 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Stereo Object Matching Network
Mar 23, 2021
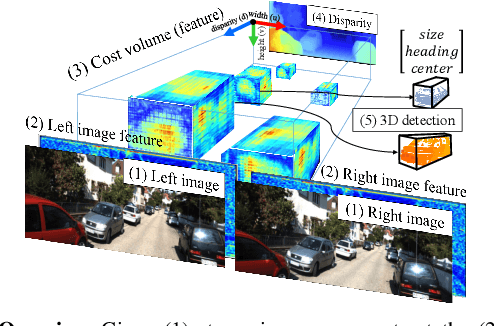
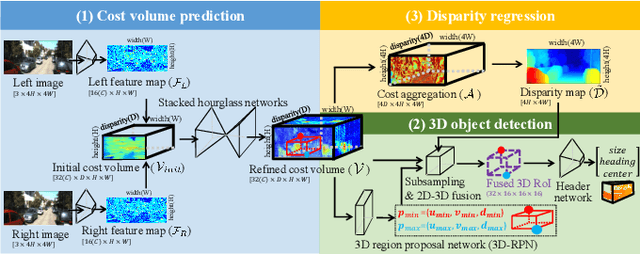
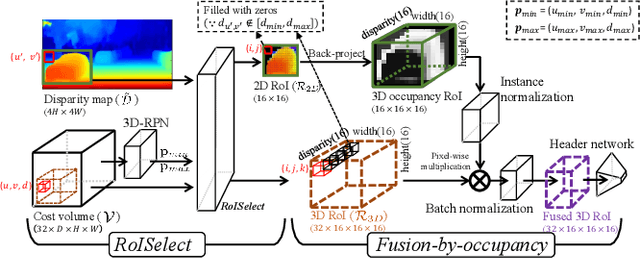
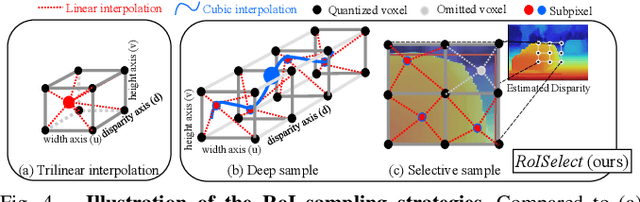
This paper presents a stereo object matching method that exploits both 2D contextual information from images as well as 3D object-level information. Unlike existing stereo matching methods that exclusively focus on the pixel-level correspondence between stereo images within a volumetric space (i.e., cost volume), we exploit this volumetric structure in a different manner. The cost volume explicitly encompasses 3D information along its disparity axis, therefore it is a privileged structure that can encapsulate the 3D contextual information from objects. However, it is not straightforward since the disparity values map the 3D metric space in a non-linear fashion. Thus, we present two novel strategies to handle 3D objectness in the cost volume space: selective sampling (RoISelect) and 2D-3D fusion (fusion-by-occupancy), which allow us to seamlessly incorporate 3D object-level information and achieve accurate depth performance near the object boundary regions. Our depth estimation achieves competitive performance in the KITTI dataset and the Virtual-KITTI 2.0 dataset.
Semi-Supervised Siamese Network for Identifying Bad Data in Medical Imaging Datasets
Aug 16, 2021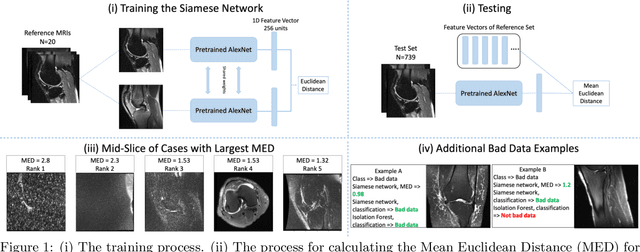
Noisy data present in medical imaging datasets can often aid the development of robust models that are equipped to handle real-world data. However, if the bad data contains insufficient anatomical information, it can have a severe negative effect on the model's performance. We propose a novel methodology using a semi-supervised Siamese network to identify bad data. This method requires only a small pool of 'reference' medical images to be reviewed by a non-expert human to ensure the major anatomical structures are present in the Field of View. The model trains on this reference set and identifies bad data by using the Siamese network to compute the distance between the reference set and all other medical images in the dataset. This methodology achieves an Area Under the Curve (AUC) of 0.989 for identifying bad data. Code will be available at https://git.io/JYFuV.
