 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Parameter Optimization for Loop Closure Detection in Closed Environments
Nov 12, 2020
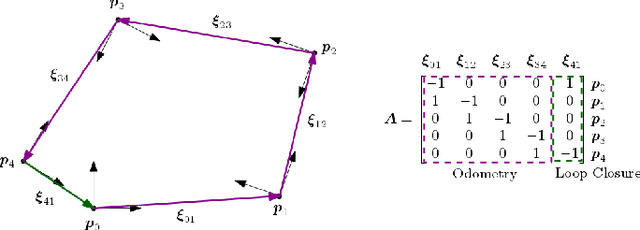
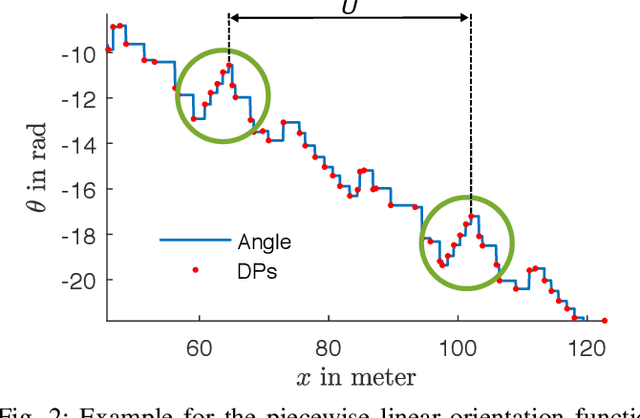
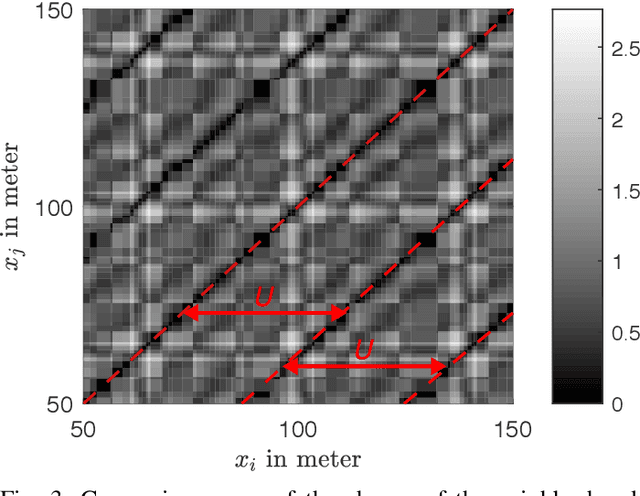
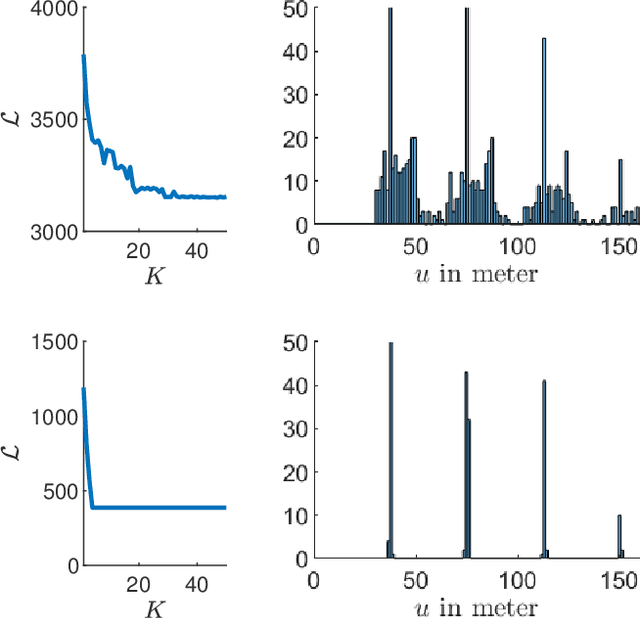
Tuning parameters is crucial for the performance of localization and mapping algorithms. In general, the tuning of the parameters requires expert knowledge and is sensitive to information about the structure of the environment. In order to design truly autonomous systems the robot has to learn the parameters automatically. Therefore, we propose a parameter optimization approach for loop closure detection in closed environments which requires neither any prior information, e.g. robot model parameters, nor expert knowledge. It relies on several path traversals along the boundary line of the closed environment. We demonstrate the performance of our method in challenging real world scenarios with limited sensing capabilities. These scenarios are exemplary for a wide range of practical applications including lawn mowers and household robots.
