 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Delay-Tolerant Consensus-based Distributed Estimation: Full-Rank Systems with Potentially Unstable Dynamics
Apr 01, 2021


Classical distributed estimation scenarios typically assume timely and reliable exchange of information over the multi-agent network. This paper, in contrast, considers single time-scale distributed estimation of (potentially) unstable full-rank dynamical systems via a multi-agent network subject to transmission time-delays. The proposed networked estimator consists of two steps: (i) consensus on (delayed) a-priori estimates, and (ii) measurement update. The agents only share their a-priori estimates with their in-neighbors over time-delayed transmission links. Considering the most general case, the delays are assumed to be time-varying, arbitrary, unknown, but upper-bounded. In contrast to most recent distributed observers assuming system observability in the neighborhood of each agent, our proposed estimator makes no such assumption. This may significantly reduce the communication/sensing loads on agents in large-scale, while making the (distributed) observability analysis more challenging. Using the notions of augmented matrices and Kronecker product, the geometric convergence of the proposed estimator over strongly-connected networks is proved irrespective of the bound on the time-delay. Simulations are provided to support our theoretical results.
Covariance Estimation from Compressive Data Partitions using a Projected Gradient-based Algorithm
Jan 11, 2021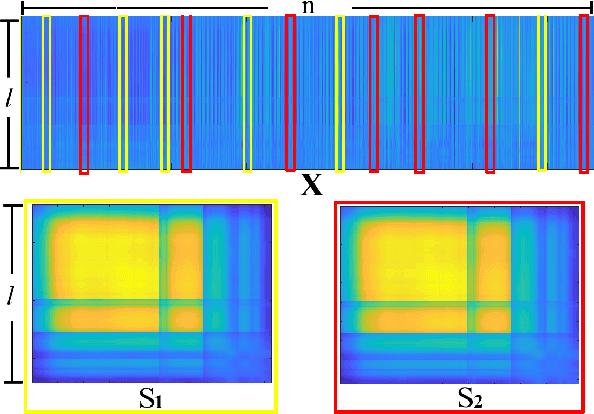
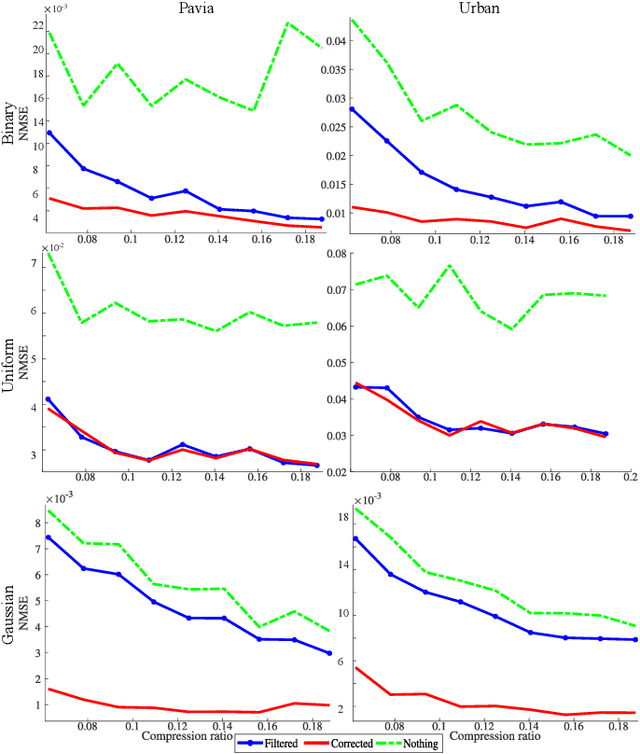
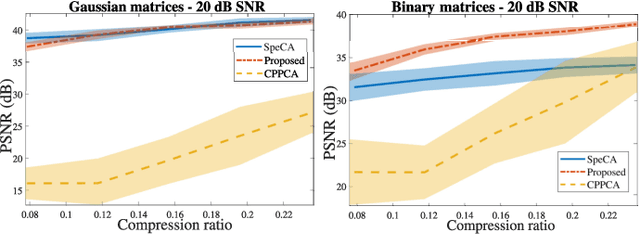
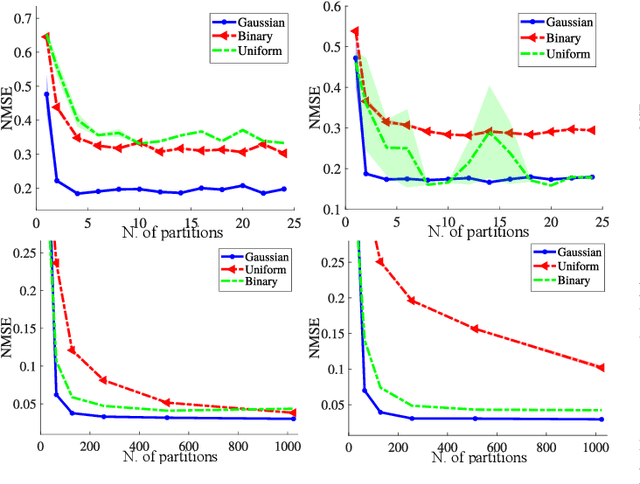
