 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Covid-19 Detection from Chest X-ray and Patient Metadata using Graph Convolutional Neural Networks
May 20, 2021
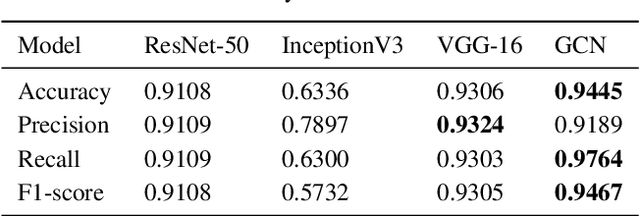
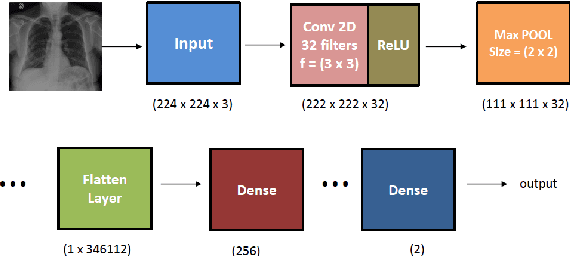
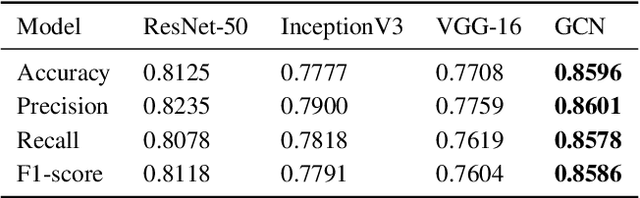
The novel corona virus (Covid-19) has introduced significant challenges due to its rapid spreading nature through respiratory transmission. As a result, there is a huge demand for Artificial Intelligence (AI) based quick disease diagnosis methods as an alternative to high demand tests such as Polymerase Chain Reaction (PCR). Chest X-ray (CXR) Image analysis is such cost-effective radiography technique due to resource availability and quick screening. But, a sufficient and systematic data collection that is required by complex deep leaning (DL) models is more difficult and hence there are recent efforts that utilize transfer learning to address this issue. Still these transfer learnt models suffer from lack of generalization and increased bias to the training dataset resulting poor performance for unseen data. Limited correlation of the transferred features from the pre-trained model to a specific medical imaging domain like X-ray and overfitting on fewer data can be reasons for this circumstance. In this work, we propose a novel Graph Convolution Neural Network (GCN) that is capable of identifying bio-markers of Covid-19 pneumonia from CXR images and meta information about patients. The proposed method exploits important relational knowledge between data instances and their features using graph representation and applies convolution to learn the graph data which is not possible with conventional convolution on Euclidean domain. The results of extensive experiments of proposed model on binary (Covid vs normal) and three class (Covid, normal, other pneumonia) classification problems outperform different benchmark transfer learnt models, hence overcoming the aforementioned drawbacks.
KLUE: Korean Language Understanding Evaluation
May 20, 2021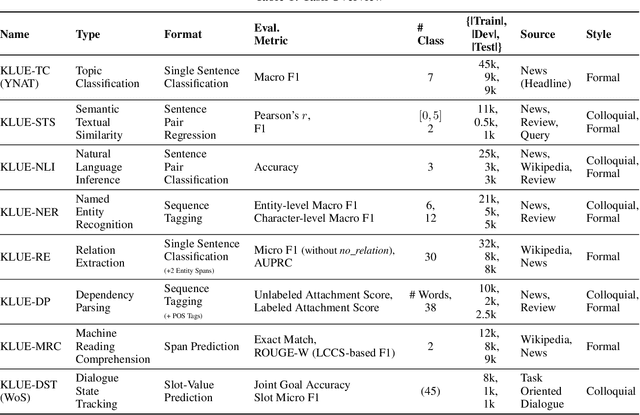
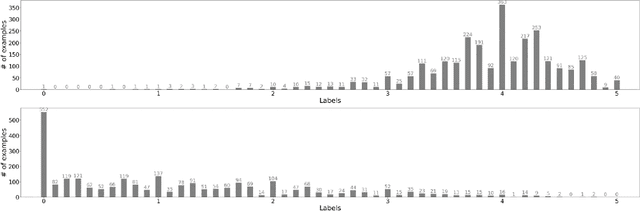
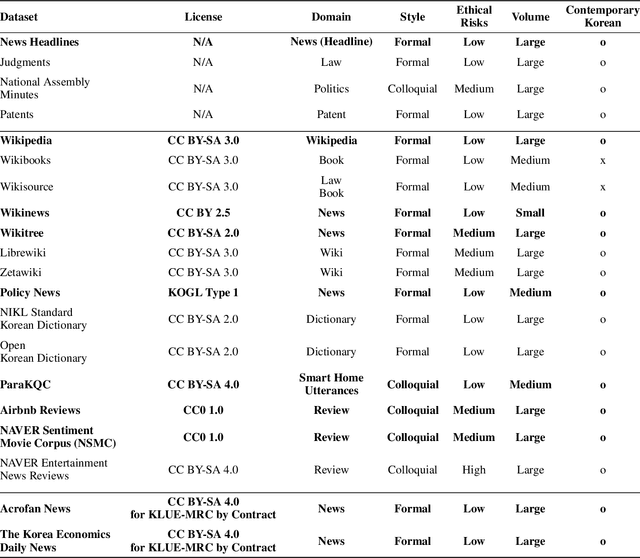
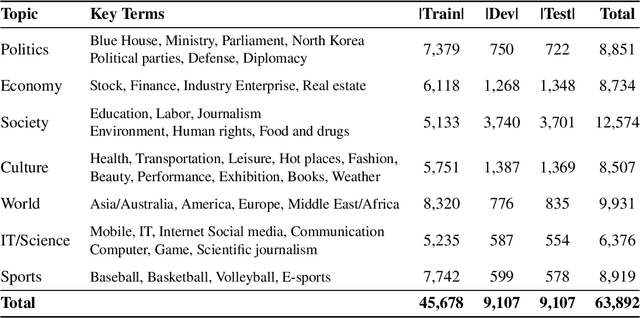
