 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Information Extraction with Character-level Neural Networks and Free Noisy Supervision
Jan 24, 2017

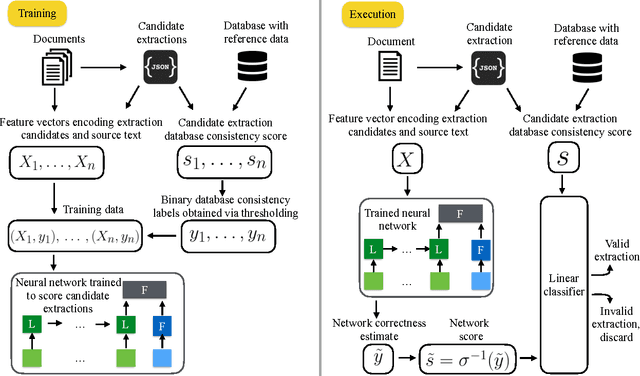
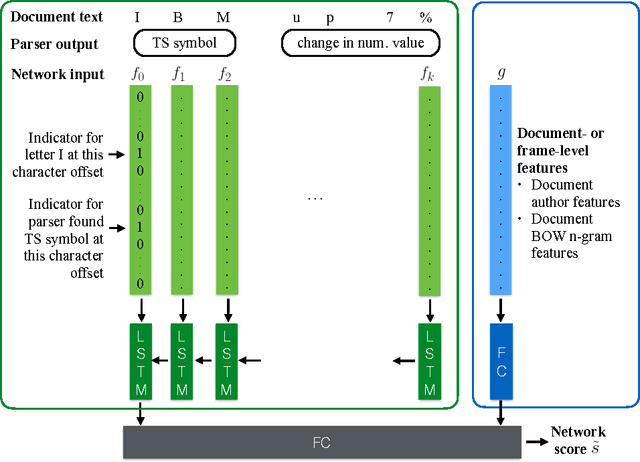
We present an architecture for information extraction from text that augments an existing parser with a character-level neural network. The network is trained using a measure of consistency of extracted data with existing databases as a form of noisy supervision. Our architecture combines the ability of constraint-based information extraction systems to easily incorporate domain knowledge and constraints with the ability of deep neural networks to leverage large amounts of data to learn complex features. Boosting the existing parser's precision, the system led to large improvements over a mature and highly tuned constraint-based production information extraction system used at Bloomberg for financial language text.
A Low Cost Modular Radio Tomography System for Bicycle and Vehicle Detection and Classification
Feb 11, 2021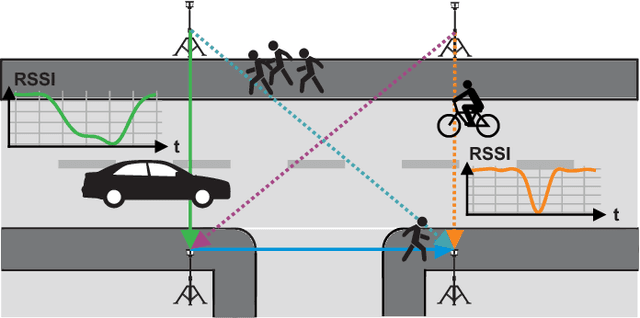
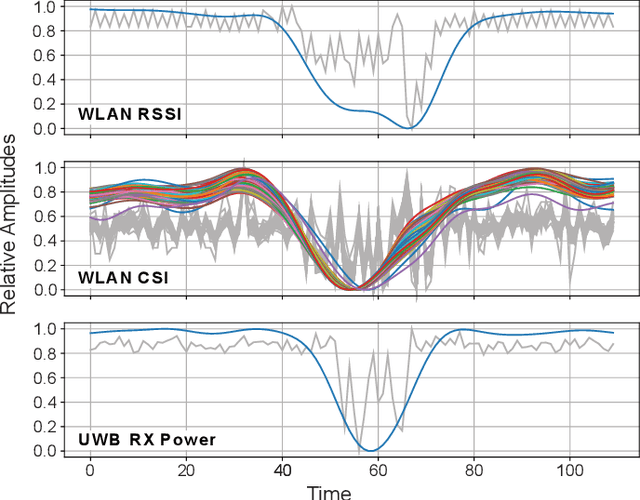
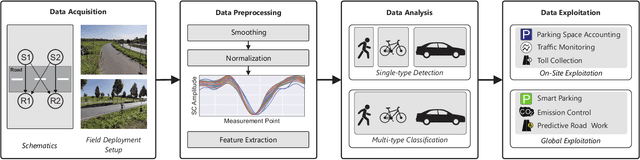

The advancing deployment of ubiquitous Internet of Things (IoT)-powered vehicle detection and classification systems will successively turn the existing road infrastructure into a highly dynamical and interconnected Cyber-physical System (CPS). Though many different sensor systems have been proposed in recent years, these solutions can only meet a subset of requirements, including cost-efficiency, robustness, accuracy, and privacy preservation. This paper provides a modular system approach that exploits radio tomography in terms of attenuation patterns and highly accurate channel information for reliable and robust detection and classification of different road users. Hereto, we use Wireless Local Area Network (WLAN) and Ultra-Wideband (UWB) transceiver modules providing either Channel State Information (CSI) or Channel Impulse Response (CIR) data. Since the proposed system utilizes off-the-shelf and power-efficient embedded systems, it allows for a cost-efficient ad-hoc deployment in existing road infrastructures. We