 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hybrid Generative-Contrastive Representation Learning
Jun 11, 2021
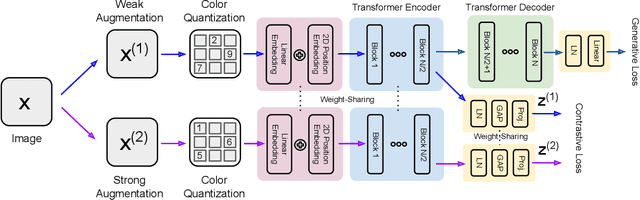
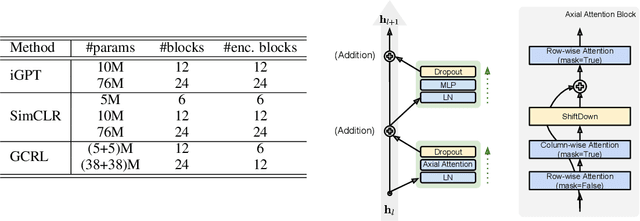

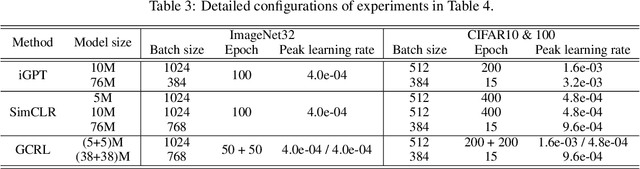
Unsupervised representation learning has recently received lots of interest due to its powerful generalizability through effectively leveraging large-scale unlabeled data. There are two prevalent approaches for this, contrastive learning and generative pre-training, where the former learns representations from instance-wise discrimination tasks and the latter learns them from estimating the likelihood. These seemingly orthogonal approaches have their own strengths and weaknesses. Contrastive learning tends to extract semantic information and discards details irrelevant for classifying objects, making the representations effective for discriminative tasks while degrading robustness to out-of-distribution data. On the other hand, the generative pre-training directly estimates the data distribution, so the representations tend to be robust but not optimal for discriminative tasks. In this paper, we show that we could achieve the best of both worlds by a hybrid training scheme. Specifically, we demonstrated that a transformer-based encoder-decoder architecture trained with both contrastive and generative losses can learn highly discriminative and robust representations without hurting the generative performance. We extensively validate our approach on various tasks.
Few-Shot Action Recognition with Compromised Metric via Optimal Transport
Apr 08, 2021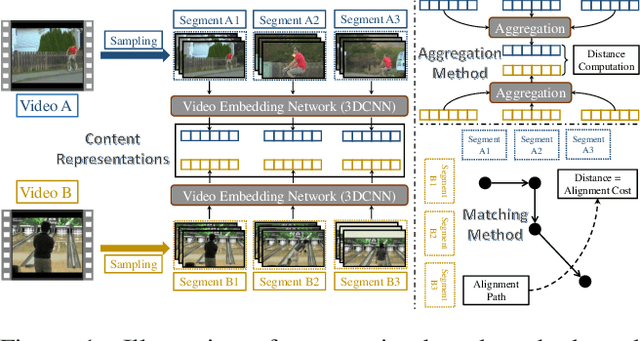


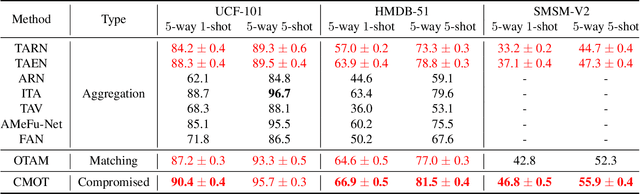
Although vital to computer vision systems, few-shot action recognition is still not mature despite the wide research of few-shot image classification. Popular few-shot learning algorithms extract a transferable embedding from seen classes and reuse it on unseen classes by constructing a metric-based classifier. One main obstacle to applying these algorithms in action recognition is the complex structure of videos. Some existing solutions sample frames from a video and aggregate their embeddings to form a video-level representation, neglecting important temporal relations. Others perform an explicit sequence matching between two videos and define their distance as matching cost, imposing too strong restrictions on sequence ordering. In this paper, we propose Compromised Metric via Optimal Transport (CMOT) to combine the advantages of these two solutions. CMOT simultaneously considers semantic and temporal information in videos under Optimal Transport framework, and is discriminative for both content-sensitive and ordering-sensitive tasks. In detail, given two videos, we sample segments from them and cast the calculation of their distance as an optimal transport problem between two segment sequences. To preserve the inherent temporal ordering information, we additionally amend the ground cost matrix by penalizing it with the positional distance between a pair of segments. Empirical results on benchmark datasets demonstrate the superiority of CMOT.
