 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time Series Analysis": models, code, and papers
Salesforce CausalAI Library: A Fast and Scalable Framework for Causal Analysis of Time Series and Tabular Data
Jan 25, 2023
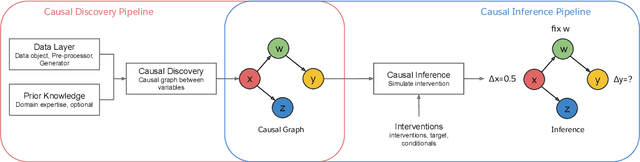

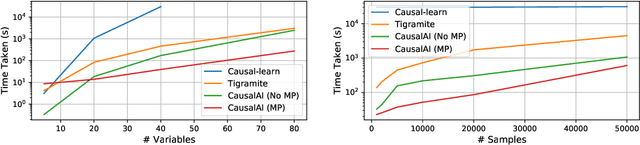
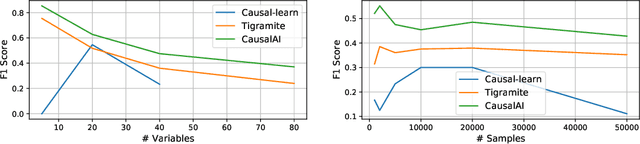
We introduce the Salesforce CausalAI Library, an open-source library for causal analysis using observational data. It supports causal discovery and causal inference for tabular and time series data, of both discrete and continuous types. This library includes algorithms that handle linear and non-linear causal relationships between variables, and uses multi-processing for speed-up. We also include a data generator capable of generating synthetic data with specified structural equation model for both the aforementioned data formats and types, that helps users control the ground-truth causal process while investigating various algorithms. Finally, we provide a user interface (UI) that allows users to perform causal analysis on data without coding. The goal of this library is to provide a fast and flexible solution for a variety of problems in the domain of causality. This technical report describes the Salesforce CausalAI API along with its capabilities, the implementations of the supported algorithms, and experiments demonstrating their performance and speed. Our library is available at \url{https://github.com/salesforce/causalai}.
Memory-free Online Change-point Detection: A Novel Neural Network Approach
Jul 08, 2022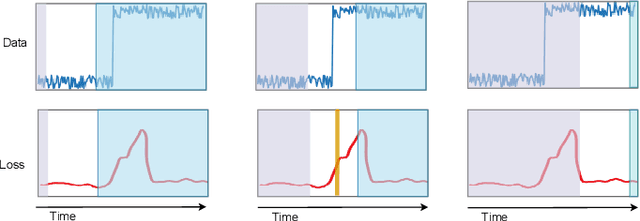
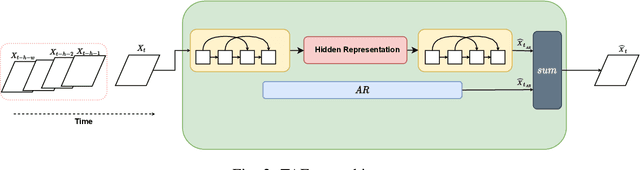
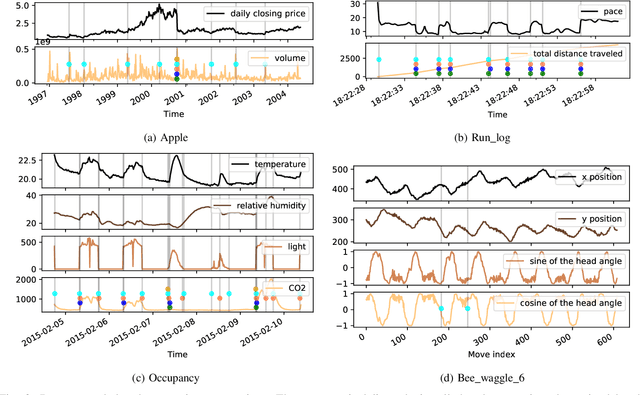
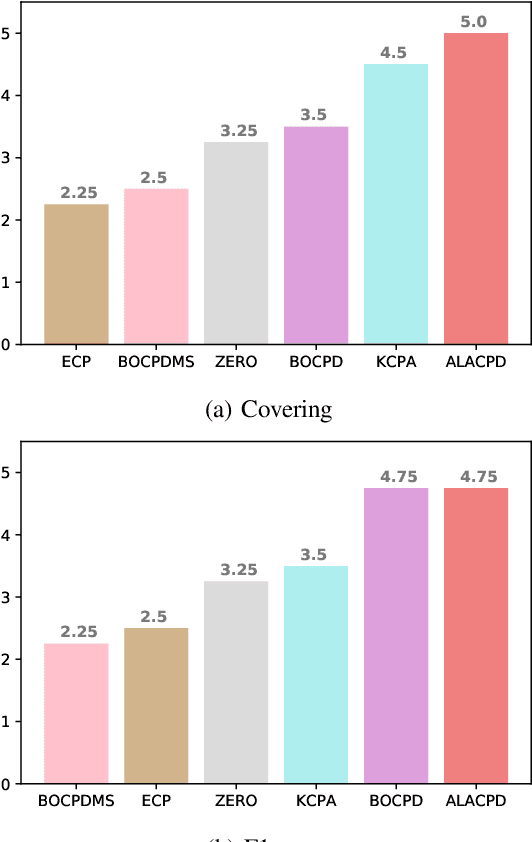
Change-point detection (CPD), which detects abrupt changes in the data distribution, is recognized as one of the most significant tasks in time series analysis. Despite the extensive literature on offline CPD, unsupervised online CPD still suffers from major challenges, including scalability, hyperparameter tuning, and learning constraints. To mitigate some of these challenges, in this paper, we propose a novel deep learning approach for unsupervised online CPD from multi-dimensional time series, named Adaptive LSTM-Autoencoder Change-Point Detection (ALACPD). ALACPD exploits an LSTM-autoencoder-based neural network to perform unsupervised online CPD. It continuously adapts to the incoming samples without keeping the previously received input, thus