 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Sentiment Analysis": models, code, and papers
A novel Counterfactual method for aspect-based sentiment analysis
Jun 24, 2023
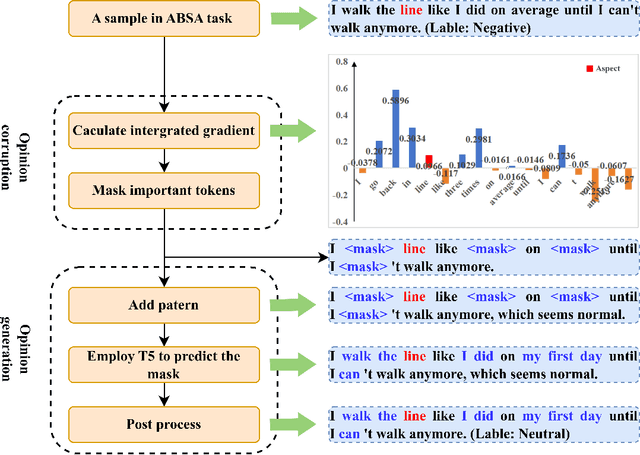
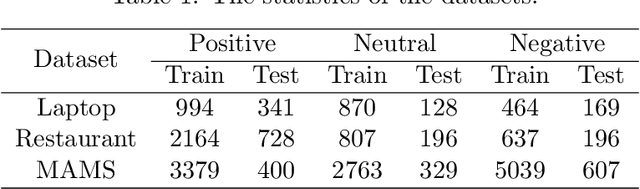
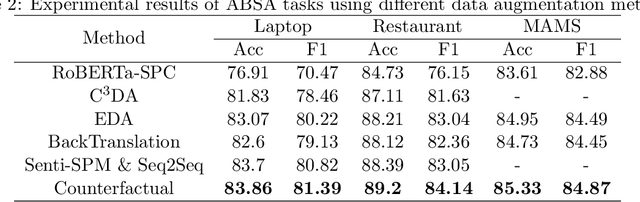
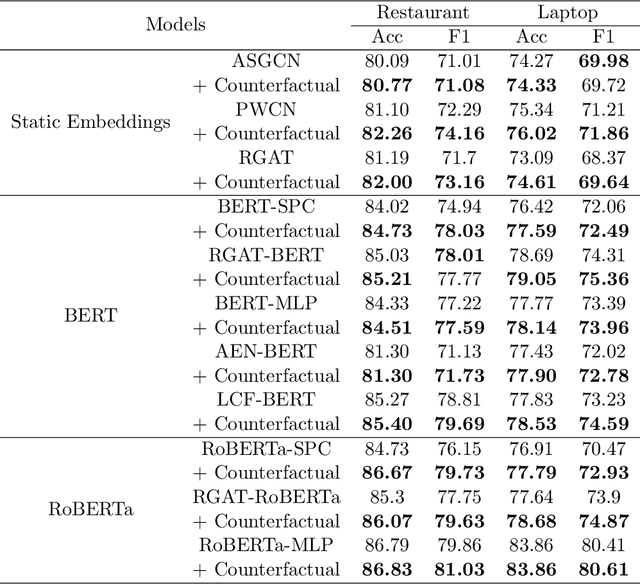
Aspect-based-sentiment-analysis (ABSA) is a fine-grained sentiment evaluation task, which analyze the emotional polarity of the evaluation aspects. However, previous works only focus on the identification of opinion expressions, forget that the diversity of opinion expressions also has great impacts on the ABSA task. To mitigate this problem, we propose a novel counterfactual data augmentation method to generate opinion expression with reversed sentiment polarity. Specially, the integrated gradients are calculated to identify and mask the opinion expression. Then, a prompt with the reverse label is combined to the original text, and a pre-trained language model (PLM), T5, is finally employed to retrieve the masks. The experimental results show the proposed counterfactual data augmentation method perform better than current augmentation methods on three ABSA datasets, i.e. Laptop, Restaurant and MAMS.