We introduce Korean Language Understanding Evaluation (KLUE) benchmark. KLUE is a collection of 8 Korean natural language understanding (NLU) tasks, including Topic Classification, Semantic Textual Similarity, Natural Language Inference, Named Entity Recognition, Relation Extraction, Dependency Parsing, Machine Reading Comprehension, and Dialogue State Tracking. We build all of the tasks from scratch from diverse source corpora while respecting copyrights, to ensure accessibility for anyone without any restrictions. With ethical considerations in mind, we carefully design annotation protocols. Along with the benchmark tasks and data, we provide suitable evaluation metrics and fine-tuning recipes for pretrained language models for each task. We furthermore release the pretrained language models (PLM), KLUE-BERT and KLUE-RoBERTa, to help reproduce baseline models on KLUE and thereby facilitate future research. We make a few interesting observations from the preliminary experiments using the proposed KLUE benchmark suite, already demonstrating the usefulness of this new benchmark suite. First, we find KLUE-RoBERTa-large outperforms other baselines, including multilingual PLMs and existing open-source Korean PLMs. Second, we see minimal degradation in performance even when we replace personally identifiable information from the pretraining corpus, suggesting that privacy and NLU capability are not at odds with each other. Lastly, we find that using BPE tokenization in combination with morpheme-level pre-tokenization is effective in tasks involving morpheme-level tagging, detection and generation. In addition to accelerating Korean NLP research, our comprehensive documentation on creating KLUE will facilitate creating similar resources for other languages in the future. KLUE is available at this https URL (https://klue-benchmark.com/).
AXM-Net: Cross-Modal Context Sharing Attention Network for Person Re-ID
Jan 19, 2021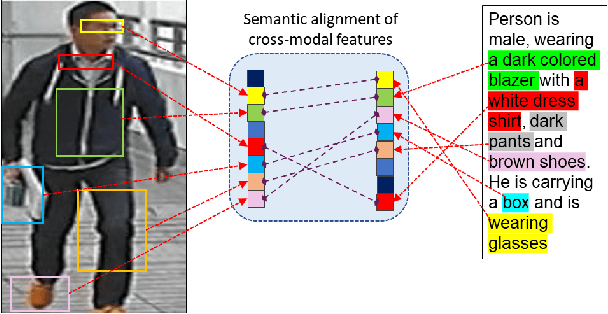
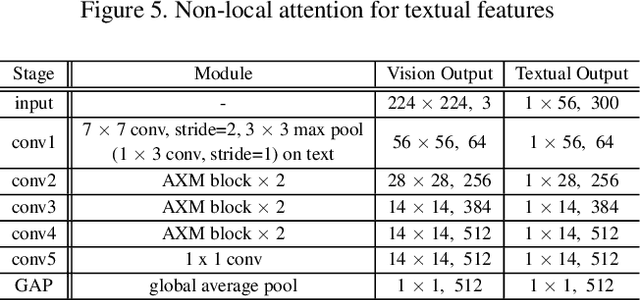
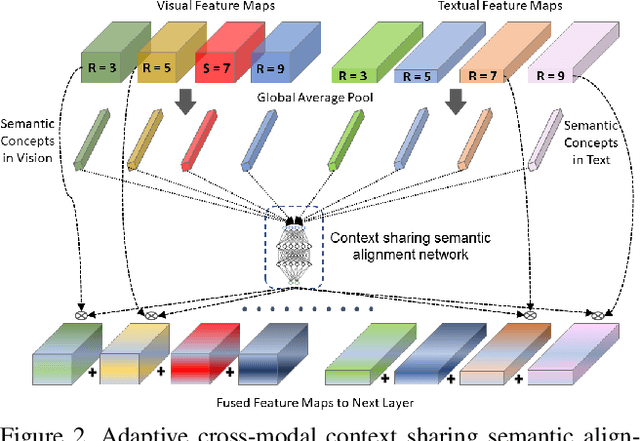
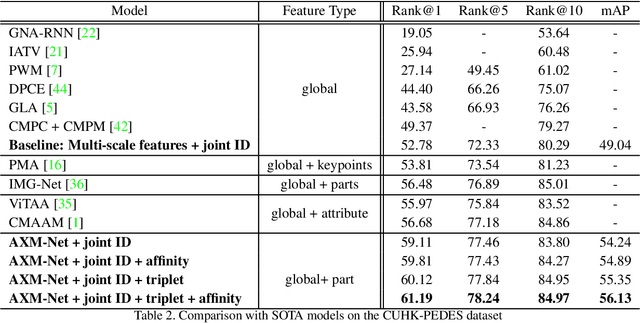