being memory-free. We perform an extensive evaluation on several real-world time series CPD benchmarks. We show that ALACPD, on average, ranks first among state-of-the-art CPD algorithms in terms of quality of the time series segmentation, and it is on par with the best performer in terms of the accuracy of the estimated change-points. The implementation of ALACPD is available online on Github\footnote{\url{https://github.com/zahraatashgahi/ALACPD}}.
Simulating Using Deep Learning The World Trade Forecasting of Export-Import Exchange Rate Convergence Factor During COVID-19
Jan 23, 2022By trade we usually mean the exchange of goods between states and countries. International trade acts as a barometer of the economic prosperity index and every country is overly dependent on resources, so international trade is essential. Trade is significant to the global health crisis, saving lives and livelihoods. By collecting the dataset called "Effects of COVID19 on trade" from the state website NZ Tatauranga Aotearoa, we have developed a sustainable prediction process on the effects of COVID-19 in world trade using a deep learning model. In the research, we have given a 180-day trade forecast where the ups and downs of daily imports and exports have been accurately predicted in the Covid-19 period. In order to fulfill this prediction, we have taken data from 1st January 2015 to 30th May 2021 for all countries, all commodities, and all transport systems and have recovered what the world trade situation will be in the next 180 days during the Covid-19 period. The deep learning method has received equal attention from both investors and researchers in the field of in-depth observation. This study predicts global trade using the Long-Short Term Memory. Time series analysis can be useful to see how a given asset, security, or economy changes over time. Time series analysis plays an important role in past analysis to get different predictions of the future and it can be observed that some factors affect a particular variable from period to period. Through the time series it is possible to observe how various economic changes or trade effects change over time. By reviewing these changes, one can be aware of the steps to be taken in the future and a country can be more careful in terms of imports and exports accordingly. From our time series analysis, it can be said that the LSTM model has given a very gracious thought of the future world import and export situation in terms of trade.