Covariance matrix estimation techniques require high acquisition costs that challenge the sampling systems' storing and transmission capabilities. For this reason, various acquisition approaches have been developed to simultaneously sense and compress the relevant information of the signal using random projections. However, estimating the covariance matrix from the random projections is an ill-posed problem that requires further information about the data, such as sparsity, low rank, or stationary behavior. Furthermore, this approach fails using high compression ratios. Therefore, this paper proposes an algorithm based on the projected gradient method to recover a low-rank or Toeplitz approximation of the covariance matrix. The proposed algorithm divides the data into subsets projected onto different subspaces, assuming that each subset contains an approximation of the signal statistics, improving the inverse problem's condition. The error induced by this assumption is analytically derived along with the convergence guarantees of the proposed method. Extensive simulations show that the proposed algorithm can effectively recover the covariance matrix of hyperspectral images with high compression ratios (8-15% approx) in noisy scenarios. Additionally, simulations and theoretical results show that filtering the gradient reduces the estimator's error recovering up to twice the number of eigenvectors.
Modeling the Severity of Complaints in Social Media
Mar 23, 2021
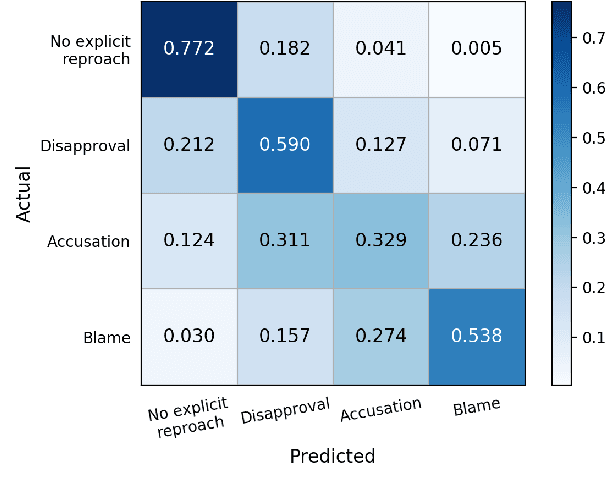
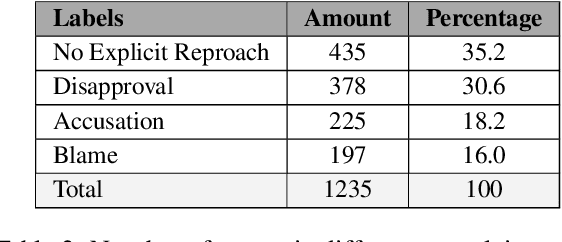
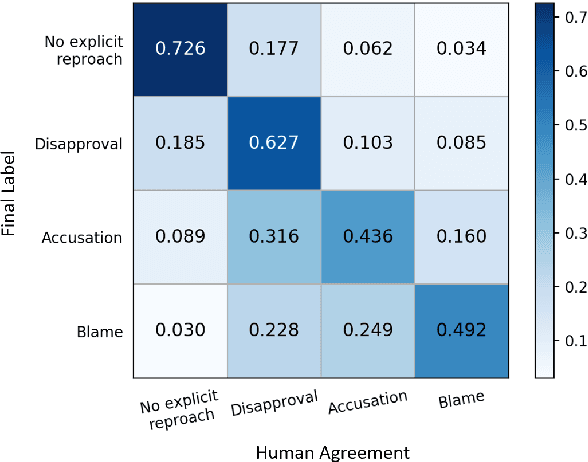
The speech act of complaining is used by humans to communicate a negative mismatch between reality and expectations as a reaction to an unfavorable situation. Linguistic theory of pragmatics categorizes complaints into various severity levels based on the face-threat that the complainer is willing to undertake. This is particularly useful for understanding the intent of complainers and how humans develop suitable apology strategies. In this paper, we study the severity level of complaints for the first time in computational linguistics. To facilitate this, we enrich a publicly available data set of complaints