Cross-modal person re-identification (Re-ID) is critical for modern video surveillance systems. The key challenge is to align inter-modality representations according to semantic information present for a person and ignore background information. In this work, we present AXM-Net, a novel CNN based architecture designed for learning semantically aligned visual and textual representations. The underlying building block consists of multiple streams of feature maps coming from visual and textual modalities and a novel learnable context sharing semantic alignment network. We also propose complementary intra modal attention learning mechanisms to focus on more fine-grained local details in the features along with a cross-modal affinity loss for robust feature matching. Our design is unique in its ability to implicitly learn feature alignments from data. The entire AXM-Net can be trained in an end-to-end manner. We report results on both person search and cross-modal Re-ID tasks. Extensive experimentation validates the proposed framework and demonstrates its superiority by outperforming the current state-of-the-art methods by a significant margin.
Concentration Inequalities for Two-Sample Rank Processes with Application to Bipartite Ranking
Apr 07, 2021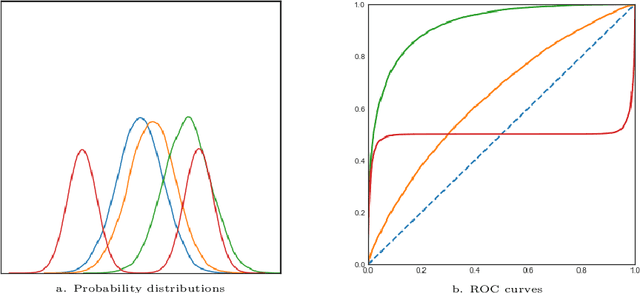
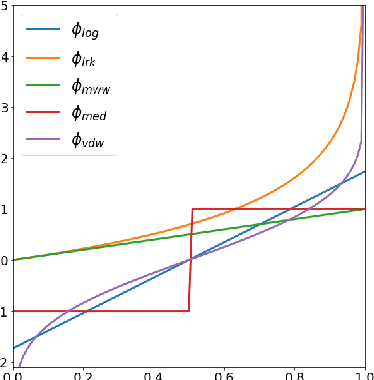
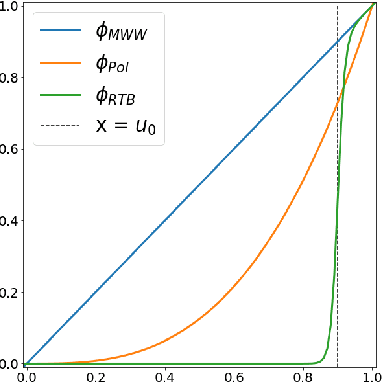
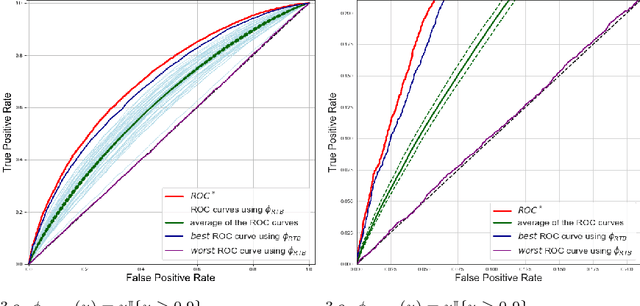
The ROC curve is the gold standard for measuring the performance of a test/scoring statistic regarding its capacity to discriminate between two statistical populations in a wide variety of applications, ranging from anomaly detection in signal processing to information retrieval, through medical diagnosis. Most practical performance measures used in scoring/ranking applications such as the AUC, the local AUC, the p-norm push, the DCG and others, can be viewed as summaries of the ROC curve. In this paper, the fact that most of these empirical criteria can be expressed as two-sample linear rank statistics is highlighted and concentration inequalities for collections of such random variables, referred to as two-sample rank processes here, are proved, when indexed by VC classes of scoring functions. Based on these nonasymptotic bounds, the generalization capacity of empirical maximizers of a wide class of ranking performance criteria is next investigated from a theoretical perspective. It is also supported by empirical evidence through convincing numerical experiments.