In-N-Out: Towards Good Initialization for Inpainting and Outpainting
Jun 26, 2021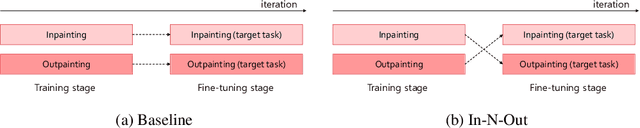
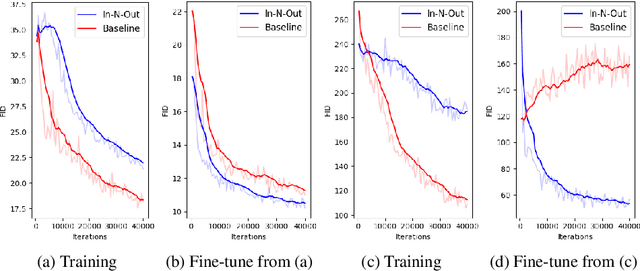

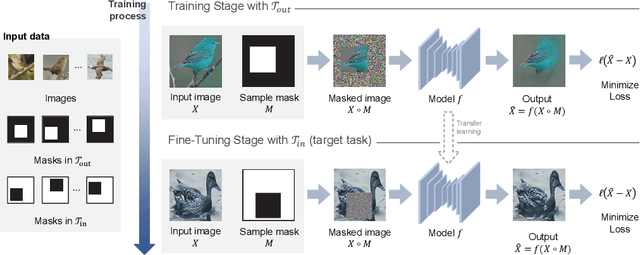
In computer vision, recovering spatial information by filling in masked regions, e.g., inpainting, has been widely investigated for its usability and wide applicability to other various applications: image inpainting, image extrapolation, and environment map estimation. Most of them are studied separately depending on the applications. Our focus, however, is on accommodating the opposite task, e.g., image outpainting, which would benefit the target applications, e.g., image inpainting. Our self-supervision method, In-N-Out, is summarized as a training approach that leverages the knowledge of the opposite task into the target model. We empirically show that In-N-Out -- which explores the complementary information -- effectively takes advantage over the traditional pipelines where only task-specific learning takes place in training. In experiments, we compare our method to the traditional procedure and analyze the effectiveness of our method on different applications: image inpainting, image extrapolation, and environment map estimation. For these tasks, we demonstrate that In-N-Out consistently improves the performance of the recent works with In-N-Out self-supervision to their training procedure. Also, we show that our approach achieves better results than an existing training approach for outpainting.
Self-supervised classification of dynamic obstacles using the temporal information provided by videos
Oct 21, 2019



Nowadays, autonomous driving systems can detect, segment, and classify the surrounding obstacles using a monocular camera. However, state-of-the-art methods solving these tasks generally perform a fully supervised learning process and require a large amount of training labeled data. On another note, some self-supervised learning approaches can deal with detection and segmentation of dynamic obstacles using the temporal information available in video sequences. In this work, we propose in addition to classifiy the detected obstacles depending on their motion pattern. We present a novel self-supervised framework consisting of learning offline clusters from temporal patch sequences and using these clusters as pseudo labels to train a real-time image classifier. The presented model outperforms state-of-the-art unsupervised image classification methods on BDD100K dataset.
