 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adaptive wavelet distillation from neural networks through interpretations
Jul 19, 2021
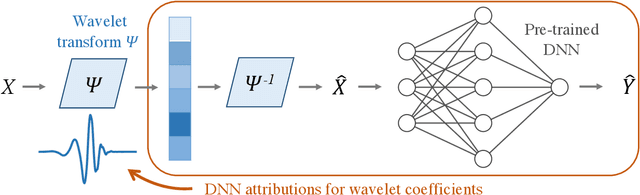

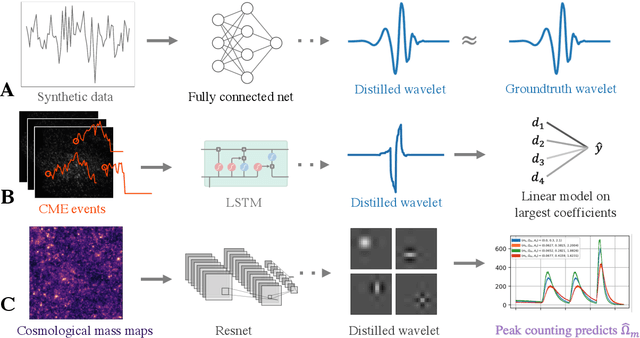

Recent deep-learning models have achieved impressive prediction performance, but often sacrifice interpretability and computational efficiency. Interpretability is crucial in many disciplines, such as science and medicine, where models must be carefully vetted or where interpretation is the goal itself. Moreover, interpretable models are concise and often yield computational efficiency. Here, we propose adaptive wavelet distillation (AWD), a method which aims to distill information from a trained neural network into a wavelet transform. Specifically, AWD penalizes feature attributions of a neural network in the wavelet domain to learn an effective multi-resolution wavelet transform. The resulting model is highly predictive, concise, computationally efficient, and has properties (such as a multi-scale structure) which make it easy to interpret. In close collaboration with domain experts, we showcase how AWD addresses challenges in two real-world settings: cosmological parameter inference and molecular-partner prediction. In both cases, AWD yields a scientifically interpretable and concise model which gives predictive performance better than state-of-the-art neural networks. Moreover, AWD identifies predictive features that are scientifically meaningful in the context of respective domains. All code and models are released in a full-fledged package available on Github (https://github.com/Yu-Group/adaptive-wavelets).
Optimizing the Long-Term Average Reward for Continuing MDPs: A Technical Report
Apr 13, 2021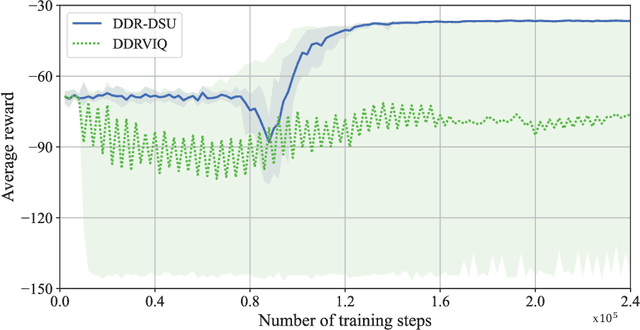
Recently, we have shaken the balance between the information freshness, in terms of age of information (AoI), experienced by users and energy consumed by sensors, by appropriately activating sensors to update their current status in caching enabled Internet of Things (IoT) networks [1]. To solve this problem, we cast the corresponding status update procedure as a continuing Markov Decision Process (MDP) (i.e., without termination states), where the number of state-action pairs increases exponentially with respect to the number of considered sensors and users. Moreover, to circumvent the curse of dimensionality, we have established a methodology for designing deep reinforcement learning (DRL) algorithms to maximize (resp. minimize) the average reward (resp. cost), by integrating R-learning, a tabular reinforcement learning (RL) algorithm tailored for maximizing the long-term average reward, and traditional DRL algorithms, initially developed to optimize the discounted long-term cumulative reward rather the average one. In this technical report, we would present detailed discussions on the technical contributions of this methodology.