Ensemble transport smoothing -- Part 1: unified framework
Oct 31, 2022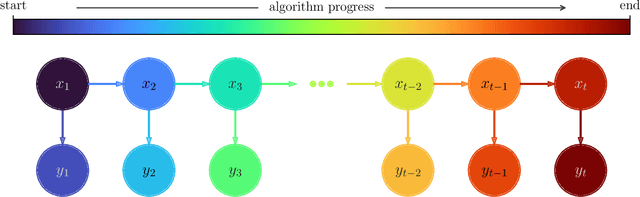
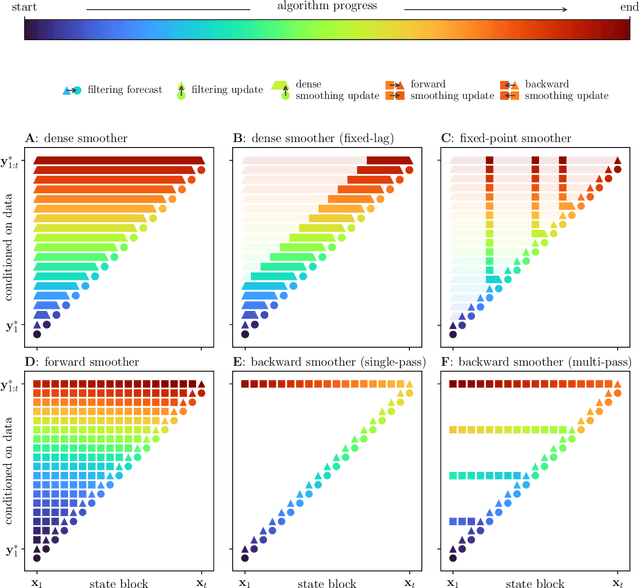
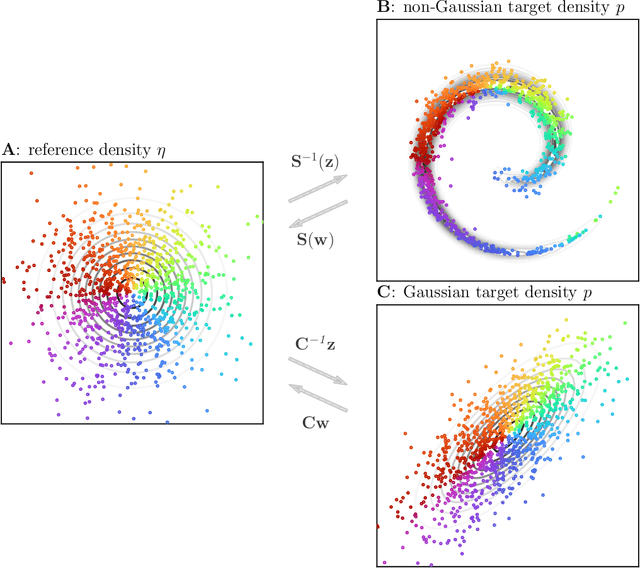
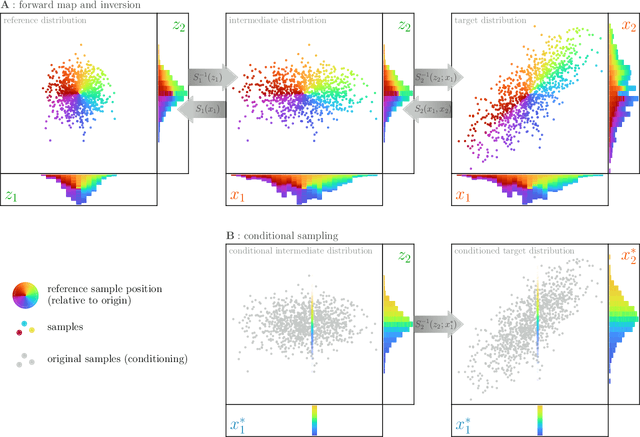
Smoothers are algorithms for Bayesian time series re-analysis. Most operational smoothers rely either on affine Kalman-type transformations or on sequential importance sampling. These strategies occupy opposite ends of a spectrum that trades computational efficiency and scalability for statistical generality and consistency: non-Gaussianity renders affine Kalman updates inconsistent with the true Bayesian solution, while the ensemble size required for successful importance sampling can be prohibitive. This paper revisits the smoothing problem from the perspective of measure transport, which offers the prospect of consistent prior-to-posterior transformations for Bayesian inference. We leverage this capacity by proposing a general ensemble framework for transport-based smoothing. Within this framework, we derive a comprehensive set of smoothing recursions based on nonlinear transport maps and detail how they exploit the structure of state-space models in fully non-Gaussian settings. We also describe how many standard Kalman-type smoothing algorithms emerge as special cases of our framework. A companion paper explores the implementation of nonlinear ensemble transport smoothers in greater depth.
