 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGateNLP at SemEval-2025 Task 10: Hierarchical Three-Step Prompting for Multilingual Narrative Classification
May 28, 2025The proliferation of online news and the increasing spread of misinformation necessitate robust methods for automatic data analysis. Narrative classification is emerging as a important task, since identifying what is being said online is critical for fact-checkers, policy markers and other professionals working on information studies. This paper presents our approach to SemEval 2025 Task 10 Subtask 2, which aims to classify news articles into a pre-defined two-level taxonomy of main narratives and sub-narratives across multiple languages. We propose Hierarchical Three-Step Prompting (H3Prompt) for multilingual narrative classification. Our methodology follows a three-step Large Language Model (LLM) prompting strategy, where the model first categorises an article into one of two domains (Ukraine-Russia War or Climate Change), then identifies the most relevant main narratives, and finally assigns sub-narratives. Our approach secured the top position on the English test set among 28 competing teams worldwide. The code is available at https://github.com/GateNLP/H3Prompt.
Finding Already Debunked Narratives via Multistage Retrieval: Enabling Cross-Lingual, Cross-Dataset and Zero-Shot Learning
Aug 10, 2023



The task of retrieving already debunked narratives aims to detect stories that have already been fact-checked. The successful detection of claims that have already been debunked not only reduces the manual efforts of professional fact-checkers but can also contribute to slowing the spread of misinformation. Mainly due to the lack of readily available data, this is an understudied problem, particularly when considering the cross-lingual task, i.e. the retrieval of fact-checking articles in a language different from the language of the online post being checked. This paper fills this gap by (i) creating a novel dataset to enable research on cross-lingual retrieval of already debunked narratives, using tweets as queries to a database of fact-checking articles; (ii) presenting an extensive experiment to benchmark fine-tuned and off-the-shelf multilingual pre-trained Transformer models for this task; and (iii) proposing a novel multistage framework that divides this cross-lingual debunk retrieval task into refinement and re-ranking stages. Results show that the task of cross-lingual retrieval of already debunked narratives is challenging and off-the-shelf Transformer models fail to outperform a strong lexical-based baseline (BM25). Nevertheless, our multistage retrieval framework is robust, outperforming BM25 in most scenarios and enabling cross-domain and zero-shot learning, without significantly harming the model's performance.
A Large-Scale Comparative Study of Accurate COVID-19 Information versus Misinformation
Apr 10, 2023



The COVID-19 pandemic led to an infodemic where an overwhelming amount of COVID-19 related content was being disseminated at high velocity through social media. This made it challenging for citizens to differentiate between accurate and inaccurate information about COVID-19. This motivated us to carry out a comparative study of the characteristics of COVID-19 misinformation versus those of accurate COVID-19 information through a large-scale computational analysis of over 242 million tweets. The study makes comparisons alongside four key aspects: 1) the distribution of topics, 2) the live status of tweets, 3) language analysis and 4) the spreading power over time. An added contribution of this study is the creation of a COVID-19 misinformation classification dataset. Finally, we demonstrate that this new dataset helps improve misinformation classification by more than 9% based on average F1 measure.