Learned Camera Gain and Exposure Control for Improved Visual Feature Detection and Matching
Feb 28, 2021


Successful visual navigation depends upon capturing images that contain sufficient useful information. In this paper, we explore a data-driven approach to account for environmental lighting changes, improving the quality of images for use in visual odometry (VO) or visual simultaneous localization and mapping (SLAM). We train a deep convolutional neural network model to predictively adjust camera gain and exposure time parameters such that consecutive images contain a maximal number of matchable features. The training process is fully self-supervised: our training signal is derived from an underlying VO or SLAM pipeline and, as a result, the model is optimized to perform well with that specific pipeline. We demonstrate through extensive real-world experiments that our network can anticipate and compensate for dramatic lighting changes (e.g., transitions into and out of road tunnels), maintaining a substantially higher number of inlier feature matches than competing camera parameter control algorithms.
What is a meaningful representation of protein sequences?
Nov 28, 2020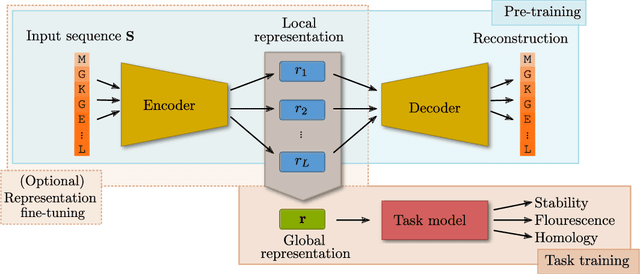
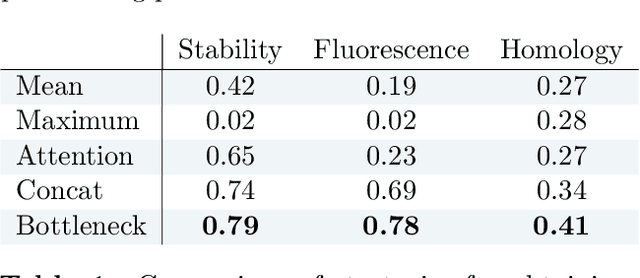
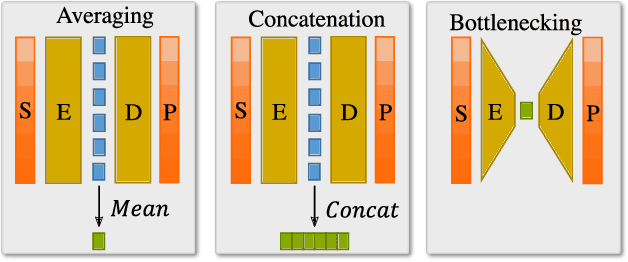
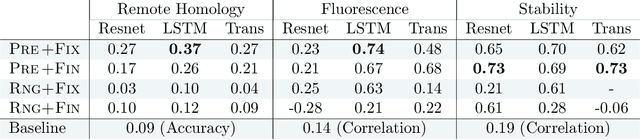
How we choose to represent our data has a fundamental impact on our ability to subsequently extract information from them. Machine learning promises to automatically determine efficient representations from large unstructured datasets, such as those arising in biology. However, empirical evidence suggests that seemingly minor changes to these machine learning models yield drastically different data representations that result in different biological interpretations of data. This begs the question of what even constitutes the most meaningful representation. Here, we approach this question for representations of protein sequences, which have received considerable attention in the recent literature. We explore two key contexts in which representations naturally arise: transfer learning and interpretable learning. In the first context, we demonstrate that several contemporary practices yield suboptimal performance, and in the latter we demonstrate that taking representation geometry into account significantly improves interpretability and lets the models reveal biological information that is otherwise obscured.