Task-aware Similarity Learning for Event-triggered Time Series
Jul 17, 2022


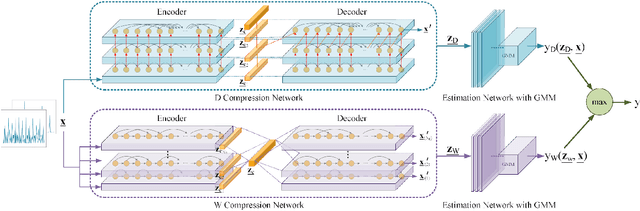
Time series analysis has achieved great success in diverse applications such as network security, environmental monitoring, and medical informatics. Learning similarities among different time series is a crucial problem since it serves as the foundation for downstream analysis such as clustering and anomaly detection. It often remains unclear what kind of distance metric is suitable for similarity learning due to the complex temporal dynamics of the time series generated from event-triggered sensing, which is common in diverse applications, including automated driving, interactive healthcare, and smart home automation. The overarching goal of this paper is to develop an unsupervised learning framework that is capable of learning task-aware similarities among unlabeled event-triggered time series. From the machine learning vantage point, the proposed framework harnesses the power of both hierarchical multi-scale sequence autoencoders and Gaussian Mixture Model (GMM) to effectively learn the low-dimensional representations from the time series. Finally, the obtained similarity measure can be easily visualized for explaining. The proposed framework aspires to offer a stepping stone that gives rise to a systematic approach to model and learn similarities among a multitude of event-triggered time series. Through extensive qualitative and quantitative experiments, it is revealed that the proposed method outperforms state-of-the-art methods considerably.
