 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Recommendation": models, code, and papers
Supplier Recommendation in Online Procurement
Mar 02, 2024

Supply chain optimization is key to a healthy and profitable business. Many companies use online procurement systems to agree contracts with suppliers. It is vital that the most competitive suppliers are invited to bid for such contracts. In this work, we propose a recommender system to assist with supplier discovery in road freight online procurement. Our system is able to provide personalized supplier recommendations, taking into account customer needs and preferences. This is a novel application of recommender systems, calling for design choices that fit the unique requirements of online procurement. Our preliminary results, using real-world data, are promising.
Physical Trajectory Inference Attack and Defense in Decentralized POI Recommendation
Jan 26, 2024As an indispensable personalized service within Location-Based Social Networks (LBSNs), the Point-of-Interest (POI) recommendation aims to assist individuals in discovering attractive and engaging places. However, the accurate recommendation capability relies on the powerful server collecting a vast amount of users' historical check-in data, posing significant risks of privacy breaches. Although several collaborative learning (CL) frameworks for POI recommendation enhance recommendation resilience and allow users to keep personal data on-device, they still share personal knowledge to improve recommendation performance, thus leaving vulnerabilities for potential attackers. Given this, we design a new Physical Trajectory Inference Attack (PTIA) to expose users' historical trajectories. Specifically, for each user, we identify the set of interacted POIs by analyzing the aggregated information from the target POIs and their correlated POIs. We evaluate the effectiveness of PTIA on two real-world datasets across two types of decentralized CL frameworks for POI recommendation. Empirical results demonstrate that PTIA poses a significant threat to