SimPLE: Similar Pseudo Label Exploitation for Semi-Supervised Classification
Mar 30, 2021
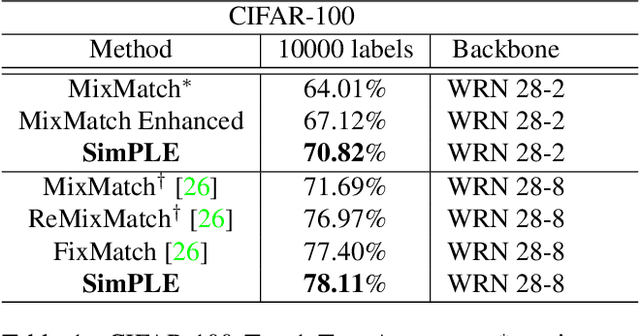
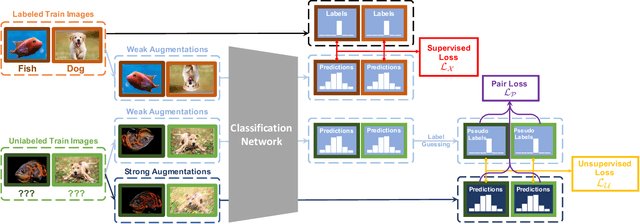
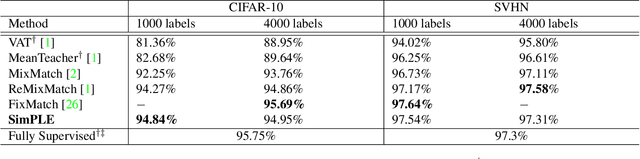
A common classification task situation is where one has a large amount of data available for training, but only a small portion is annotated with class labels. The goal of semi-supervised training, in this context, is to improve classification accuracy by leverage information not only from labeled data but also from a large amount of unlabeled data. Recent works have developed significant improvements by exploring the consistency constrain between differently augmented labeled and unlabeled data. Following this path, we propose a novel unsupervised objective that focuses on the less studied relationship between the high confidence unlabeled data that are similar to each other. The new proposed Pair Loss minimizes the statistical distance between high confidence pseudo labels with similarity above a certain threshold. Combining the Pair Loss with the techniques developed by the MixMatch family, our proposed SimPLE algorithm shows significant performance gains over previous algorithms on CIFAR-100 and Mini-ImageNet, and is on par with the state-of-the-art methods on CIFAR-10 and SVHN. Furthermore, SimPLE also outperforms the state-of-the-art methods in the transfer learning setting, where models are initialized by the weights pre-trained on ImageNet or DomainNet-Real. The code is available at github.com/zijian-hu/SimPLE.
Joint Channel Estimation and Synchronization Techniques for Time Interleaved Block Windowed Burst OFDM
Mar 30, 2021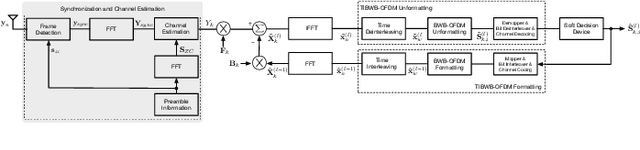
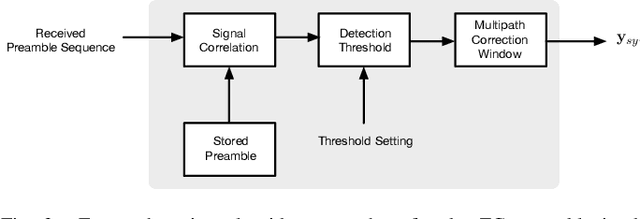
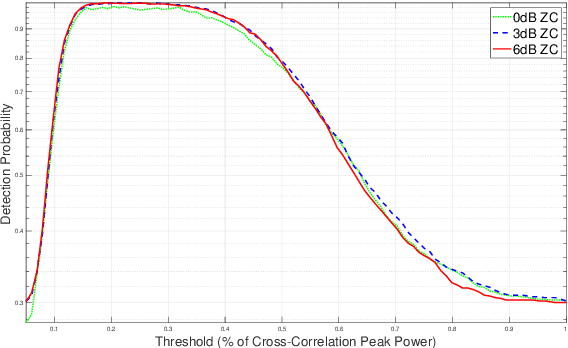
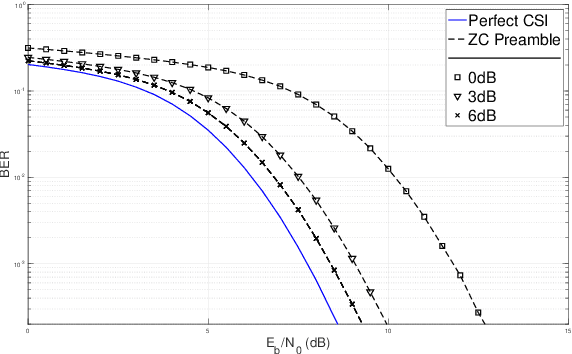
From a conceptual perspective, 5G technology promises to deliver low latency, high data rate and more reliable connections for the next generations of communication systems. To face these demands, modulation schemes based on Orthogonal Frequency Domain Multiplexing (OFDM) can accommodate these requirements for wireless systems. On the other hand, several hybrid OFDM-based systems such as the Time-Interleaved Block Windowed Burst Orthogonal Frequency Division Multiplexing (TIBWB-OFDM) are capable of achieving even better spectral confinement and power efficiency. This paper addresses