GateNLP-UShef at SemEval-2022 Task 8: Entity-Enriched Siamese Transformer for Multilingual News Article Similarity
May 31, 2022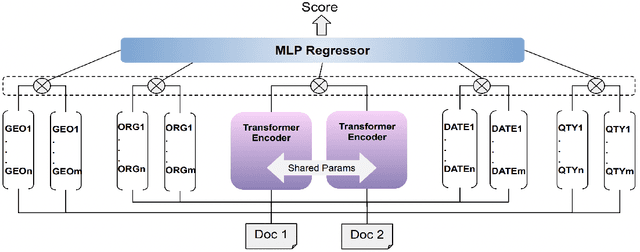
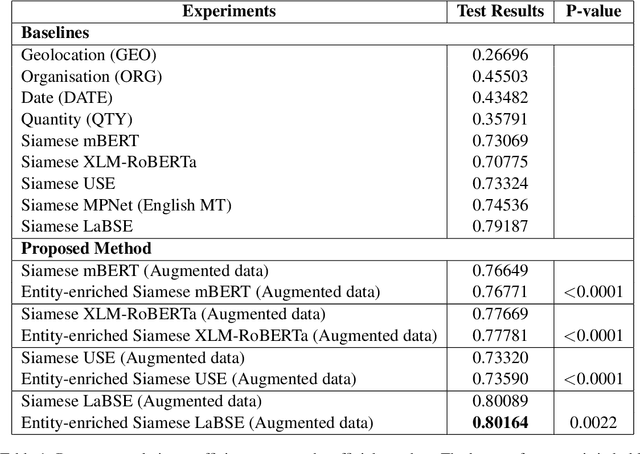
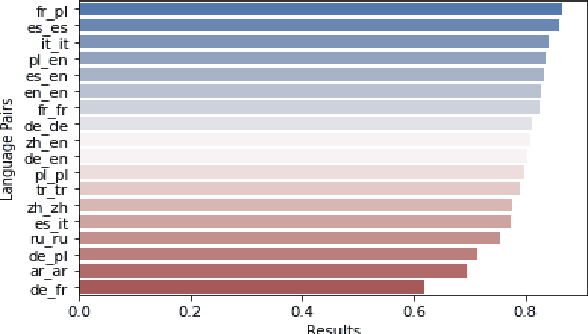
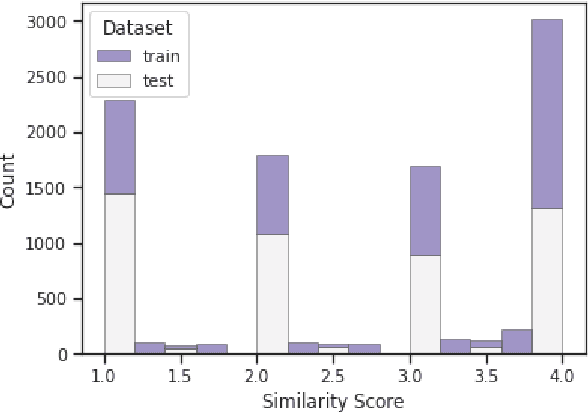
This paper describes the second-placed system on the leaderboard of SemEval-2022 Task 8: Multilingual News Article Similarity. We propose an entity-enriched Siamese Transformer which computes news article similarity based on different sub-dimensions, such as the shared narrative, entities, location and time of the event discussed in the news article. Our system exploits a Siamese network architecture using a Transformer encoder to learn document-level representations for the purpose of capturing the narrative together with the auxiliary entity-based features extracted from the news articles. The intuition behind using all these features together is to capture the similarity between news articles at different granularity levels and to assess the extent to which different news outlets write about "the same events". Our experimental results and detailed ablation study demonstrate the effectiveness and the validity of our proposed method.
