in the search or choice of weights during scalarization. Finally, we demonstrate its advantages through empirical evaluations on various multi-objective optimization problems. Our results are noteworthy since manually selecting scalarization weights is cumbersome, and reliable, efficient solutions are scarce.
Expressive equivalence of classical and quantum restricted Boltzmann machines
Feb 24, 2025Quantum computers offer the potential for efficiently sampling from complex probability distributions, attracting increasing interest in generative modeling within quantum machine learning. This surge in interest has driven the development of numerous generative quantum models, yet their trainability and scalability remain significant challenges. A notable example is a quantum restricted Boltzmann machine (QRBM), which is based on the Gibbs state of a parameterized non-commuting Hamiltonian. While QRBMs are expressive, their non-commuting Hamiltonians make gradient evaluation computationally demanding, even on fault-tolerant quantum computers. In this work, we propose a semi-quantum restricted Boltzmann machine (sqRBM), a model designed for classical data that mitigates the challenges associated with previous QRBM proposals. The sqRBM Hamiltonian is commuting in the visible subspace while remaining non-commuting in the hidden subspace. This structure allows us to derive closed-form expressions for both output probabilities and gradients. Leveraging these analytical results, we demonstrate that sqRBMs share a close relationship with classical restricted Boltzmann machines (RBM). Our theoretical analysis predicts that, to learn a given probability distribution, an RBM requires three times as many hidden units as an sqRBM, while both models have the same total number of parameters. We validate these findings through numerical simulations involving up to 100 units. Our results suggest that sqRBMs could enable practical quantum machine learning applications in the near future by significantly reducing quantum resource requirements.
Hybrid Quantum-Classical Multi-Agent Pathfinding
Jan 24, 2025Multi-Agent Path Finding (MAPF) focuses on determining conflict-free paths for multiple agents navigating through a shared space to reach specified goal locations. This problem becomes computationally challenging, particularly when handling large numbers of agents, as frequently encountered in practical applications like coordinating autonomous vehicles. Quantum computing (QC) is a promising candidate in overcoming such limits. However, current quantum hardware is still in its infancy and thus limited in terms of computing power and error robustness. In this work, we present the first optimal hybrid quantum-classical MAPF algorithm which is based on branch-and-cut-and-prize. QC is integrated by iteratively solving QUBO problems, based on conflict graphs. Experiments on actual quantum hardware and results on benchmark data suggest that our approach dominates previous QUBO formulations and baseline MAPF solvers.
Dynamic Range Reduction via Branch-and-Bound
Sep 17, 2024



The demand for high-performance computing in machine learning and artificial intelligence has led to the development of specialized hardware accelerators like Tensor Processing Units (TPUs), Graphics Processing Units (GPUs), and Field-Programmable Gate Arrays (FPGAs). A key strategy to enhance these accelerators is the reduction of precision in arithmetic operations, which increases processing speed and lowers latency - crucial for real-time AI applications. Precision reduction minimizes memory bandwidth requirements and energy consumption, essential for large-scale and mobile deployments, and increases throughput by enabling more parallel operations per cycle, maximizing hardware resource utilization. This strategy is equally vital for solving NP-hard quadratic unconstrained binary optimization (QUBO) problems common in machine learning, which often require high precision for accurate representation. Special hardware solvers, such as quantum annealers, benefit significantly from precision reduction. This paper introduces a fully principled Branch-and-Bound algorithm for reducing precision needs in QUBO problems by utilizing dynamic range as a measure of complexity. Experiments validate our algorithm's effectiveness on an actual quantum annealer.
Computing Marginal and Conditional Divergences between Decomposable Models with Applications
Oct 13, 2023