Fast approximations of the Jeffreys divergence between univariate Gaussian mixture models via exponential polynomial densities
Jul 13, 2021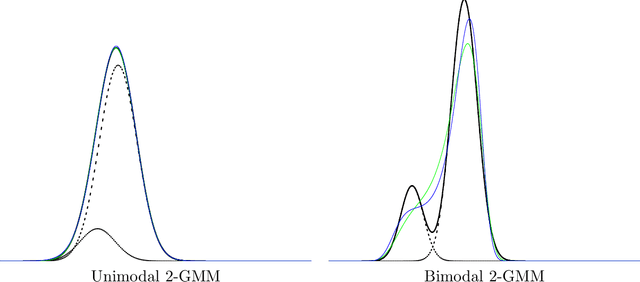
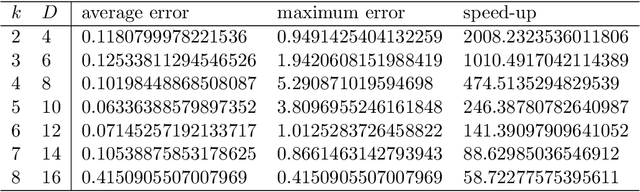

The Jeffreys divergence is a renown symmetrization of the statistical Kullback-Leibler divergence which is often used in machine learning, signal processing, and information sciences. Since the Jeffreys divergence between the ubiquitous Gaussian Mixture Models are not available in closed-form, many techniques with various pros and cons have been proposed in the literature to either (i) estimate, (ii) approximate, or (iii) lower and upper bound this divergence. In this work, we propose a simple yet fast heuristic to approximate the Jeffreys divergence between two GMMs of arbitrary number of components. The heuristic relies on converting GMMs into pairs of dually parameterized probability densities belonging to exponential families. In particular, we consider Polynomial Exponential Densities, and design a goodness-of-fit criterion to measure the dissimilarity between a GMM and a PED which is a generalization of the Hyv\"arinen divergence. This criterion allows one to select the orders of the PEDs to approximate the GMMs. We demonstrate experimentally that the computational time of our heuristic improves over the stochastic Monte Carlo estimation baseline by several orders of magnitude while approximating reasonably well the Jeffreys divergence, specially when the univariate mixtures have a small number of modes.