Effect of depth order on iterative nested named entity recognition models
Apr 02, 2021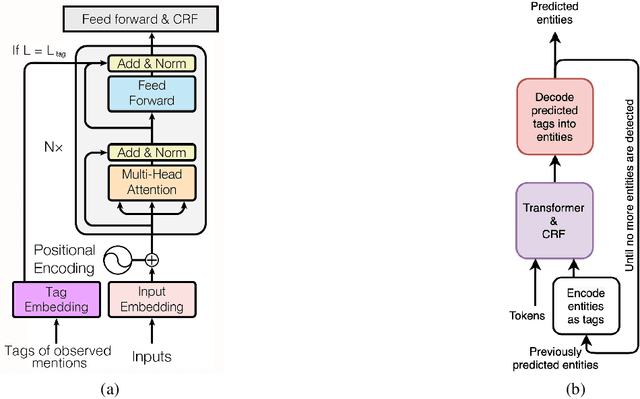
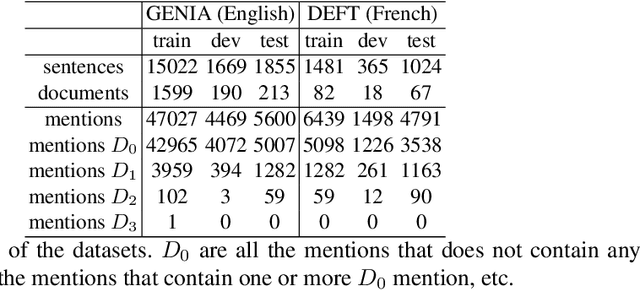
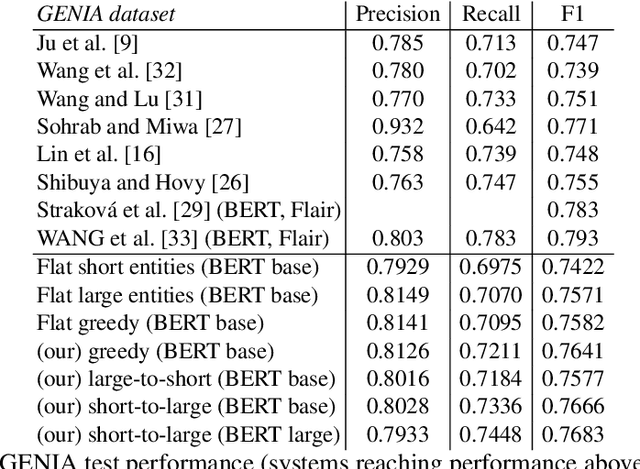
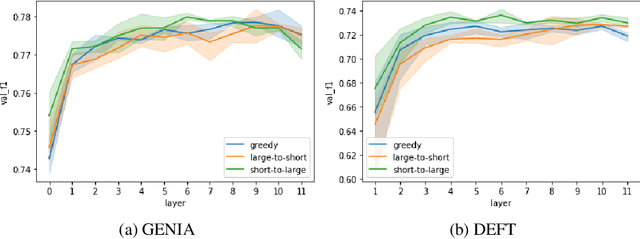
This paper studies the effect of the order of depth of mention on nested named entity recognition (NER) models. NER is an essential task in the extraction of biomedical information, and nested entities are common since medical concepts can assemble to form larger entities. Conventional NER systems only predict disjointed entities. Thus, iterative models for nested NER use multiple predictions to enumerate all entities, imposing a predefined order from largest to smallest or smallest to largest. We design an order-agnostic iterative model and a procedure to choose a custom order during training and prediction. To accommodate for this task, we propose a modification of the Transformer architecture to take into account the entities predicted in the previous steps. We provide a set of experiments to study the model's capabilities and the effects of the order on performance. Finally, we show that the smallest to largest order gives the best results.