with four severity categories and train different transformer-based networks combined with linguistic information achieving 55.7 macro F1. We also jointly model binary complaint classification and complaint severity in a multi-task setting achieving new state-of-the-art results on binary complaint detection reaching up to 88.2 macro F1. Finally, we present a qualitative analysis of the behavior of our models in predicting complaint severity levels.
Modelling Temporal Information Using Discrete Fourier Transform for Video Classification
Aug 17, 2016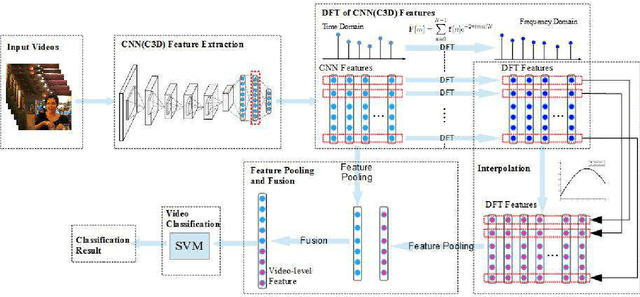
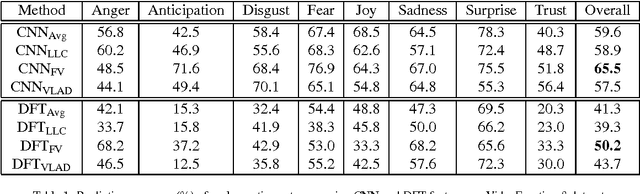
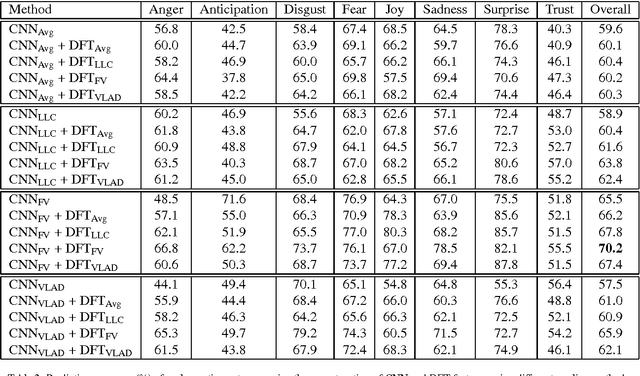
Recently, video classification attracts intensive research efforts. However, most existing works are based on framelevel visual features, which might fail to model the temporal information, e.g. characteristics accumulated along time. In order to capture video temporal information, we propose to analyse features in frequency domain transformed by discrete Fourier transform (DFT features). Frame-level features are firstly extract by a pre-trained deep convolutional neural network (CNN). Then, time domain features are transformed and interpolated into DFT features. CNN and DFT features are further encoded by using different pooling methods and fused for video classification. In this way, static image features extracted from a pre-trained deep CNN and temporal information represented by DFT features are jointly considered for video classification. We test our method for video emotion classification and action recognition. Experimental results demonstrate that combining DFT features can effectively capture temporal information and therefore improve the performance of both video emotion classification and action recognition. Our approach has achieved a state-of-the-art performance on the largest video emotion dataset (VideoEmotion-8 dataset) and competitive results on UCF-101.