Adapt in Contexts: Retrieval-Augmented Domain Adaptation via In-Context Learning
Nov 20, 2023Large language models (LLMs) have showcased their capability with few-shot inference known as in-context learning. However, in-domain demonstrations are not always readily available in real scenarios, leading to cross-domain in-context learning. Besides, LLMs are still facing challenges in long-tail knowledge in unseen and unfamiliar domains. The above limitations demonstrate the necessity of Unsupervised Domain Adaptation (UDA). In this paper, we study the UDA problem under an in-context learning setting to adapt language models from the source domain to the target domain without any target labels. The core idea is to retrieve a subset of cross-domain elements that are the most similar to the query, and elicit language model to adapt in an in-context manner by learning both target domain distribution and the discriminative task signal simultaneously with the augmented cross-domain in-context examples. We devise different prompting and training strategies, accounting for different LM architectures to learn the target distribution via language modeling. With extensive experiments on Sentiment Analysis (SA) and Named Entity Recognition (NER) tasks, we thoroughly study the effectiveness of ICL for domain transfer and demonstrate significant improvements over baseline models.
SentiGOLD: A Large Bangla Gold Standard Multi-Domain Sentiment Analysis Dataset and its Evaluation
Jun 09, 2023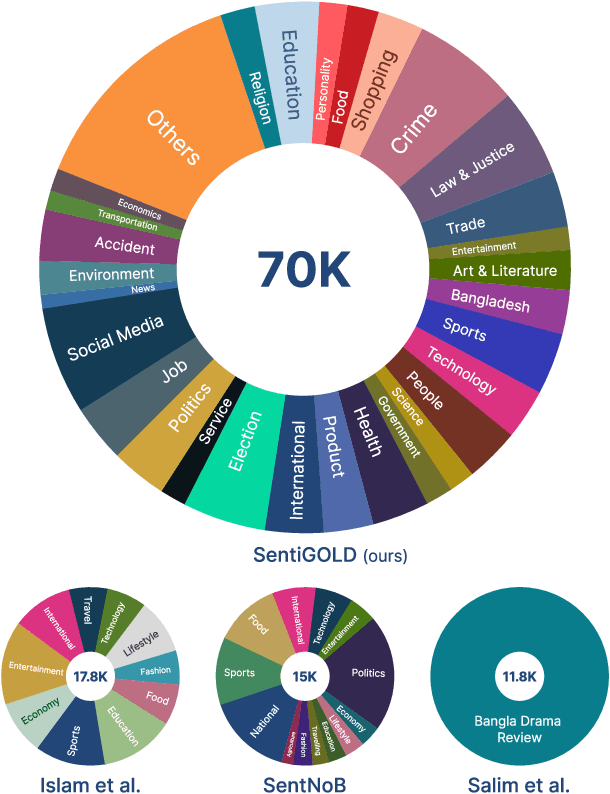
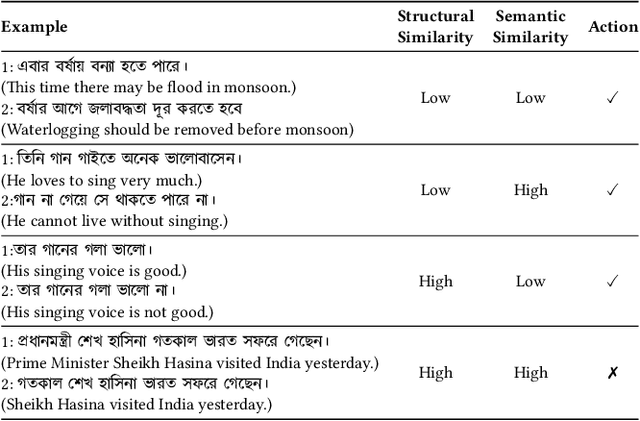
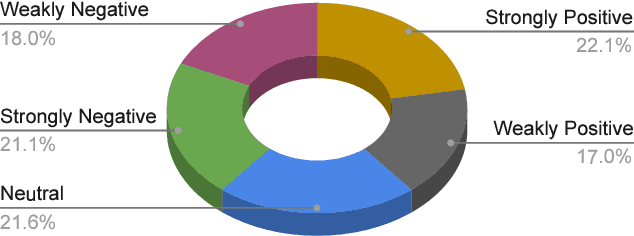
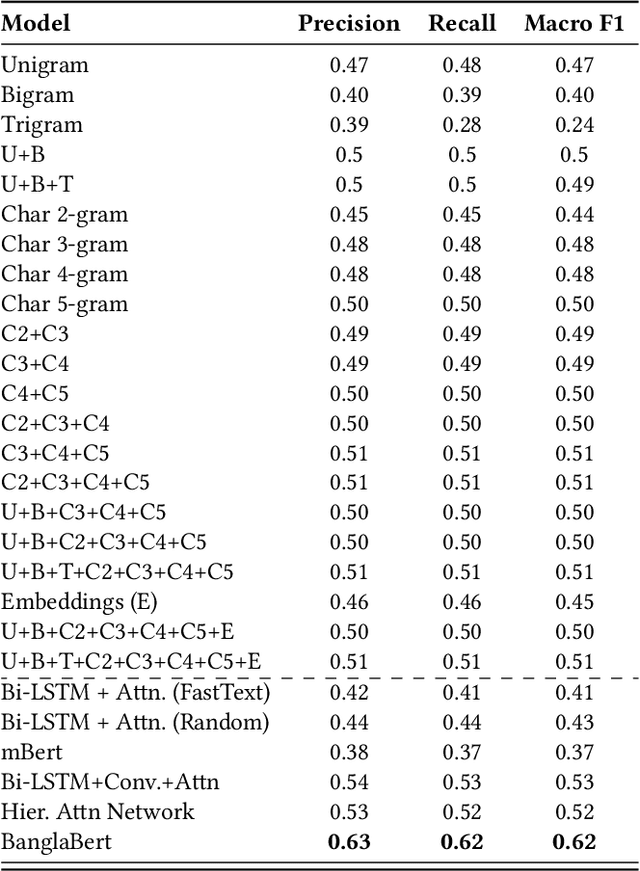
This study introduces SentiGOLD, a Bangla multi-domain sentiment analysis dataset. Comprising 70,000 samples, it was created from diverse sources and annotated by a gender-balanced team of linguists. SentiGOLD adheres to established linguistic conventions agreed upon by the Government of Bangladesh and a Bangla linguistics committee. Unlike English and other languages, Bangla lacks standard sentiment analysis datasets due to the absence of a national linguistics framework. The dataset incorporates data from online video comments, social media posts, blogs, news, and other