 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Fast Graph Kernel Based Classification Method for Wireless Link Scheduling on Riemannian Manifold
Jun 25, 2021
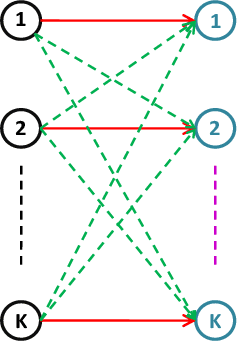
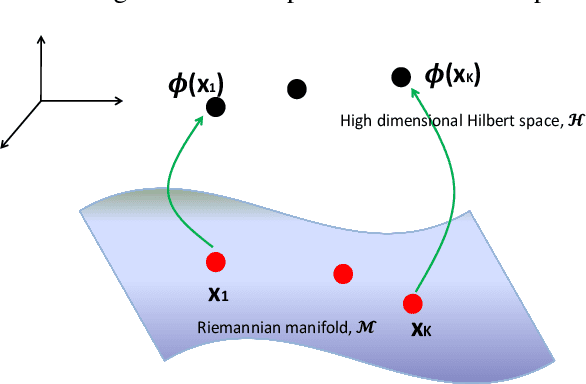
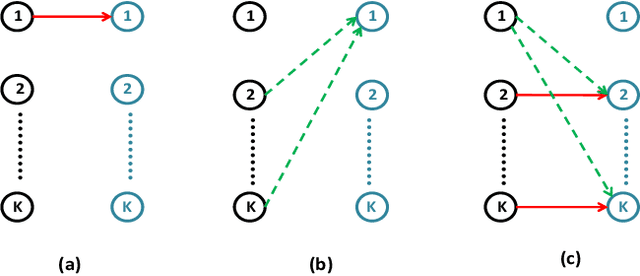
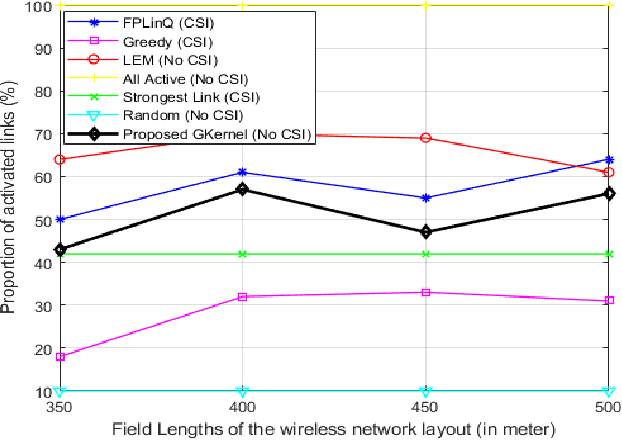
In this paper, we propose a novel graph kernel method for the wireless link scheduling problem in device-to-device (D2D) networks on Riemannian manifold. The link scheduling problem can be considered as a binary classification problem since each D2D pair can only hold the state active or inactive. Our goal is to learn a novel metric that facilitates the design of an efficient but less computationally demanding machine learning (ML) solution for the binary classification task of link scheduling problem that requires no channel state information (CSI) and a fewer number of training samples as opposed to other benchmark ML algorithms. To this aim, we first represent the wireless D2D network as a graph and model the features of each D2D pair, including its communication and interference links, as regularized (i.e., positively-shifted) Laplacian matrices which are symmetric positive definite (SPD) one. By doing so, we represent the feature information of each D2D pair as a point on the SPD manifold, and we analyze the topology through Riemannian geometry. We compute the Riemannian metric, e.g., Log-Euclidean metric (LEM), which are suitable distance measures between the regularized Laplacian matrices. The LEM is then utilized to define a positive definite graph kernel for the binary classification of the link scheduling decisions. Simulation results demonstrate that the proposed graph Kernel-based method is computationally less demanding and achieves a sum rate of more than 95% of benchmark algorithm FPLinQ [1] for 10 D2D pairs without using CSI and less than a hundred training network layouts.
