 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Power Minimization of Downlink Spectrum Slicing for eMBB and URLLC Users
Jun 16, 2021
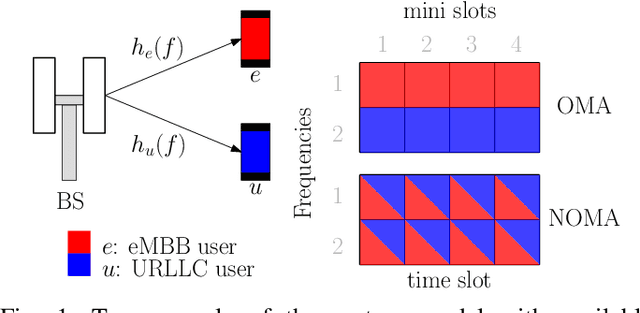
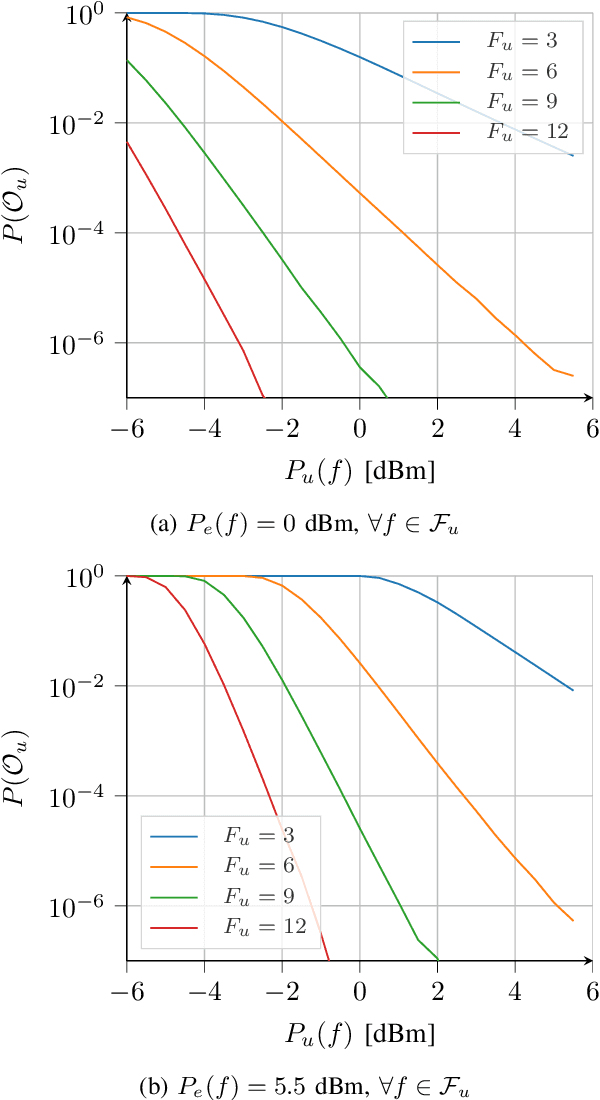
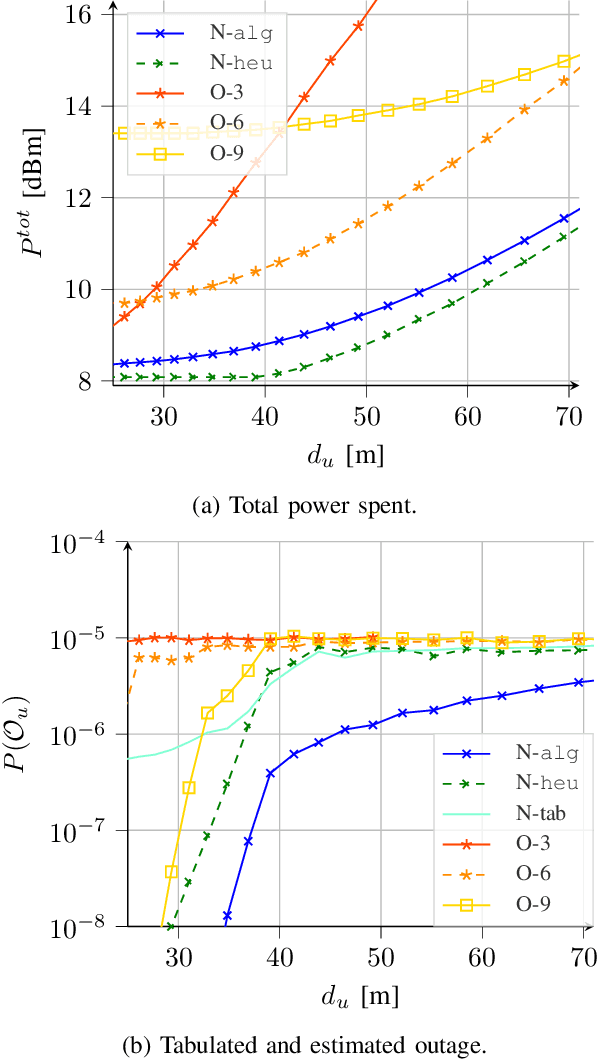
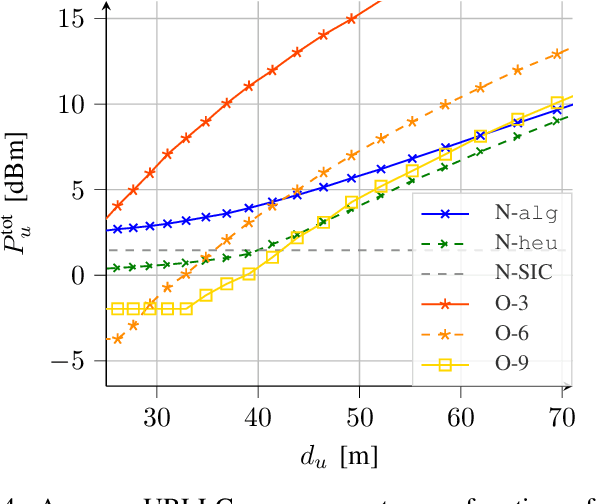
A critical task in 5G networks with heterogeneous services is spectrum slicing of the shared radio resources, through which each service gets performance guarantees. In this paper, we consider a setup in which a Base Station (BS) should serve two types of traffic in the downlink, enhanced mobile broadband (eMBB) and ultra-reliable low-latency communication (URLLC), respectively. Two resource allocation strategies are considered, non-orthogonal multiple access (NOMA) and orthogonal multiple access (OMA). A framework for power minimization is presented, in which the BS knows the channel state information (CSI) of the eMBB users only. Nevertheless, due to the resource sharing, it is shown that this knowledge can be used also to the benefit of the URLLC users. The numerical results show that NOMA leads to a lower power consumption compared to OMA for every simulation parameter under test.
Using Voice and Biofeedback to Predict User Engagement during Requirements Interviews
Apr 06, 2021


Capturing users engagement is crucial for gathering feedback about the features of a software product. In a market-driven context, current approaches to collect and analyze users feedback are based on techniques leveraging information extracted from product reviews and social media. These approaches are hardly applicable in bespoke software development, or in contexts in which one needs to gather information from specific users. In such cases, companies need to resort to face-to-face interviews to get feedback on their products. In this paper, we propose to utilize biometric data, in terms of physiological and voice features, to complement interviews with information about the engagement of the user on the discussed product-relevant topics. We evaluate our approach by interviewing users while gathering their physiological data (i.e., biofeedback) using an Empatica E4 wristband, and capturing their voice through the default audio-recorder of a common laptop. Our results show that we can predict users' engagement by training supervised machine learning algorithms on biometric data, and that voice features alone can be sufficiently effective. The performance of the prediction algorithms is maximised when pre-processing the training data with the synthetic minority oversampling technique (SMOTE). The results of our work suggest that biofeedback and voice analysis can be used to facilitate prioritization of requirements oriented to product improvement, and to steer the interview based on users' engagement. Furthermore, the usage of voice features can be particularly helpful for emotion-aware requirements elicitation in remote communication, either performed by human analysts or voice-based chatbots.
Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance
Aug 02, 2021
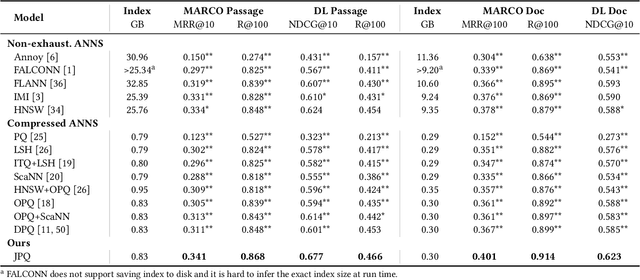
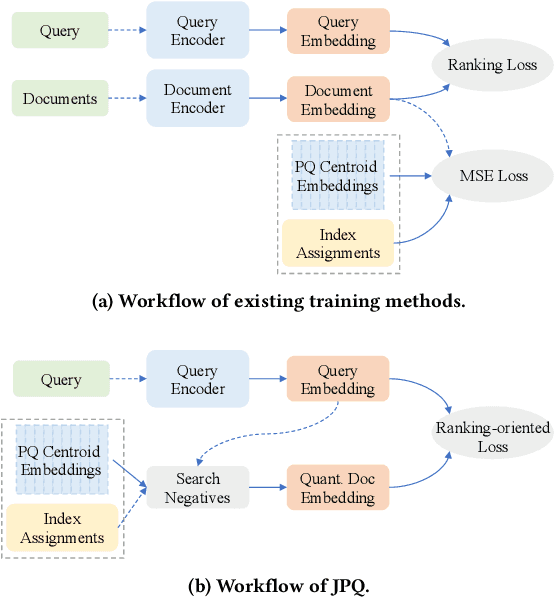
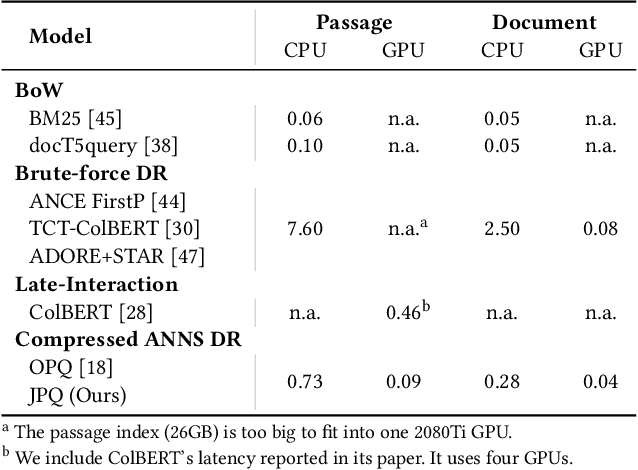
Recently, Information Retrieval community has witnessed fast-paced advances in Dense Retrieval (DR), which performs first-stage retrieval by encoding documents in a low-dimensional embedding space and querying them with embedding-based search. Despite the impressive ranking performance, previous studies usually adopt brute-force search to acquire candidates, which is prohibitive in practical Web search scenarios due to its tremendous memory usage and time cost. To overcome these problems, vector compression methods, a branch of Approximate Nearest Neighbor Search (ANNS), have been adopted in many practical embedding-based retrieval applications. One of the most popular methods is Product Quantization (PQ). However, although existing vector compression methods including PQ can help improve the efficiency of DR, they incur severely decayed retrieval performance due to the separation between encoding and compression. To tackle this problem, we present JPQ, which stands for Joint optimization of query encoding and Product Quantization. It trains the query encoder and PQ index jointly in an end-to-end manner based on three optimization strategies, namely ranking-oriented loss, PQ centroid optimization, and end-to-end negative sampling. We evaluate JPQ on two publicly available retrieval benchmarks. Experimental results show that JPQ significantly outperforms existing popular vector compression methods in terms of different trade-off settings. Compared with previous DR models that use brute-force search, JPQ almost matches the best retrieval performance with 30x compression on index size. The compressed index further brings 10x speedup on CPU and 2x speedup on GPU in query latency.