Fidelity and Privacy of Synthetic Medical Data
Jan 18, 2021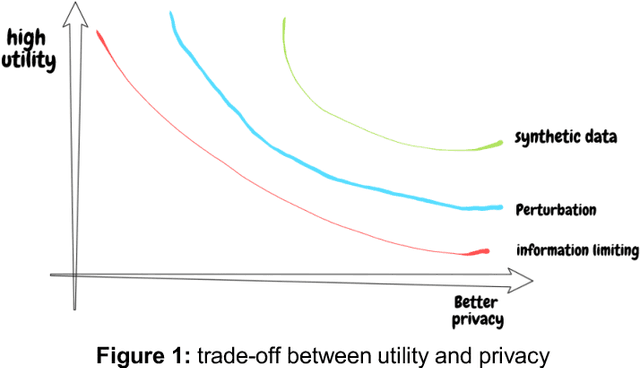
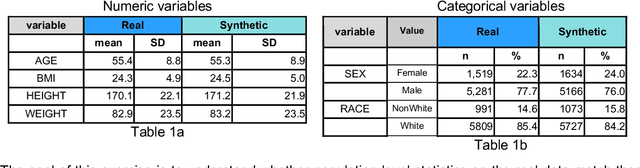
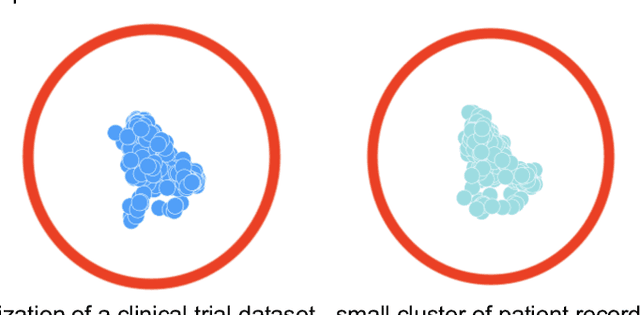

The digitization of medical records ushered in a new era of big data to clinical science, and with it the possibility that data could be shared, to multiply insights beyond what investigators could abstract from paper records. The need to share individual-level medical data to accelerate innovation in precision medicine continues to grow, and has never been more urgent, as scientists grapple with the COVID-19 pandemic. However, enthusiasm for the use of big data has been tempered by a fully appropriate concern for patient autonomy and privacy. That is, the ability to extract private or confidential information about an individual, in practice, renders it difficult to share data, since significant infrastructure and data governance must be established before data can be shared. Although HIPAA provided de-identification as an approved mechanism for data sharing, linkage attacks were identified as a major vulnerability. A variety of mechanisms have been established to avoid leaking private information, such as field suppression or abstraction, strictly limiting the amount of information that can be shared, or employing mathematical techniques such as differential privacy. Another approach, which we focus on here, is creating synthetic data that mimics the underlying data. For synthetic data to be a useful mechanism in support of medical innovation and a proxy for real-world evidence, one must demonstrate two properties of the synthetic dataset: (1) any analysis on the real data must be matched by analysis of the synthetic data (statistical fidelity) and (2) the synthetic data must preserve privacy, with minimal risk of re-identification (privacy guarantee). In this paper we propose a framework for quantifying the statistical fidelity and privacy preservation properties of synthetic datasets and demonstrate these metrics for synthetic data generated by Syntegra technology.