users' historical trajectories. Furthermore, Local Differential Privacy (LDP), the traditional privacy-preserving method for CL frameworks, has also been proven ineffective against PTIA. In light of this, we propose a novel defense mechanism (AGD) against PTIA based on an adversarial game to eliminate sensitive POIs and their information in correlated POIs. After conducting intensive experiments, AGD has been proven precise and practical, with minimal impact on recommendation performance.
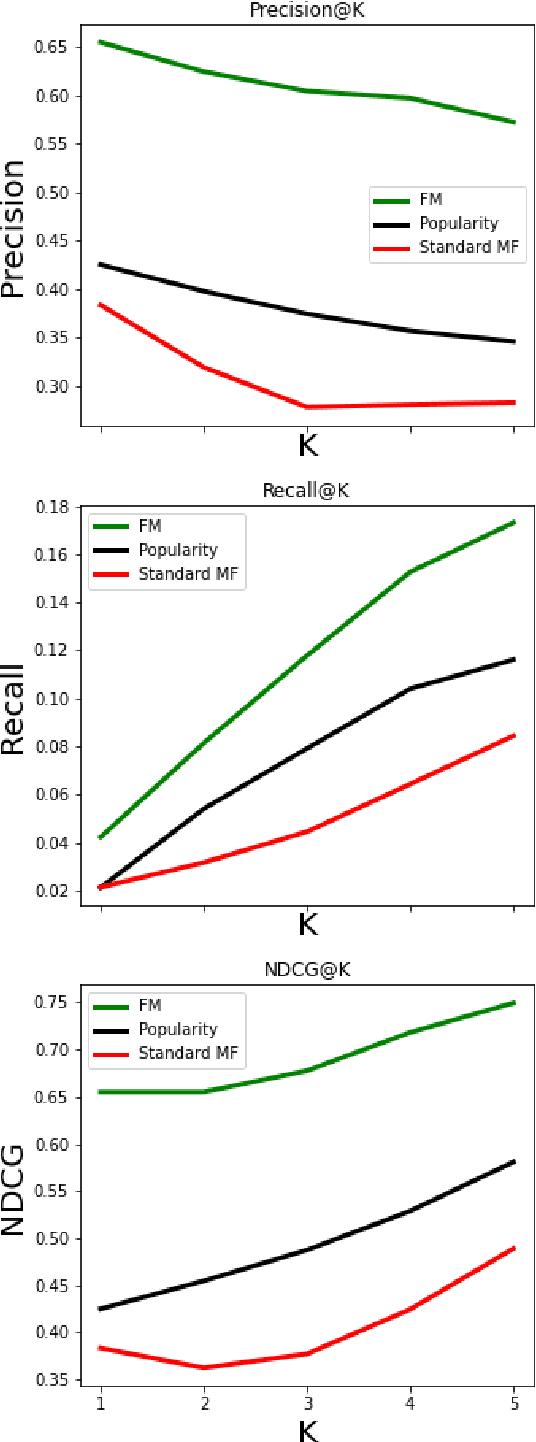
A Distance Metric Learning Model Based On Variational Information Bottleneck
Mar 05, 2024
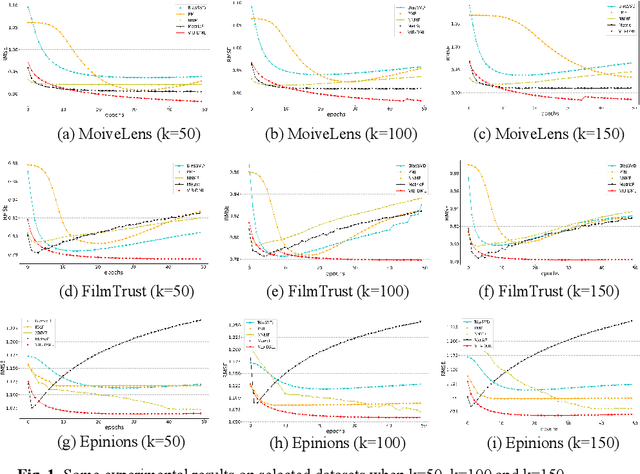

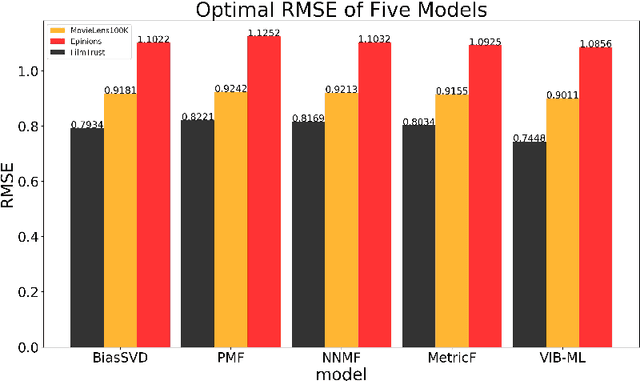
In recent years, personalized recommendation technology has flourished and become one of the hot research directions. The matrix factorization model and the metric learning model which proposed successively have been widely studied and applied. The latter uses the Euclidean distance instead of the dot product used by the former to measure the latent space vector. While avoiding the shortcomings of the dot product, the assumption of Euclidean distance is neglected, resulting in limited recommendation quality of the model. In order to solve this problem, this paper combines the Variationl Information Bottleneck with metric learning model for the first time, and proposes a new metric learning model VIB-DML (Variational Information Bottleneck Distance Metric Learning) for rating prediction, which limits the mutual information of the latent space feature vector to improve the robustness of the model and satisfiy the assumption of Euclidean distance by decoupling the latent space feature vector. In this paper, the experimental results are compared with the root mean square error (RMSE) on the three public datasets. The results show that the generalization ability of VIB-DML is excellent. Compared with the general metric learning model MetricF, the prediction error is reduced by 7.29%. Finally, the paper proves the strong robustness of VIBDML through experiments.