Differentiable Particle Filters through Conditional Normalizing Flow
Jul 01, 2021
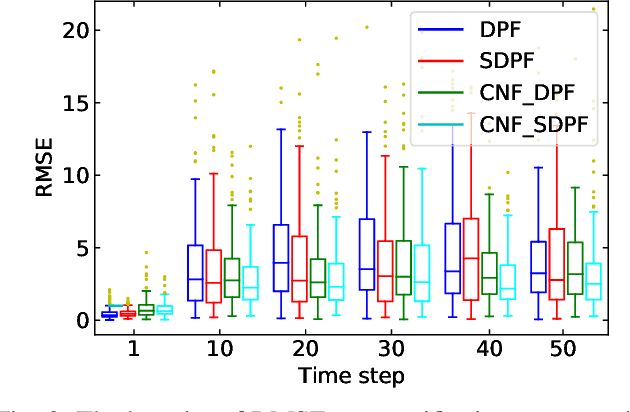
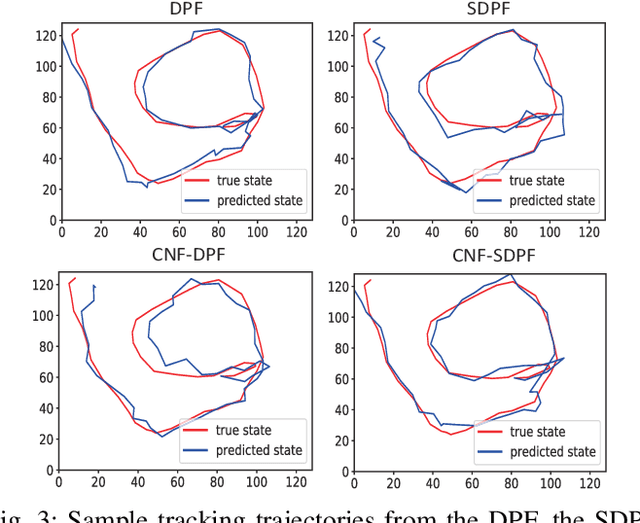
Differentiable particle filters provide a flexible mechanism to adaptively train dynamic and measurement models by learning from observed data. However, most existing differentiable particle filters are within the bootstrap particle filtering framework and fail to incorporate the information from latest observations to construct better proposals. In this paper, we utilize conditional normalizing flows to construct proposal distributions for differentiable particle filters, enriching the distribution families that the proposal distributions can represent. In addition, normalizing flows are incorporated in the construction of the dynamic model, resulting in a more expressive dynamic model. We demonstrate the performance of the proposed conditional normalizing flow-based differentiable particle filters in a visual tracking task.
Recursive Fusion and Deformable Spatiotemporal Attention for Video Compression Artifact Reduction
Aug 04, 2021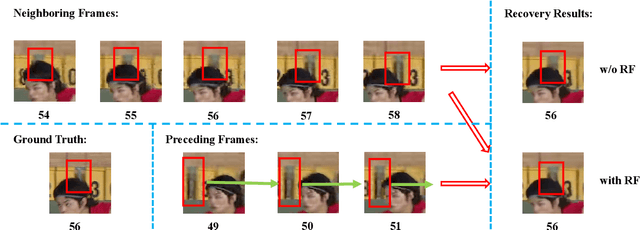
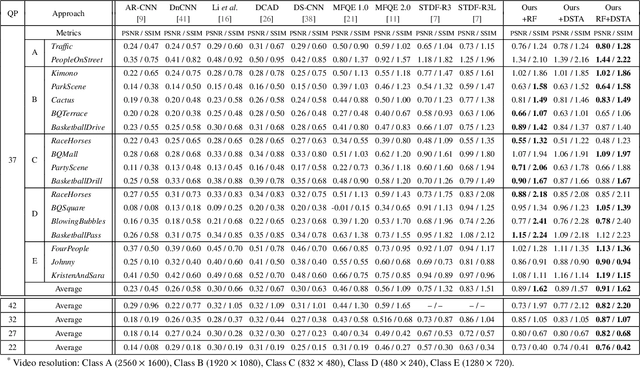
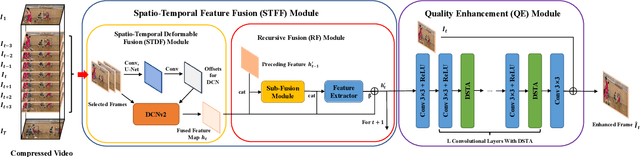
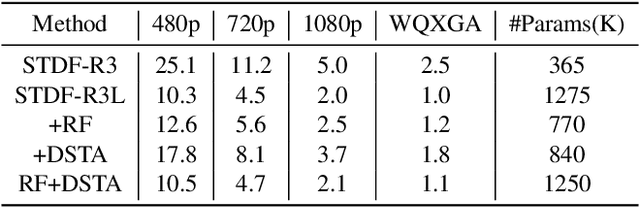
A number of deep learning based algorithms have been proposed to recover high-quality videos from low-quality compressed ones. Among them, some restore the missing details of each frame via exploring the spatiotemporal information of neighboring frames. However, these methods usually suffer from a narrow temporal scope, thus may miss some useful details from some frames outside the neighboring ones. In this paper, to boost artifact removal, on the one hand, we propose a Recursive Fusion (RF) module to model the temporal dependency within a long temporal range. Specifically, RF utilizes both the current reference frames and the preceding hidden state to conduct better spatiotemporal