have evaluated the proposed system's performance for cyclists and other motorized vehicles with an experimental live deployment. In this concern, the primary focus has been on the accurate detection of cyclists on a bicycle path. However, we also have conducted preliminary evaluation tests measuring different motorized vehicles using a similar system configuration as for the cyclists. In summary, the system achieves up to 100% accuracy for detecting cyclists and more than 98% classifying cyclists and cars.
The $r$-value: evaluating stability with respect to distributional shifts
May 07, 2021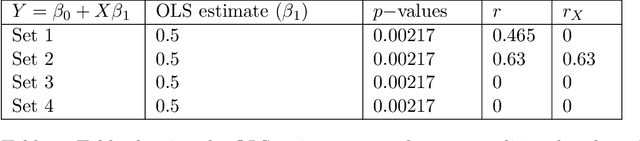
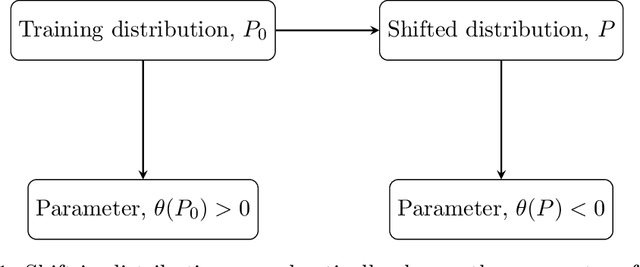

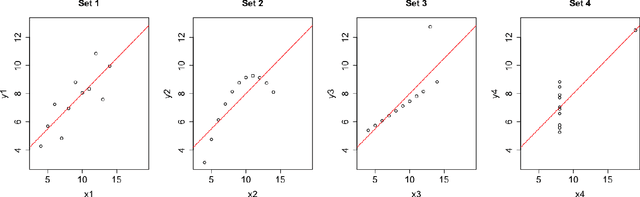
Common statistical measures of uncertainty like $p$-values and confidence intervals quantify the uncertainty due to sampling, that is, the uncertainty due to not observing the full population. In practice, populations change between locations and across time. This makes it difficult to gather knowledge that transfers across data sets. We propose a measure of uncertainty that quantifies the distributional uncertainty of a statistical estimand with respect to Kullback-Liebler divergence, that is, the sensitivity of the parameter under general distributional perturbations within a Kullback-Liebler divergence ball. If the signal-to-noise ratio is small, distributional uncertainty is a monotonous transformation of the signal-to-noise ratio. In general, however, it is a different concept and corresponds to a different research question. Further, we propose measures to estimate the stability of parameters with respect to directional or variable-specific shifts. We also demonstrate how the measure of distributional uncertainty can be used to prioritize data collection for better estimation of statistical parameters under shifted distribution. We evaluate the performance of the proposed measure in simulations and real data and show that it can elucidate the distributional (in-)stability of an estimator with respect to certain shifts and give more accurate estimates of parameters under shifted distribution only requiring to collect limited information from the shifted distribution.