STD: A Seasonal-Trend-Dispersion Decomposition of Time Series
Apr 21, 2022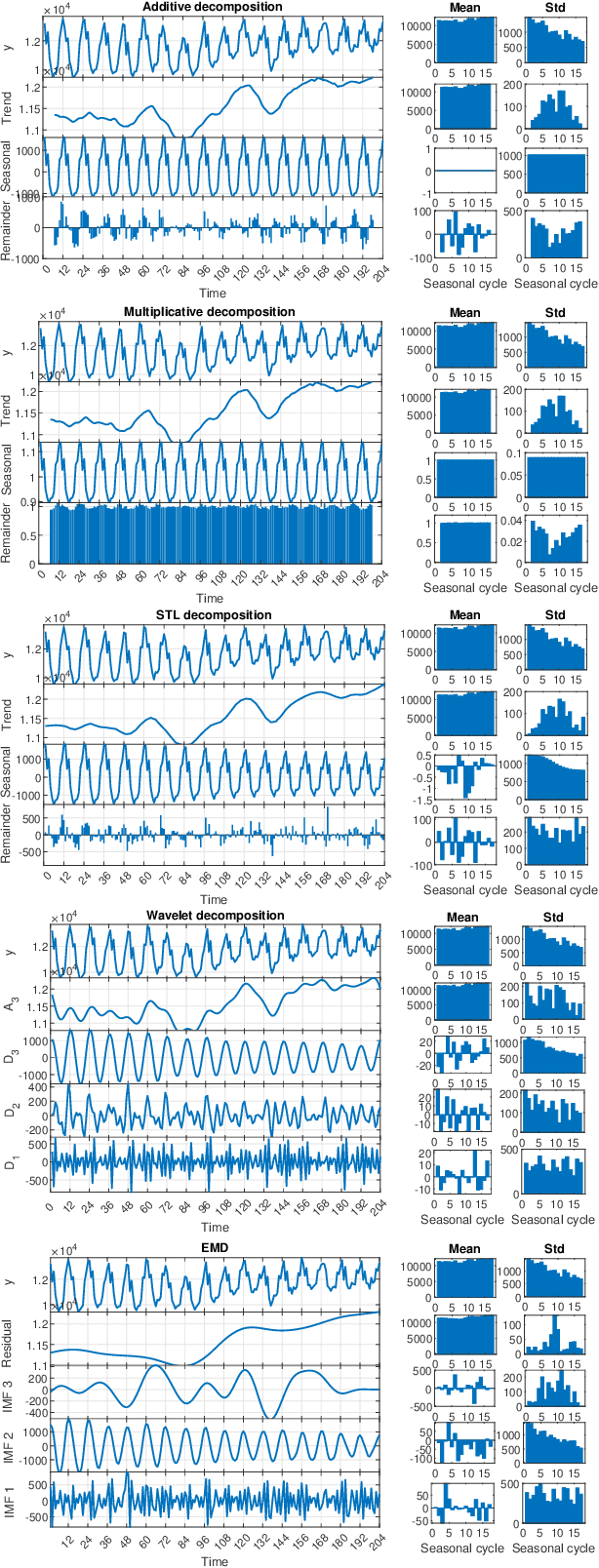
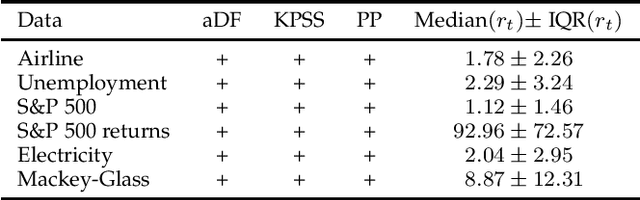
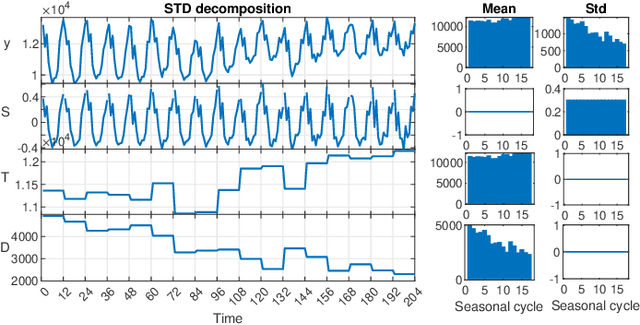
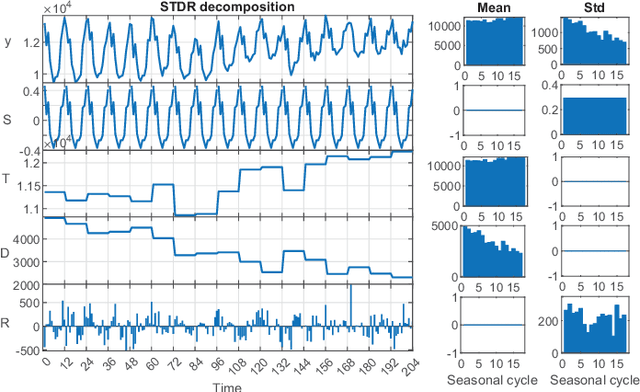
The decomposition of a time series is an essential task that helps to understand its very nature. It facilitates the analysis and forecasting of complex time series expressing various hidden components such as the trend, seasonal components, cyclic components and irregular fluctuations. Therefore, it is crucial in many fields for forecasting and decision processes. In recent years, many methods of time series decomposition have been developed, which extract and reveal different time series properties. Unfortunately, they neglect a very important property, i.e. time series variance. To deal with heteroscedasticity in time series, the method proposed in this work -- a seasonal-trend-dispersion decomposition (STD) -- extracts the trend, seasonal component and component related to the dispersion of the time series. We define STD decomposition in two ways: with and without an irregular component. We show how STD can be used for time series analysis and forecasting.
