 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
Aspect-Based Sentiment Analysis using Local Context Focus Mechanism with DeBERTa
Jul 07, 2022
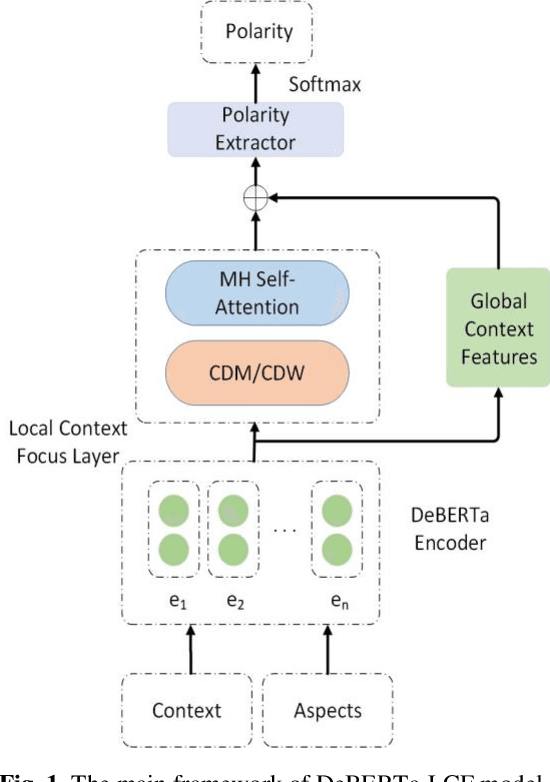

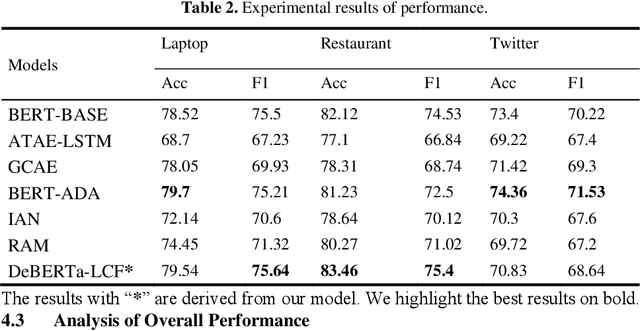
Text sentiment analysis, also known as opinion mining, is research on the calculation of people's views, evaluations, attitude and emotions expressed by entities. Text sentiment analysis can be divided into text-level sentiment analysis, sen-tence-level sentiment analysis and aspect-level sentiment analysis. Aspect-Based Sentiment Analysis (ABSA) is a fine-grained task in the field of sentiment analysis, which aims to predict the polarity of aspects. The research of pre-training neural model has significantly improved the performance of many natural language processing tasks. In recent years, pre training model (PTM) has been applied in ABSA. Therefore, there has been a question, which is whether PTMs contain sufficient syntactic information for ABSA. In this paper, we explored the recent DeBERTa model (Decoding-enhanced BERT with disentangled attention) to solve Aspect-Based Sentiment Analysis problem. DeBERTa is a kind of neural language model based on transformer, which uses self-supervised learning to pre-train on a large number of original text corpora. Based on the Local Context Focus (LCF) mechanism, by integrating DeBERTa model, we purpose a multi-task learning model for aspect-based sentiment analysis. The experiments result on the most commonly used the laptop and restaurant datasets of SemEval-2014 and the ACL twitter dataset show that LCF mechanism with DeBERTa has significant improvement.
Types of Approaches, Applications and Challenges in the Development of Sentiment Analysis Systems
Mar 09, 2023

Today, the web has become a mandatory platform to express users' opinions, emotions and feelings about various events. Every person using his smartphone can give his opinion about the purchase of a product, the occurrence of an accident, the occurrence of a new disease, etc. in blogs and social networks such as (Twitter, WhatsApp, Telegram and Instagram) register. Therefore, millions of comments are recorded daily and it creates a huge volume of unstructured text data that can extract useful knowledge from this type of data by using natural language processing methods. Sentiment analysis is one of the important applications of natural language processing and machine learning, which allows us to analyze the sentiments of comments and other textual information recorded by web users. Therefore, the analysis of sentiments, approaches and challenges in this field will be explained in the following.