to the implementation of the TIBWB-OFDM system in a more realistic and practical wireless link scenarios by addressing the challenges of proper and reliable channel estimation and frame synchronization. We propose to incorporate a preamble formed by optimum correlation training sequences, such as the Zadoff-Chu (ZC) sequences. The added ZC preamble sequence is used to jointly estimate the frame beginning, through signal correlation strategies and a threshold decision device, and acquire the channel state information (CSI), by employing estimators based on the preamble sequence and the transmitted data. The employed receiver estimators show that it is possible to detect the TIBWB-OFDM frame beginning and provide a close BER performance comparatively to the one where the perfect channel is known.
A clinical validation of VinDr-CXR, an AI system for detecting abnormal chest radiographs
Apr 07, 2021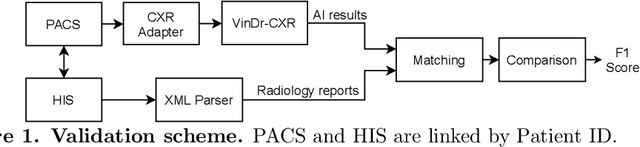

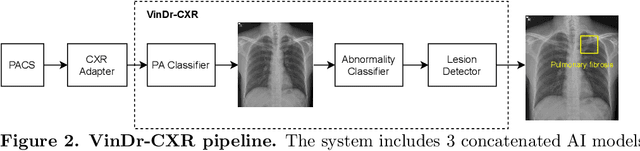

Computer-Aided Diagnosis (CAD) systems for chest radiographs using artificial intelligence (AI) have recently shown a great potential as a second opinion for radiologists. The performances of such systems, however, were mostly evaluated on a fixed dataset in a retrospective manner and, thus, far from the real performances in clinical practice. In this work, we demonstrate a mechanism for validating an AI-based system for detecting abnormalities on X-ray scans, VinDr-CXR, at the Phu Tho General Hospital - a provincial hospital in the North of Vietnam. The AI system was directly integrated into the Picture Archiving and Communication System (PACS) of the hospital after being trained on a fixed annotated dataset from other sources. The performance of the system was prospectively measured by matching and comparing the AI results with the radiology reports of 6,285 chest X-ray examinations extracted from the Hospital Information System (HIS) over the last two months of 2020. The normal/abnormal status of a radiology report was determined by a set of rules and served as the ground truth. Our system achieves an F1 score - the harmonic average of the recall and the precision - of 0.653 (95% CI 0.635, 0.671) for detecting any abnormalities on chest X-rays. Despite a significant drop from the in-lab performance, this result establishes a high level of confidence in applying such a system in real-life situations.