sources while maintaining domain and class distribution rigorously. It spans 30 domains (e.g., politics, entertainment, sports) and includes 5 sentiment classes (strongly negative, weakly negative, neutral, and strongly positive). The annotation scheme, approved by the national linguistics committee, ensures a robust Inter Annotator Agreement (IAA) with a Fleiss' kappa score of 0.88. Intra- and cross-dataset evaluation protocols are applied to establish a standard classification system. Cross-dataset evaluation on the noisy SentNoB dataset presents a challenging test scenario. Additionally, zero-shot experiments demonstrate the generalizability of SentiGOLD. The top model achieves a macro f1 score of 0.62 (intra-dataset) across 5 classes, setting a benchmark, and 0.61 (cross-dataset from SentNoB) across 3 classes, comparable to the state-of-the-art. Fine-tuned sentiment analysis model can be accessed at https://sentiment.bangla.gov.bd.
A Comparative Analysis of the COVID-19 Infodemic in English and Chinese: Insights from Social Media Textual Data
Nov 14, 2023The COVID-19 infodemic, characterized by the rapid spread of misinformation and unverified claims related to the pandemic, presents a significant challenge. This paper presents a comparative analysis of the COVID-19 infodemic in the English and Chinese languages, utilizing textual data extracted from social media platforms. To ensure a balanced representation, two infodemic datasets were created by augmenting previously collected social media textual data. Through word frequency analysis, the thirty-five most frequently occurring infodemic words are identified, shedding light on prevalent discussions surrounding the infodemic. Moreover, topic clustering analysis uncovers thematic structures and provides a deeper understanding of primary topics within each language context. Additionally, sentiment analysis enables comprehension of the emotional tone associated with COVID-19 information on social media platforms in English and Chinese. This research contributes to a better understanding of the COVID-19 infodemic phenomenon and can guide the development of strategies to combat misinformation during public health crises across different languages.