A Wide Evaluation of ChatGPT on Affective Computing Tasks
Aug 26, 2023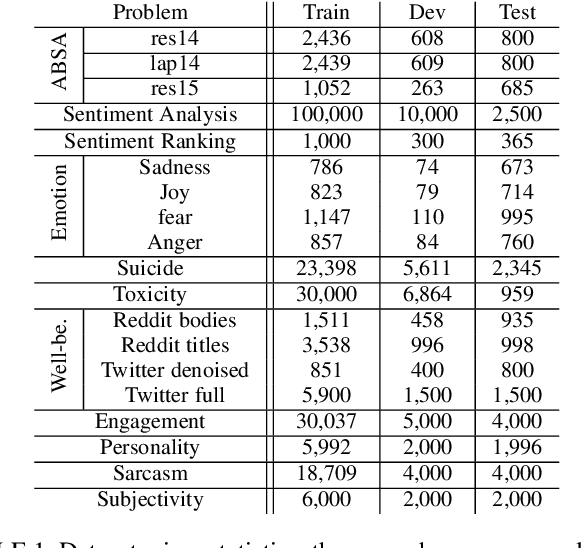

With the rise of foundation models, a new artificial intelligence paradigm has emerged, by simply using general purpose foundation models with prompting to solve problems instead of training a separate machine learning model for each problem. Such models have been shown to have emergent properties of solving problems that they were not initially trained on. The studies for the effectiveness of such models are still quite limited. In this work, we widely study the capabilities of the ChatGPT models, namely GPT-4 and GPT-3.5, on 13 affective computing problems, namely aspect extraction, aspect polarity classification, opinion extraction, sentiment analysis, sentiment intensity ranking, emotions intensity ranking, suicide tendency detection, toxicity detection, well-being assessment, engagement measurement, personality assessment, sarcasm detection, and subjectivity detection. We introduce a framework to evaluate the ChatGPT models on regression-based problems, such as intensity ranking problems, by modelling them as pairwise ranking classification. We compare ChatGPT against more traditional NLP methods, such as end-to-end recurrent neural networks and transformers. The results demonstrate the emergent abilities of the ChatGPT models on a wide range of affective computing problems, where GPT-3.5 and especially GPT-4 have shown strong performance on many problems, particularly the ones related to sentiment, emotions, or toxicity. The ChatGPT models fell short for problems with implicit signals, such as engagement measurement and subjectivity detection.
Video Games as a Corpus: Sentiment Analysis using Fallout New Vegas Dialog
Dec 05, 2022
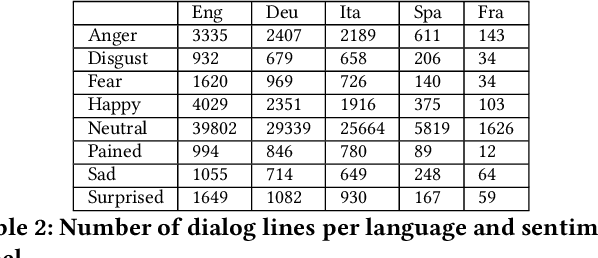
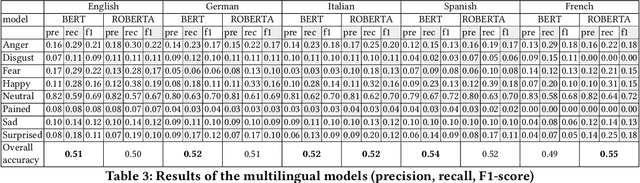
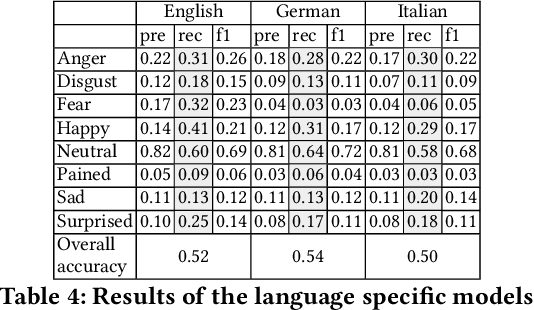
We present a method for extracting a multilingual sentiment annotated dialog data set from Fallout New Vegas. The game developers have preannotated every line of dialog in the game in one of the 8 different sentiments: \textit{anger, disgust, fear, happy, neutral, pained, sad } and \textit{surprised}. The game has been translated into English, Spanish, German, French and Italian. We conduct experiments on multilingual, multilabel sentiment analysis on the extracted data set using multilingual BERT, XLMRoBERTa and language specific BERT models. In our experiments, multilingual BERT outperformed XLMRoBERTa for most of the languages, also language specific models were slightly better than multilingual BERT for most of the languages. The best overall accuracy was 54\% and it was achieved by using multilingual BERT on Spanish data. The extracted data set presents a challenging task for sentiment analysis. We have released the data, including the testing and training splits, openly on Zenodo. The data set has been shuffled for copyright reasons.