On the Convergence Time of Federated Learning Over Wireless Networks Under Imperfect CSI
Apr 01, 2021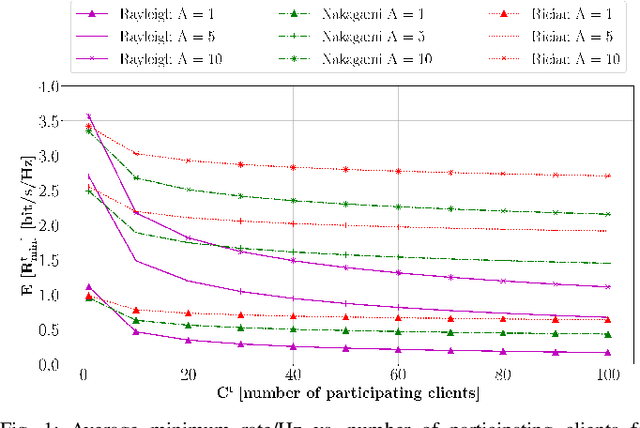
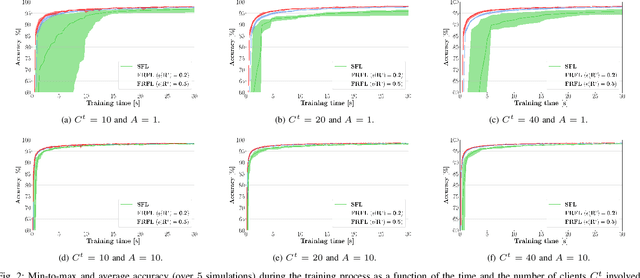
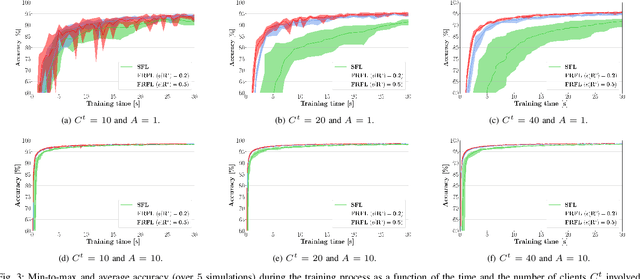
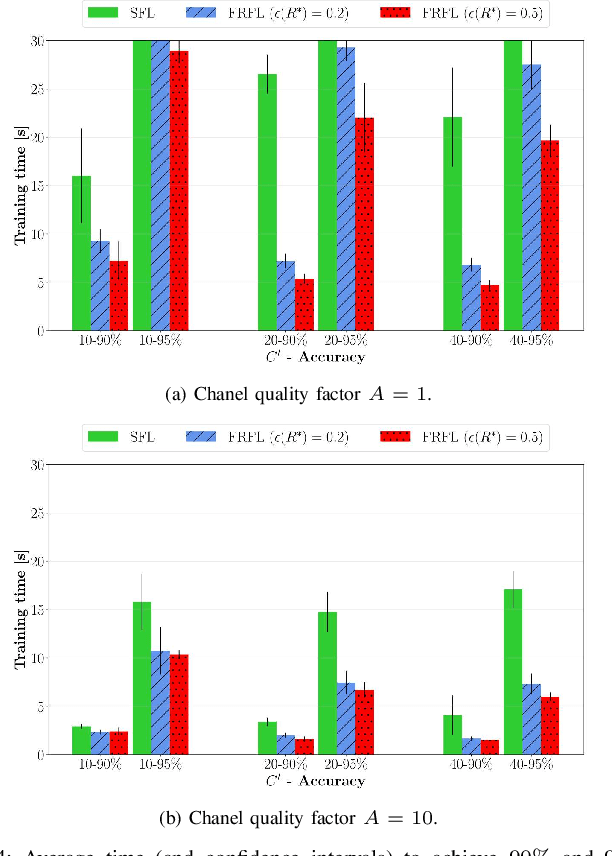
Federated learning (FL) has recently emerged as an attractive decentralized solution for wireless networks to collaboratively train a shared model while keeping data localized. As a general approach, existing FL methods tend to assume perfect knowledge of the Channel State Information (CSI) during the training phase, which may not be easy to acquire in case of fast fading channels. Moreover, literature analyses either consider a fixed number of clients participating in the training of the federated model, or simply assume that all clients operate at the maximum achievable rate to transmit model data. In this paper, we fill these gaps by proposing a training process that takes channel statistics as a bias to minimize the convergence time under imperfect CSI. Numerical experiments demonstrate that it is possible to reduce the training time by neglecting model updates from clients that cannot sustain a minimum predefined transmission rate. We also examine the trade-off between number of clients involved in the training process and model accuracy as a function of different fading regimes.