It's all in the (Sub-)title? Expanding Signal Evaluation in Crowdfunding Research
Oct 27, 2020
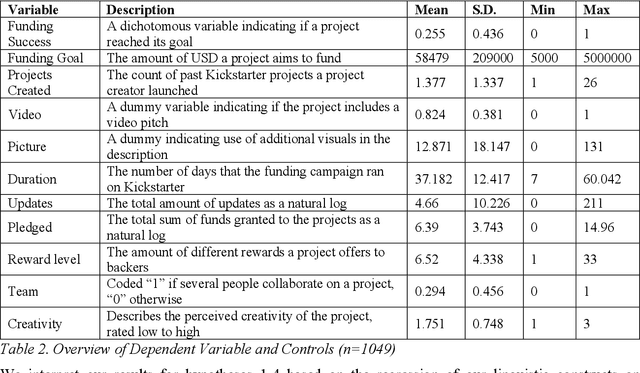
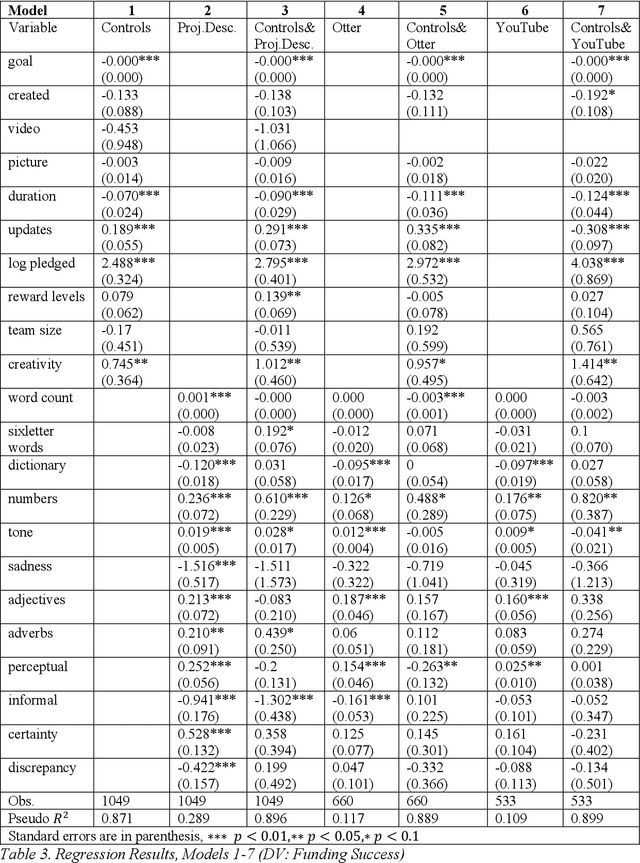
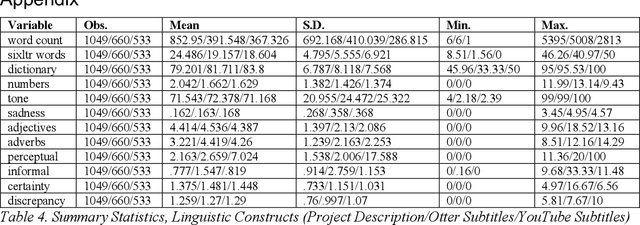
Research on crowdfunding success that incorporates CATA (computer-aided text analysis) is quickly advancing to the big leagues (e.g., Parhankangas and Renko, 2017; Anglin et al., 2018; Moss et al., 2018) and is often theoretically based on information asymmetry, social capital, signaling or a combination thereof. Yet, current papers that explore crowdfunding success criteria fail to take advantage of the full breadth of signals available and only very few such papers examine technology projects. In this paper, we compare and contrast the strength of the entrepreneur's textual success signals to project backers within this category. Based on a random sample of 1,049 technology