Physical deep learning based on optimal control of dynamical systems
Dec 16, 2020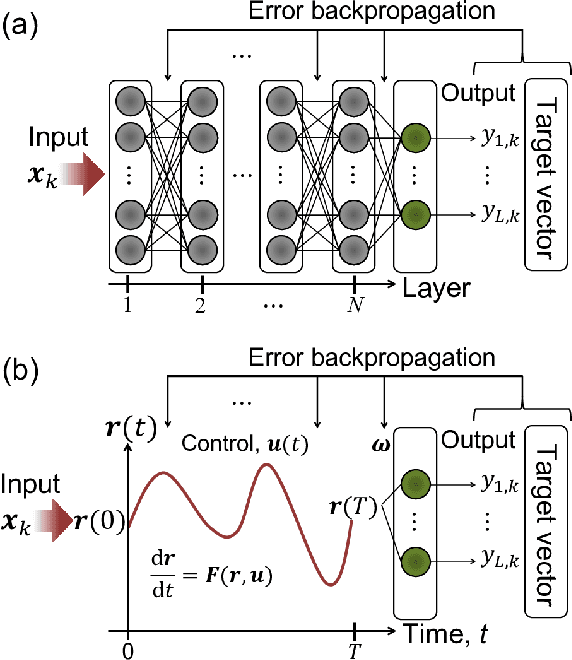
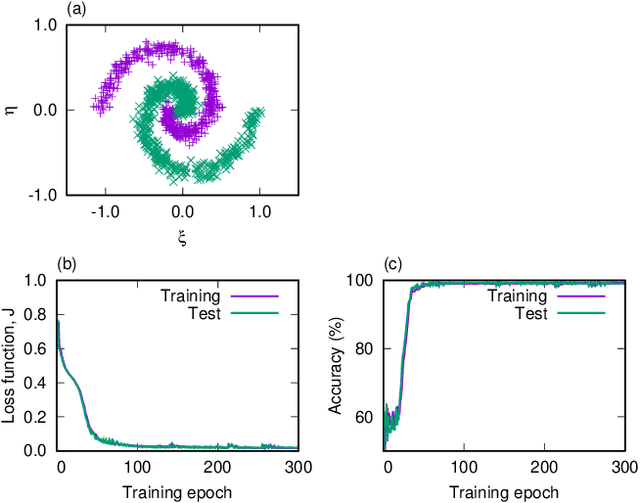
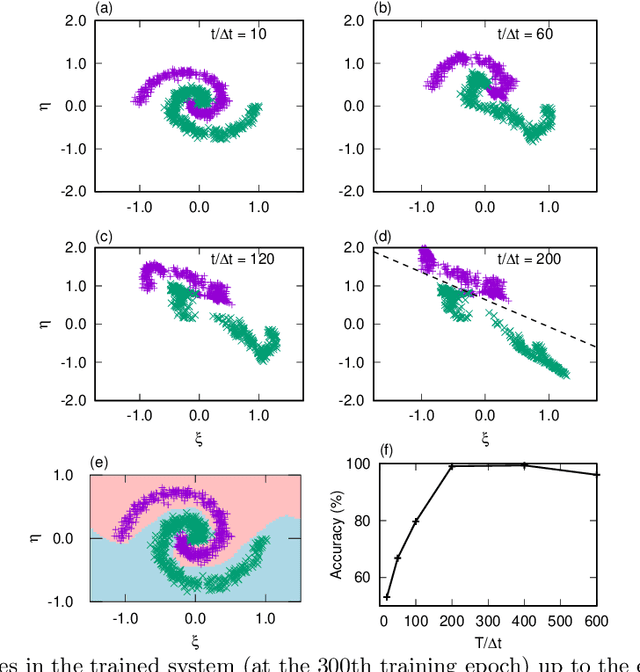
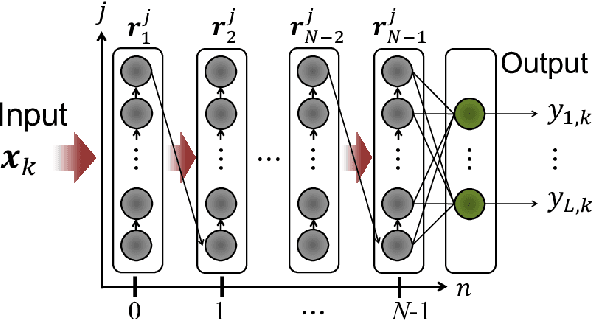
A central topic in recent artificial intelligence technologies is deep learning, which can be regarded as a multilayer feedforward neural network. An essence of deep learning is the information propagation through the layers, suggesting a connection between deep neural networks and dynamical systems, in the sense that the information propagation is explicitly modeled by the time-evolution of dynamical systems. Here, we present a pattern recognition based on optimal control of continuous-time dynamical systems, which is suitable for physical hardware implementation. The learning is based on the adjoint method to optimally control dynamical systems, and the deep (virtual) network structures based on the time evolution of the systems can be used for processing input information. As an example, we apply the dynamics-based recognition approach to an optoelectronic delay system and show that the use of the delay system enables image recognition and nonlinear classifications with only a few control signals, in contrast to conventional multilayer neural networks which require training of a large number of weight parameters. The proposed approach enables to gain insight into mechanisms of deep network processing in the framework of an optimal control problem and opens a novel pathway to realize physical computing hardware.