AlbMoRe: A Corpus of Movie Reviews for Sentiment Analysis in Albanian
Jun 14, 2023


Lack of available resources such as text corpora for low-resource languages seriously hinders research on natural language processing and computational linguistics. This paper presents AlbMoRe, a corpus of 800 sentiment annotated movie reviews in Albanian. Each text is labeled as positive or negative and can be used for sentiment analysis research. Preliminary results based on traditional machine learning classifiers trained with the AlbMoRe samples are also reported. They can serve as comparison baselines for future research experiments.
Delving Deeper Into Astromorphic Transformers
Dec 18, 2023Preliminary attempts at incorporating the critical role of astrocytes - cells that constitute more than 50% of human brain cells - in brain-inspired neuromorphic computing remain in infancy. This paper seeks to delve deeper into various key aspects of neuron-synapse-astrocyte interactions to mimic self-attention mechanisms in Transformers. The cross-layer perspective explored in this work involves bio-plausible modeling of Hebbian and pre-synaptic plasticities in neuron-astrocyte networks, incorporating effects of non-linearities and feedback along with algorithmic formulations to map the neuron-astrocyte computations to self-attention mechanism and evaluating the impact of incorporating bio-realistic effects from the machine learning application side. Our analysis on sentiment and image classification tasks on the IMDB and CIFAR10 datasets underscores the importance of constructing Astromorphic Transformers from both accuracy and learning speed improvement perspectives.
FinXABSA: Explainable Finance through Aspect-Based Sentiment Analysis
Mar 16, 2023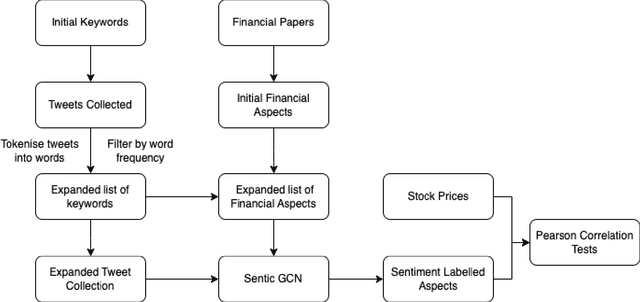
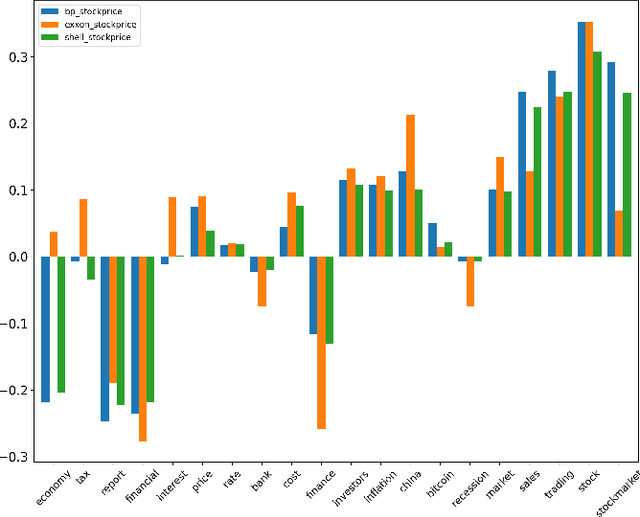
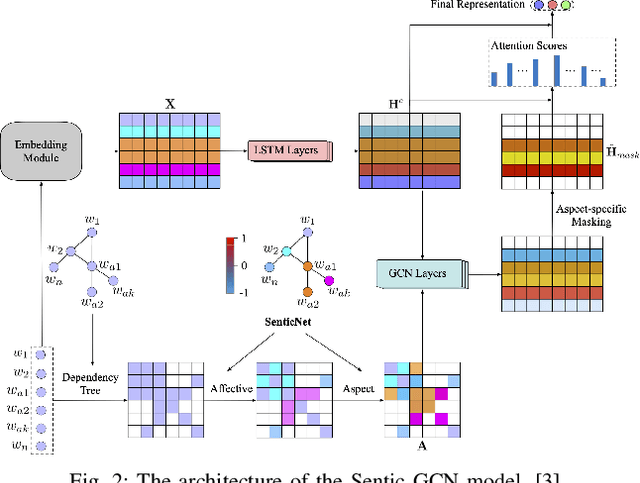
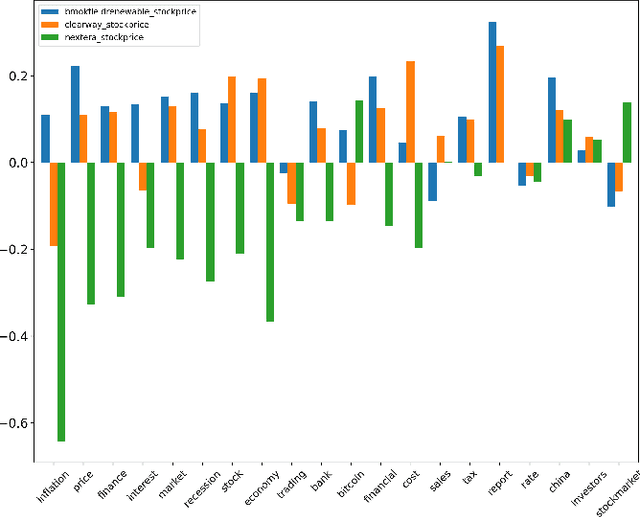
This paper presents a novel approach for explainability in financial analysis by utilizing the Pearson correlation coefficient to establish a relationship between aspect-based sentiment analysis and stock prices. The proposed methodology involves constructing an aspect list from financial news articles and analyzing sentiment intensity scores for each aspect. These scores are then compared to the stock prices for the relevant companies