compensation. On the other hand, we design an efficient and effective Deformable Spatiotemporal Attention (DSTA) module such that the model can pay more effort on restoring the artifact-rich areas like the boundary area of a moving object. Extensive experiments show that our method outperforms the existing ones on the MFQE 2.0 dataset in terms of both fidelity and perceptual effect. Code is available at https://github.com/zhaominyiz/RFDA-PyTorch.
CTNet: Context-based Tandem Network for Semantic Segmentation
Apr 20, 2021
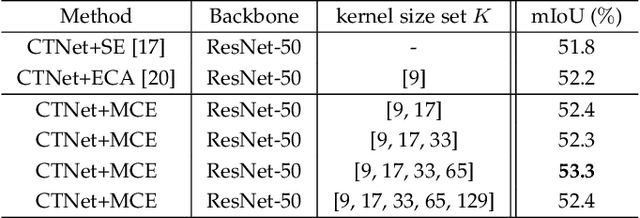
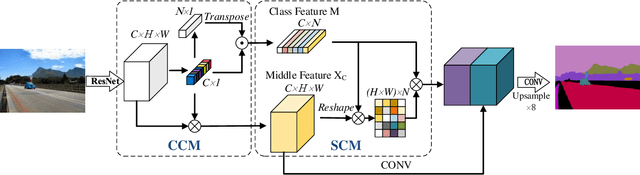
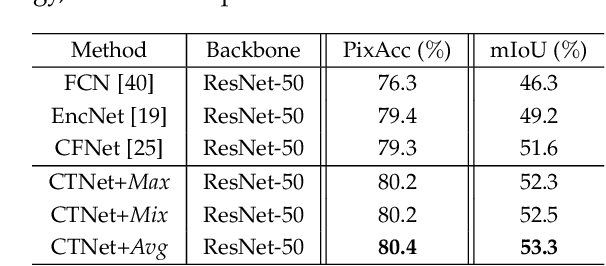
Contextual information has been shown to be powerful for semantic segmentation. This work proposes a novel Context-based Tandem Network (CTNet) by interactively exploring the spatial contextual information and the channel contextual information, which can discover the semantic context for semantic segmentation. Specifically, the Spatial Contextual Module (SCM) is leveraged to uncover the spatial contextual dependency between pixels by exploring the correlation between pixels and categories. Meanwhile, the Channel Contextual Module (CCM) is introduced to learn the semantic features including the semantic feature maps and class-specific features by modeling the long-term semantic dependence between channels. The learned semantic features are utilized as the prior knowledge to guide the learning of SCM, which can make SCM obtain more accurate long-range spatial dependency. Finally, to further improve the performance of the learned representations for semantic segmentation, the results of the two context modules are adaptively integrated to achieve better results. Extensive experiments are conducted on three widely-used datasets, i.e., PASCAL-Context, ADE20K and PASCAL VOC2012. The results demonstrate the superior performance of the proposed CTNet by comparison with several state-of-the-art methods.