A Graph VAE and Graph Transformer Approach to Generating Molecular Graphs
Apr 09, 2021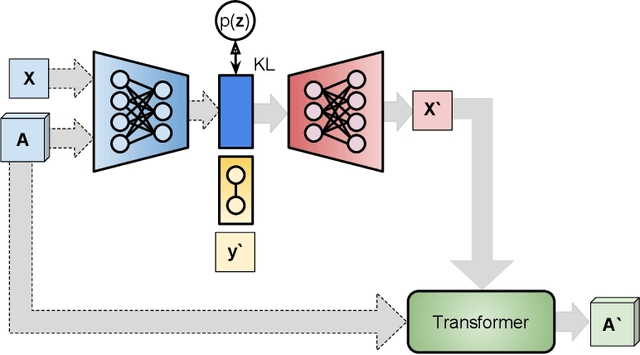
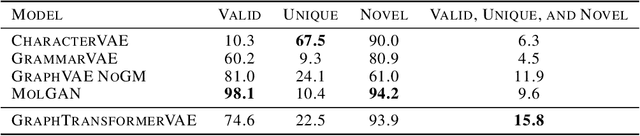
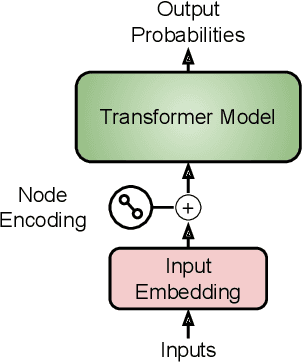

We propose a combination of a variational autoencoder and a transformer based model which fully utilises graph convolutional and graph pooling layers to operate directly on graphs. The transformer model implements a novel node encoding layer, replacing the position encoding typically used in transformers, to create a transformer with no position information that operates on graphs, encoding adjacent node properties into the edge generation process. The proposed model builds on graph generative work operating on graphs with edge features, creating a model that offers improved scalability with the number of nodes in a graph. In addition, our model is capable of learning a disentangled, interpretable latent space that represents graph properties through a mapping between latent variables and graph properties. In experiments we chose a benchmark task of molecular generation, given the importance of both generated node and edge features. Using the QM9 dataset we demonstrate that our model performs strongly across the task of generating valid, unique and novel molecules. Finally, we demonstrate that the model is interpretable by generating molecules controlled by molecular properties, and we then analyse and visualise the learned latent representation.