Multistage BiCross Encoder: Team GATE Entry for MLIA Multilingual Semantic Search Task 2
Jan 15, 2021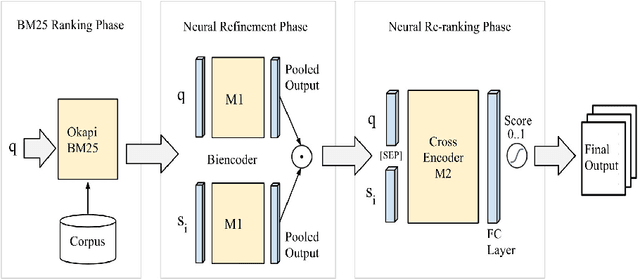
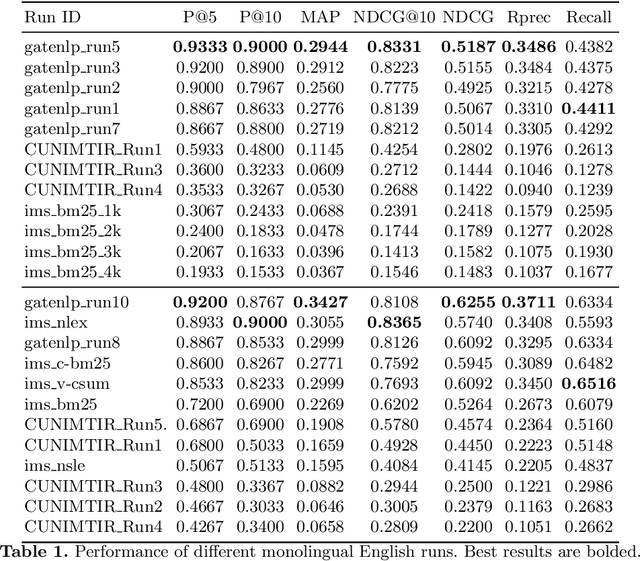
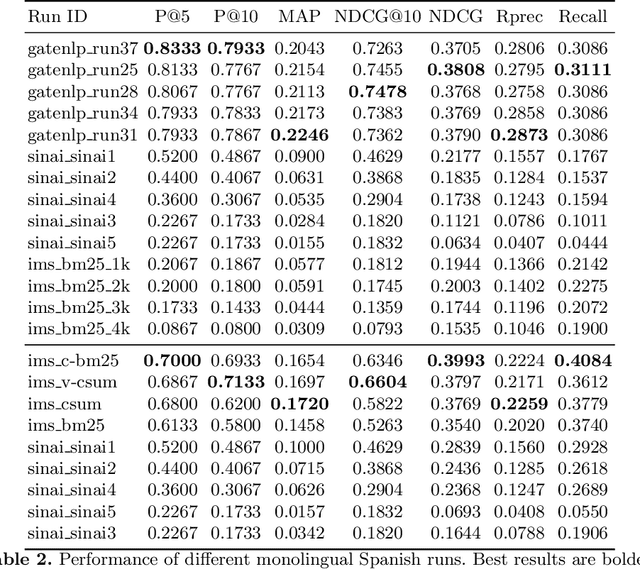
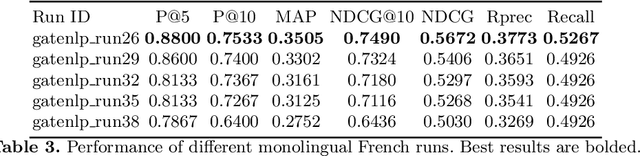
The Coronavirus (COVID-19) pandemic has led to a rapidly growing `infodemic' online. Thus, the accurate retrieval of reliable relevant data from millions of documents about COVID-19 has become urgently needed for the general public as well as for other stakeholders. The COVID-19 Multilingual Information Access (MLIA) initiative is a joint effort to ameliorate exchange of COVID-19 related information by developing applications and services through research and community participation. In this work, we present a search system called Multistage BiCross Encoder, developed by team GATE for the MLIA task 2 Multilingual Semantic Search. Multistage BiCross-Encoder is a sequential three stage pipeline which uses the Okapi BM25 algorithm and a transformer based bi-encoder and cross-encoder to effectively rank the documents with respect to the query. The results of round 1 show that our models achieve state-of-the-art performance for all ranking metrics for both monolingual and bilingual runs.