Personalized Negative Reservoir for Incremental Learning in Recommender Systems
Mar 06, 2024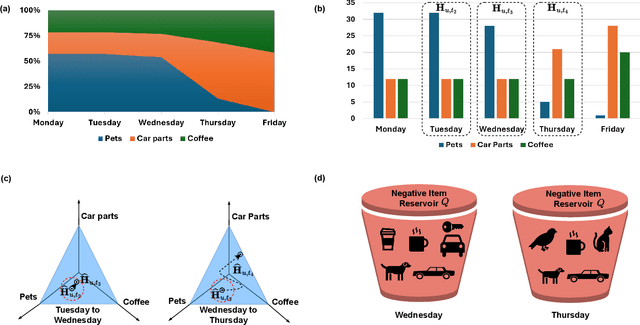
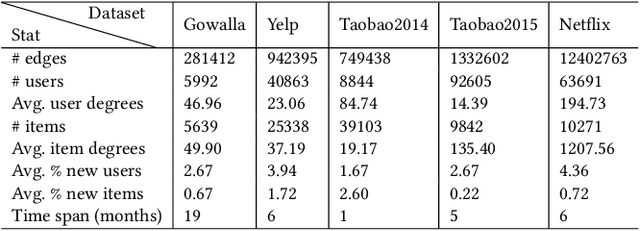
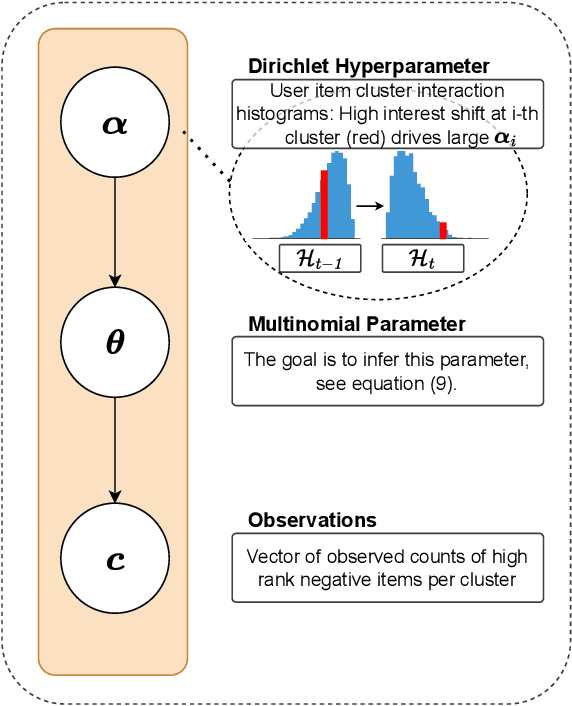

Recommender systems have become an integral part of online platforms. Every day the volume of training data is expanding and the number of user interactions is constantly increasing. The exploration of larger and more expressive models has become a necessary pursuit to improve user experience. However, this progression carries with it an increased computational burden. In commercial settings, once a recommendation system model has been trained and deployed it typically needs to be updated frequently as new client data arrive. Cumulatively, the mounting volume of data is guaranteed to eventually make full batch retraining of the model from scratch computationally infeasible. Naively fine-tuning solely on the new data runs into the well-documented problem of catastrophic forgetting. Despite the fact that negative sampling is a crucial part of training with implicit feedback, no specialized technique exists that is tailored to the incremental learning framework. In this work, we take the first step to propose, a personalized negative reservoir strategy which is used to obtain negative samples for the standard triplet loss. This technique balances alleviation of forgetting with plasticity by encouraging the model to remember stable user preferences and selectively forget when user interests change. We derive the mathematical formulation of a negative sampler to populate and update the reservoir. We integrate our design in three SOTA and commonly used incremental recommendation models. We show that these concrete realizations of our negative reservoir framework achieve state-of-the-art results in standard benchmarks, on multiple standard top-k evaluation metrics.
Rec-GPT4V: Multimodal Recommendation with Large Vision-Language Models
Feb 13, 2024The development of large vision-language models (LVLMs) offers the potential to address challenges faced by traditional multimodal recommendations thanks to their proficient understanding of static images and textual dynamics. However, the application of LVLMs in this field is still limited due to the following complexities: First, LVLMs lack user preference knowledge as they are trained from vast general datasets. Second, LVLMs suffer setbacks in addressing multiple image dynamics in scenarios involving discrete, noisy, and redundant image sequences. To overcome these issues, we propose the novel reasoning scheme named Rec-GPT4V: Visual-Summary Thought (VST) of leveraging large vision-language models for multimodal recommendation. We utilize user history as in-context user preferences to address the first challenge. Next, we prompt LVLMs to generate item image summaries and utilize image comprehension in natural language space combined with item titles to query the user preferences over candidate items. We conduct comprehensive experiments across four datasets with three LVLMs: GPT4-V, LLaVa-7b, and LLaVa-13b. The numerical results indicate the efficacy of VST.