OmniPose: A Multi-Scale Framework for Multi-Person Pose Estimation
Mar 18, 2021
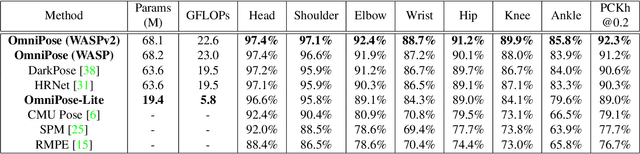

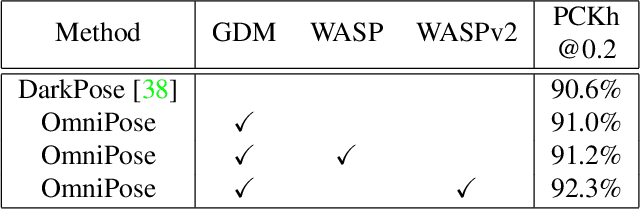
We propose OmniPose, a single-pass, end-to-end trainable framework, that achieves state-of-the-art results for multi-person pose estimation. Using a novel waterfall module, the OmniPose architecture leverages multi-scale feature representations that increase the effectiveness of backbone feature extractors, without the need for post-processing. OmniPose incorporates contextual information across scales and joint localization with Gaussian heatmap modulation at the multi-scale feature extractor to estimate human pose with state-of-the-art accuracy. The multi-scale representations, obtained by the improved waterfall module in OmniPose, leverage the efficiency of progressive filtering in the cascade architecture, while maintaining multi-scale fields-of-view comparable to spatial pyramid configurations. Our results on multiple datasets demonstrate that OmniPose, with an improved HRNet backbone and waterfall module, is a robust and efficient architecture for multi-person pose estimation that achieves state-of-the-art results.
Semantic SLAM with Autonomous Object-Level Data Association
Nov 20, 2020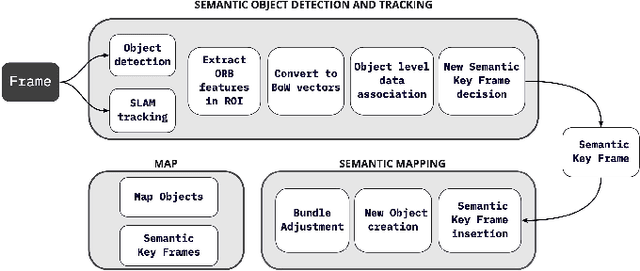



It is often desirable to capture and map semantic information of an environment during simultaneous localization and mapping (SLAM). Such semantic information can enable a robot to better distinguish places with similar low-level geometric and visual features and perform high-level tasks that use semantic information about objects to be manipulated and environments to be navigated. While semantic SLAM has gained increasing attention, there is little research on semanticlevel data association based on semantic objects, i.e., object-level data association. In this paper, we propose a novel object-level data association algorithm based on bag of words algorithm, formulated as a maximum weighted bipartite matching problem. With object-level data association solved, we develop a quadratic-programming-based semantic object initialization scheme using dual quadric and introduce additional constraints to improve the success rate of object initialization. The integrated semantic-level SLAM system can achieve high-accuracy object-level data association and real-time semantic mapping as demonstrated in the experiments. The online semantic map building and semantic-level localization capabilities facilitate semantic-level mapping and task planning in a priori unknown environment.