Process Model Forecasting Using Time Series Analysis of Event Sequence Data
May 03, 2021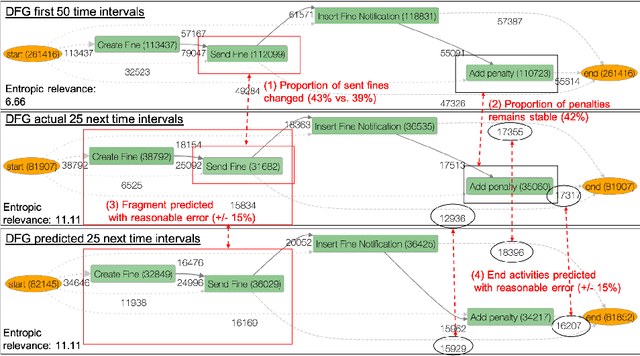

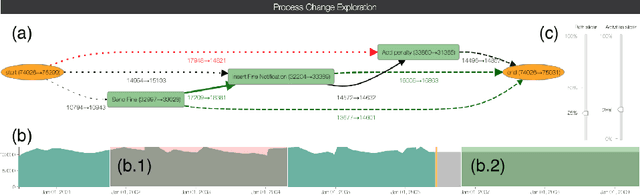
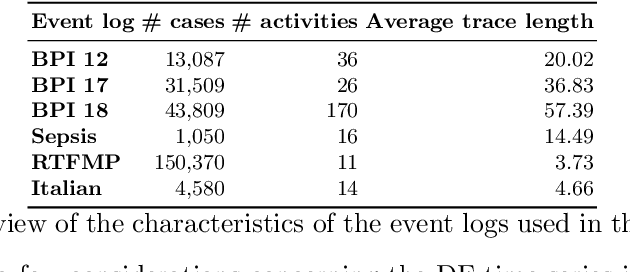
Process analytics is the field focusing on predictions for individual process instances or overall process models. At the instance level, various novel techniques have been recently devised, tackling next activity, remaining time, and outcome prediction. At the model level, there is a notable void. It is the ambition of this paper to fill this gap. To this end, we develop a technique to forecast the entire process model from historical event data. A forecasted model is a will-be process model representing a probable future state of the overall process. Such a forecast helps to investigate the consequences of drift and emerging bottlenecks. Our technique builds on a representation of event data as multiple time series, each capturing the evolution of a behavioural aspect of the process model, such that corresponding forecasting techniques can be applied. Our implementation demonstrates the accuracy of our technique on real-world event log data.
Grouped self-attention mechanism for a memory-efficient Transformer
Oct 06, 2022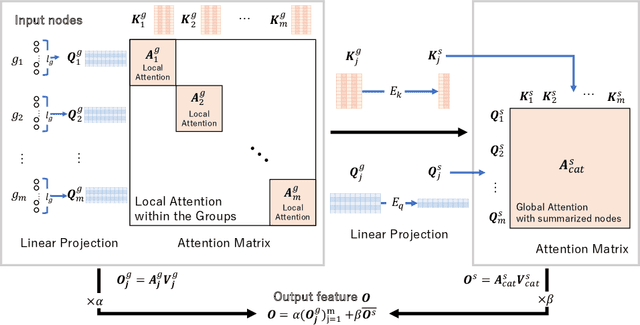
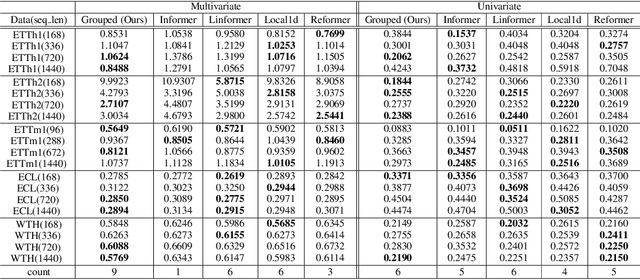
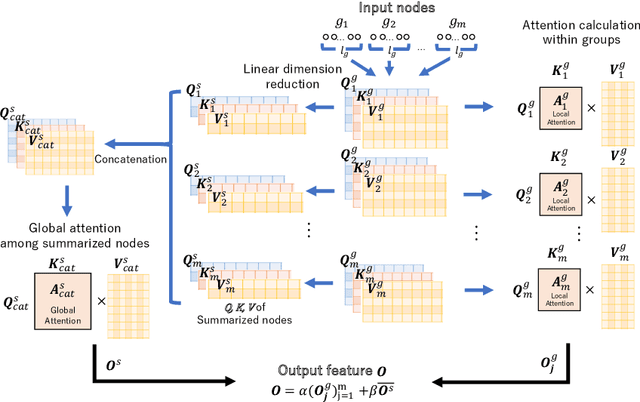
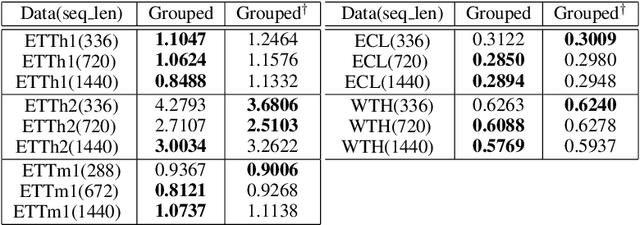
Time-series data analysis is important because numerous real-world tasks such as forecasting weather, electricity consumption, and stock market involve predicting data that vary over time. Time-series data are generally recorded over a long period of observation with long sequences owing to their periodic characteristics and