using the Pearson coefficient to determine any significant correlations. The results indicate that the proposed approach provides a more detailed and accurate understanding of the relationship between sentiment analysis and stock prices, which can be useful for investors and financial analysts in making informed decisions. Additionally, this methodology offers a transparent and interpretable way to explain the sentiment analysis results and their impact on stock prices. Overall, the findings of this paper demonstrate the importance of explainability in financial analysis and highlight the potential benefits of utilizing the Pearson coefficient for analyzing aspect-based sentiment analysis and stock prices. The proposed approach offers a valuable tool for understanding the complex relationships between financial news sentiment and stock prices, providing a new perspective on the financial market and aiding in making informed investment decisions.
AoM: Detecting Aspect-oriented Information for Multimodal Aspect-Based Sentiment Analysis
May 31, 2023
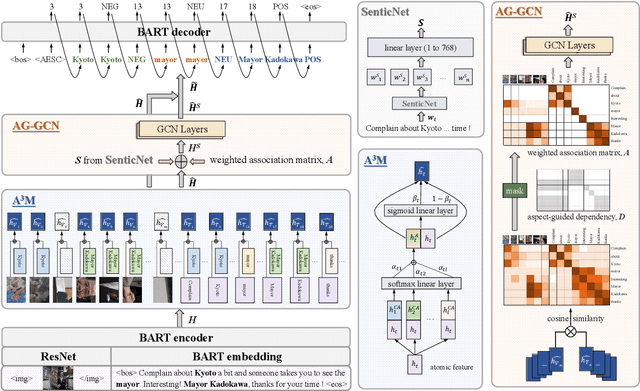
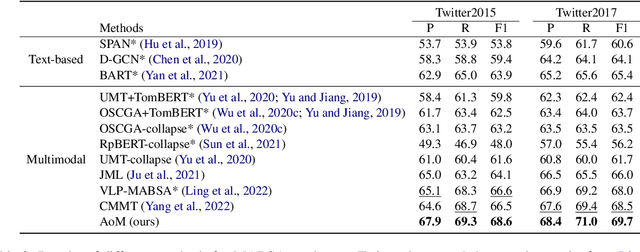
Multimodal aspect-based sentiment analysis (MABSA) aims to extract aspects from text-image pairs and recognize their sentiments. Existing methods make great efforts to align the whole image to corresponding aspects. However, different regions of the image may relate to different aspects in the same sentence, and coarsely establishing image-aspect alignment will introduce noise to aspect-based sentiment analysis (i.e., visual noise). Besides, the sentiment of a specific aspect can also be interfered by descriptions of other aspects (i.e., textual noise). Considering the aforementioned noises, this paper proposes an Aspect-oriented Method (AoM) to detect aspect-relevant semantic and sentiment information. Specifically, an aspect-aware attention module is designed to simultaneously select textual tokens and image blocks that are semantically related to the aspects. To accurately aggregate sentiment information, we explicitly introduce sentiment embedding into AoM, and use a graph convolutional network to model the vision-text and text-text interaction. Extensive experiments demonstrate the superiority of AoM to existing methods. The source code is publicly released at https://github.com/SilyRab/AoM.