Multi-Modal Aesthetic Assessment for MObile Gaming Image
Jan 27, 2021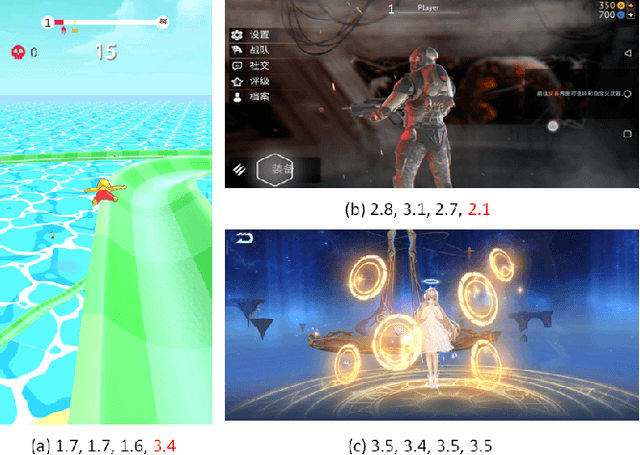
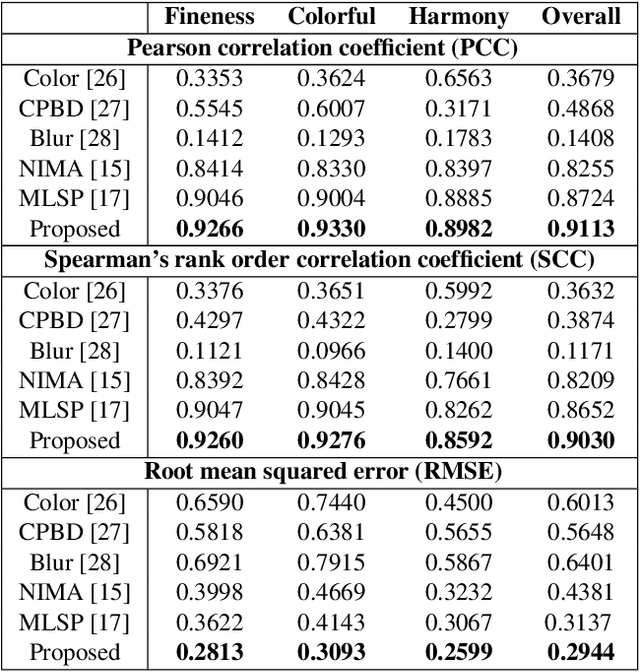
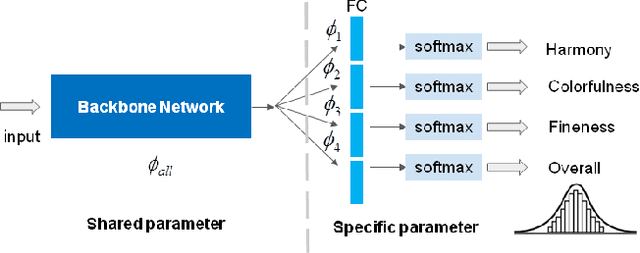
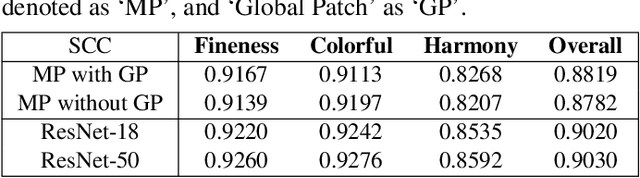
With the proliferation of various gaming technology, services, game styles, and platforms, multi-dimensional aesthetic assessment of the gaming contents is becoming more and more important for the gaming industry. Depending on the diverse needs of diversified game players, game designers, graphical developers, etc. in particular conditions, multi-modal aesthetic assessment is required to consider different aesthetic dimensions/perspectives. Since there are different underlying relationships between different aesthetic dimensions, e.g., between the `Colorfulness' and `Color Harmony', it could be advantageous to leverage effective information attached in multiple relevant dimensions. To this end, we solve this problem via multi-task learning. Our inclination is to seek and learn the correlations between different aesthetic relevant dimensions to further boost the generalization performance in predicting all the aesthetic dimensions. Therefore, the `bottleneck' of obtaining good predictions with limited labeled data for one individual dimension could be unplugged by harnessing complementary sources of other dimensions, i.e., augment the training data indirectly by sharing training information across dimensions. According to experimental results, the proposed model outperforms state-of-the-art aesthetic metrics significantly in predicting four gaming aesthetic dimensions.
End-to-End 3D Point Cloud Learning for Registration Task Using Virtual Correspondences
Nov 30, 2020
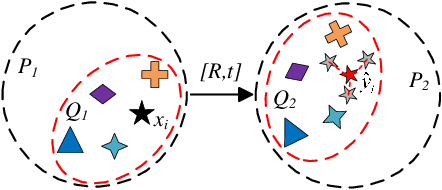
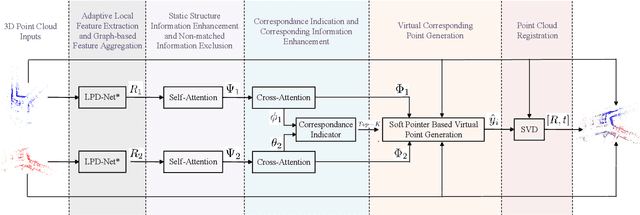

3D Point cloud registration is still a very challenging topic due to the difficulty in finding the rigid transformation between two point clouds with partial correspondences, and it's even harder in the absence of any initial estimation information. In this paper, we present an end-to-end deep-learning based approach to resolve the point cloud registration problem. Firstly, the revised LPD-Net is introduced to extract features and aggregate them with the graph network. Secondly, the self-attention mechanism is utilized to enhance the structure information in the point cloud and the cross-attention mechanism is designed to enhance the corresponding information between the two input point clouds. Based on which, the virtual corresponding points can be generated by a soft pointer based method, and finally, the point cloud registration problem can be solved by implementing the SVD method. Comparison results in ModelNet40 dataset validate that the proposed approach reaches the state-of-the-art in point cloud registration tasks and experiment resutls in KITTI dataset validate the effectiveness of the proposed approach in real applications.