projects collected from Kickstarter, we evaluate textual information not only from project titles and descriptions but also from video subtitles. We find that incorporating subtitle information increases the variance explained by the respective models and therefore their predictive capability for funding success. By expanding the information landscape, our work advances the field and paves the way for more fine-grained studies of success signals in crowdfunding and therefore for an improved understanding of investor decision-making in the crowd.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 01, 2021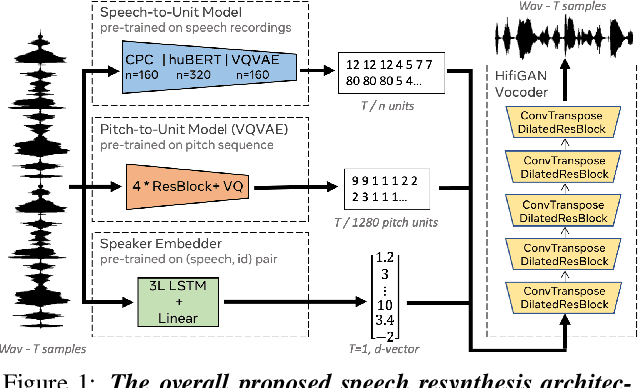
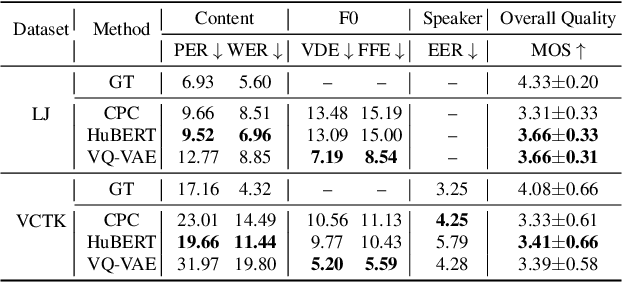
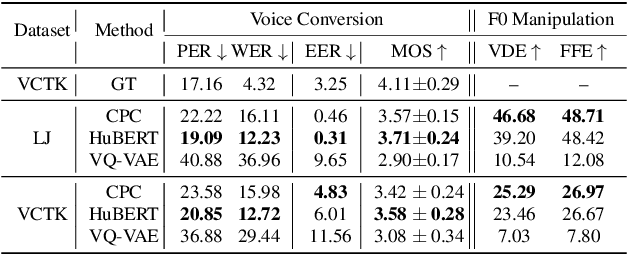
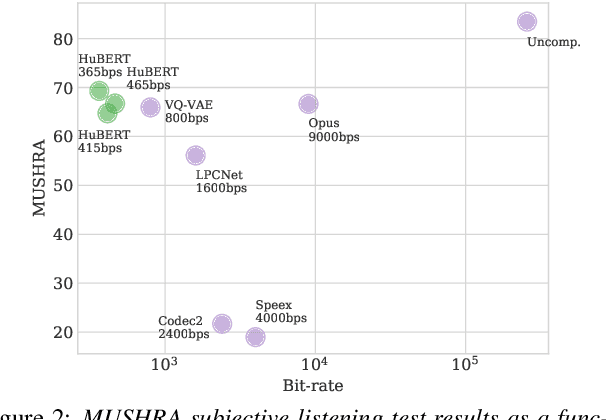
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under the following link: \url{https://resynthesis-ssl.github.io/}.
