 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Efficient Data Learning for Open Information Extraction with Pre-trained Language Models
Oct 23, 2023
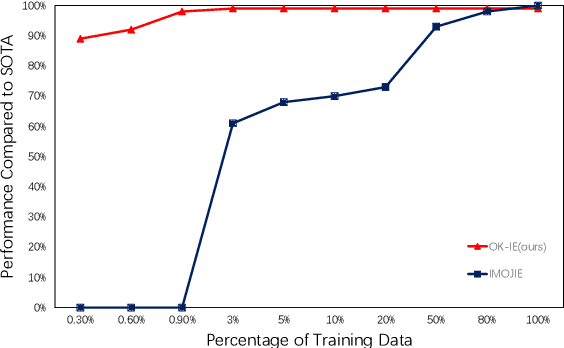
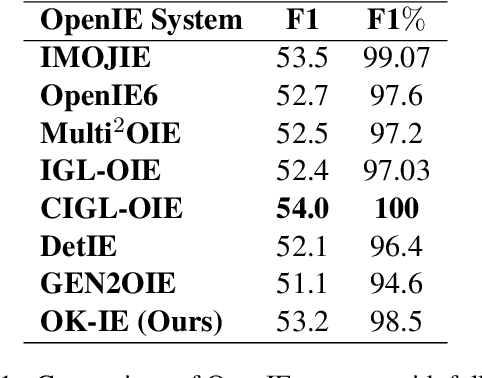

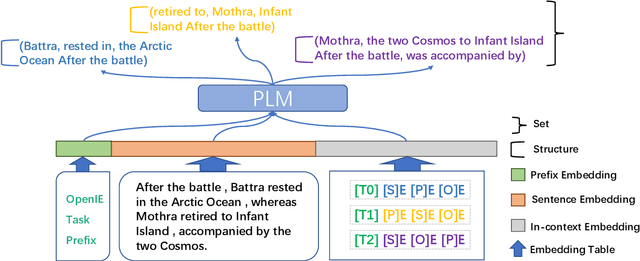
Open Information Extraction (OpenIE) is a fundamental yet challenging task in Natural Language Processing, which involves extracting all triples (subject, predicate, object) from a given sentence. While labeling-based methods have their merits, generation-based techniques offer unique advantages, such as the ability to generate tokens not present in the original sentence. However, these generation-based methods often require a significant amount of training data to learn the task form of OpenIE and substantial training time to overcome slow model convergence due to the order penalty. In this paper, we introduce a novel framework, OK-IE, that ingeniously transforms the task form of OpenIE into the pre-training task form of the T5 model, thereby reducing the need for extensive training data. Furthermore, we introduce an innovative concept of Anchor to control the sequence of model outputs, effectively eliminating the impact of order penalty on model convergence and significantly reducing training time. Experimental results indicate that, compared to previous SOTA methods, OK-IE requires only 1/100 of the training data (900 instances) and 1/120 of the training time (3 minutes) to achieve comparable results.
On RIS-Aided SIMO Gaussian Channels: Towards A Single-RF MIMO Transceiver Architecture
Nov 24, 2023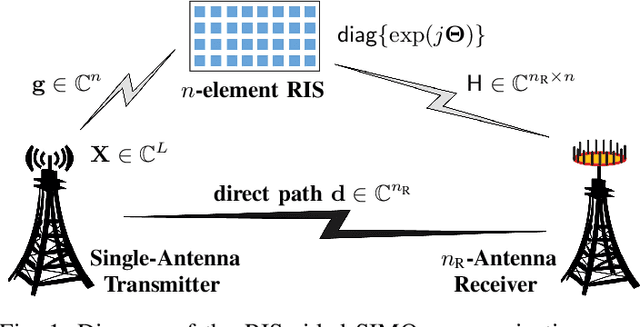
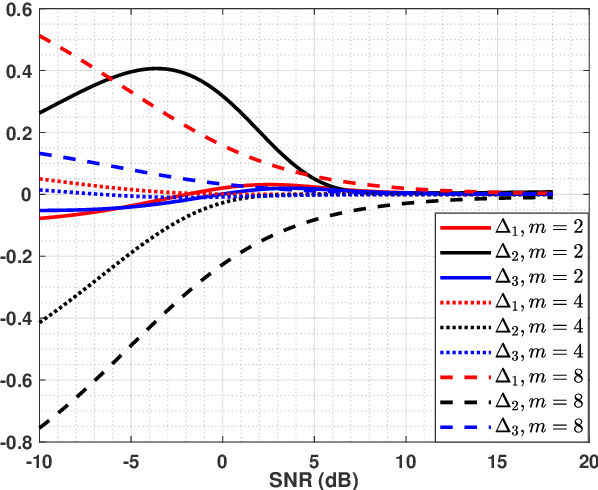
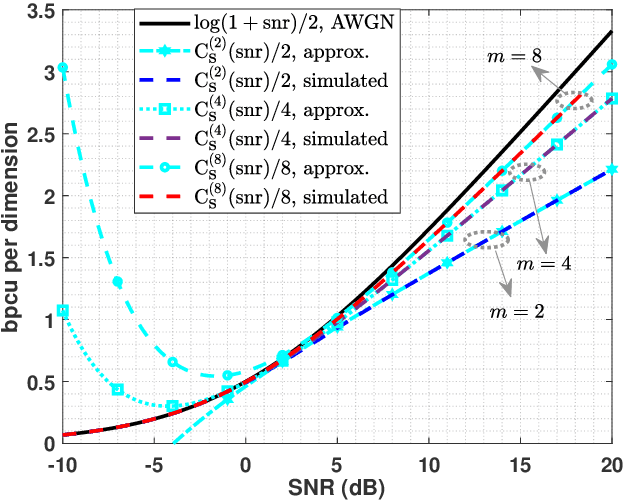
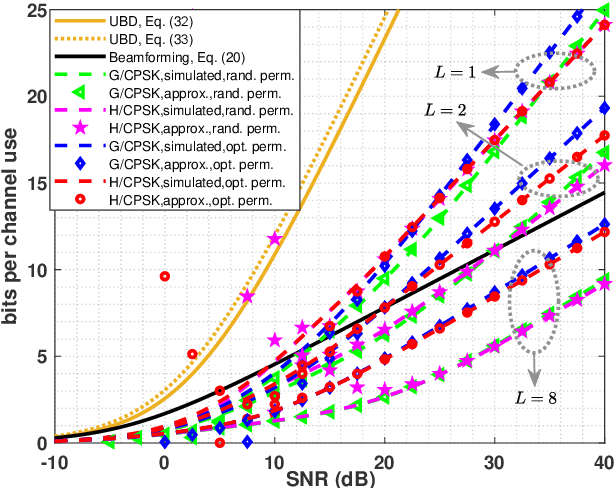
In this paper, for a single-input multiple-output (SIMO) system aided by a passive reconfigurable intelligent surface (RIS), the joint transmission accomplished by the single transmit antenna and the RIS with multiple controllable reflective elements is considered. Relying on a general capacity upper bound derived by a maximum-trace argument, we respectively characterize the capacity of such \rev{a} channel in the low-SNR or the rank-one regimes, in which the optimal configuration of the RIS is proved to be beamforming with carefully-chosen phase shifts. To exploit the potential of modulating