Optical Tactile Sim-to-Real Policy Transfer via Real-to-Sim Tactile Image Translation
Jun 16, 2021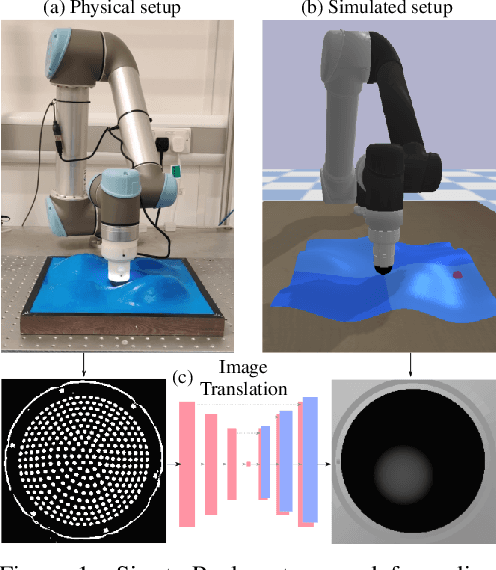

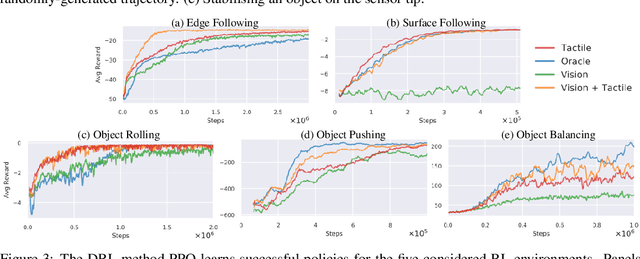

Simulation has recently become key for deep reinforcement learning to safely and efficiently acquire general and complex control policies from visual and proprioceptive inputs. Tactile information is not usually considered despite its direct relation to environment interaction. In this work, we present a suite of simulated environments tailored towards tactile robotics and reinforcement learning. A simple and fast method of simulating optical tactile sensors is provided, where high-resolution contact geometry is represented as depth images. Proximal Policy Optimisation (PPO) is used to learn successful policies across all considered tasks. A data-driven approach enables translation of the current state of a real tactile sensor to corresponding simulated depth images. This policy is implemented within a real-time control loop on a physical robot to demonstrate zero-shot sim-to-real policy transfer on several physically-interactive tasks requiring a sense of touch.
Low-cost Stereovision system (disparity map) for few dollars
Jun 02, 2021


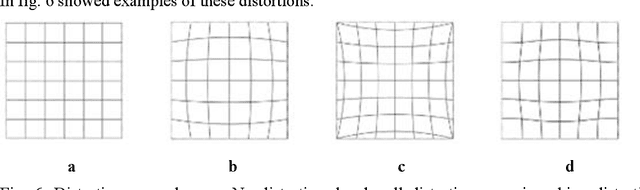
The paper presents an analysis of the latest developments in the field of stereo vision in the low-cost segment, both for prototypes and for industrial designs. We described the theory of stereo vision and presented information about cameras and data transfer protocols and their compatibility with various devices. The theory in the field of image processing for stereo vision processes is considered and the calibration process is described in detail. Ultimately, we presented the developed stereo vision system and provided the main points that need to be considered when developing such systems. The final, we presented software for adjusting stereo vision parameters in real-time in the python language in the Windows operating system.