PEMNET: A Transfer Learning-based Modeling Approach of High-Temperature Polymer Electrolyte Membrane Electrochemical Systems
May 07, 2021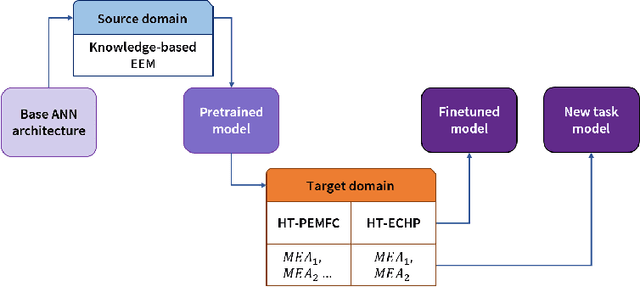
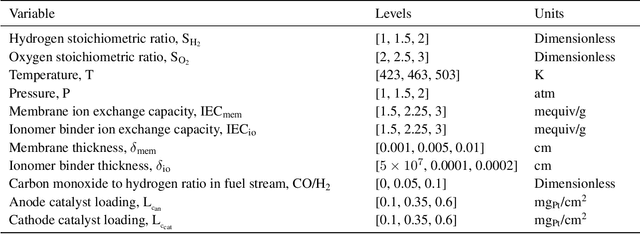
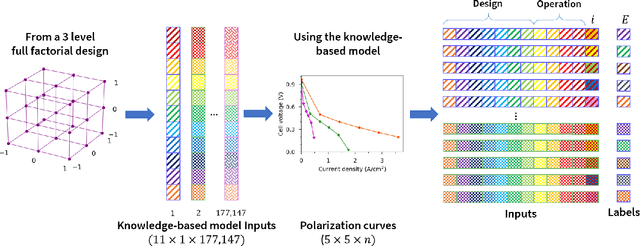
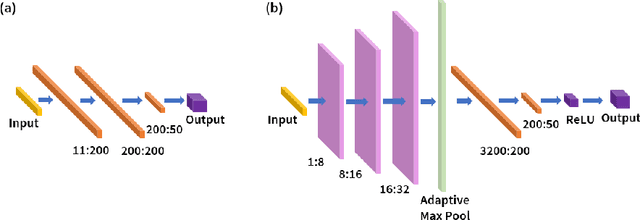
Widespread adoption of high-temperature polymer electrolyte membrane fuel cells (HT-PEMFCs) and HT-PEM electrochemical hydrogen pumps (HT-PEM ECHPs) requires models and computational tools that provide accurate scale-up and optimization. Knowledge-based modeling has limitations as it is time consuming and requires information about the system that is not always available (e.g., material properties and interfacial behavior between different materials). Data-driven modeling on the other hand, is easier to implement, but often necessitates large datasets that could be difficult to obtain. In this contribution, knowledge-based modeling and data-driven modeling are uniquely combined by implementing a Few-Shot Learning (FSL) approach. A knowledge-based model originally developed for a HT-PEMFC was used to generate simulated data (887,735 points) and used to pretrain a neural network source model. Furthermore, the source model developed for HT-PEMFCs was successfully applied to HT-PEM ECHPs - a different electrochemical system that utilizes similar materials to the fuel cell. Experimental datasets from both HT-PEMFCs and HT-PEM ECHPs with different materials and operating conditions (~50 points each) were used to train 8 target models via FSL. Models for the unseen data reached high accuracies in all cases (rRMSE between 1.04 and 3.73% for HT-PEMCs and between 6.38 and 8.46% for HT-PEM ECHPs).