Helping university students to choose elective courses by using a hybrid multi-criteria recommendation system with genetic optimization
Feb 13, 2024The wide availability of specific courses together with the flexibility of academic plans in university studies reveal the importance of Recommendation Systems (RSs) in this area. These systems appear as tools that help students to choose courses that suit to their personal interests and their academic performance. This paper presents a hybrid RS that combines Collaborative Filtering (CF) and Content-based Filtering (CBF) using multiple criteria related both to student and course information to recommend the most suitable courses to the students. A Genetic Algorithm (GA) has been developed to automatically discover the optimal RS configuration which include both the most relevant criteria and the configuration of the rest of parameters. The experimental study has used real information of Computer Science Degree of University of Cordoba (Spain) including information gathered from students during three academic years, counting on 2500 entries of 95 students and 63 courses. Experimental results show a study of the most relevant criteria for the course recommendation, the importance of using a hybrid model that combines both student information and course information to increase the reliability of the recommendations as well as an excellent performance compared to previous models.
A Framework for Effective AI Recommendations in Cyber-Physical-Human Systems
Mar 08, 2024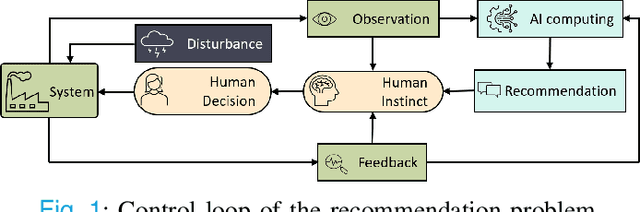
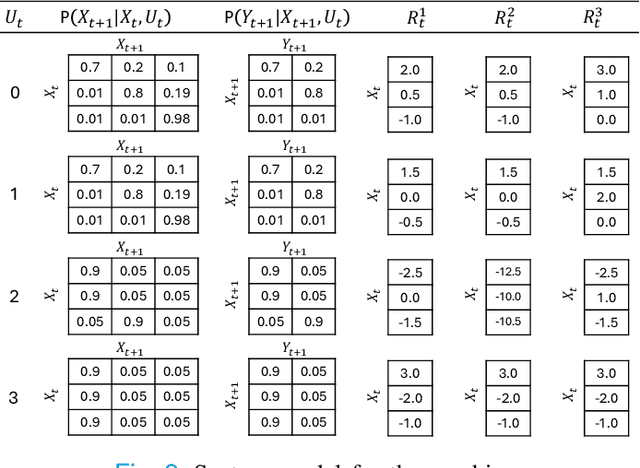
Many cyber-physical-human systems (CPHS) involve a human decision-maker who may receive recommendations from an artificial intelligence (AI) platform while holding the ultimate responsibility of making decisions. In such CPHS applications, the human decision-maker may depart from an optimal recommended decision and instead implement a different one for various reasons. In this letter, we develop a rigorous framework to overcome this challenge. In our framework, we consider that humans may deviate from AI recommendations as they perceive and interpret the system's state in a different way than the AI platform. We establish the structural properties of optimal recommendation strategies and develop an approximate human model (AHM) used by the AI. We provide theoretical bounds on the optimality gap that arises from an AHM and illustrate the efficacy of our results in a numerical example.