Bayesian Distributional Policy Gradients
Mar 23, 2021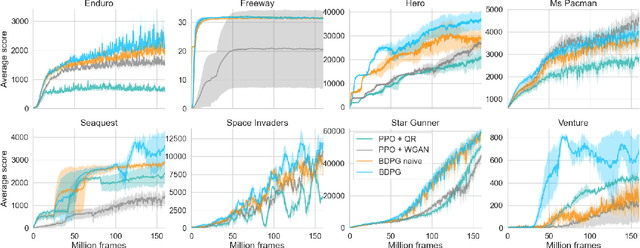
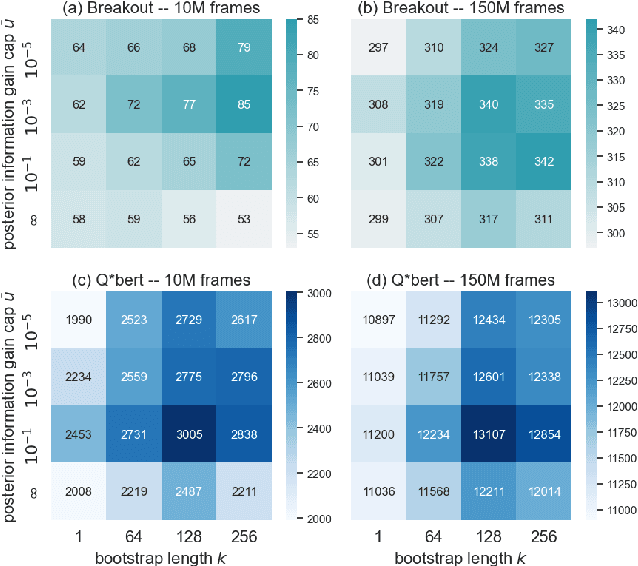
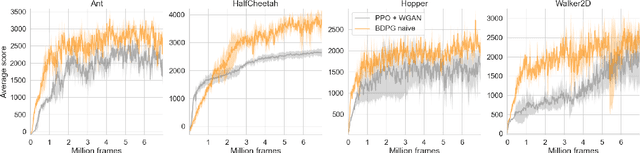
Distributional Reinforcement Learning (RL) maintains the entire probability distribution of the reward-to-go, i.e. the return, providing more learning signals that account for the uncertainty associated with policy performance, which may be beneficial for trading off exploration and exploitation and policy learning in general. Previous works in distributional RL focused mainly on computing the state-action-return distributions, here we model the state-return distributions. This enables us to translate successful conventional RL algorithms that are based on state values into distributional RL. We formulate the distributional Bellman operation as an inference-based auto-encoding process that minimises Wasserstein metrics between target/model return distributions. The proposed algorithm, BDPG (Bayesian Distributional Policy Gradients), uses adversarial training in joint-contrastive learning to estimate a variational posterior from the returns. Moreover, we can now interpret the return prediction uncertainty as an information gain, which allows to obtain a new curiosity measure that helps BDPG steer exploration actively and efficiently. We demonstrate in a suite of Atari 2600 games and MuJoCo tasks, including well known hard-exploration challenges, how BDPG learns generally faster and with higher asymptotic performance than reference distributional RL algorithms.
GRN: Generative Rerank Network for Context-wise Recommendation
Apr 07, 2021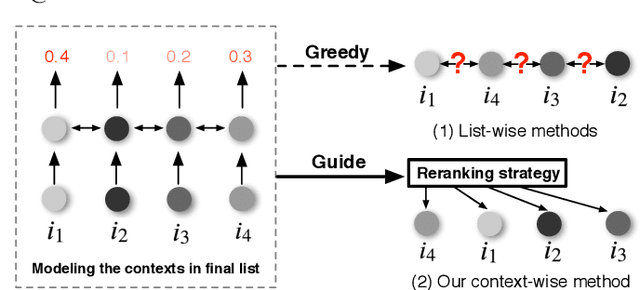
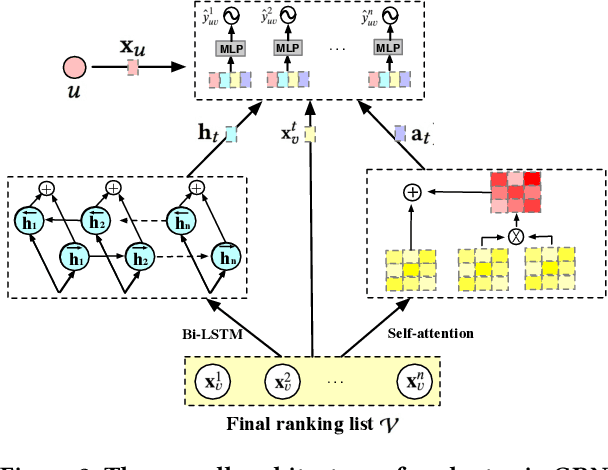
Reranking is attracting incremental attention in the recommender systems, which rearranges the input ranking list into the final rank-ing list to better meet user demands. Most existing methods greedily rerank candidates through the rating scores from point-wise or list-wise models. Despite effectiveness, neglecting the mutual influence between each item and its contexts in the final ranking list often makes the greedy strategy based reranking methods sub-optimal. In this