Ontology-driven Information Extraction
Dec 18, 2015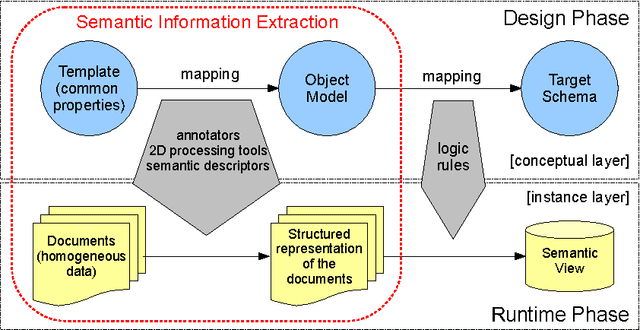
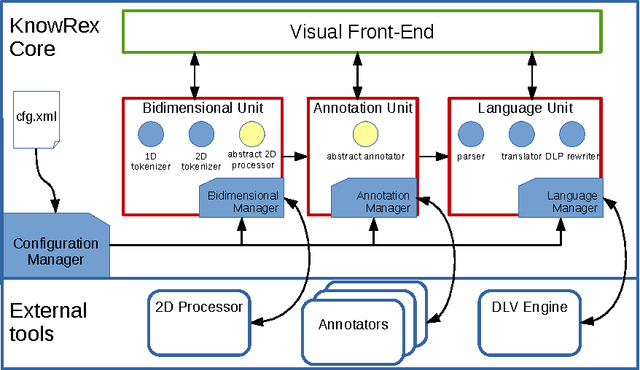

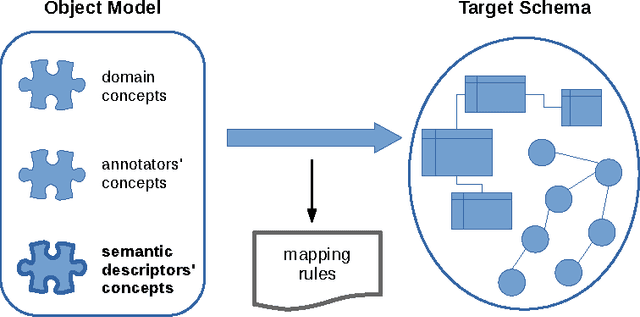
Homogeneous unstructured data (HUD) are collections of unstructured documents that share common properties, such as similar layout, common file format, or common domain of values. Building on such properties, it would be desirable to automatically process HUD to access the main information through a semantic layer -- typically an ontology -- called semantic view. Hence, we propose an ontology-based approach for extracting semantically rich information from HUD, by integrating and extending recent technologies and results from the fields of classical information extraction, table recognition, ontologies, text annotation, and logic programming. Moreover, we design and implement a system, named KnowRex, that has been successfully applied to curriculum vitae in the Europass style to offer a semantic view of them, and be able, for example, to select those which exhibit required skills.