The ability to compute the exact divergence between two high-dimensional distributions is useful in many applications but doing so naively is intractable. Computing the alpha-beta divergence -- a family of divergences that includes the Kullback-Leibler divergence and Hellinger distance -- between the joint distribution of two decomposable models, i.e chordal Markov networks, can be done in time exponential in the treewidth of these models. However, reducing the dissimilarity between two high-dimensional objects to a single scalar value can be uninformative. Furthermore, in applications such as supervised learning, the divergence over a conditional distribution might be of more interest. Therefore, we propose an approach to compute the exact alpha-beta divergence between any marginal or conditional distribution of two decomposable models. Doing so tractably is non-trivial as we need to decompose the divergence between these distributions and therefore, require a decomposition over the marginal and conditional distributions of these models. Consequently, we provide such a decomposition and also extend existing work to compute the marginal and conditional alpha-beta divergence between these decompositions. We then show how our method can be used to analyze distributional changes by first applying it to a benchmark image dataset. Finally, based on our framework, we propose a novel way to quantify the error in contemporary superconducting quantum computers. Code for all experiments is available at: https://lklee.dev/pub/2023-icdm/code
Explainable Quantum Machine Learning
Jan 22, 2023Methods of artificial intelligence (AI) and especially machine learning (ML) have been growing ever more complex, and at the same time have more and more impact on people's lives. This leads to explainable AI (XAI) manifesting itself as an important research field that helps humans to better comprehend ML systems. In parallel, quantum machine learning (QML) is emerging with the ongoing improvement of quantum computing hardware combined with its increasing availability via cloud services. QML enables quantum-enhanced ML in which quantum mechanics is exploited to facilitate ML tasks, typically in form of quantum-classical hybrid algorithms that combine quantum and classical resources. Quantum gates constitute the building blocks of gate-based quantum hardware and form circuits that can be used for quantum computations. For QML applications, quantum circuits are typically parameterized and their parameters are optimized classically such that a suitably defined objective function is minimized. Inspired by XAI, we raise the question of explainability of such circuits by quantifying the importance of (groups of) gates for specific goals. To this end, we transfer and adapt the well-established concept of Shapley values to the quantum realm. The resulting attributions can be interpreted as explanations for why a specific circuit works well for a given task, improving the understanding of how to construct parameterized (or variational) quantum circuits, and fostering their human interpretability in general. An experimental evaluation on simulators and two superconducting quantum hardware devices demonstrates the benefits of the proposed framework for classification, generative modeling, transpilation, and optimization. Furthermore, our results shed some light on the role of specific gates in popular QML approaches.
Shapley Values with Uncertain Value Functions
Jan 19, 2023We propose a novel definition of Shapley values with uncertain value functions based on first principles using probability theory. Such uncertain value functions can arise in the context of explainable machine learning as a result of non-deterministic algorithms. We show that random effects can in fact be absorbed into a Shapley value with a noiseless but shifted value function. Hence, Shapley values with uncertain value functions can be used in analogy to regular Shapley values. However, their reliable evaluation typically requires more computational effort.
Full Kullback-Leibler-Divergence Loss for Hyperparameter-free Label Distribution Learning
Sep 05, 2022
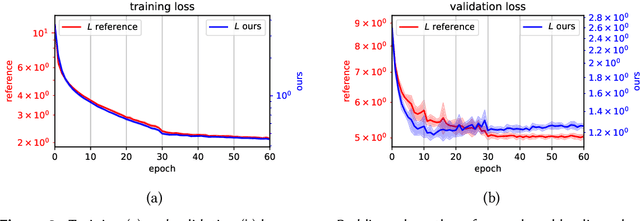
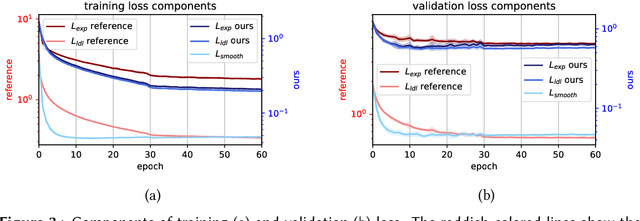
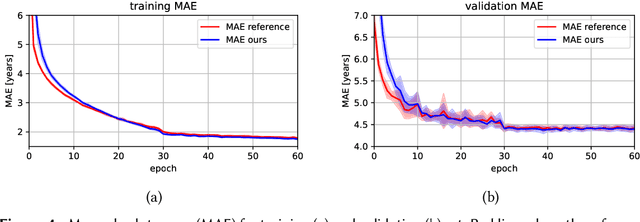
The concept of Label Distribution Learning (LDL) is a technique to stabilize classification and regression problems with ambiguous and/or imbalanced labels. A prototypical use-case of LDL is human age estimation based on profile images. Regarding this regression problem, a so called Deep Label Distribution Learning (DLDL) method has been developed. The main idea is the joint regression of the label distribution and its expectation value. However, the original DLDL method uses loss components with different mathematical motivation and, thus, different scales, which is why the use of a hyperparameter becomes necessary. In this work, we introduce a loss function for DLDL whose components are completely defined by Kullback-Leibler (KL) divergences and, thus, are directly comparable to each other without the need of additional hyperparameters. It generalizes the concept of DLDL with regard to further use-cases, in particular for multi-dimensional or multi-scale distribution learning tasks.
On Quantum Circuits for Discrete Graphical Models
Jun 01, 2022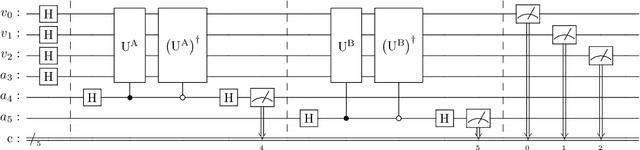
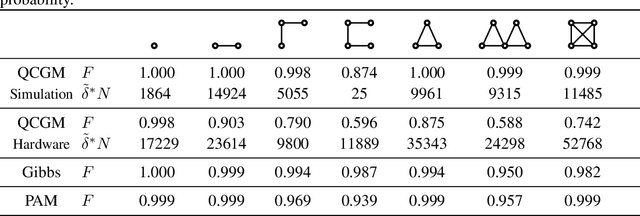

Graphical models are useful tools for describing structured high-dimensional probability distributions. Development of efficient algorithms for generating unbiased and independent samples from graphical models remains an active research topic. Sampling from graphical models that describe the statistics of discrete variables is a particularly challenging problem, which is intractable in the presence of high dimensions. In this work, we provide the first method that allows one to provably generate unbiased and independent samples from general discrete factor models with a quantum circuit. Our method is compatible with multi-body interactions and its success probability does not depend on the number of variables. To this end, we identify a novel embedding of the graphical model into unitary operators and provide rigorous guarantees on the resulting quantum state. Moreover, we prove a unitary Hammersley-Clifford theorem -- showing that our quantum embedding factorizes over the cliques of the underlying conditional independence structure. Importantly, the quantum embedding allows for maximum likelihood learning as well as maximum a posteriori state approximation via state-of-the-art hybrid quantum-classical methods. Finally, the proposed quantum method can be implemented on current quantum processors. Experiments with quantum simulation as well as actual quantum hardware show that our method can carry out sampling and parameter learning on quantum computers.