New Adversarial Image Detection Based on Sentiment Analysis
May 03, 2023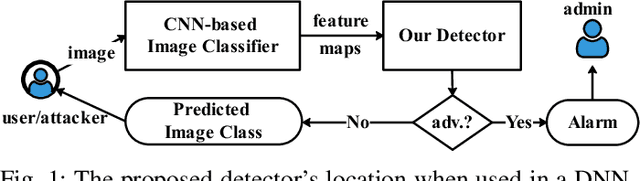
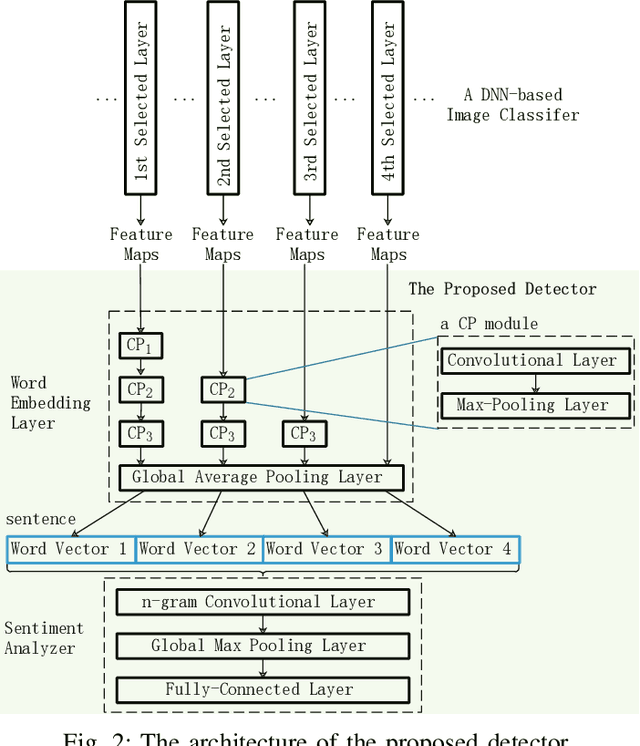
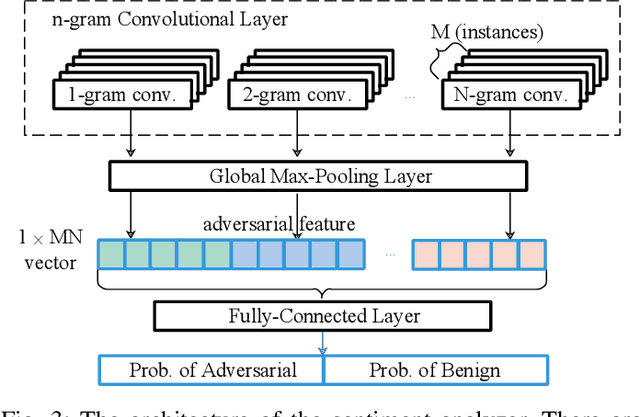

Deep Neural Networks (DNNs) are vulnerable to adversarial examples, while adversarial attack models, e.g., DeepFool, are on the rise and outrunning adversarial example detection techniques. This paper presents a new adversarial example detector that outperforms state-of-the-art detectors in identifying the latest adversarial attacks on image datasets. Specifically, we propose to use sentiment analysis for adversarial example detection, qualified by the progressively manifesting impact of an adversarial perturbation on the hidden-layer feature maps of a DNN under attack. Accordingly, we design a modularized embedding layer with the minimum learnable parameters to embed the hidden-layer feature maps into word vectors and assemble sentences ready for sentiment analysis. Extensive experiments demonstrate that the new detector consistently surpasses the state-of-the-art detection algorithms in detecting the latest attacks launched against ResNet and Inception neutral networks on the CIFAR-10, CIFAR-100 and SVHN datasets. The detector only has about 2 million parameters, and takes shorter than 4.6 milliseconds to detect an adversarial example generated by the latest attack models using a Tesla K80 GPU card.