Interflow: Aggregating Multi-layer Feature Mappings with Attention Mechanism
Jul 13, 2021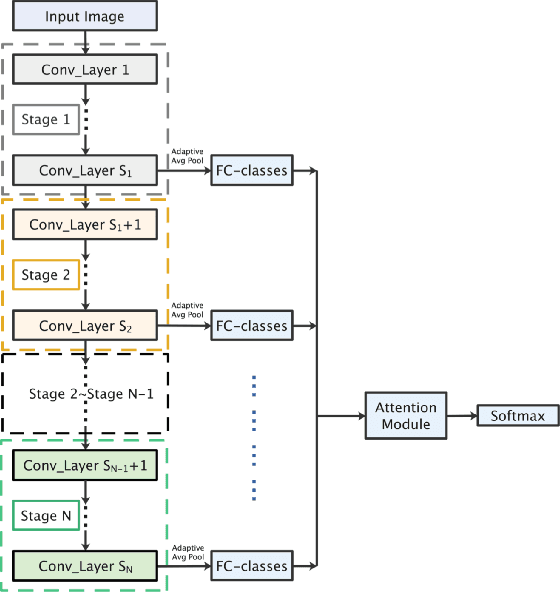
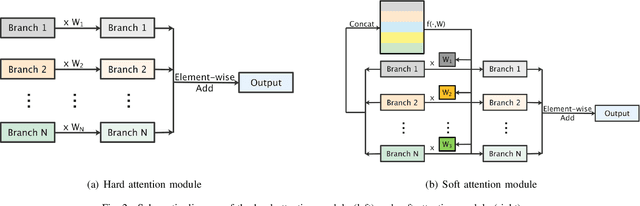
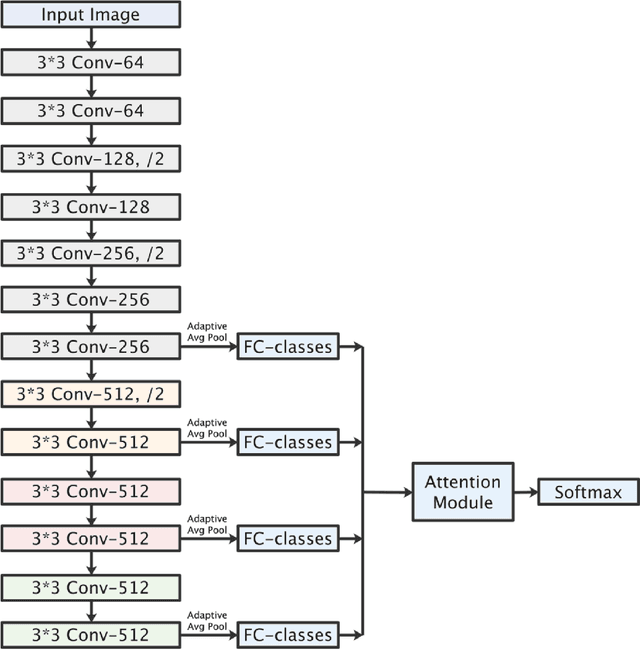
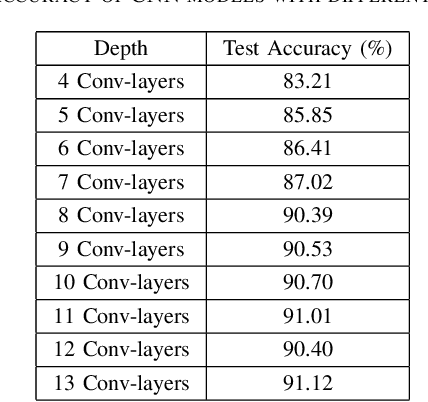
Traditionally, CNN models possess hierarchical structures and utilize the feature mapping of the last layer to obtain the prediction output. However, it can be difficulty to settle the optimal network depth and make the middle layers learn distinguished features. This paper proposes the Interflow algorithm specially for traditional CNN models. Interflow divides CNNs into several stages according to the depth and makes predictions by the feature mappings in each stage. Subsequently, we input these prediction branches into a well-designed attention module, which learns the weights of these prediction branches, aggregates them and obtains the final output. Interflow weights and fuses the features learned in both shallower and deeper layers, making the feature information at each stage processed reasonably and effectively, enabling the middle layers to learn more distinguished features, and enhancing the model representation ability. In addition, Interflow can alleviate gradient vanishing problem, lower the difficulty of network depth selection, and lighten possible over-fitting problem by introducing attention mechanism. Besides, it can avoid network degradation as a byproduct. Compared with the original model, the CNN model with Interflow achieves higher test accuracy on multiple benchmark datasets.