A Machine Learning Approach to Safer Airplane Landings: Predicting Runway Conditions using Weather and Flight Data
Jul 01, 2021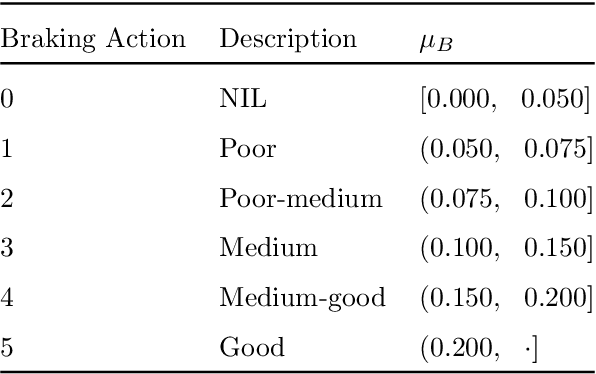
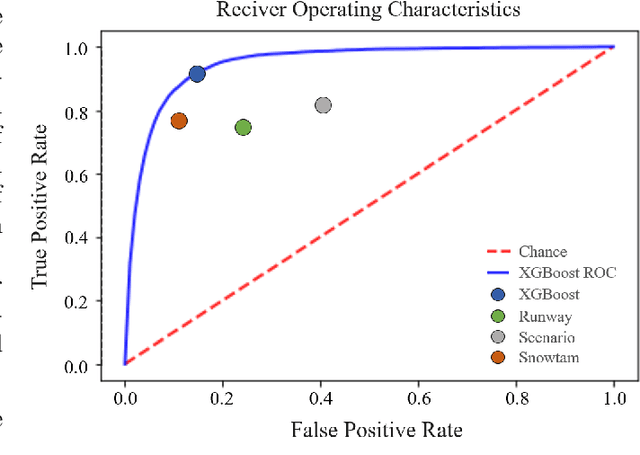
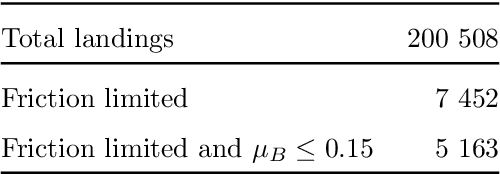
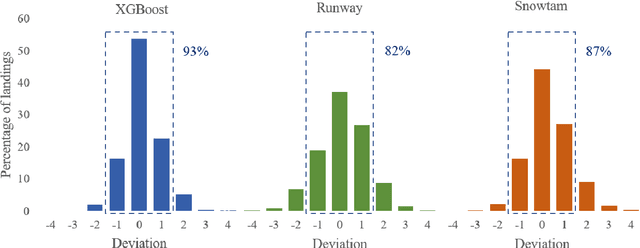
The presence of snow and ice on runway surfaces reduces the available tire-pavement friction needed for retardation and directional control and causes potential economic and safety threats for the aviation industry during the winter seasons. To activate appropriate safety procedures, pilots need accurate and timely information on the actual runway surface conditions. In this study, XGBoost is used to create a combined runway assessment system, which includes a classifcation model to predict slippery conditions and a regression model to predict the level of slipperiness. The models are trained on weather data and data from runway reports. The runway surface conditions are represented by the tire-pavement friction coefficient, which is estimated from flight sensor data from landing aircrafts. To evaluate the performance of the models, they are compared to several state-of-the-art runway assessment methods. The XGBoost models identify slippery runway conditions with a ROC AUC of 0.95, predict the friction coefficient with a MAE of 0.0254, and outperforms all the previous methods. The results show the strong abilities of machine learning methods to model complex, physical phenomena with a good accuracy when domain knowledge is used in the variable extraction. The XGBoost models are combined with SHAP (SHapley Additive exPlanations) approximations to provide a comprehensible decision support system for airport operators and pilots, which can contribute to safer and more economic operations of airport runways.