Multi-Source Fusion and Automatic Predictor Selection for Zero-Shot Video Object Segmentation
Aug 11, 2021

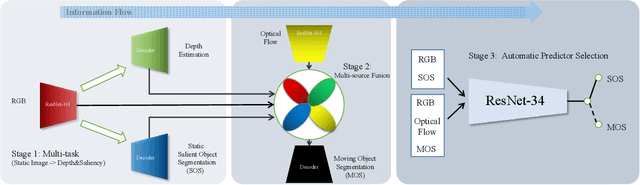
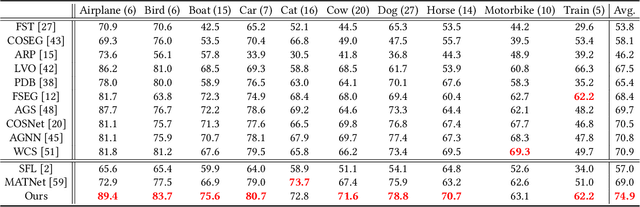
Location and appearance are the key cues for video object segmentation. Many sources such as RGB, depth, optical flow and static saliency can provide useful information about the objects. However, existing approaches only utilize the RGB or RGB and optical flow. In this paper, we propose a novel multi-source fusion network for zero-shot video object segmentation. With the help of interoceptive spatial attention module (ISAM), spatial importance of each source is highlighted. Furthermore, we design a feature purification module (FPM) to filter the inter-source incompatible features. By the ISAM and FPM, the multi-source features are effectively fused. In addition, we put forward an automatic predictor selection network (APS) to select the better prediction of either the static saliency predictor or the moving object predictor in order to prevent over-reliance on the failed results caused by low-quality optical flow maps. Extensive experiments on three challenging public benchmarks (i.e. DAVIS$_{16}$, Youtube-Objects and FBMS) show that the proposed model achieves compelling performance against the state-of-the-arts. The source code will be publicly available at \textcolor{red}{\url{https://github.com/Xiaoqi-Zhao-DLUT/Multi-Source-APS-ZVOS}}.
Label Design-based ELM Network for Timing Synchronization in OFDM Systems with Nonlinear Distortion
Jul 28, 2021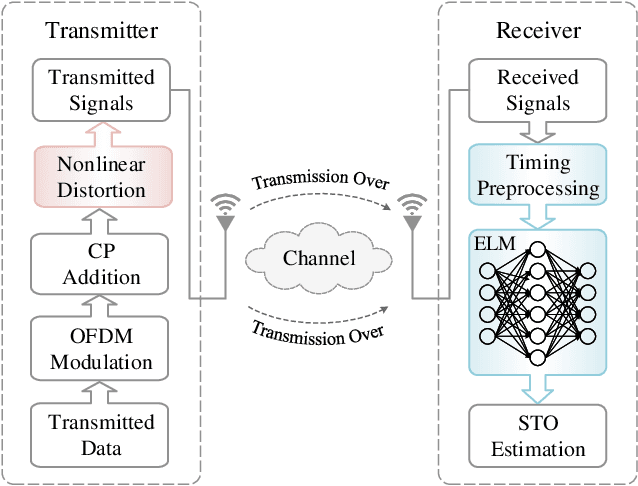
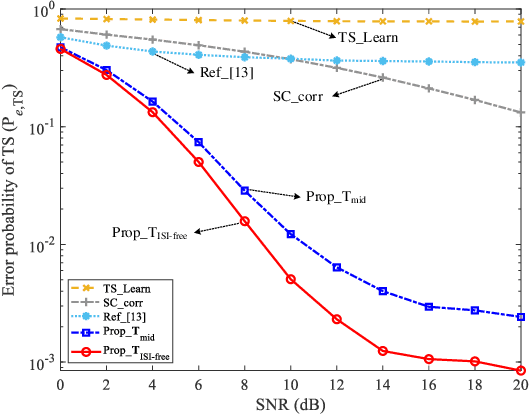
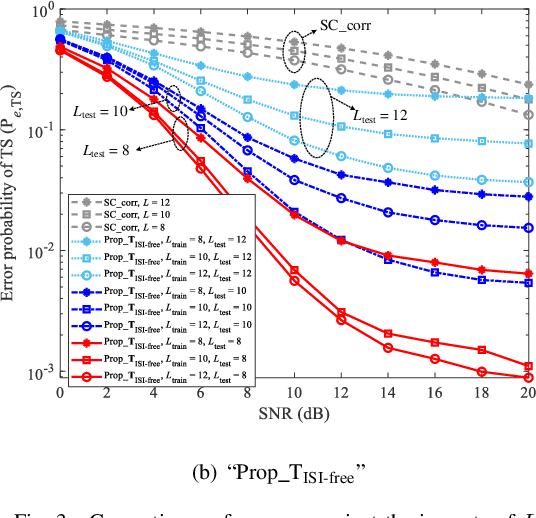
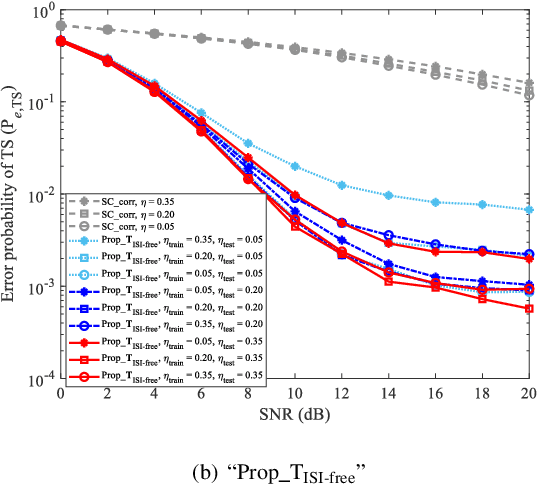
Due to the nonlinear distortion in Orthogonal frequency division multiplexing (OFDM) systems, the timing synchronization (TS) performance is inevitably degraded at the receiver. To relieve this issue, an extreme learning machine (ELM)-based network with a novel learning label is proposed to the TS of OFDM system in our work and increases the possibility of symbol timing offset (STO) estimation residing in inter-symbol interference (ISI)-free