Contrast-enhanced MRI Synthesis Using 3D High-Resolution ConvNets
Apr 04, 2021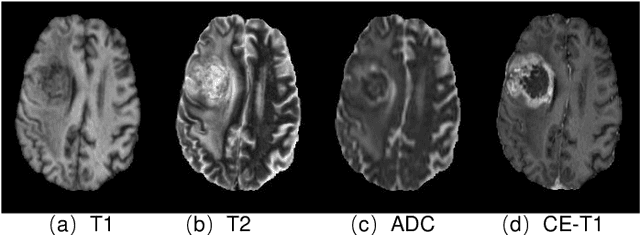
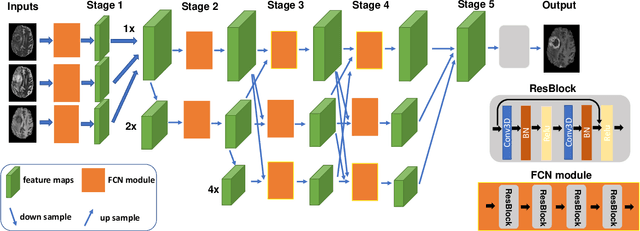
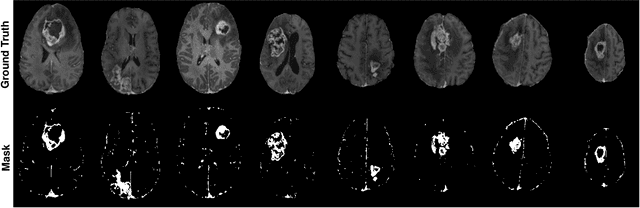
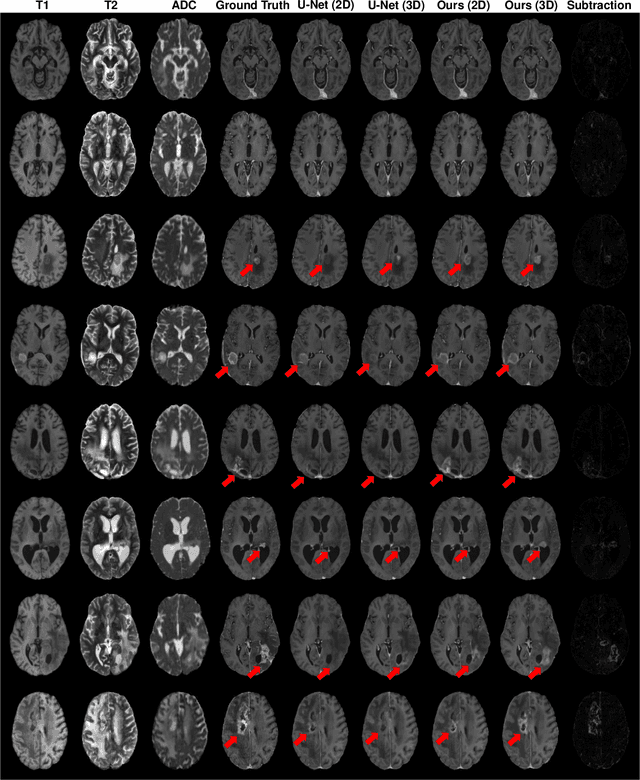
Gadolinium-based contrast agents (GBCAs) have been widely used to better visualize disease in brain magnetic resonance imaging (MRI). However, gadolinium deposition within the brain and body has raised safety concerns about the use of GBCAs. Therefore, the development of novel approaches that can decrease or even eliminate GBCA exposure while providing similar contrast information would be of significant use clinically. For brain tumor patients, standard-of-care includes repeated MRI with gadolinium-based contrast for disease monitoring, increasing the risk of gadolinium deposition. In this work, we present a deep learning based approach for contrast-enhanced T1 synthesis on brain tumor patients. A 3D high-resolution fully convolutional network (FCN), which maintains high resolution information through processing and aggregates multi-scale information in parallel, is designed to map pre-contrast MRI sequences to contrast-enhanced MRI sequences. Specifically, three pre-contrast MRI sequences, T1, T2 and apparent diffusion coefficient map (ADC), are utilized as inputs and the post-contrast T1 sequences are utilized as target output. To alleviate the data imbalance problem between normal tissues and the tumor regions, we introduce a local loss to improve the contribution of the tumor regions, which leads to better enhancement results on tumors. Extensive quantitative and visual assessments are performed, with our proposed model achieving a PSNR of 28.24dB in the brain and 21.2dB in tumor regions. Our results suggests the potential of substituting GBCAs with synthetic contrast images generated via deep learning.