CAR-Net: Unsupervised Co-Attention Guided Registration Network for Joint Registration and Structure Learning
Jun 11, 2021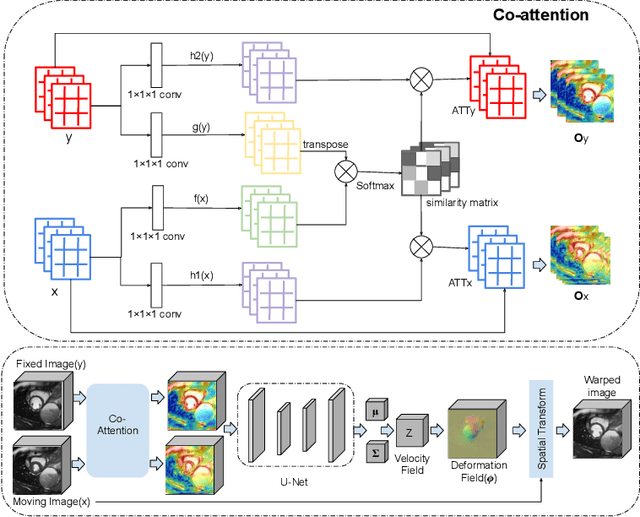
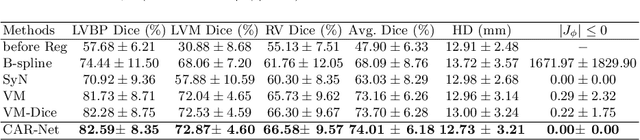
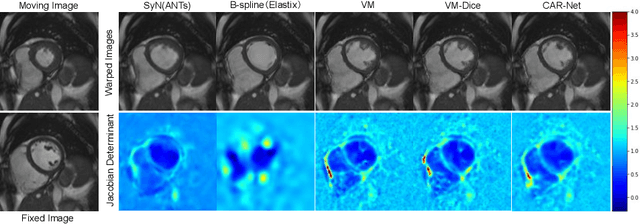
Image registration is a fundamental building block for various applications in medical image analysis. To better explore the correlation between the fixed and moving images and improve registration performance, we propose a novel deep learning network, Co-Attention guided Registration Network (CAR-Net). CAR-Net employs a co-attention block to learn a new representation of the inputs, which drives the registration of the fixed and moving images. Experiments on UK Biobank cardiac cine-magnetic resonance image data demonstrate that CAR-Net obtains higher registration accuracy and smoother deformation fields than state-of-the-art unsupervised registration methods, while achieving comparable or better registration performance than corresponding weakly-supervised variants. In addition, our approach can provide critical structural information of the input fixed and moving images simultaneously in a completely unsupervised manner.
Lifelong Teacher-Student Network Learning
Jul 09, 2021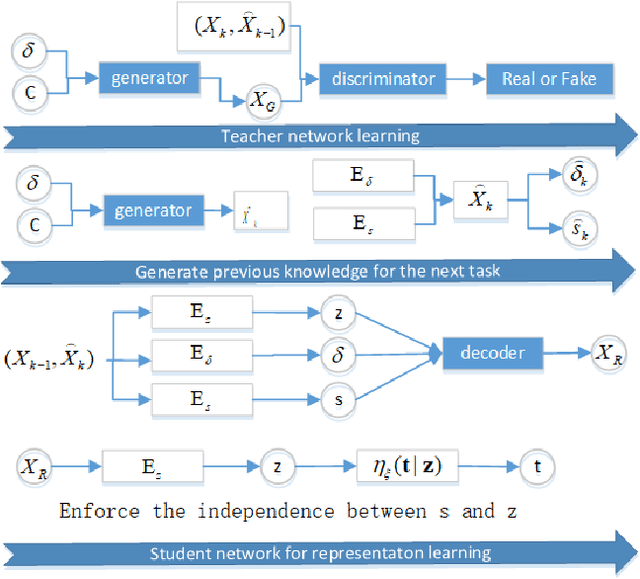

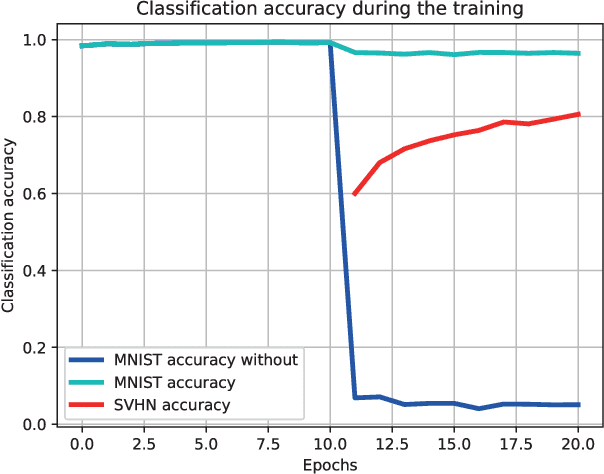
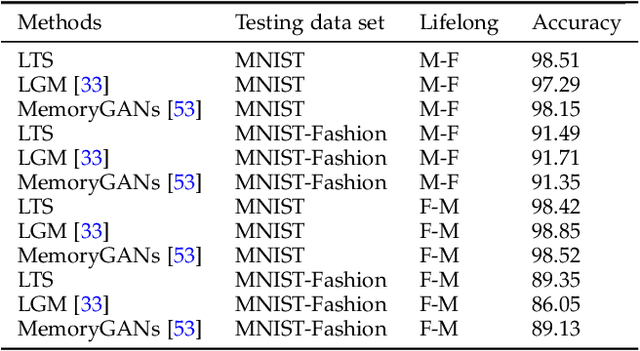
A unique cognitive capability of humans consists in their ability to acquire new knowledge and skills from a sequence of experiences. Meanwhile, artificial intelligence systems are good at learning only the last given task without being able to remember the databases learnt in the past. We propose a novel lifelong learning methodology by employing a Teacher-Student network framework. While the Student module is trained with a new given database, the Teacher module would remind the Student about the information learnt in the past. The Teacher, implemented by a Generative Adversarial Network (GAN), is trained to preserve and