Sentiment analysis on electricity twitter posts
Jun 10, 2022
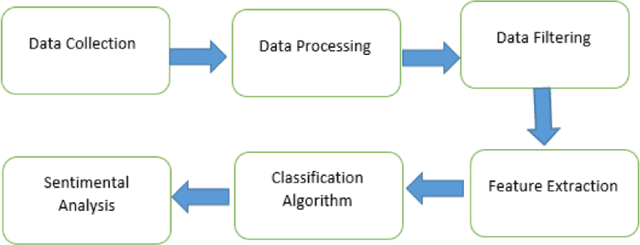
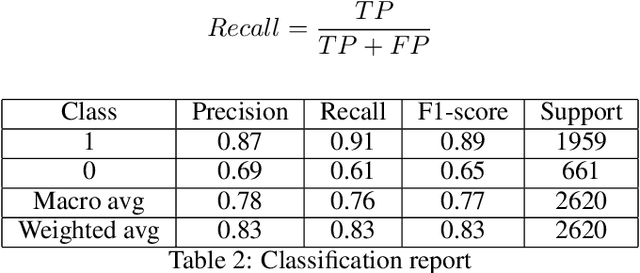
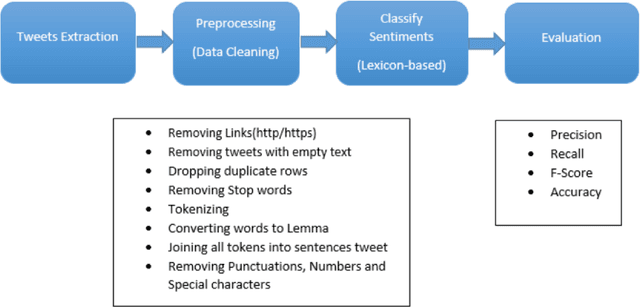
In today's world, everyone is expressive in some way, and the focus of this project is on people's opinions about rising electricity prices in United Kingdom and India using data from Twitter, a micro-blogging platform on which people post messages, known as tweets. Because many people's incomes are not good and they have to pay so many taxes and bills, maintaining a home has become a disputed issue these days. Despite the fact that Government offered subsidy schemes to compensate people electricity bills but it is not welcomed by people. In this project, the aim is to perform sentiment analysis on people's expressions and opinions expressed on Twitter. In order to grasp the electricity prices opinion, it is necessary to carry out sentiment analysis for the government and consumers in energy market. Furthermore, text present on these medias are unstructured in nature, so to process them we firstly need to pre-process the data. There are so many feature extraction techniques such as Bag of Words, TF-IDF (Term Frequency-Inverse Document Frequency), word embedding, NLP based features like word count. In this project, we analysed the impact of feature TF-IDF word level on electricity bills dataset of sentiment analysis. We found that by using TF-IDF word level performance of sentiment analysis is 3-4 higher than using N-gram features. Analysis is done using four classification algorithms including Naive Bayes, Decision Tree, Random Forest, and Logistic Regression and considering F-Score, Accuracy, Precision, and Recall performance parameters.