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020
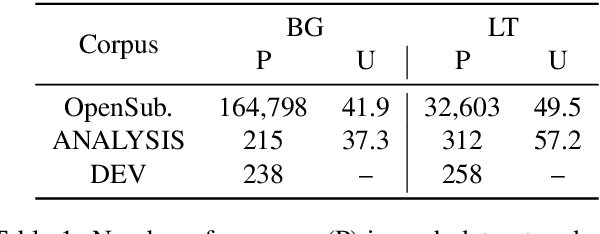
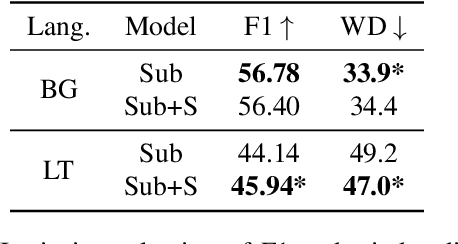

In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Do Language Embeddings Capture Scales?
Oct 11, 2020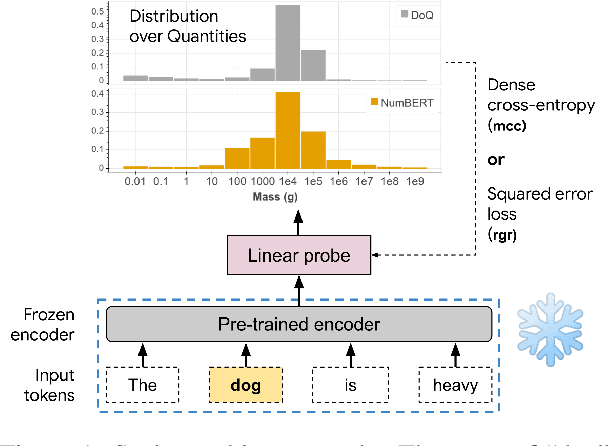
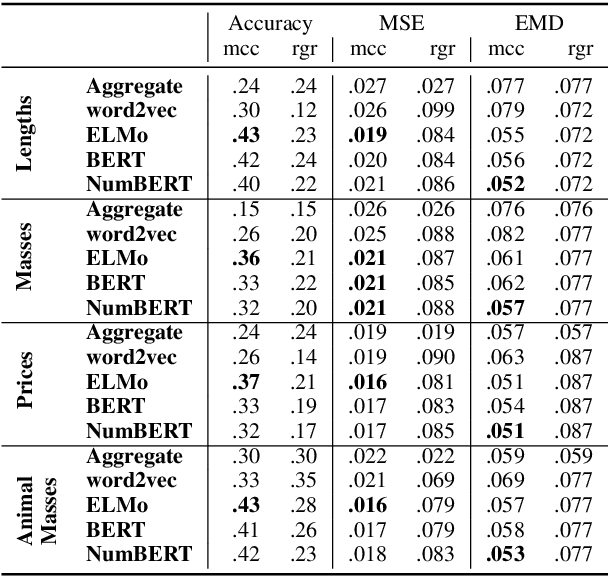
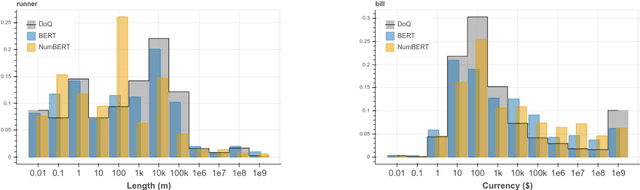
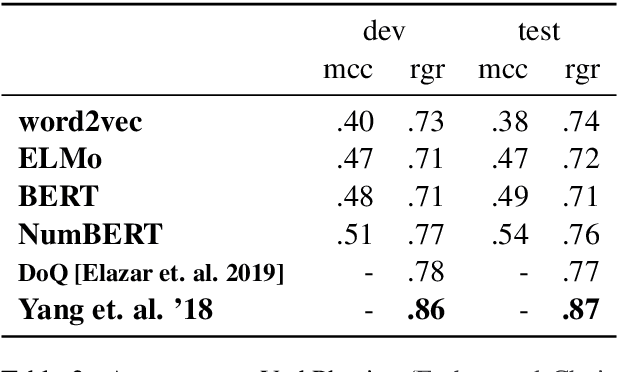
Pretrained Language Models (LMs) have been shown to possess significant linguistic, common sense, and factual knowledge. One form of knowledge that has not been studied yet in this context is information about the scalar magnitudes of objects. We show that pretrained language models capture a significant amount of this information but are short of the capability required for general common-sense reasoning. We identify contextual information in pre-training and numeracy as two key factors affecting their performance and show that a simple method of canonicalizing numbers can have a significant effect on the results.