Towards Natural Brain-Machine Interaction using Endogenous Potentials based on Deep Neural Networks
Jun 25, 2021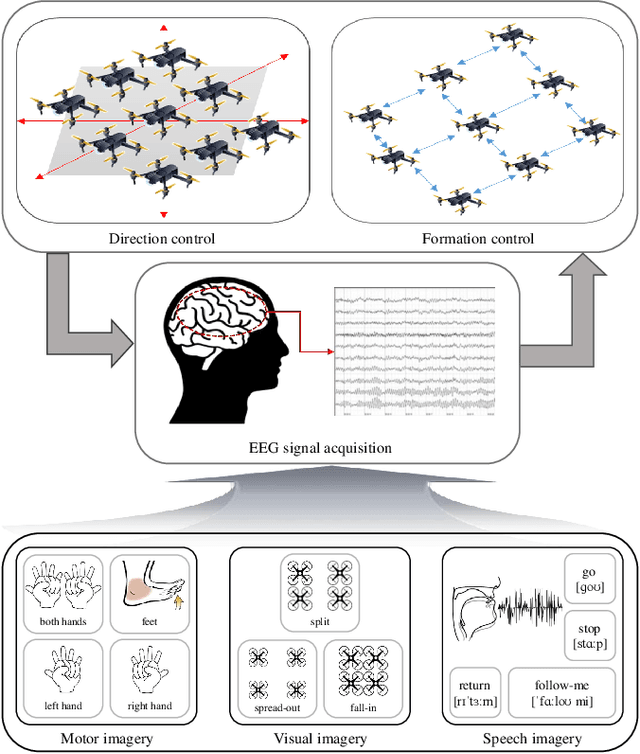
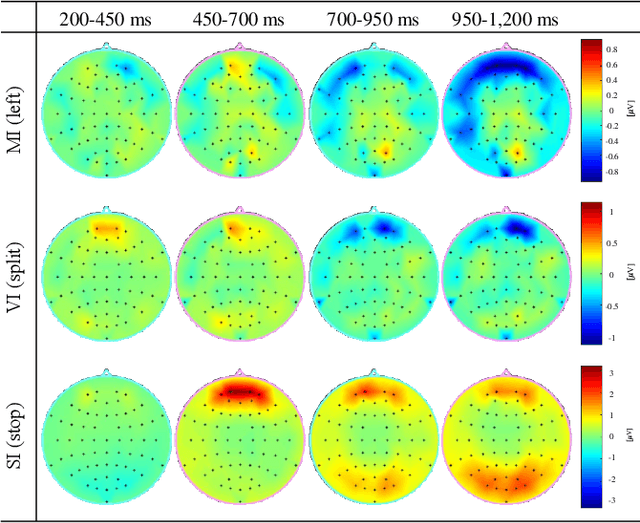
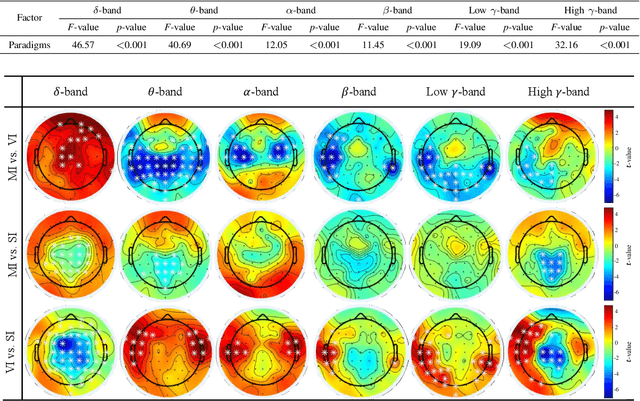
Human-robot collaboration has the potential to maximize the efficiency of the operation of autonomous robots. Brain-machine interface (BMI) would be a desirable technology to collaborate with robots since the intention or state of users can be translated from the neural activities. However, the electroencephalogram (EEG), which is one of the most popularly used non-invasive BMI modalities, has low accuracy and a limited degree of freedom (DoF) due to a low signal-to-noise ratio. Thus, improving the performance of multi-class EEG classification is crucial to develop more flexible BMI-based human-robot collaboration. In this study, we investigated the possibility for inter-paradigm classification of multiple endogenous BMI paradigms, such as motor imagery (MI), visual imagery (VI), and speech imagery (SI), to enhance the limited DoF while maintaining robust accuracy. We conducted the statistical and neurophysiological analyses on MI, VI, and SI and classified three paradigms using the proposed temporal information-based neural network (TINN). We confirmed that statistically significant features could be extracted on different brain regions when classifying three endogenous paradigms. Moreover, our proposed TINN showed the highest accuracy of 0.93 compared to the previous methods for classifying three different types of mental imagery tasks (MI, VI, and SI).