Classification Aware Neural Topic Model and its Application on a New COVID-19 Disinformation Corpus
Jun 05, 2020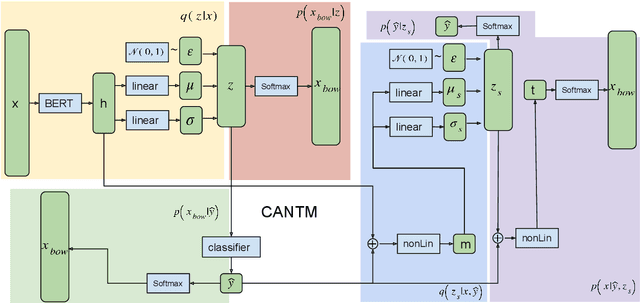
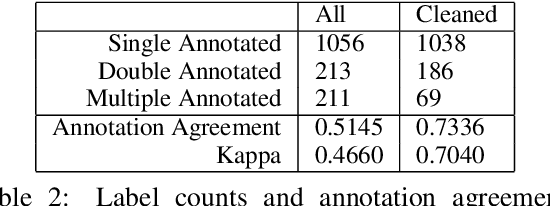
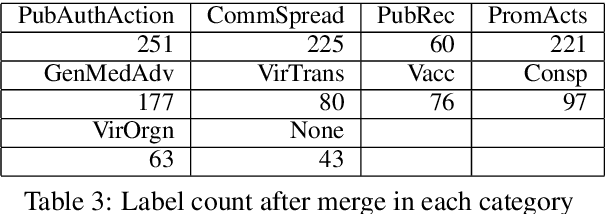
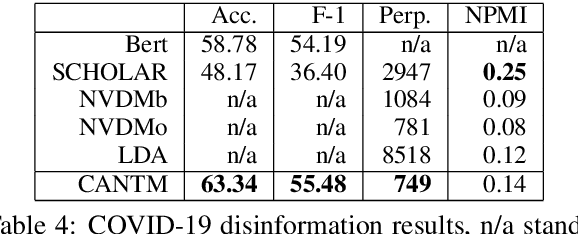
The explosion of disinformation related to the COVID-19 pandemic has overloaded fact-checkers and media worldwide. To help tackle this, we developed computational methods to support COVID-19 disinformation debunking and social impacts research. This paper presents: 1) the currently largest available manually annotated COVID-19 disinformation category dataset; and 2) a classification-aware neural topic model (CANTM) that combines classification and topic modelling under a variational autoencoder framework. We demonstrate that CANTM efficiently improves classification performance with low resources, and is scalable. In addition, the classification-aware topics help researchers and end-users to better understand the classification results.
On the Coherence of Fake News Articles
Jun 26, 2019
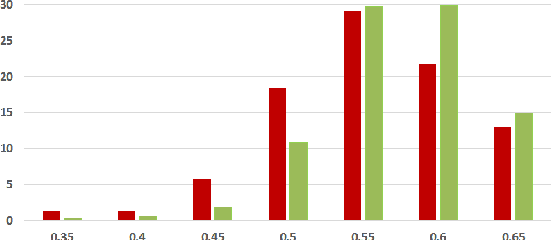
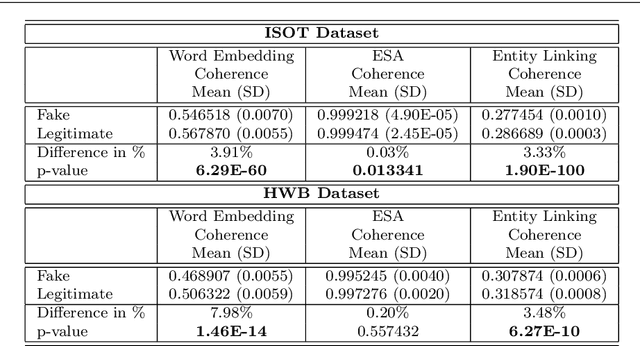
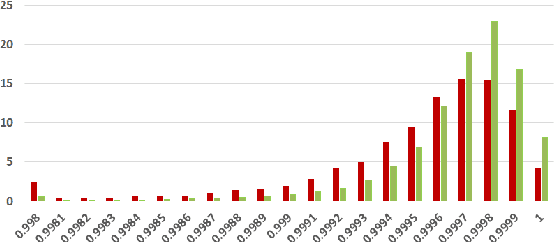
The generation and spread of fake news within new and online media sources is emerging as a phenomenon of high societal significance. Combating them using data-driven analytics has been attracting much recent scholarly interest. In this study, we analyze the textual coherence of fake news articles vis-a-vis legitimate ones. We develop three computational formulations of textual coherence drawing upon the state-of-the-art methods in natural language processing and data science. Two real-world datasets from widely different domains which have fake/legitimate article labellings are then analyzed with respect to textual coherence. We observe apparent differences in textual coherence across fake and legitimate news articles, with fake news articles consistently scoring lower on coherence as compared to legitimate news ones. While the relative coherence shortfall of fake news articles as compared to legitimate ones form the main observation from our study, we analyze several aspects of the differences and outline potential avenues of further inquiry.