extra information on the RIS, based on the QR decomposition, successive interference cancellation, and a strategy named \textit{partially beamforming and partially information-carrying}, we propose a novel transceiver architecture with only a single RF front end at the transmitter, by which the considered channel can be regarded as a concatenation of a vector Gaussian channel and several phase-modulated channels. Especially, we investigate a class of vector Gaussian channels with a hypersphere input support constraint, and not only generalize the existing result to arbitrary-dimensional real spaces but also present its high-order capacity asymptotics, by which both capacities of hypersphere-constrained channels and achievable rates of the proposed transceiver with two different signaling schemes can be well-approximated. Information-theoretic analyses show that the transceiver architecture designed for the SIMO channel has a boosted multiplexing gain, rather than one for the conventionally-used optimized beamforming scheme.Numerical results verify our derived asymptotics and show notable superiority of the proposed transceiver.
Towards out-of-distribution generalization in large-scale astronomical surveys: robust networks learn similar representations
Nov 29, 2023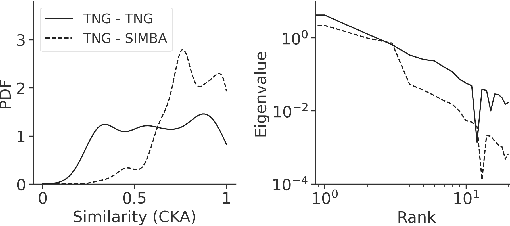
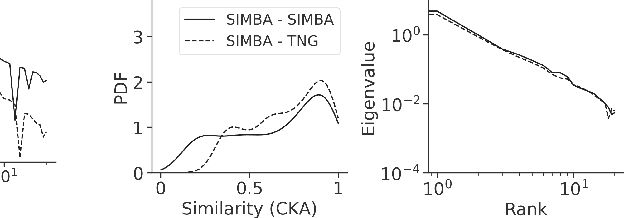
The generalization of machine learning (ML) models to out-of-distribution (OOD) examples remains a key challenge in extracting information from upcoming astronomical surveys. Interpretability approaches are a natural way to gain insights into the OOD generalization problem. We use Centered Kernel Alignment (CKA), a similarity measure metric of neural network representations, to examine the relationship between representation similarity and performance of pre-trained Convolutional Neural Networks (CNNs) on the CAMELS Multifield Dataset. We find that when models are robust to a distribution shift, they produce substantially different representations across their layers on OOD data. However, when they fail to generalize, these representations change less from layer to layer on OOD data. We discuss the potential application of similarity representation in guiding model design, training strategy, and mitigating the OOD problem by incorporating CKA as an inductive bias during training.