Soft Prompt Guided Joint Learning for Cross-Domain Sentiment Analysis
Mar 01, 2023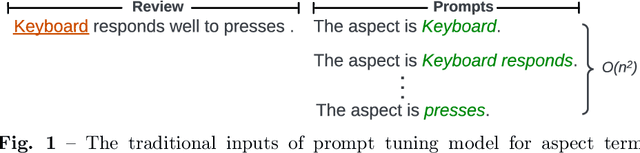
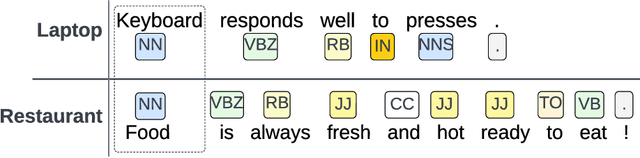

Aspect term extraction is a fundamental task in fine-grained sentiment analysis, which aims at detecting customer's opinion targets from reviews on product or service. The traditional supervised models can achieve promising results with annotated datasets, however, the performance dramatically decreases when they are applied to the task of cross-domain aspect term extraction. Existing cross-domain transfer learning methods either directly inject linguistic features into Language models, making it difficult to transfer linguistic knowledge to target domain, or rely on the fixed predefined prompts, which is time-consuming to construct the prompts over all potential aspect term spans. To resolve the limitations, we propose a soft prompt-based joint learning method for cross domain aspect term extraction in this paper. Specifically, by incorporating external linguistic features, the proposed method learn domain-invariant representations between source and target domains via multiple objectives, which bridges the gap between domains with varied distributions of aspect terms. Further, the proposed method interpolates a set of transferable soft prompts consisted of multiple learnable vectors that are beneficial to detect aspect terms in target domain. Extensive experiments are conducted on the benchmark datasets and the experimental results demonstrate the effectiveness of the proposed method for cross-domain aspect terms extraction.
Applications and Challenges of Sentiment Analysis in Real-life Scenarios
Jan 24, 2023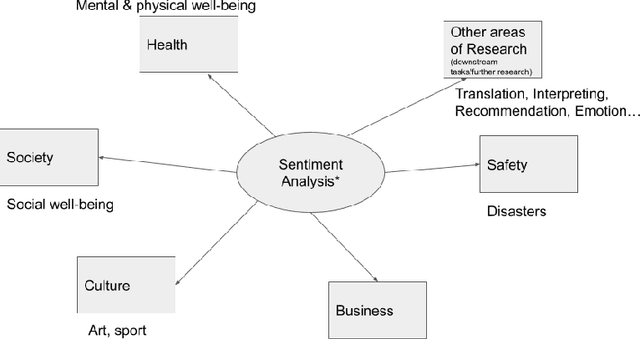
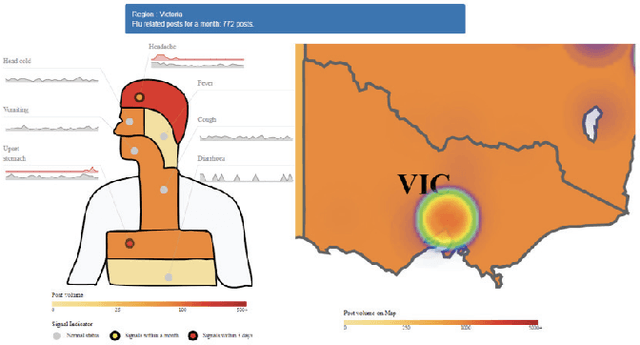
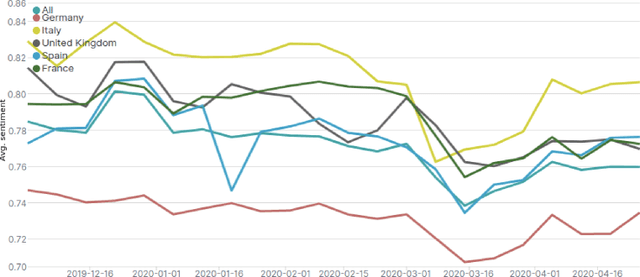
Sentiment analysis has benefited from the availability of lexicons and benchmark datasets created over decades of research. However, its applications to the real world are a driving force for research in SA. This chapter describes some of these applications and related challenges in real-life scenarios. In this chapter, we focus on five applications of SA: health, social policy, e-commerce, digital humanities and other areas of NLP. This chapter is intended to equip an NLP researcher with the `what', `why' and `how' of applications of SA: what is the application about, why it is important and challenging and how current research in SA deals with the application. We note that, while the use of deep learning techniques is a popular paradigm that spans these applications, challenges around privacy and selection bias of datasets is a recurring theme across several applications.