region. Especially, by exploiting the prior information of the ISI-free region, two types of learning labels are developed to facilitate the ELM-based TS network. With designed learning labels, a timing-processing by classic TS scheme is first executed to capture the coarse timing metric (TM) and then followed by an ELM network to refine the TM. According to experiments and analysis, our scheme shows its effectiveness in the improvement of TS performance and reveals its generalization performance in different training and testing channel scenarios.
DP-NormFedAvg: Normalizing Client Updates for Privacy-Preserving Federated Learning
Jun 13, 2021
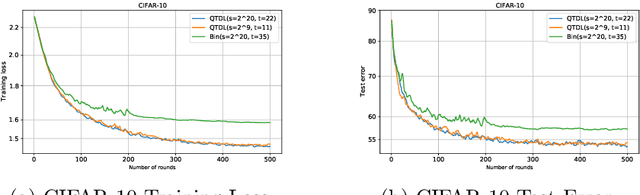

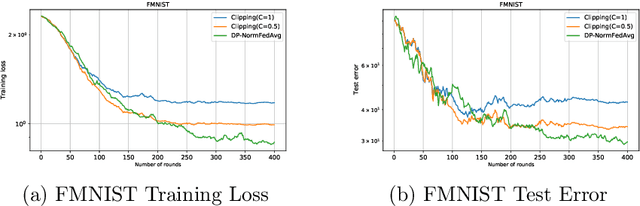
In this paper, we focus on facilitating differentially private quantized communication between the clients and server in federated learning (FL). Towards this end, we propose to have the clients send a \textit{private quantized} version of only the \textit{unit vector} along the change in their local parameters to the server, \textit{completely throwing away the magnitude information}. We call this algorithm \texttt{DP-NormFedAvg} and show that it has the same order-wise convergence rate as \texttt{FedAvg} on smooth quasar-convex functions (an important class of non-convex functions for modeling optimization of deep neural networks), thereby establishing that discarding the magnitude information is not detrimental from an optimization point of view. We also introduce QTDL, a new differentially private quantization mechanism for unit-norm vectors, which we use in \texttt{DP-NormFedAvg}. QTDL employs \textit{discrete} noise having a Laplacian-like distribution on a \textit{finite support} to provide privacy. We show that under a growth-condition assumption on the per-sample client losses, the extra per-coordinate communication cost in each round incurred due to privacy by our method is $\mathcal{O}(1)$ with respect to the model dimension, which is an improvement over prior work. Finally, we show the efficacy of our proposed method with experiments on fully-connected neural networks trained on CIFAR-10 and Fashion-MNIST.