Weakly Supervised Multi-Object Tracking and Segmentation
Jan 03, 2021
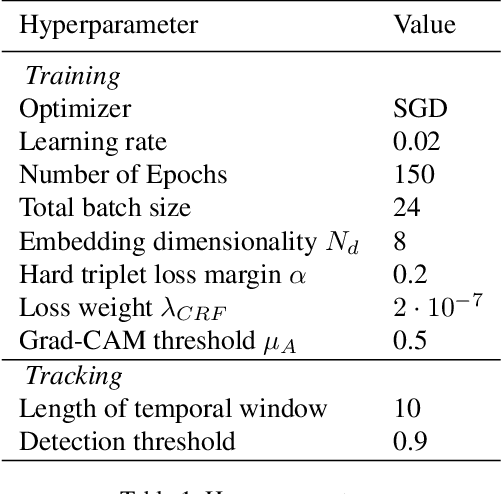
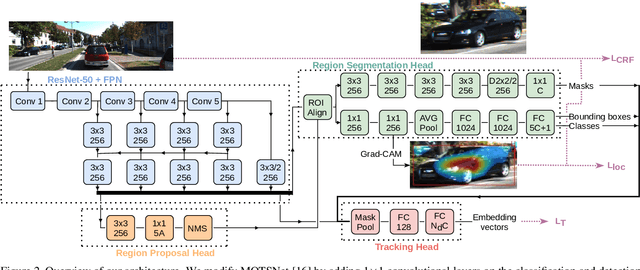
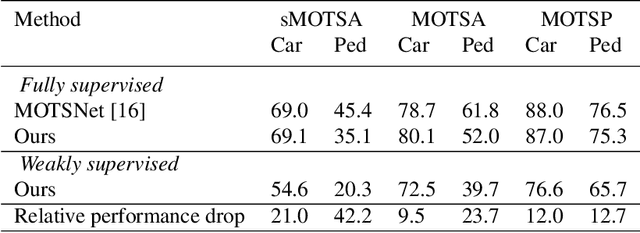
We introduce the problem of weakly supervised Multi-Object Tracking and Segmentation, i.e. joint weakly supervised instance segmentation and multi-object tracking, in which we do not provide any kind of mask annotation. To address it, we design a novel synergistic training strategy by taking advantage of multi-task learning, i.e. classification and tracking tasks guide the training of the unsupervised instance segmentation. For that purpose, we extract weak foreground localization information, provided by Grad-CAM heatmaps, to generate a partial ground truth to learn from. Additionally, RGB image level information is employed to refine the mask prediction at the edges of the objects. We evaluate our method on KITTI MOTS, the most representative benchmark for this task, reducing the performance gap on the MOTSP metric between the fully supervised and weakly supervised approach to just 12% and 12.7% for cars and pedestrians, respectively.