Luna: Linear Unified Nested Attention
Jun 03, 2021
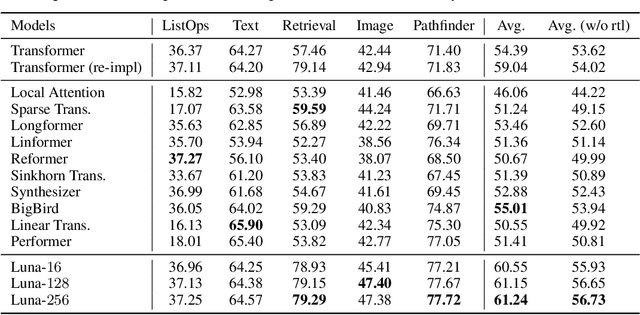
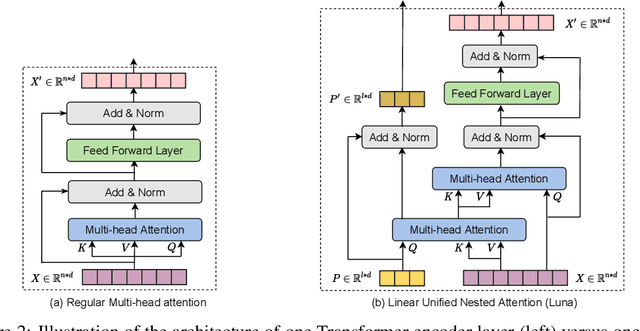
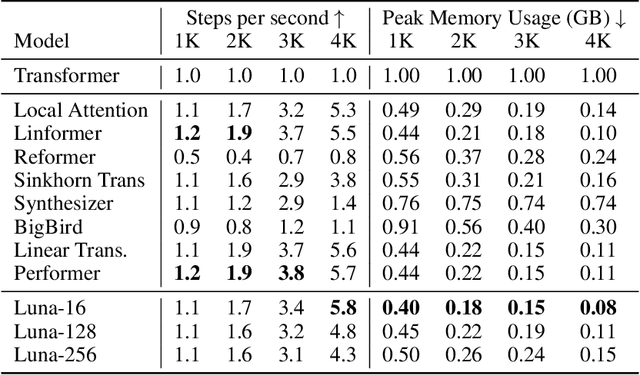
The quadratic computational and memory complexities of the Transformer's attention mechanism have limited its scalability for modeling long sequences. In this paper, we propose Luna, a linear unified nested attention mechanism that approximates softmax attention with two nested linear attention functions, yielding only linear (as opposed to quadratic) time and space complexity. Specifically, with the first attention function, Luna packs the input sequence into a sequence of fixed length. Then, the packed sequence is unpacked using the second attention function. As compared to a more traditional attention mechanism, Luna introduces an additional sequence with a fixed length as input and an additional corresponding output, which allows Luna to perform attention operation linearly, while also storing adequate contextual information. We perform extensive evaluations on three benchmarks of sequence modeling tasks: long-context sequence modeling, neural machine translation and masked language modeling for large-scale pretraining. Competitive or even better experimental results demonstrate both the effectiveness and efficiency of Luna compared to a variety
Improving Knowledge Tracing via Pre-training Question Embeddings
Dec 09, 2020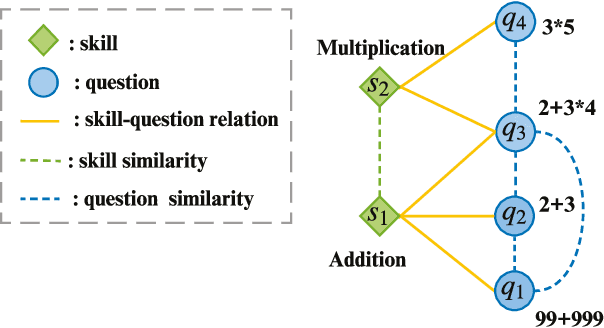
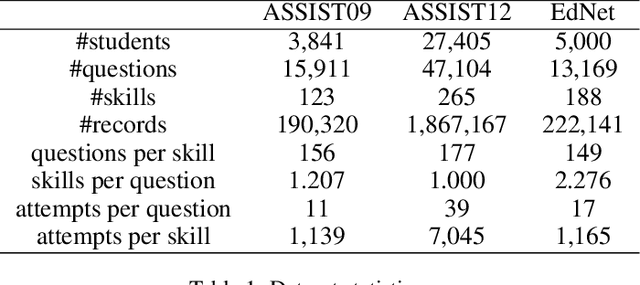
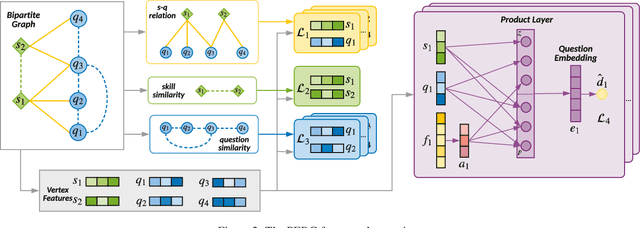
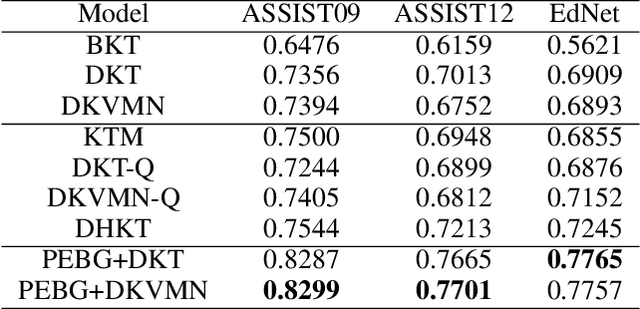