Aspect-oriented Opinion Alignment Network for Aspect-Based Sentiment Classification
Aug 22, 2023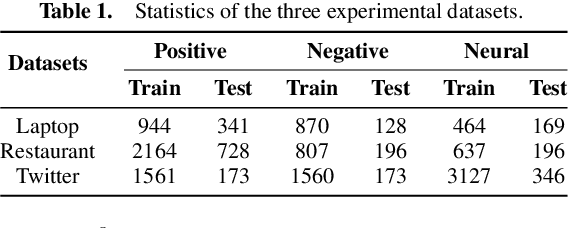
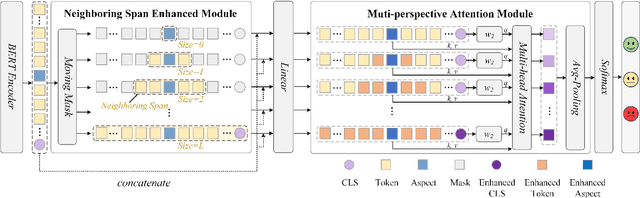
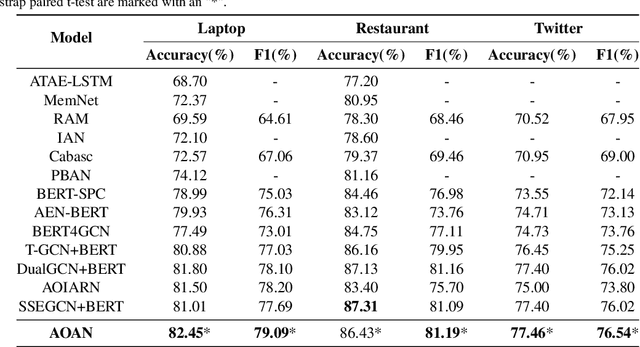
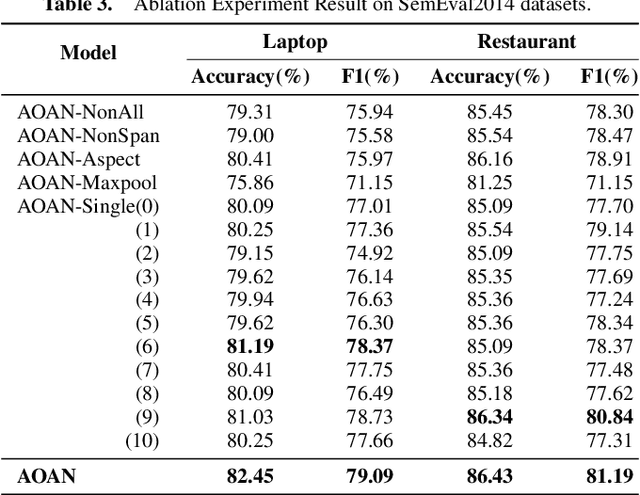
Aspect-based sentiment classification is a crucial problem in fine-grained sentiment analysis, which aims to predict the sentiment polarity of the given aspect according to its context. Previous works have made remarkable progress in leveraging attention mechanism to extract opinion words for different aspects. However, a persistent challenge is the effective management of semantic mismatches, which stem from attention mechanisms that fall short in adequately aligning opinions words with their corresponding aspect in multi-aspect sentences. To address this issue, we propose a novel Aspect-oriented Opinion Alignment Network (AOAN) to capture the contextual association between opinion words and the corresponding aspect. Specifically, we first introduce a neighboring span enhanced module which highlights various compositions of neighboring words and given aspects. In addition, we design a multi-perspective attention mechanism that align relevant opinion information with respect to the given aspect. Extensive experiments on three benchmark datasets demonstrate that our model achieves state-of-the-art results. The source code is available at https://github.com/AONE-NLP/ABSA-AOAN.