Using Biological Variables and Social Determinants to Predict Malaria and Anemia among Children in Senegal
Aug 08, 2021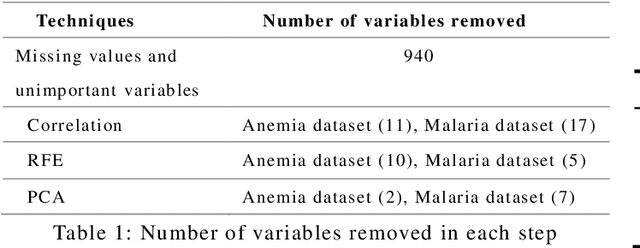
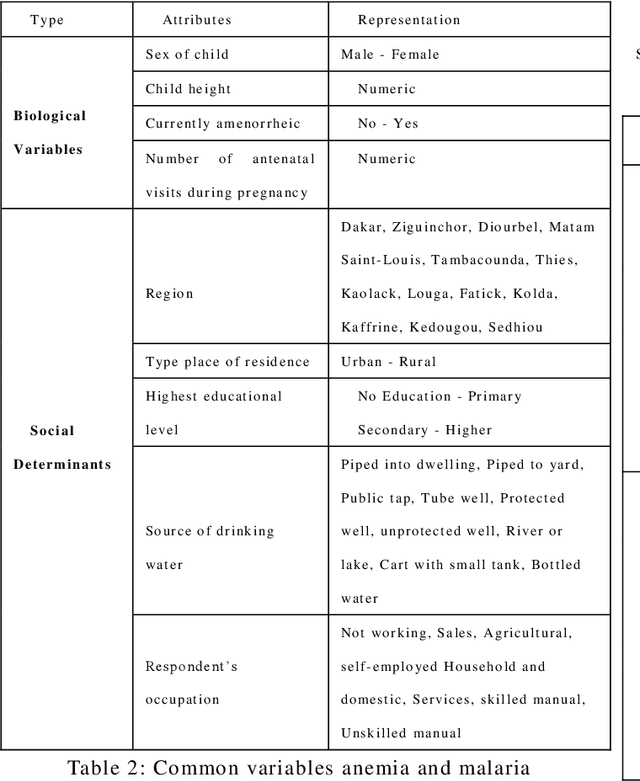

Integrating machine learning techniques in healthcare becomes very common nowadays, and it contributes positively to improving clinical care and health decisions planning. Anemia and malaria are two life-threatening diseases in Africa that affect the red blood cells and reduce hemoglobin production. This paper focuses on analyzing child health data in Senegal using four machine learning algorithms in Python: KNN, Random Forests, SVM, and Na\"ive Bayes. Our task aims to investigate large-scale data from The Demographic and Health Survey (DHS) and to find out hidden information for anemia and malaria. We present two classification models for the two blood disorders using biological variables and social determinants. The findings of this research will contribute to improving child healthcare in Senegal by eradicating anemia and malaria, and decreasing the child mortality rate.
Inharmonious Region Localization
Apr 19, 2021
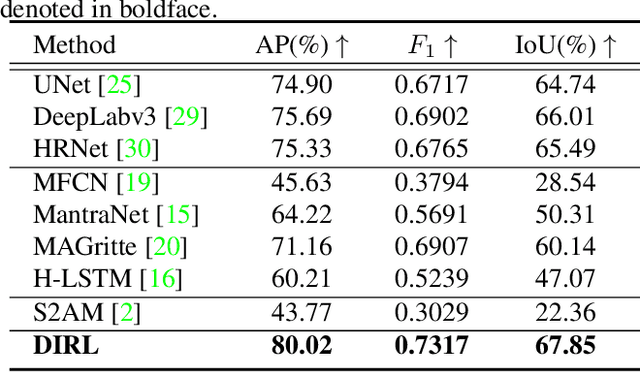
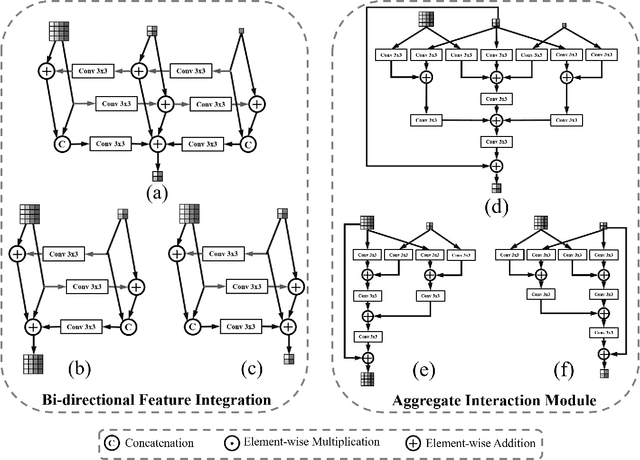
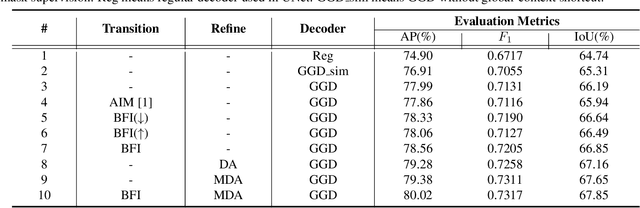
The advance of image editing techniques allows users to create artistic works, but the manipulated regions may be incompatible with the background. Localizing the inharmonious region is an appealing yet challenging task. Realizing that this task requires effective aggregation of multi-scale contextual information and suppression of redundant information, we design novel Bi-directional Feature Integration (BFI) block and Global-context Guided Decoder (GGD) block to fuse multi-scale features in the encoder and decoder respectively. We also employ Mask-guided Dual Attention (MDA) block between the encoder and decoder to suppress the redundant information. Experiments on the image harmonization dataset demonstrate that our method achieves competitive performance for inharmonious region localization. The source code is available at https://github.com/bcmi/DIRL.