Knowledge tracing (KT) defines the task of predicting whether students can correctly answer questions based on their historical response. Although much research has been devoted to exploiting the question information, plentiful advanced information among questions and skills hasn't been well extracted, making it challenging for previous work to perform adequately. In this paper, we demonstrate that large gains on KT can be realized by pre-training embeddings for each question on abundant side information, followed by training deep KT models on the obtained embeddings. To be specific, the side information includes question difficulty and three kinds of relations contained in a bipartite graph between questions and skills. To pre-train the question embeddings, we propose to use product-based neural networks to recover the side information. As a result, adopting the pre-trained embeddings in existing deep KT models significantly outperforms state-of-the-art baselines on three common KT datasets.
Analysis of Twitter Users' Lifestyle Choices using Joint Embedding Model
May 04, 2021
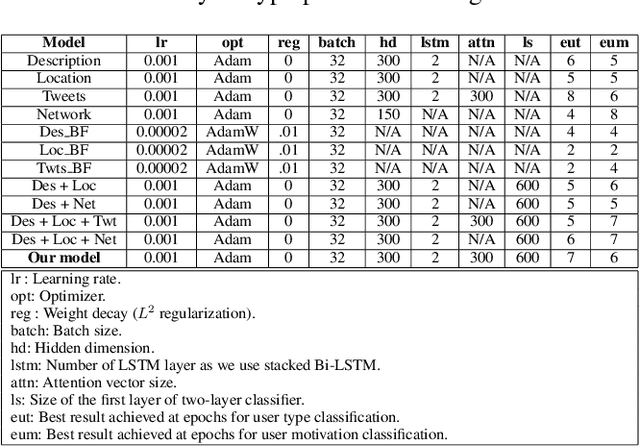
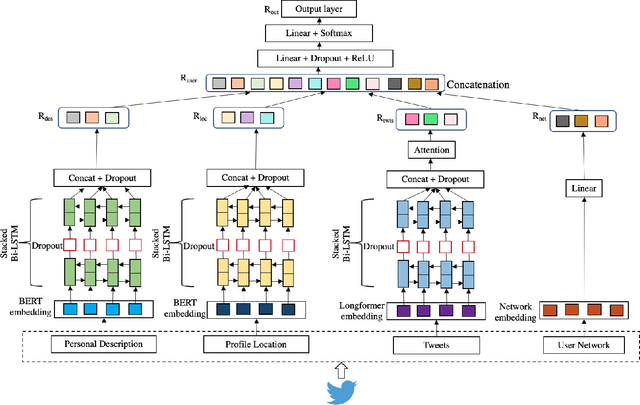
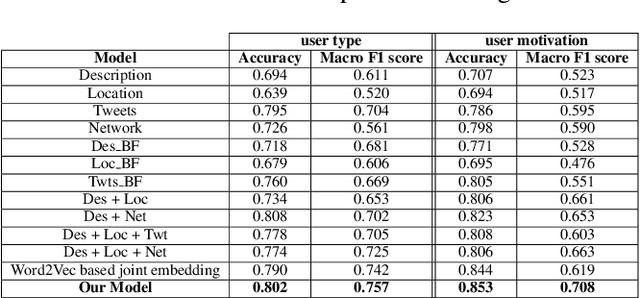
Multiview representation learning of data can help construct coherent and contextualized users' representations on social media. This paper suggests a joint embedding model, incorporating users' social and textual information to learn contextualized user representations used for understanding their lifestyle choices. We apply our model to tweets related to two lifestyle activities, `Yoga' and `Keto diet' and use it to analyze users' activity type and motivation. We explain the data collection and annotation process in detail and provide an in-depth analysis of users from different classes based on their Twitter content. Our experiments show that our model results in performance improvements in both domains.