NDT-Transformer: Large-Scale 3D Point Cloud Localisation using the Normal Distribution Transform Representation
Mar 23, 2021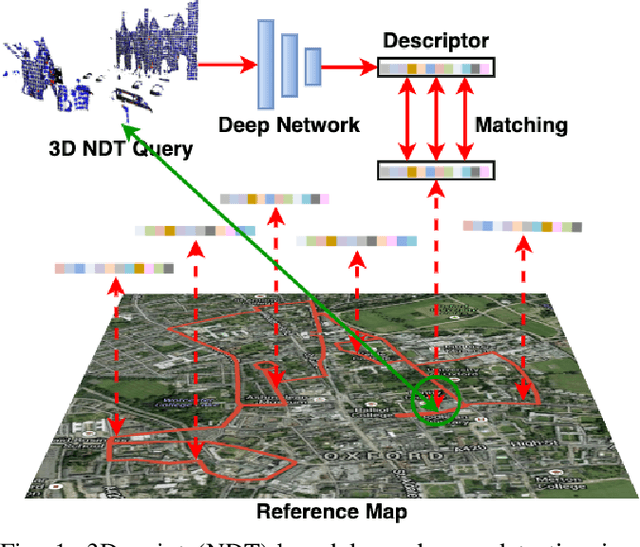

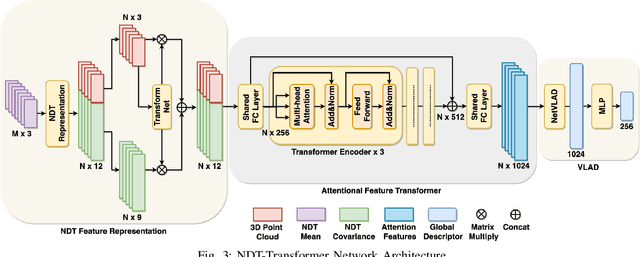
3D point cloud-based place recognition is highly demanded by autonomous driving in GPS-challenged environments and serves as an essential component (i.e. loop-closure detection) in lidar-based SLAM systems. This paper proposes a novel approach, named NDT-Transformer, for realtime and large-scale place recognition using 3D point clouds. Specifically, a 3D Normal Distribution Transform (NDT) representation is employed to condense the raw, dense 3D point cloud as probabilistic distributions (NDT cells) to provide the geometrical shape description. Then a novel NDT-Transformer network learns a global descriptor from a set of 3D NDT cell representations. Benefiting from the NDT representation and NDT-Transformer network, the learned global descriptors are enriched with both geometrical and contextual information. Finally, descriptor retrieval is achieved using a query-database for place recognition. Compared to the state-of-the-art methods, the proposed approach achieves an improvement of 7.52% on average top 1 recall and 2.73% on average top 1% recall on the Oxford Robotcar benchmark.
Local word statistics affect reading times independently of surprisal
Mar 07, 2021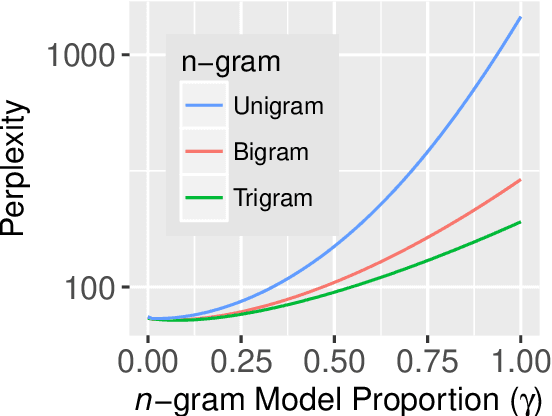
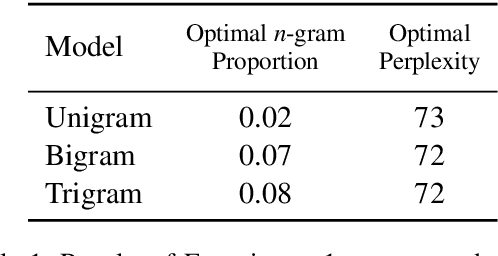

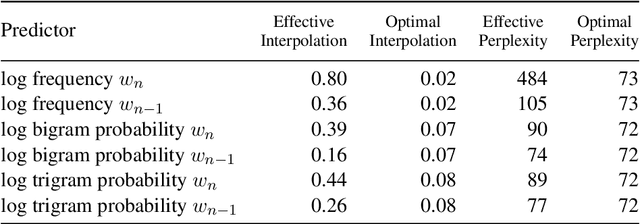
Surprisal theory has provided a unifying framework for understanding many phenomena in sentence processing (Hale, 2001; Levy, 2008a), positing that a word's conditional probability given all prior context fully determines processing difficulty. Problematically for this claim, one local statistic, word frequency, has also been shown to affect processing, even when conditional probability given context is held constant. Here, we ask whether other local statistics have a role in processing, or whether word frequency is a special case. We present the first clear evidence that more complex local statistics, word bigram and trigram probability, also affect processing independently of surprisal. These findings suggest a significant and independent role of local statistics in processing. Further, it motivates research into new generalizations of surprisal that can also explain why local statistical information should have an outsized effect.