A Review of Biomedical Datasets Relating to Drug Discovery: A Knowledge Graph Perspective
Feb 26, 2021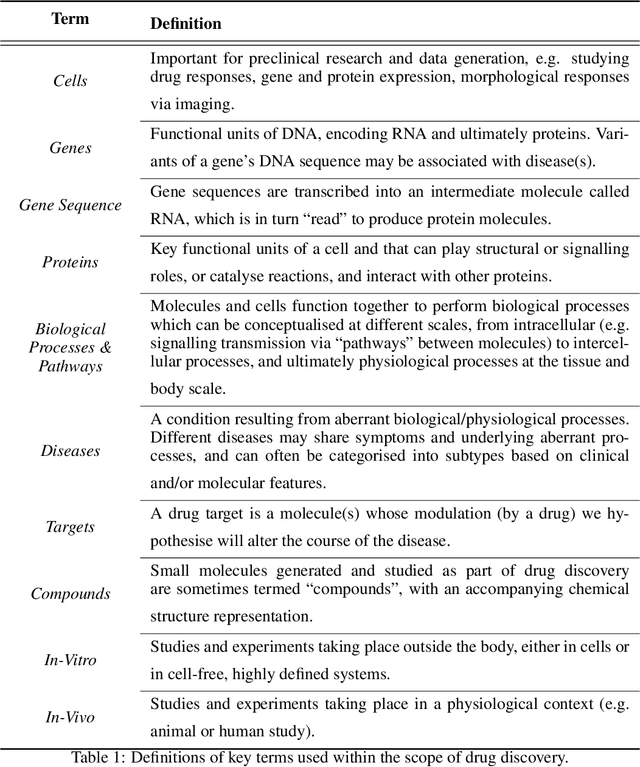
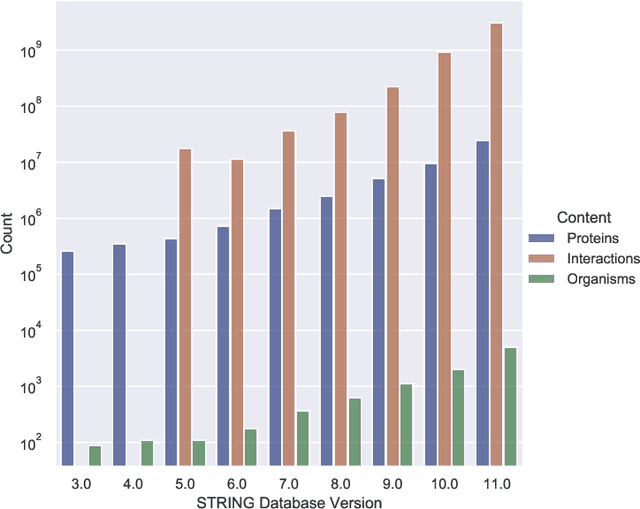
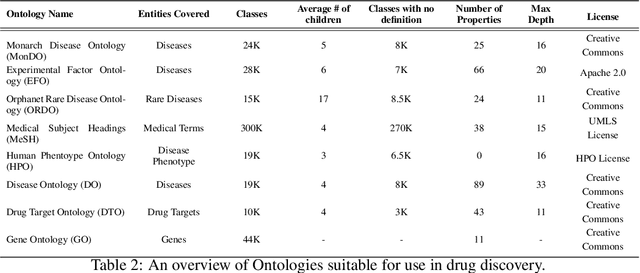
Drug discovery and development is an extremely complex process, with high attrition contributing to the costs of delivering new medicines to patients. Recently, various machine learning approaches have been proposed and investigated to help improve the effectiveness and speed of multiple stages of the drug discovery pipeline. Among these techniques, it is especially those using Knowledge Graphs that are proving to have considerable promise across a range of tasks, including drug repurposing, drug toxicity prediction and target gene-disease prioritisation. In such a knowledge graph-based representation of drug discovery domains, crucial elements including genes, diseases and drugs are represented as entities or vertices, whilst relationships or edges between them indicate some level of interaction. For example, an edge between a disease and drug entity might represent a successful clinical trial, or an edge between two drug entities could indicate a potentially harmful interaction. In order to construct high-quality and ultimately informative knowledge graphs however, suitable data and information is of course required. In this review, we detail publicly available primary data sources containing information suitable for use in constructing various drug discovery focused knowledge graphs. We aim to help guide machine learning and knowledge graph practitioners who are interested in applying new techniques to the drug discovery field, but who may be unfamiliar with the relevant data sources. Overall we hope this review will help motivate more machine learning researchers to explore combining knowledge graphs and machine learning to help solve key and emerging questions in the drug discovery domain.