Overview of BioASQ 2020: The eighth BioASQ challenge on Large-Scale Biomedical Semantic Indexing and Question Answering
Jun 28, 2021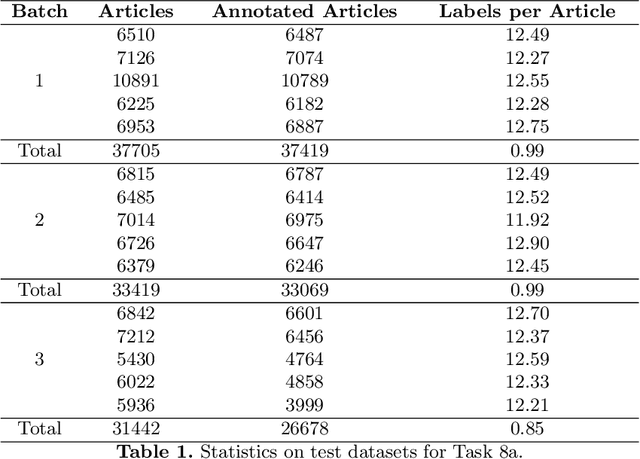

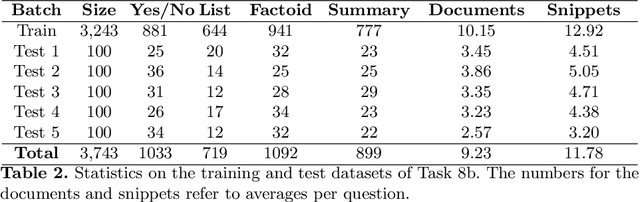
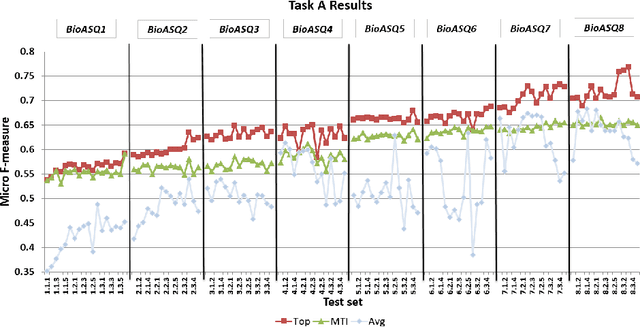
In this paper, we present an overview of the eighth edition of the BioASQ challenge, which ran as a lab in the Conference and Labs of the Evaluation Forum (CLEF) 2020. BioASQ is a series of challenges aiming at the promotion of systems and methodologies for large-scale biomedical semantic indexing and question answering. To this end, shared tasks are organized yearly since 2012, where different teams develop systems that compete on the same demanding benchmark datasets that represent the real information needs of experts in the biomedical domain. This year, the challenge has been extended with the introduction of a new task on medical semantic indexing in Spanish. In total, 34 teams with more than 100 systems participated in the three tasks of the challenge. As in previous years, the results of the evaluation reveal that the top-performing systems managed to outperform the strong baselines, which suggests that state-of-the-art systems keep pushing the frontier of research through continuous improvements.
* 21 pages, 10 tables, 3 figures
SSMix: Saliency-Based Span Mixup for Text Classification
Jun 15, 2021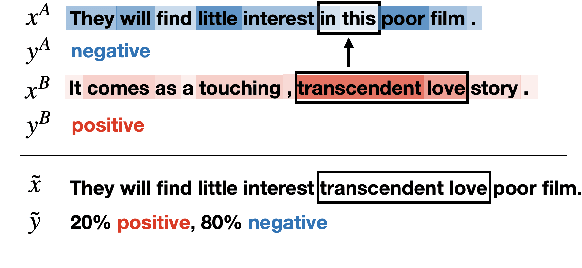
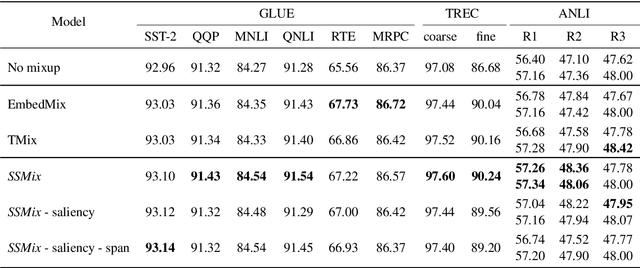
Data augmentation with mixup has shown to be effective on various computer vision tasks. Despite its great success, there has been a hurdle to apply mixup to NLP tasks since text consists of discrete tokens with variable length. In this work, we propose SSMix, a novel mixup method where the operation is performed on input text rather than on hidden vectors like previous approaches. SSMix synthesizes a sentence while preserving the locality of two original texts by span-based mixing and keeping more tokens related to the prediction relying on saliency information. With extensive experiments, we empirically validate that our method outperforms hidden-level mixup methods on a wide range of text classification benchmarks, including textual entailment, sentiment classification, and question-type classification. Our code is available at https://github.com/clovaai/ssmix.