work, we propose a new context-wise reranking framework named Generative Rerank Network (GRN). Specifically, we first design the evaluator, which applies Bi-LSTM and self-attention mechanism to model the contextual information in the labeled final ranking list and predict the interaction probability of each item more precisely. Afterwards, we elaborate on the generator, equipped with GRU, attention mechanism and pointer network to select the item from the input ranking list step by step. Finally, we apply cross-entropy loss to train the evaluator and, subsequently, policy gradient to optimize the generator under the guidance of the evaluator. Empirical results show that GRN consistently and significantly outperforms state-of-the-art point-wise and list-wise methods. Moreover, GRN has achieved a performance improvement of 5.2% on PV and 6.1% on IPV metric after the successful deployment in one popular recommendation scenario of Taobao application.
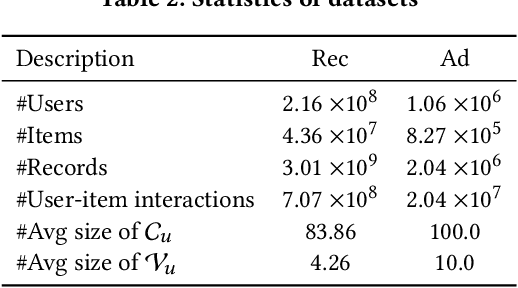
Exploring the social influence of Kaggle virtual community on the M5 competition
Feb 28, 2021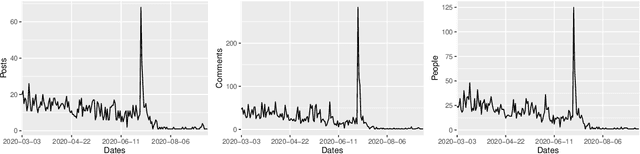
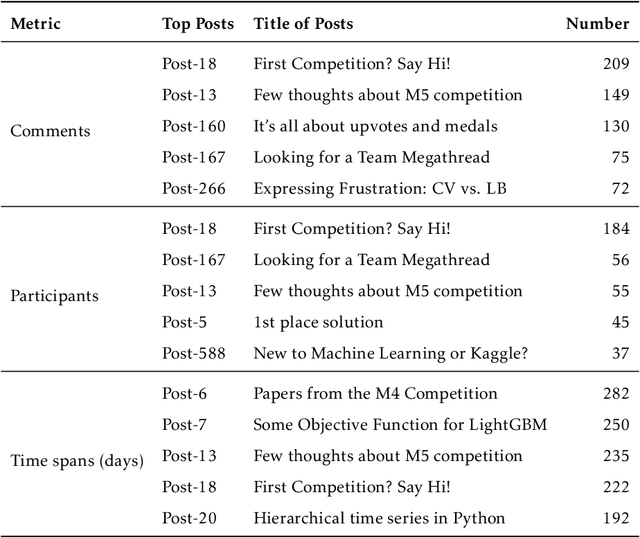
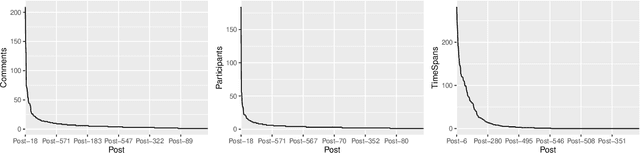

One of the most significant differences of M5 over previous forecasting competitions is that it was held on Kaggle, an online community of data scientists and machine learning practitioners. On the Kaggle platform, people can form virtual communities such as online notebooks and discussions to discuss their models, choice of features, loss functions, etc. This paper aims to study the social influence of virtual communities on the competition. We first study the content of the M5 virtual community by topic modeling and trend analysis. Further, we perform social media analysis to identify the potential relationship network of the virtual community. We find some key roles in the network and study their roles in spreading the LightGBM related information within the network. Overall, this study provides in-depth insights into the dynamic mechanism of the virtual community influence on the participants and has potential implications for future online competitions.