OKSP: A Novel Deep Learning Automatic Event Detection Pipeline for Seismic Monitoringin Costa Rica
Sep 06, 2021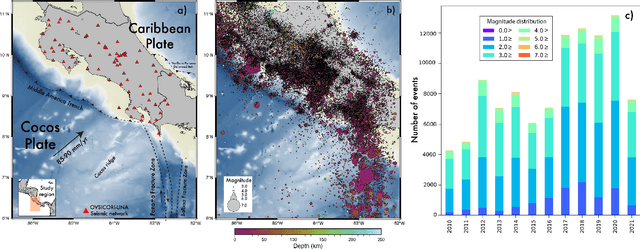
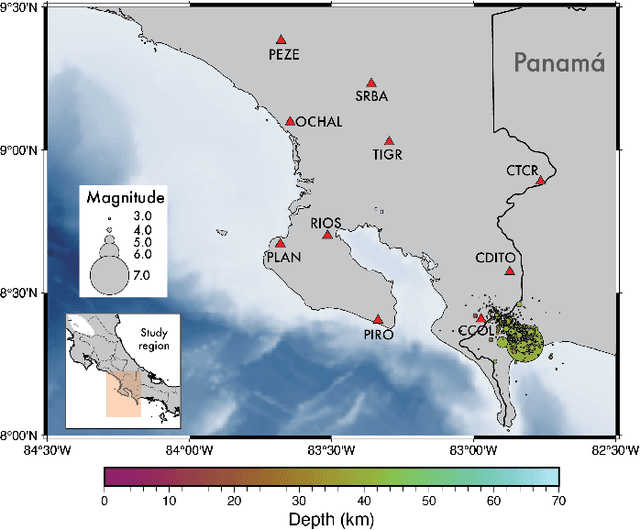
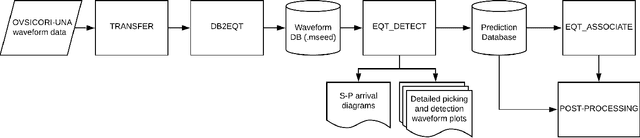
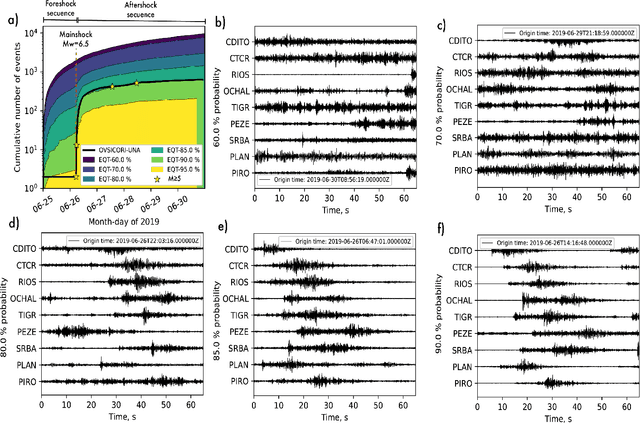
Small magnitude earthquakes are the most abundant but the most difficult to locate robustly and well due to their low amplitudes and high frequencies usually obscured by heterogeneous noise sources. They highlight crucial information about the stress state and the spatio-temporal behavior of fault systems during the earthquake cycle, therefore, its full characterization is then crucial for improving earthquake hazard assessment. Modern DL algorithms along with the increasing computational power are exploiting the continuously growing seismological databases, allowing scientists to improve the completeness for earthquake catalogs, systematically detecting smaller magnitude earthquakes and reducing the errors introduced mainly by human intervention. In this work, we introduce OKSP, a novel automatic earthquake detection pipeline for seismic monitoring in Costa Rica. Using Kabre supercomputer from the Costa Rica High Technology Center, we applied OKSP to the day before and the first 5 days following the Puerto Armuelles, M6.5, earthquake that occurred on 26 June, 2019, along the Costa Rica-Panama border and found 1100 more earthquakes previously unidentified by the Volcanological and Seismological Observatory of Costa Rica. From these events, a total of 23 earthquakes with magnitudes below 1.0 occurred a day to hours prior to the mainshock, shedding light about the rupture initiation and earthquake interaction leading to the occurrence of this productive seismic sequence. Our observations show that for the study period, the model was 100% exhaustive and 82% precise, resulting in an F1 score of 0.90. This effort represents the very first attempt for automatically detecting earthquakes in Costa Rica using deep learning methods and demonstrates that, in the near future, earthquake monitoring routines will be carried out entirely by AI algorithms.