Aligning Large Language Models for Controllable Recommendations
Mar 08, 2024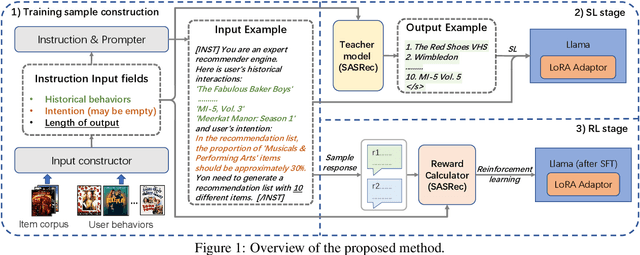
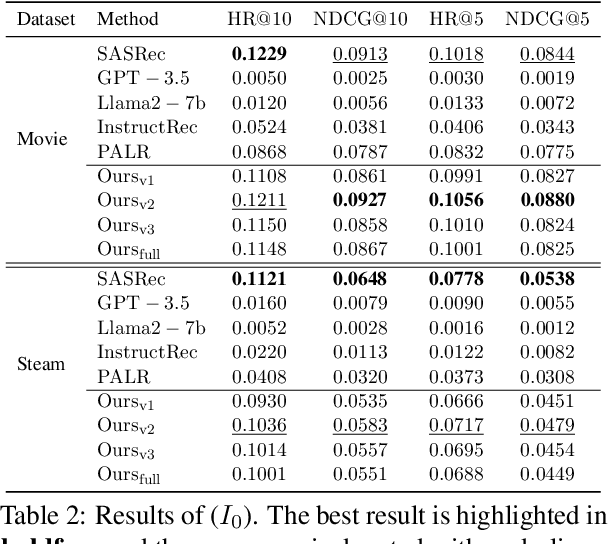
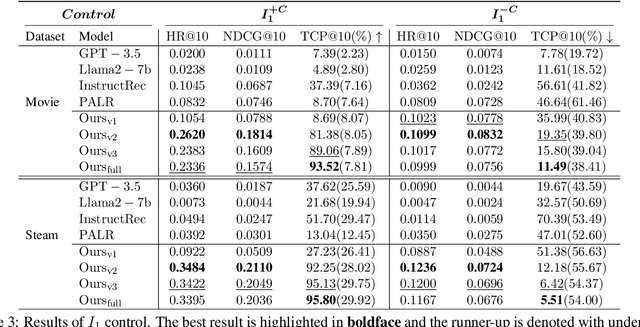
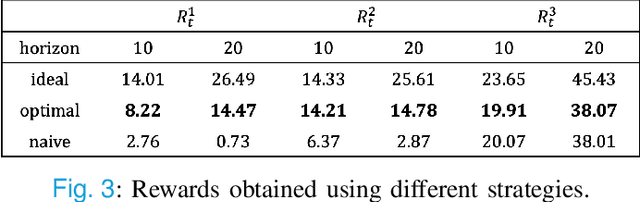
Inspired by the exceptional general intelligence of Large Language Models (LLMs), researchers have begun to explore their application in pioneering the next generation of recommender systems - systems that are conversational, explainable, and controllable. However, existing literature primarily concentrates on integrating domain-specific knowledge into LLMs to enhance accuracy, often neglecting the ability to follow instructions. To address this gap, we initially introduce a collection of supervised learning tasks, augmented with labels derived from a conventional recommender model, aimed at explicitly improving LLMs' proficiency in adhering to recommendation-specific instructions. Subsequently, we develop a reinforcement learning-based alignment procedure to further strengthen LLMs' aptitude in responding to users' intentions and mitigating formatting errors. Through extensive experiments on two real-world datasets, our method markedly advances the capability of LLMs to comply with instructions within recommender systems, while sustaining a high level of accuracy performance.