Advanced Image Enhancement Method for Distant Vessels and Structures in Capsule Endoscopy
Apr 08, 2021
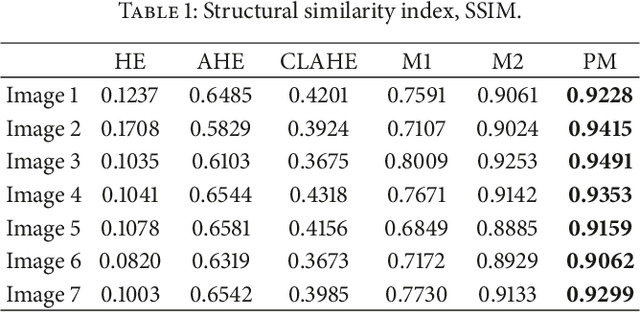
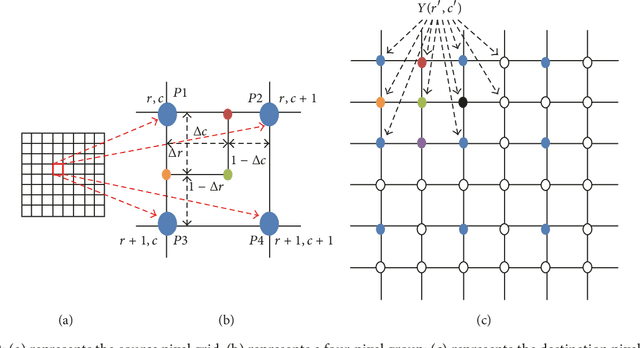
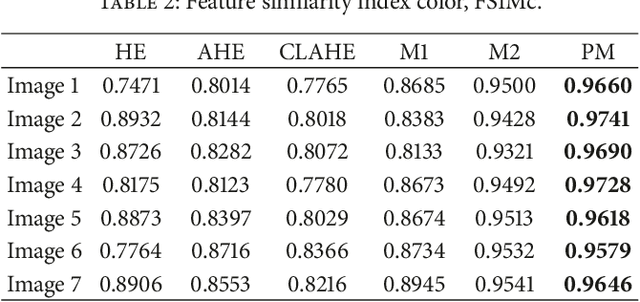
This paper proposes an advanced method for contrast enhancement of capsule endoscopic images, with the main objective to obtain sufficient information about the vessels and structures in more distant (or darker) parts of capsule endoscopic images. The proposed method (PM) combines two algorithms for the enhancement of darker and brighter areas of capsule endoscopic images, respectively. The half-unit weighted bilinear algorithm (HWB) proposed in our previous work is used to enhance darker areas according to the darker map content of its HSV's component V. Enhancement of brighter areas is achieved thanks to the novel thresholded weighted-bilinear algorithm (TWB) developed to avoid overexposure and enlargement of specular highlight spots while preserving the hue, in such areas. The TWB performs enhancement operations following a gradual increment of the brightness of the brighter map content of its HSV's component V. In other words, the TWB decreases its averaged-weights as the intensity content of the component V increases. Extensive experimental demonstrations were conducted, and based on evaluation of the reference and PM enhanced images, a gastroenterologist ({\O}H) concluded that the PM enhanced images were the best ones based on the information about the vessels, contrast in the images, and the view or visibility of the structures in more distant parts of the capsule endoscopy images.