Lex2Sent: A bagging approach to unsupervised sentiment analysis
Sep 26, 2022
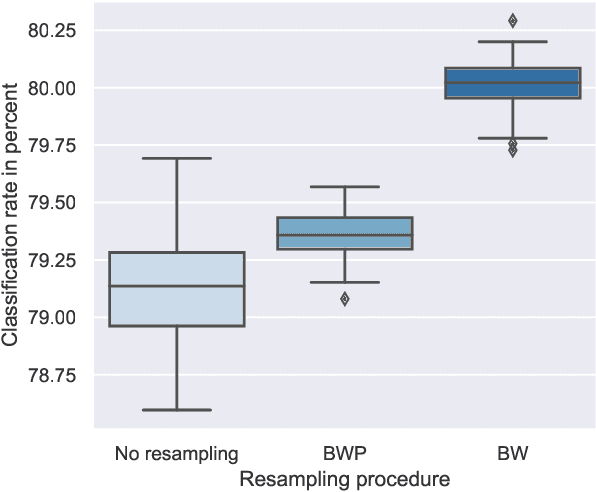
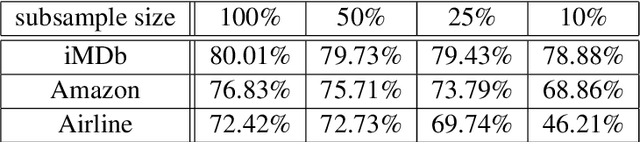
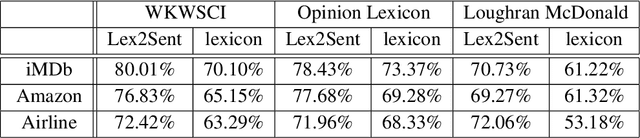
Unsupervised sentiment analysis is traditionally performed by counting those words in a text that are stored in a sentiment lexicon and then assigning a label depending on the proportion of positive and negative words registered. While these "counting" methods are considered to be beneficial as they rate a text deterministically, their classification rates decrease when the analyzed texts are short or the vocabulary differs from what the lexicon considers default. The model proposed in this paper, called Lex2Sent, is an unsupervised sentiment analysis method to improve the classification of sentiment lexicon methods. For this purpose, a Doc2Vec-model is trained to determine the distances between document embeddings and the embeddings of the positive and negative part of a sentiment lexicon. These distances are then evaluated for multiple executions of Doc2Vec on resampled documents and are averaged to perform the classification task. For three benchmark datasets considered in this paper, the proposed Lex2Sent outperforms every evaluated lexicon, including state-of-the-art lexica like VADER or the Opinion Lexicon in terms of classification rate.