Insights into Age-Related Functional Brain Changes during Audiovisual Integration Tasks: A Comprehensive EEG Source-Based Analysis
Nov 27, 2023The seamless integration of visual and auditory information is a fundamental aspect of human cognition. Although age-related functional changes in Audio-Visual Integration (AVI) have been extensively explored in the past, thorough studies across various age groups remain insufficient. Previous studies have provided valuable insights into agerelated AVI using EEG-based sensor data. However, these studies have been limited in their ability to capture spatial information related to brain source activation and their connectivity. To address these gaps, our study conducted a comprehensive audiovisual integration task with a specific focus on assessing the aging effects in various age groups, particularly middle-aged individuals. We presented visual, auditory, and audio-visual stimuli and recorded EEG data from Young (18-25 years), Transition (26- 33 years), and Middle (34-42 years) age cohort healthy participants. We aimed to understand how aging affects brain activation and functional connectivity among hubs during audio-visual tasks. Our findings revealed delayed brain activation in middleaged individuals, especially for bimodal stimuli. The superior temporal cortex and superior frontal gyrus showed significant changes in neuronal activation with aging. Lower frequency bands (theta and alpha) showed substantial changes with increasing age during AVI. Our findings also revealed that the AVI-associated brain regions can be clustered into five different brain networks using the k-means algorithm. Additionally, we observed increased functional connectivity in middle age, particularly in the frontal, temporal, and occipital regions. These results highlight the compensatory neural mechanisms involved in aging during cognitive tasks.
InstructMol: Multi-Modal Integration for Building a Versatile and Reliable Molecular Assistant in Drug Discovery
Nov 27, 2023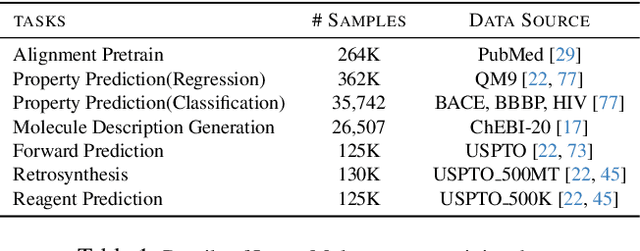
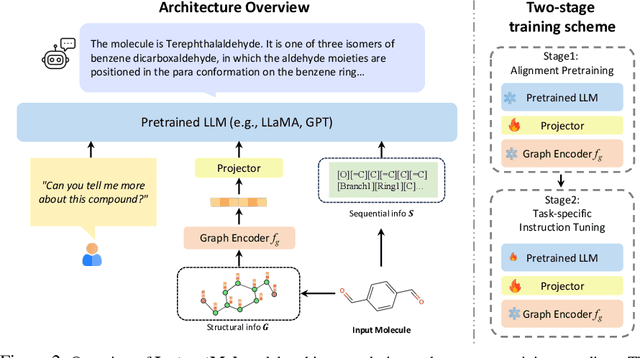
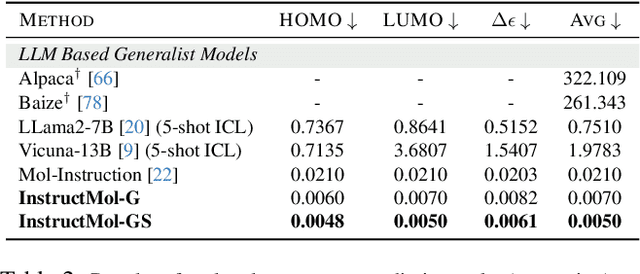
The rapid evolution of artificial intelligence in drug discovery encounters challenges with generalization and extensive training, yet Large Language Models (LLMs) offer promise in reshaping interactions with complex molecular data. Our novel contribution, InstructMol, a multi-modal LLM, effectively aligns molecular structures with natural language via an instruction-tuning approach, utilizing a two-stage training strategy that adeptly combines limited domain-specific data with molecular and textual information. InstructMol showcases substantial performance improvements in drug discovery-related molecular tasks, surpassing leading LLMs and significantly reducing the gap with specialized models, thereby establishing a robust foundation for a versatile and dependable drug discovery assistant.