* 8 pages, 12 figures, 4 tables
Orthonormal Product Quantization Network for Scalable Face Image Retrieval
Jul 01, 2021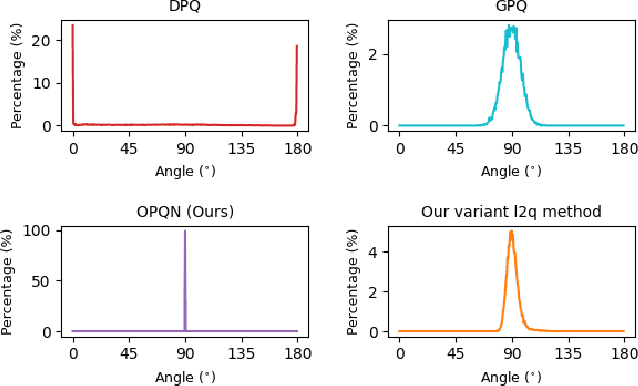
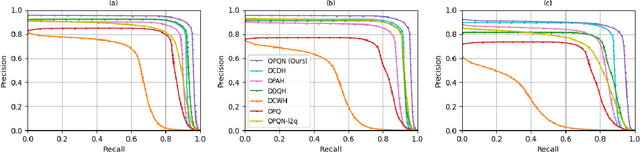
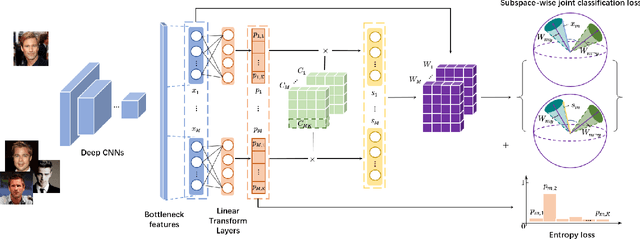
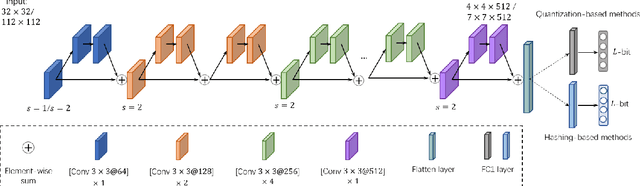
Recently, deep hashing with Hamming distance metric has drawn increasing attention for face image retrieval tasks. However, its counterpart deep quantization methods, which learn binary code representations with dictionary-related distance metrics, have seldom been explored for the task. This paper makes the first attempt to integrate product quantization into an end-to-end deep learning framework for face image retrieval. Unlike prior deep quantization methods where the codewords for quantization are learned from data, we propose a novel scheme using predefined orthonormal vectors as codewords, which aims to enhance the quantization informativeness and reduce the codewords' redundancy. To make the most of the discriminative information, we design a tailored loss function that maximizes the identity discriminability in each quantization subspace for both the quantized and the original features. Furthermore, an entropy-based regularization term is imposed to reduce the quantization error. We conduct experiments on three commonly-used datasets under the settings of both single-domain and cross-domain retrieval. It shows that the proposed method outperforms all the compared deep hashing/quantization methods under both settings with significant superiority. The proposed codewords scheme consistently improves both regular model performance and model generalization ability, verifying the importance of codewords' distribution for the quantization quality. Besides, our model's better generalization ability than deep hashing models indicates that it is more suitable for scalable face image retrieval tasks.