replay past knowledge corresponding to the probabilistic representations of previously learn databases. Meanwhile, the Student module is implemented by a Variational Autoencoder (VAE) which infers its latent variable representation from both the output of the Teacher module as well as from the newly available database. Moreover, the Student module is trained to capture both continuous and discrete underlying data representations across different domains. The proposed lifelong learning framework is applied in supervised, semi-supervised and unsupervised training. The code is available~: \url{https://github.com/dtuzi123/Lifelong-Teacher-Student-Network-Learning}
On the information in spike timing: neural codes derived from polychronous groups
Mar 09, 2018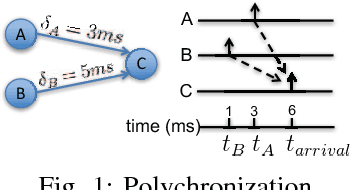
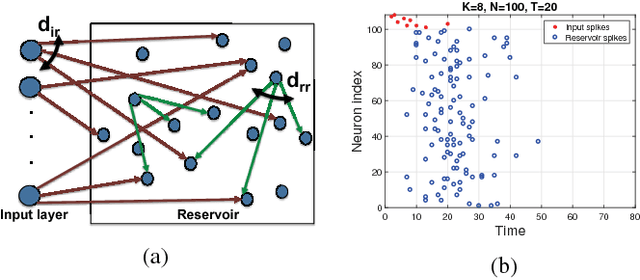
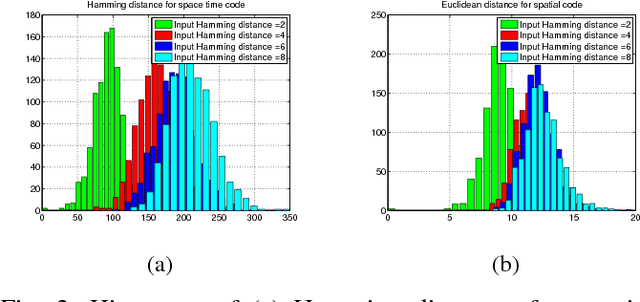
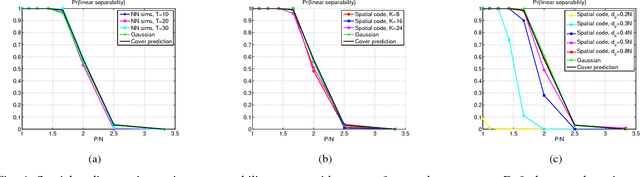
There is growing evidence regarding the importance of spike timing in neural information processing, with even a small number of spikes carrying information, but computational models lag significantly behind those for rate coding. Experimental evidence on neuronal behavior is consistent with the dynamical and state dependent behavior provided by recurrent connections. This motivates the minimalistic abstraction investigated in this paper, aimed at providing insight into information encoding in spike timing via recurrent connections. We employ information-theoretic techniques for a simple reservoir model which encodes input spatiotemporal patterns into a sparse neural code, translating the polychronous groups introduced by Izhikevich into codewords on which we can perform standard vector operations. We show that the distance properties of the code are similar to those for (optimal) random codes. In particular, the code meets benchmarks associated with both linear classification and capacity, with the latter scaling exponentially with reservoir size.