* Accepted at Autonomous Vehicle Vision WACV 2021 Workshop
Multistage BiCross Encoder: Team GATE Entry for MLIA Multilingual Semantic Search Task 2
Jan 08, 2021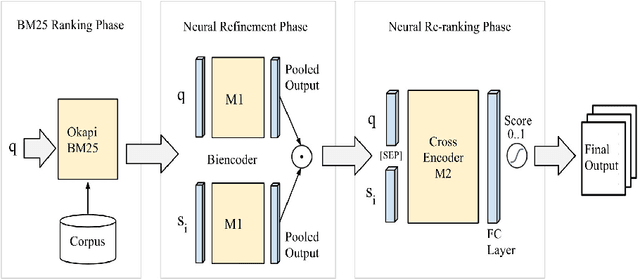
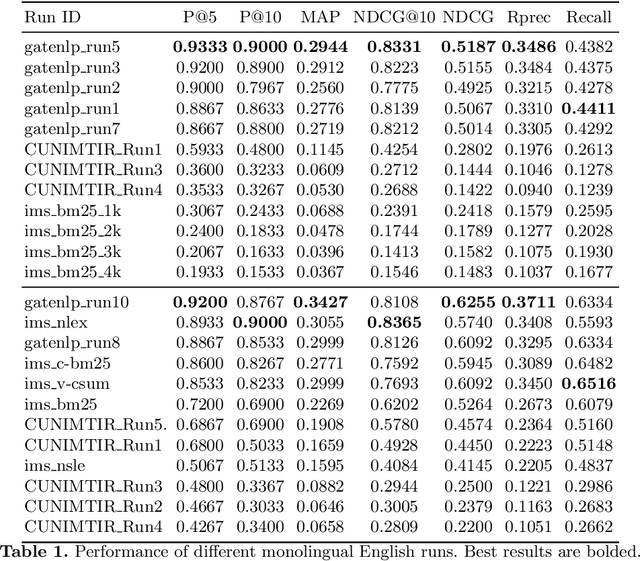
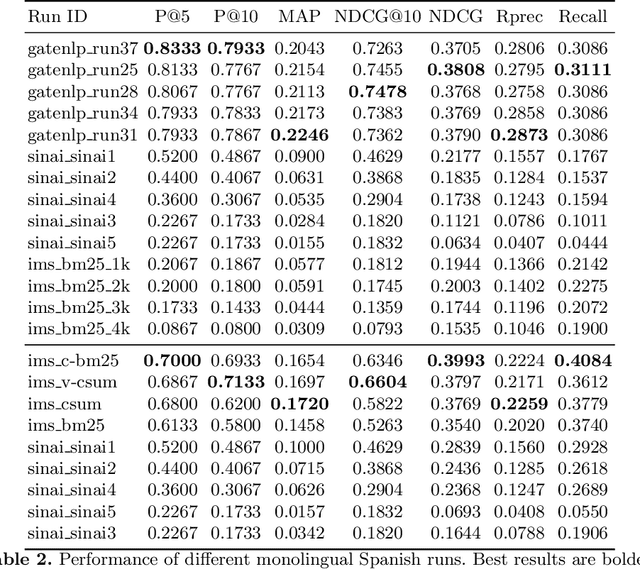
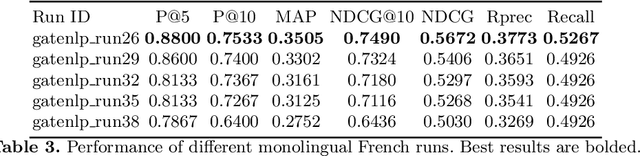
The Coronavirus (COVID-19) pandemic has led to a rapidly growing `infodemic' online. Thus, the accurate retrieval of reliable relevant data from millions of documents about COVID-19 has become urgently needed for the general public as well as for other stakeholders. The COVID-19 Multilingual Information Access (MLIA) initiative is a joint effort to ameliorate exchange of COVID-19 related information by developing applications and services through research and community participation. In this work, we present a search system called Multistage BiCross Encoder, developed by team GATE for the MLIA task 2 Multilingual Semantic Search. Multistage BiCross-Encoder is a sequential three stage pipeline which uses the Okapi BM25 algorithm and a transformer based bi-encoder and cross-encoder to effectively rank the documents with respect to the query. The results of round 1 show that our models achieve state-of-the-art performance for all ranking metrics for both monolingual and bilingual runs.