Uncovering the Deep Filter Bubble: Narrow Exposure in Short-Video Recommendation
Mar 07, 2024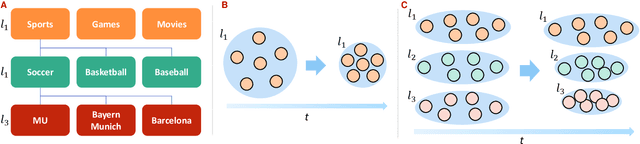
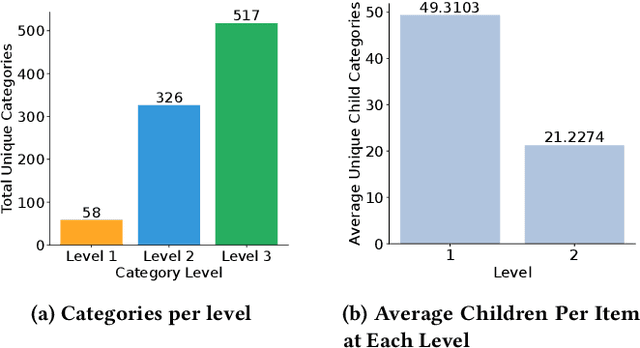
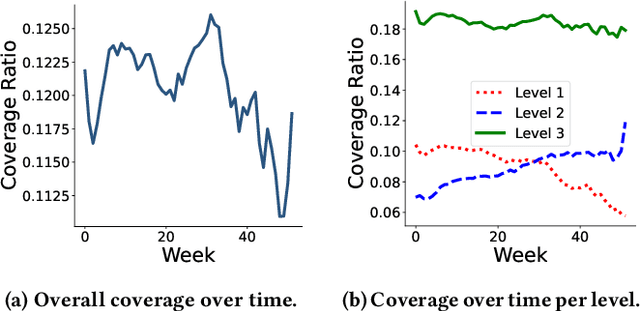
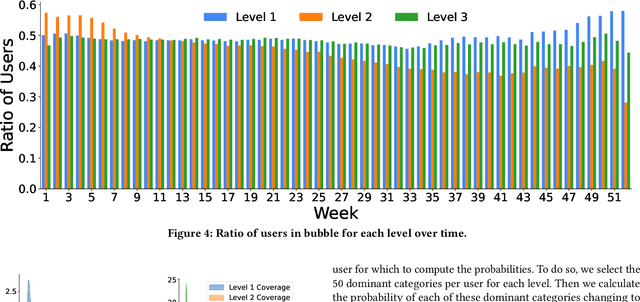
Filter bubbles have been studied extensively within the context of online content platforms due to their potential to cause undesirable outcomes such as user dissatisfaction or polarization. With the rise of short-video platforms, the filter bubble has been given extra attention because these platforms rely on an unprecedented use of the recommender system to provide relevant content. In our work, we investigate the deep filter bubble, which refers to the user being exposed to narrow content within their broad interests. We accomplish this using one-year interaction data from a top short-video platform in China, which includes hierarchical data with three levels of categories for each video. We formalize our definition of a "deep" filter bubble within this context, and then explore various correlations within the data: first understanding the evolution of the deep filter bubble over time, and later revealing some of the factors that give rise to this phenomenon, such as specific categories, user demographics, and feedback type. We observe that while the overall proportion of users in a filter bubble remains largely constant over time, the depth composition of their filter bubble changes. In addition, we find that some demographic groups that have a higher likelihood of seeing narrower content and implicit feedback signals can lead to less bubble formation. Finally, we propose some ways in which recommender systems can be designed to reduce the risk of a user getting caught in a bubble.
Towards Personalized Privacy: User-Governed Data Contribution for Federated Recommendation
Jan 31, 2024Federated recommender systems (FedRecs) have gained significant attention for their potential to protect user's privacy by keeping user privacy data locally and only communicating model parameters/gradients to the server. Nevertheless, the currently existing architecture of FedRecs assumes that all users have the same 0-privacy budget, i.e., they do not upload any data to the server, thus overlooking those users who are less concerned about privacy and are willing to upload data to get a better recommendation service. To bridge this gap, this paper explores a user-governed data contribution federated recommendation architecture where users are free to take control of whether they share data and the proportion of data they share to the server. To this end, this paper presents a cloud-device collaborative graph neural network federated recommendation model, named CDCGNNFed. It trains user-centric ego graphs locally, and high-order graphs based on user-shared data in the server in a collaborative manner via contrastive learning. Furthermore, a graph mending strategy is utilized to predict missing links in the graph on the server, thus leveraging the capabilities of graph neural networks over high-order graphs. Extensive experiments were conducted on two public datasets, and the results demonstrate the effectiveness of the proposed method.