Unsupervised Super-Resolution of Satellite Imagery for High Fidelity Material Label Transfer
May 16, 2021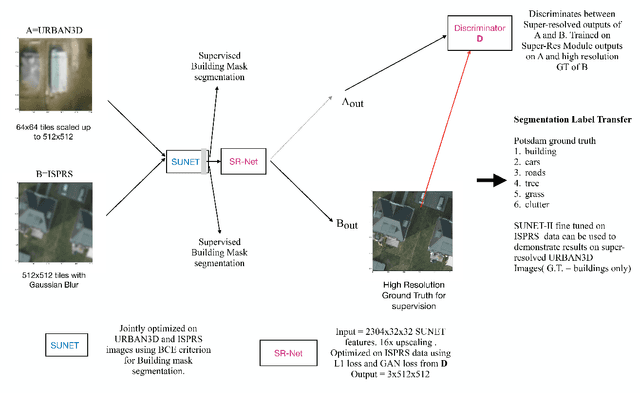


Urban material recognition in remote sensing imagery is a highly relevant, yet extremely challenging problem due to the difficulty of obtaining human annotations, especially on low resolution satellite images. To this end, we propose an unsupervised domain adaptation based approach using adversarial learning. We aim to harvest information from smaller quantities of high resolution data (source domain) and utilize the same to super-resolve low resolution imagery (target domain). This can potentially aid in semantic as well as material label transfer from a richly annotated source to a target domain.
* Published in the proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium
HinDom: A Robust Malicious Domain Detection System based on Heterogeneous Information Network with Transductive Classification
Sep 04, 2019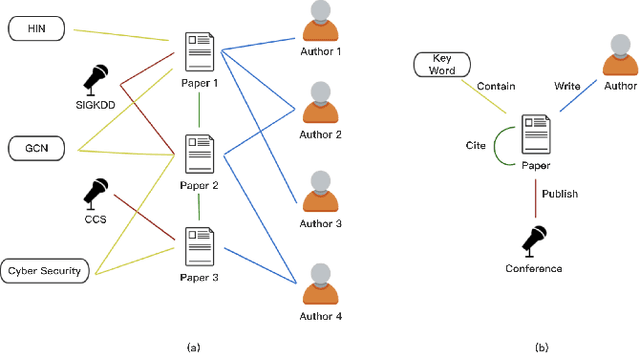

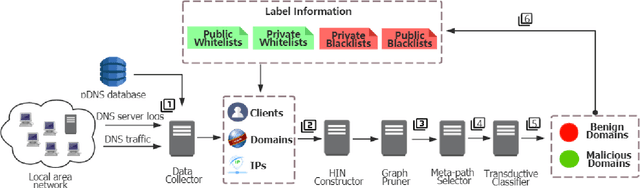

Domain name system (DNS) is a crucial part of the Internet, yet has been widely exploited by cyber attackers. Apart from making static methods like blacklists or sinkholes infeasible, some weasel attackers can even bypass detection systems with machine learning based classifiers. As a solution to this problem, we propose a robust domain detection system named HinDom. Instead of relying on manually selected features, HinDom models the DNS scene as a Heterogeneous Information Network (HIN) consist of clients, domains, IP addresses and their diverse relationships. Besides, the metapath-based transductive classification method enables HinDom to detect malicious domains with only a small fraction of labeled samples. So far as we know, this is the first work to apply HIN in DNS analysis. We build a prototype of HinDom and evaluate it in CERNET2 and TUNET. The results reveal that HinDom is accurate, robust and can identify previously unknown malicious domains.