Interpreting intermediate convolutional layers of CNNs trained on raw speech
Apr 19, 2021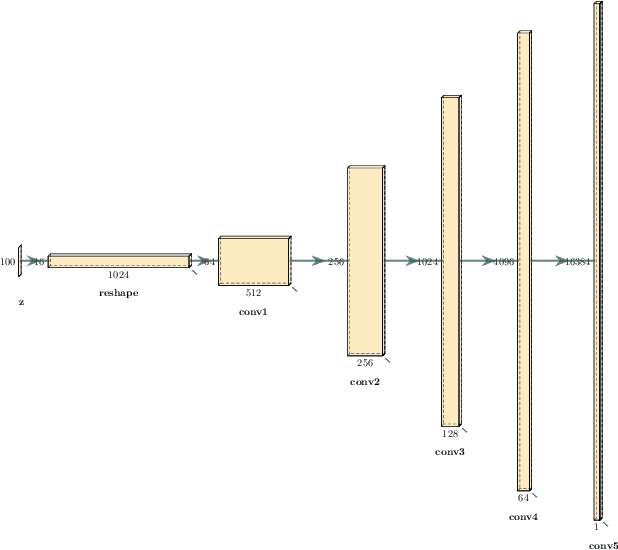
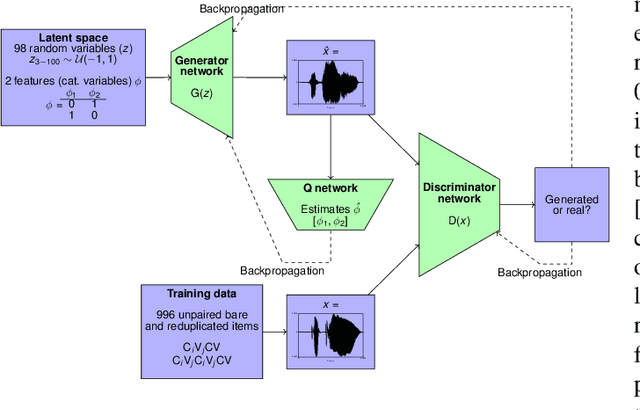
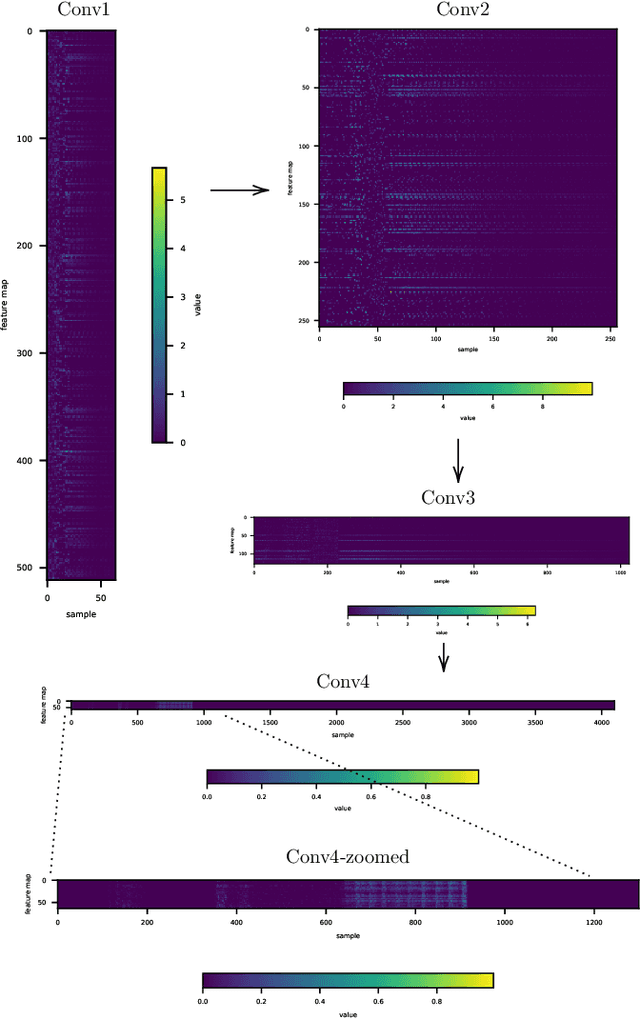
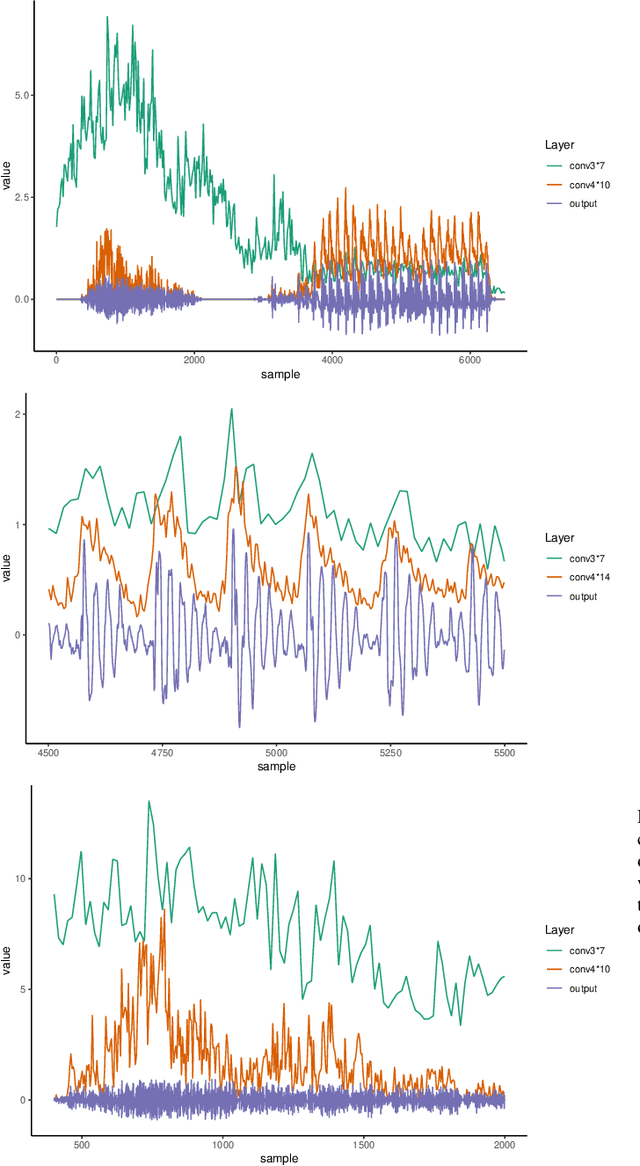
This paper presents a technique to interpret and visualize intermediate layers in CNNs trained on raw speech data in an unsupervised manner. We show that averaging over feature maps after ReLU activation in each convolutional layer yields interpretable time-series data. The proposed technique enables acoustic analysis of intermediate convolutional layers. To uncover how meaningful representation in speech gets encoded in intermediate layers of CNNs, we manipulate individual latent variables to marginal levels outside of the training range. We train and probe internal representations on two models -- a bare GAN architecture and a ciwGAN extension which forces the Generator to output informative data and results in emergence of linguistically meaningful representations. Interpretation and visualization is performed for three basic acoustic properties of speech: periodic vibration (corresponding to vowels), aperiodic noise vibration (corresponding to fricatives), and silence (corresponding to stops). We also argue that the proposed technique allows acoustic analysis of intermediate layers that parallels the acoustic analysis of human speech data: we can extract F0, intensity, duration, formants, and other acoustic properties from intermediate layers in order to test where and how CNNs encode various types of information. The models are trained on two speech processes with different degrees of complexity: a simple presence of [s] and a computationally complex presence of reduplication (copied material). Observing the causal effect between interpolation and the resulting changes in intermediate layers can reveal how individual variables get transformed into spikes in activation in intermediate layers. Using the proposed technique, we can analyze how linguistically meaningful units in speech get encoded in different convolutional layers.