BERT-Deep CNN: State-of-the-Art for Sentiment Analysis of COVID-19 Tweets
Nov 04, 2022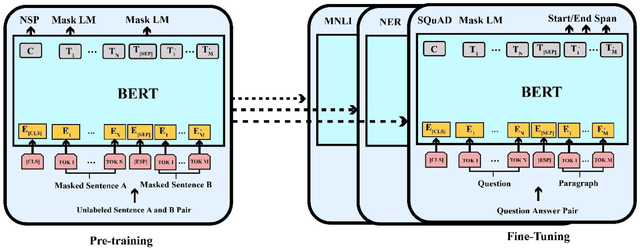
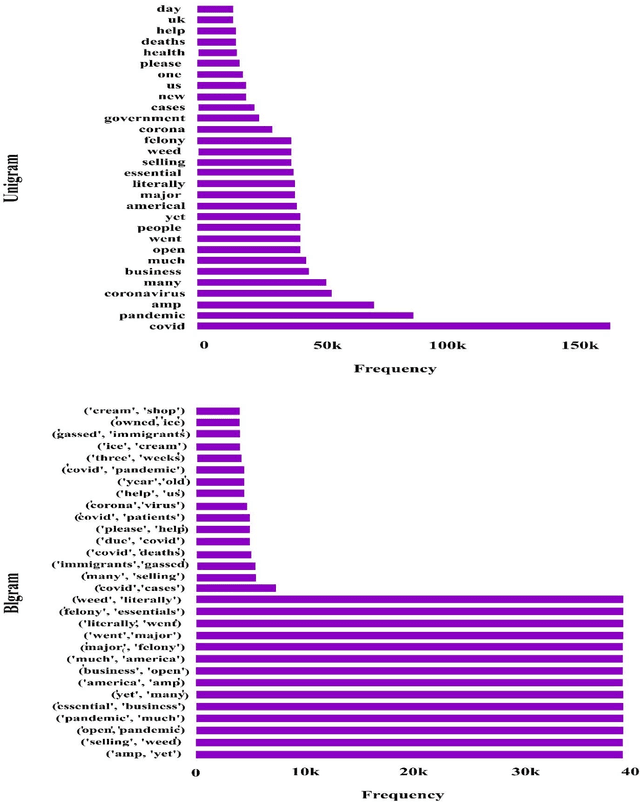
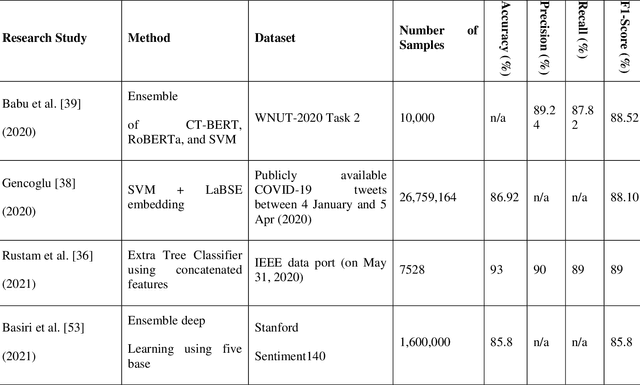
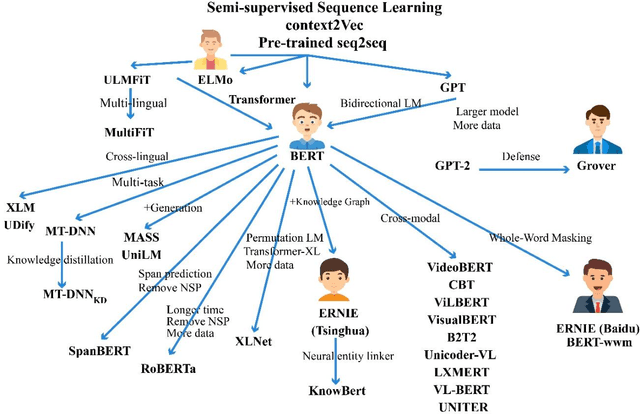
The free flow of information has been accelerated by the rapid development of social media technology. There has been a significant social and psychological impact on the population due to the outbreak of Coronavirus disease (COVID-19). The COVID-19 pandemic is one of the current events being discussed on social media platforms. In order to safeguard societies from this pandemic, studying people's emotions on social media is crucial. As a result of their particular characteristics, sentiment analysis of texts like tweets remains challenging. Sentiment analysis is a powerful text analysis tool. It automatically detects and analyzes opinions and emotions from unstructured data. Texts from a wide range of sources are examined by a sentiment analysis tool, which extracts meaning from them, including emails, surveys, reviews, social media posts, and web articles. To evaluate sentiments, natural language processing (NLP) and machine learning techniques are used, which assign weights to entities, topics, themes, and categories in sentences or phrases. Machine learning tools learn how to detect sentiment without human intervention by examining examples of emotions in text. In a pandemic situation, analyzing social media texts to uncover sentimental trends can be very helpful in gaining a better understanding of society's needs and predicting future trends. We intend to study society's perception of the COVID-19 pandemic through social media using state-of-the-art BERT and Deep CNN models. The superiority of BERT models over other deep models in sentiment analysis is evident and can be concluded from the comparison of the various research studies mentioned in this article.