long-range dependencies over time. Thus, capturing long-range dependency is an important factor in time-series data forecasting. To solve these problems, we proposed two novel modules, Grouped Self-Attention (GSA) and Compressed Cross-Attention (CCA). With both modules, we achieved a computational space and time complexity of order $O(l)$ with a sequence length $l$ under small hyperparameter limitations, and can capture locality while considering global information. The results of experiments conducted on time-series datasets show that our proposed model efficiently exhibited reduced computational complexity and performance comparable to or better than existing methods.
Scalable Predictive Time-Series Analysis of COVID-19: Cases and Fatalities
Apr 22, 2021
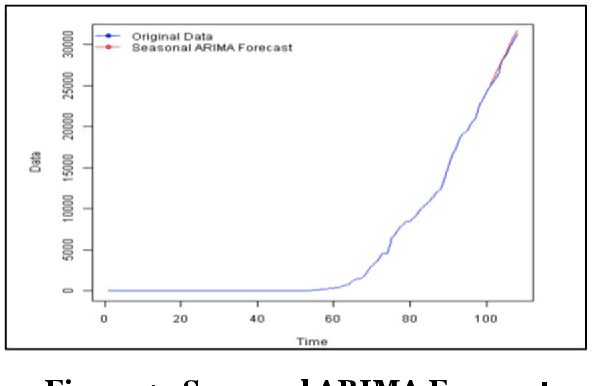
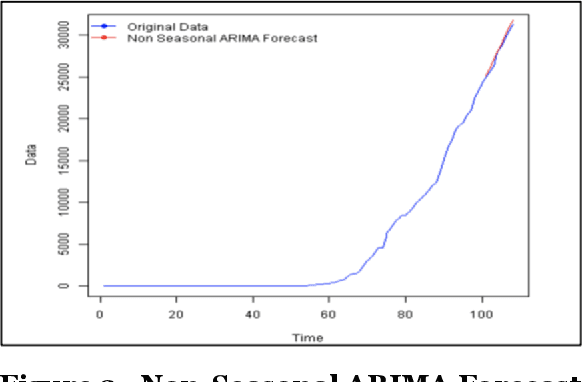

COVID 19 is an acute disease that started spreading throughout the world, beginning in December 2019. It has spread worldwide and has affected more than 7 million people, and 200 thousand people have died due to this infection as of Oct 2020. In this paper, we have forecasted the number of deaths and the confirmed cases in Los Angeles and New York of the United States using the traditional and Big Data platforms based on the Times Series: ARIMA and ETS. We also implemented a more sophisticated time-series forecast model using Facebook Prophet API. Furthermore, we developed the classification models: Logistic Regression and Random Forest regression to show that the Weather does not affect the number of the confirmed cases. The models are built and run in legacy systems (Azure ML Studio) and Big Data systems (Oracle Cloud and Databricks). Besides, we present the accuracy of the models.