Efficient Model-Based Concave Utility Reinforcement Learning through Greedy Mirror Descent
Nov 30, 2023Many machine learning tasks can be solved by minimizing a convex function of an occupancy measure over the policies that generate them. These include reinforcement learning, imitation learning, among others. This more general paradigm is called the Concave Utility Reinforcement Learning problem (CURL). Since CURL invalidates classical Bellman equations, it requires new algorithms. We introduce MD-CURL, a new algorithm for CURL in a finite horizon Markov decision process. MD-CURL is inspired by mirror descent and uses a non-standard regularization to achieve convergence guarantees and a simple closed-form solution, eliminating the need for computationally expensive projection steps typically found in mirror descent approaches. We then extend CURL to an online learning scenario and present Greedy MD-CURL, a new method adapting MD-CURL to an online, episode-based setting with partially unknown dynamics. Like MD-CURL, the online version Greedy MD-CURL benefits from low computational complexity, while guaranteeing sub-linear or even logarithmic regret, depending on the level of information available on the underlying dynamics.
Instructing Hierarchical Tasks to Robots by Verbal Commands
Nov 30, 2023Natural language is an effective tool for communication, as information can be expressed in different ways and at different levels of complexity. Verbal commands, utilized for instructing robot tasks, can therefor replace traditional robot programming techniques, and provide a more expressive means to assign actions and enable collaboration. However, the challenge of utilizing speech for robot programming is how actions and targets can be grounded to physical entities in the world. In addition, to be time-efficient, a balance needs to be found between fine- and course-grained commands and natural language phrases. In this work we provide a framework for instructing tasks to robots by verbal commands. The framework includes functionalities for single commands to actions and targets, as well as longer-term sequences of actions, thereby providing a hierarchical structure to the robot tasks. Experimental evaluation demonstrates the functionalities of the framework by human collaboration with a robot in different tasks, with different levels of complexity. The tools are provided open-source at https://petim44.github.io/voice-jogger/
Age Effects on Decision-Making, Drift Diffusion Model
Nov 30, 2023Training can improve human decision-making performance. After several training sessions, a person can quickly and accurately complete a task. However, decision-making is always a trade-off between accuracy and response time. Factors such as age and drug abuse can affect the decision-making process. This study examines how training can improve the performance of different age groups in completing a random dot motion (RDM) task. The participants are divided into two groups: old and young. They undergo a three-phase training and then repeat the same RDM task. The hierarchical drift-diffusion model analyzes the subjects' responses and determines how the model's parameters change after training for both age groups. The results show that after training, the participants were able to accumulate sensory information faster, and the model drift rate increased. However, their decision boundary decreased as they became more confident and had a lower decision-making threshold. Additionally, the old group had a higher boundary and lower drift rate in both pre and post-training, and there was less difference between the two group parameters after training.
Communication-Efficient Federated Optimization over Semi-Decentralized Networks
Nov 30, 2023In large-scale federated and decentralized learning, communication efficiency is one of the most challenging bottlenecks. While gossip communication -- where agents can exchange information with their connected neighbors -- is more cost-effective than communicating with the remote server, it often requires a greater number of communication rounds, especially for large and sparse networks. To tackle the trade-off, we examine the communication efficiency under a semi-decentralized communication protocol, in which agents can perform both agent-to-agent and agent-to-server communication in a probabilistic manner. We design a tailored communication-efficient algorithm over semi-decentralized networks, referred to as PISCO, which inherits the robustness to data heterogeneity thanks to gradient tracking and allows multiple local updates for saving communication. We establish the convergence rate of PISCO for nonconvex problems and show that PISCO enjoys a linear speedup in terms of the number of agents and local updates. Our numerical results highlight the superior communication efficiency of PISCO and its resilience to data heterogeneity and various network topologies.
Automatic Implementation of Neural Networks through Reaction Networks -- Part I: Circuit Design and Convergence Analysis
Nov 30, 2023Information processing relying on biochemical interactions in the cellular environment is essential for biological organisms. The implementation of molecular computational systems holds significant interest and potential in the fields of synthetic biology and molecular computation. This two-part article aims to introduce a programmable biochemical reaction network (BCRN) system endowed with mass action kinetics that realizes the fully connected neural network (FCNN) and has the potential to act automatically in vivo. In part I, the feedforward propagation computation, the backpropagation component, and all bridging processes of FCNN are ingeniously designed as specific BCRN modules based on their dynamics. This approach addresses a design gap in the biochemical assignment module and judgment termination module and provides a novel precise and robust realization of bi-molecular reactions for the learning process. Through equilibrium approaching, we demonstrate that the designed BCRN system achieves FCNN functionality with exponential convergence to target computational results, thereby enhancing the theoretical support for such work. Finally, the performance of this construction is further evaluated on two typical logic classification problems.