Fine-grained Geolocation Prediction of Tweets with Human Machine Collaboration
Jun 25, 2021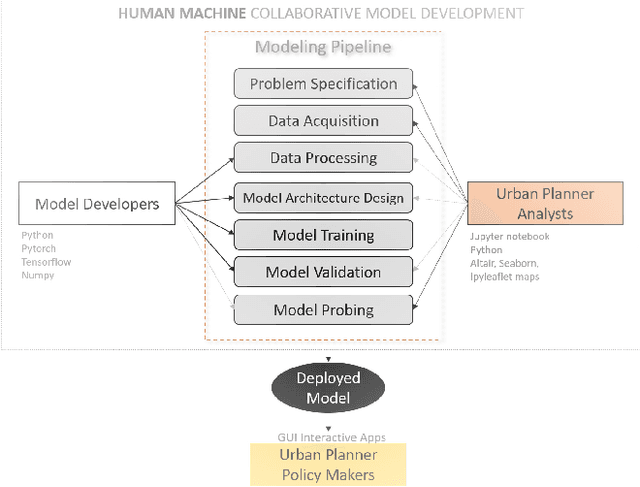
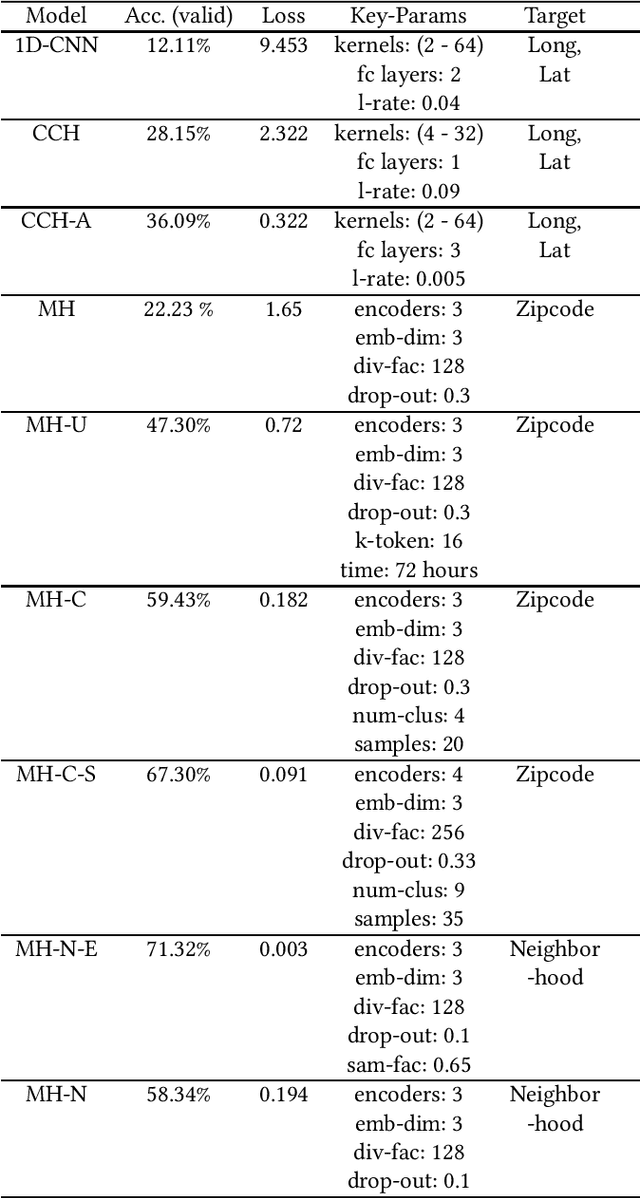
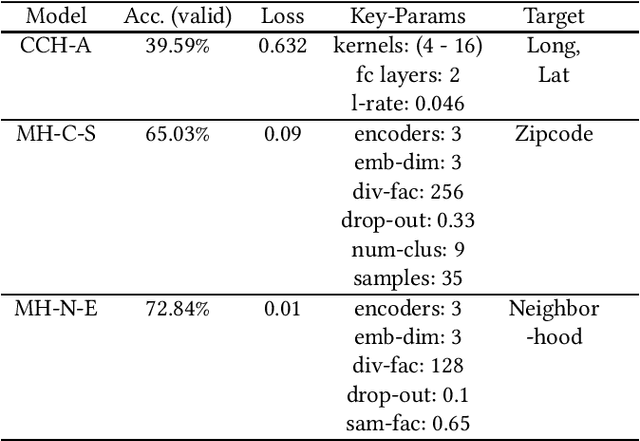
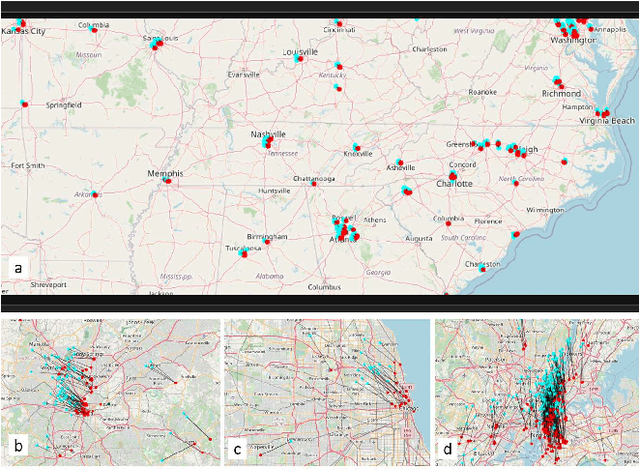
Twitter is a useful resource to analyze peoples' opinions on various topics. Often these topics are correlated or associated with locations from where these Tweet posts are made. For example, restaurant owners may need to know where their target customers eat with respect to the sentiment of the posts made related to food, policy planners may need to analyze citizens' opinion on relevant issues such as crime, safety, congestion, etc. with respect to specific parts of the city, or county or state. As promising as this is, less than $1\%$ of the crawled Tweet posts come with geolocation tags. That makes accurate prediction of Tweet posts for the non geo-tagged tweets very critical to analyze data in various domains. In this research, we utilized millions of Twitter posts and end-users domain expertise to build a set of deep neural network models using natural language processing (NLP) techniques, that predicts the geolocation of non geo-tagged Tweet posts at various level of granularities such as neighborhood, zipcode, and longitude with latitudes. With multiple neural architecture experiments, and a collaborative human-machine workflow design, our ongoing work on geolocation detection shows promising results that empower end-users to correlate relationship between variables of choice with the location information.