Here's What I've Learned: Asking Questions that Reveal Reward Learning
Jul 02, 2021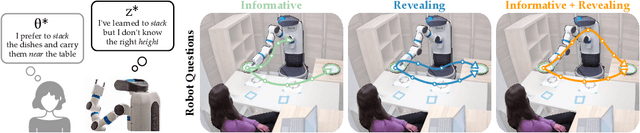

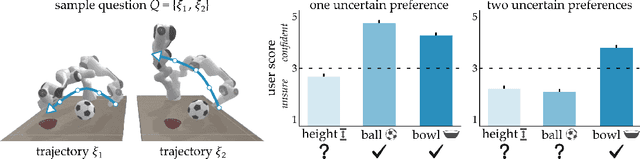
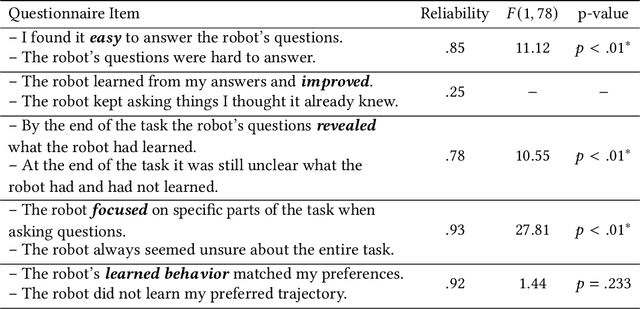
Robots can learn from humans by asking questions. In these questions the robot demonstrates a few different behaviors and asks the human for their favorite. But how should robots choose which questions to ask? Today's robots optimize for informative questions that actively probe the human's preferences as efficiently as possible. But while informative questions make sense from the robot's perspective, human onlookers often find them arbitrary and misleading. In this paper we formalize active preference-based learning from the human's perspective. We hypothesize that -- from the human's point-of-view -- the robot's questions reveal what the robot has and has not learned. Our insight enables robots to use questions to make their learning process transparent to the human operator. We develop and test a model that robots can leverage to relate the questions they ask to the information these questions reveal. We then introduce a trade-off between informative and revealing questions that considers both human and robot perspectives: a robot that optimizes for this trade-off actively gathers information from the human while simultaneously keeping the human up to date with what it has learned. We evaluate our approach across simulations, online surveys, and in-person user studies. Videos of our user studies and results are available here: https://youtu.be/tC6y_jHN7Vw.
Syntactic Patterns Improve Information Extraction for Medical Search
Apr 30, 2018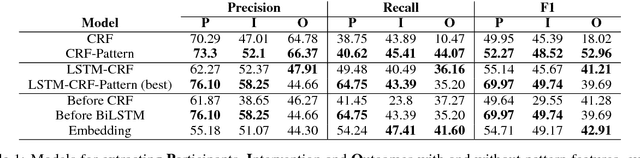
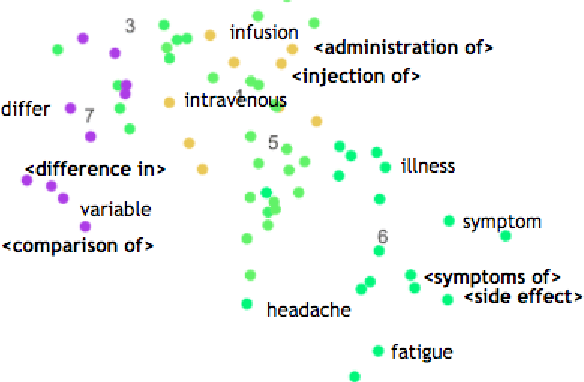


Medical professionals search the published literature by specifying the type of patients, the medical intervention(s) and the outcome measure(s) of interest. In this paper we demonstrate how features encoding syntactic patterns improve the performance of state-of-the-art sequence tagging models (both linear and neural) for information extraction of these medically relevant categories. We present an analysis of the type of patterns exploited, and the semantic space induced for these, i.e., the distributed representations learned for identified multi-token patterns. We show that these learned representations differ substantially from those of the constituent unigrams, suggesting that the patterns capture contextual information that is otherwise lost.