Causal Inference for Time series Analysis: Problems, Methods and Evaluation
Feb 11, 2021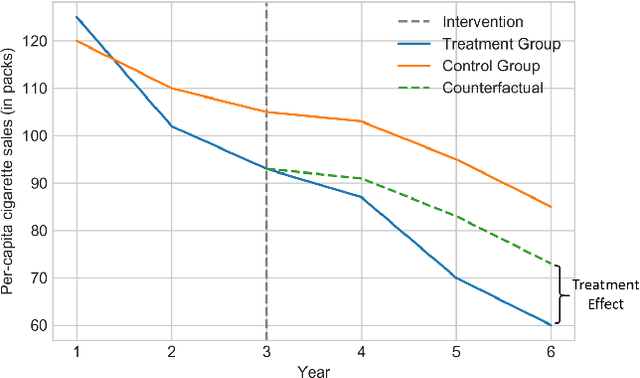

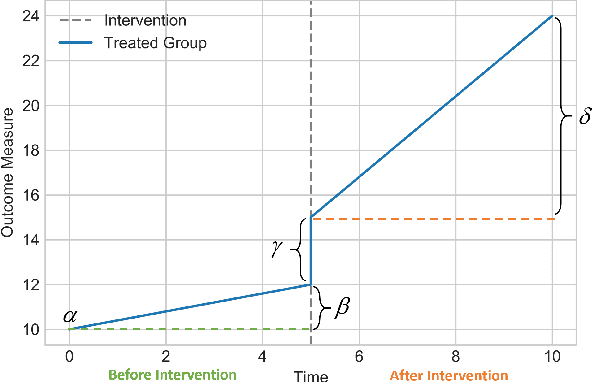
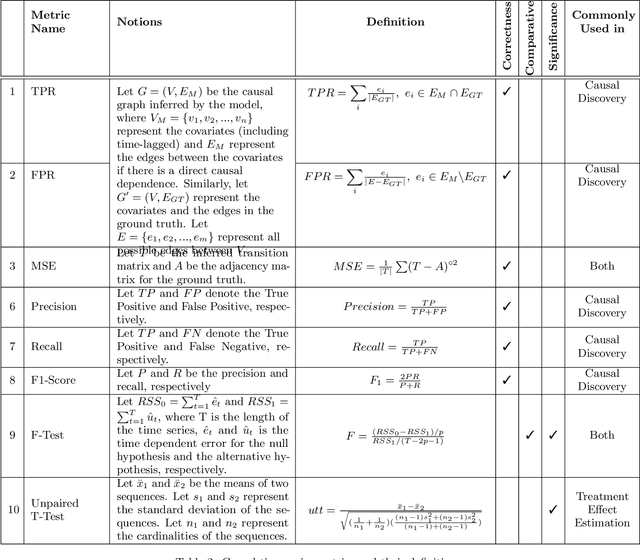
Time series data is a collection of chronological observations which is generated by several domains such as medical and financial fields. Over the years, different tasks such as classification, forecasting, and clustering have been proposed to analyze this type of data. Time series data has been also used to study the effect of interventions over time. Moreover, in many fields of science, learning the causal structure of dynamic systems and time series data is considered an interesting task which plays an important role in scientific discoveries. Estimating the effect of an intervention and identifying the causal relations from the data can be performed via causal inference. Existing surveys on time series discuss traditional tasks such as classification and forecasting or explain the details of the approaches proposed to solve a specific task. In this paper, we focus on two causal inference tasks, i.e., treatment effect estimation and causal discovery for time series data, and provide a comprehensive review of the approaches in each task. Furthermore, we curate a list of commonly used evaluation metrics and datasets for each task and provide in-depth insight. These metrics and datasets can serve as benchmarks for research in the field.