Spatio-Temporal Matching for Siamese Visual Tracking
May 06, 2021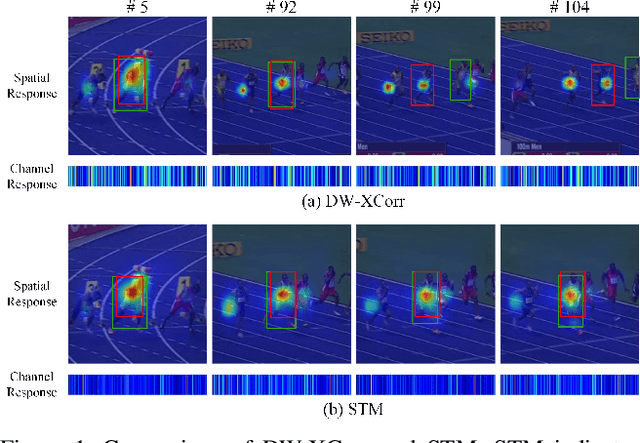
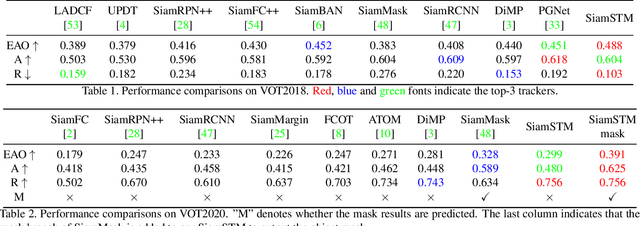
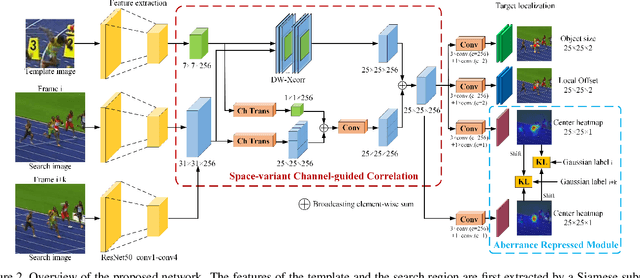
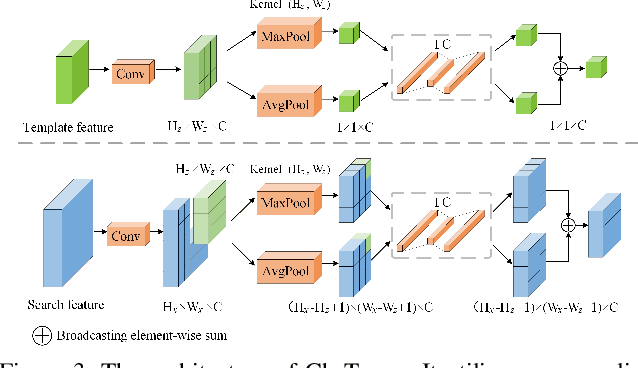
Similarity matching is a core operation in Siamese trackers. Most Siamese trackers carry out similarity learning via cross correlation that originates from the image matching field. However, unlike 2-D image matching, the matching network in object tracking requires 4-D information (height, width, channel and time). Cross correlation neglects the information from channel and time dimensions, and thus produces ambiguous matching. This paper proposes a spatio-temporal matching process to thoroughly explore the capability of 4-D matching in space (height, width and channel) and time. In spatial matching, we introduce a space-variant channel-guided correlation (SVC-Corr) to recalibrate channel-wise feature responses for each spatial location, which can guide the generation of the target-aware matching features. In temporal matching, we investigate the time-domain context relations of the target and the background and develop an aberrance repressed module (ARM). By restricting the abrupt alteration in the interframe response maps, our ARM can clearly suppress aberrances and thus enables more robust and accurate object tracking. Furthermore, a novel anchor-free tracking framework is presented to accommodate these innovations. Experiments on challenging benchmarks including OTB100, VOT2018, VOT2020, GOT-10k, and LaSOT demonstrate the state-of-the-art performance of the proposed method.