Learning from Matured Dumb Teacher for Fine Generalization
Aug 17, 2021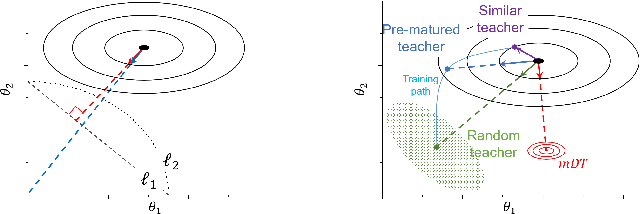
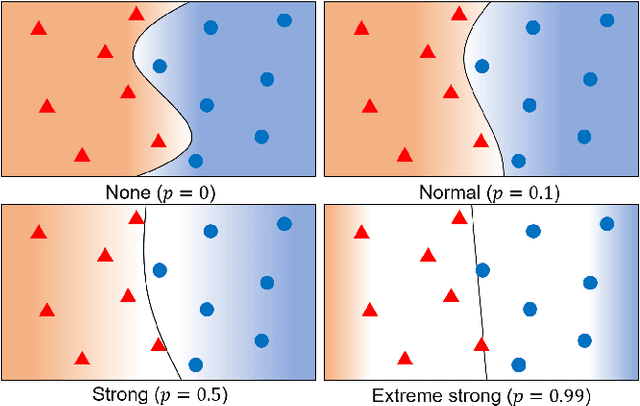
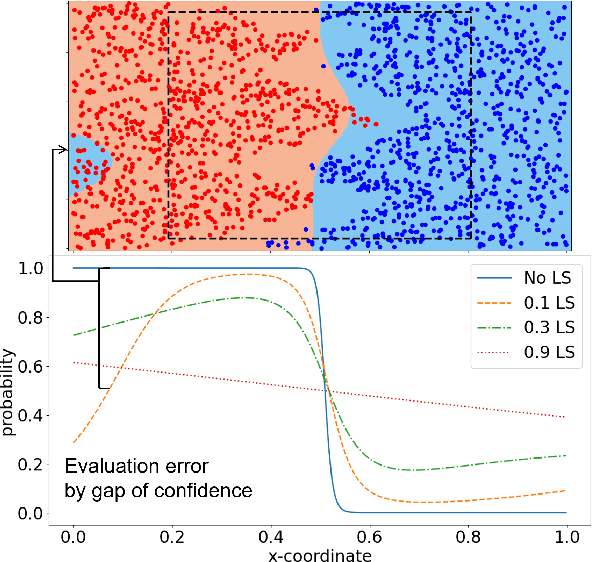
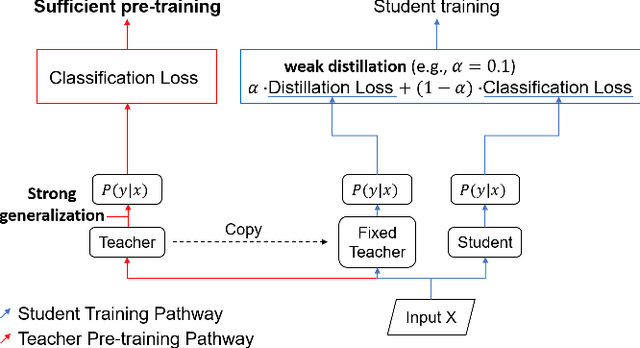
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.