Monotonicity Marking from Universal Dependency Trees
May 12, 2021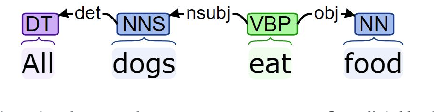
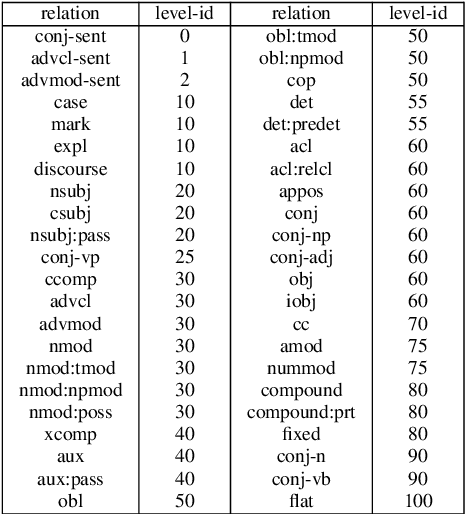
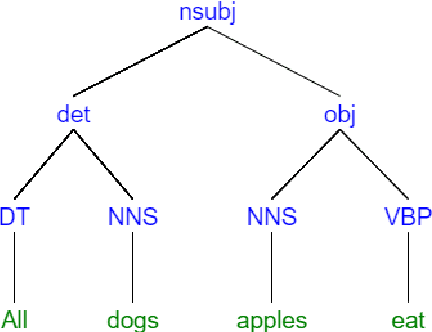

Dependency parsing is a tool widely used in the field of Natural language processing and computational linguistics. However, there is hardly any work that connects dependency parsing to monotonicity, which is an essential part of logic and linguistic semantics. In this paper, we present a system that automatically annotates monotonicity information based on Universal Dependency parse trees. Our system utilizes surface-level monotonicity facts about quantifiers, lexical items, and token-level polarity information. We compared our system's performance with existing systems in the literature, including NatLog and ccg2mono, on a small evaluation dataset. Results show that our system outperforms NatLog and ccg2mono.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 16, 2021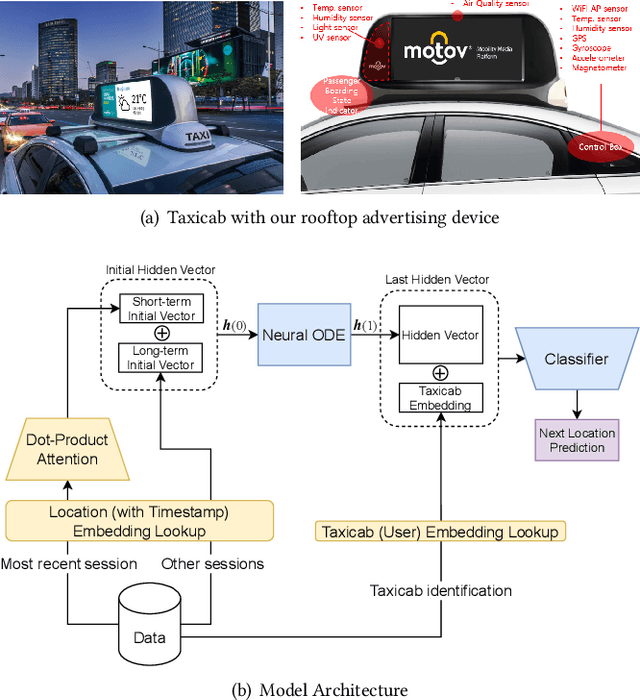

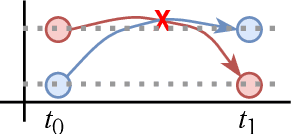
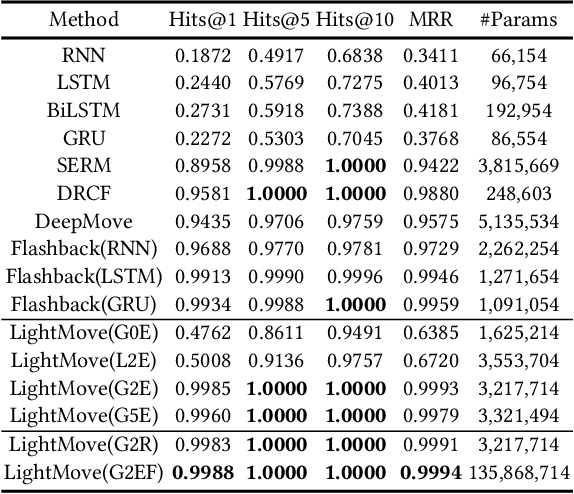
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.