Emotions in Macroeconomic News and their Impact on the European Bond Market
Jun 15, 2021
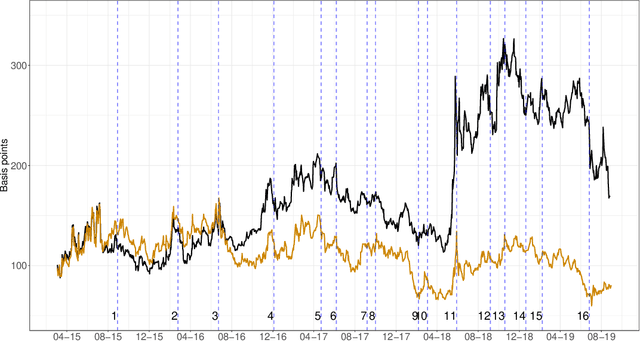
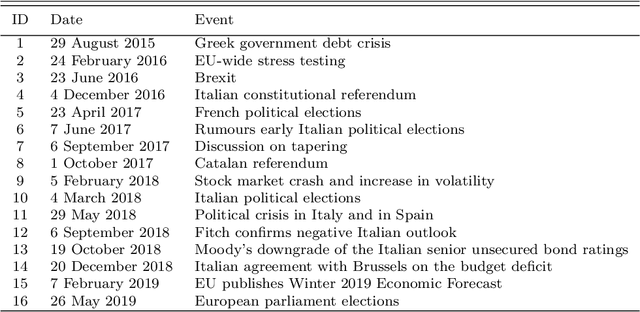
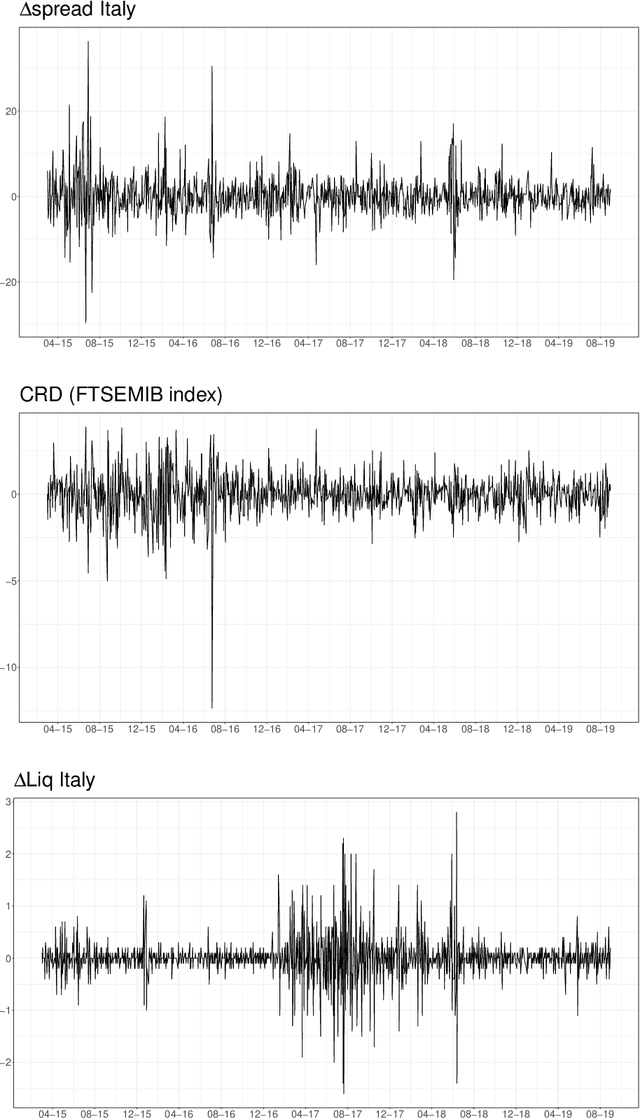
We show how emotions extracted from macroeconomic news can be used to explain and forecast future behaviour of sovereign bond yield spreads in Italy and Spain. We use a big, open-source, database known as Global Database of Events, Language and Tone to construct emotion indicators of bond market affective states. We find that negative emotions extracted from news improve the forecasting power of government yield spread models during distressed periods even after controlling for the number of negative words present in the text. In addition, stronger negative emotions, such as panic, reveal useful information for predicting changes in spread at the short-term horizon, while milder emotions, such as distress, are useful at longer time horizons. Emotions generated by the Italian political turmoil propagate to the Spanish news affecting this neighbourhood market.
A Graph Neural Network Approach for Product Relationship Prediction
May 12, 2021
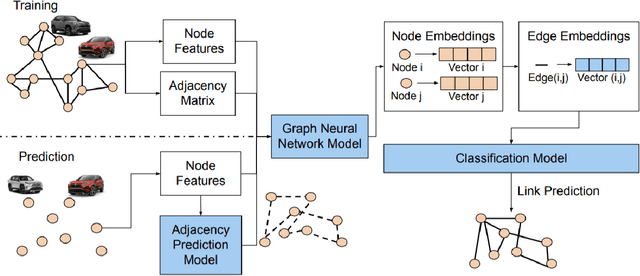
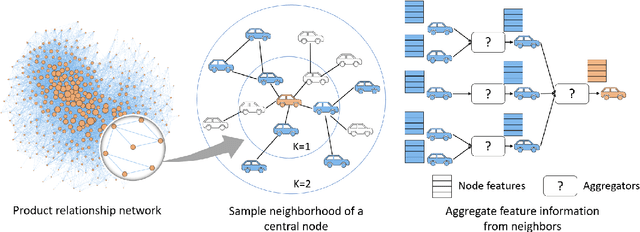
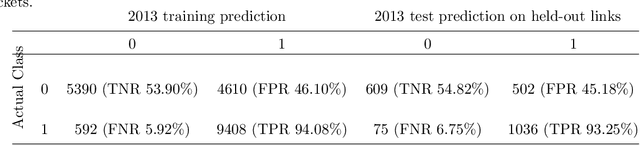
Graph Neural Networks have revolutionized many machine learning tasks in recent years, ranging from drug discovery, recommendation systems, image classification, social network analysis to natural language understanding. This paper shows their efficacy in modeling relationships between products and making predictions for unseen product networks. By representing products as nodes and their relationships as edges of a graph, we show how an inductive graph neural network approach, named GraphSAGE, can efficiently learn continuous representations for nodes and edges. These representations also capture product feature information such as price, brand, or engineering attributes. They are combined with a classification model for predicting the existence of the relationship between products. Using a case study of the Chinese car market, we find that our method yields double the prediction performance compared to an Exponential Random Graph Model-based method for predicting the co-consideration relationship between cars. While a vanilla GraphSAGE requires a partial network to make predictions, we introduce an `adjacency prediction model' to circumvent this limitation. This enables us to predict product relationships when no neighborhood information is known. Finally, we demonstrate how a permutation-based interpretability analysis can provide insights on how design attributes impact the predictions of relationships between products. This work provides a systematic method to predict the relationships between products in many different markets.