 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Investigating Post-pretraining Representation Alignment for Cross-Lingual Question Answering
Sep 24, 2021
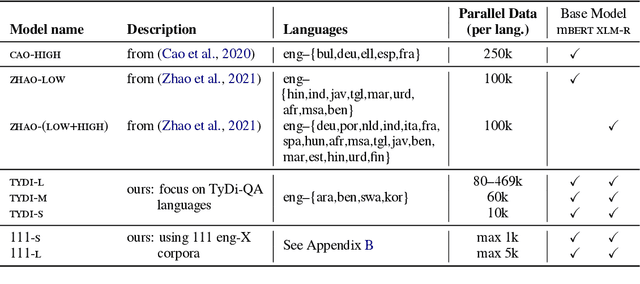
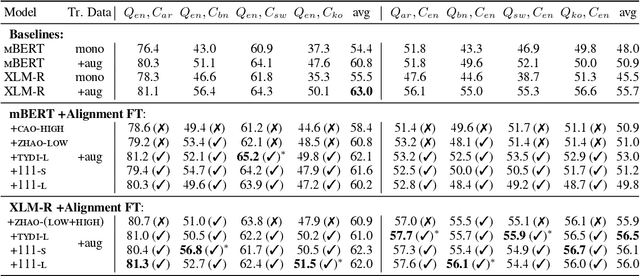
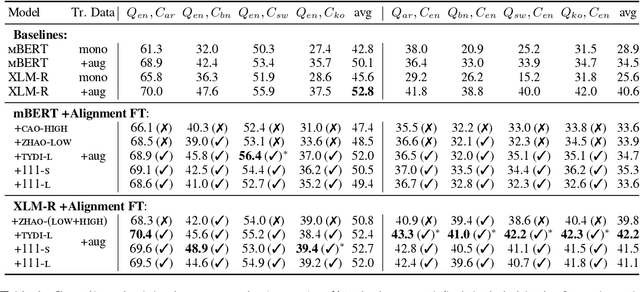
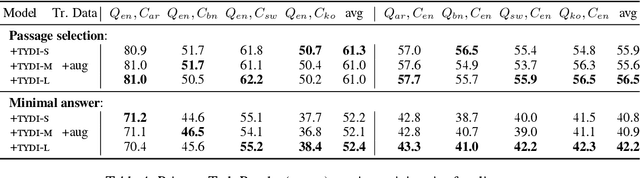
Human knowledge is collectively encoded in the roughly 6500 languages spoken around the world, but it is not distributed equally across languages. Hence, for information-seeking question answering (QA) systems to adequately serve speakers of all languages, they need to operate cross-lingually. In this work we investigate the capabilities of multilingually pre-trained language models on cross-lingual QA. We find that explicitly aligning the representations across languages with a post-hoc fine-tuning step generally leads to improved performance. We additionally investigate the effect of data size as well as the language choice in this fine-tuning step, also releasing a dataset for evaluating cross-lingual QA systems. Code and dataset are publicly available here: https://github.com/ffaisal93/aligned_qa
Robust Contrastive Learning Using Negative Samples with Diminished Semantics
Oct 27, 2021
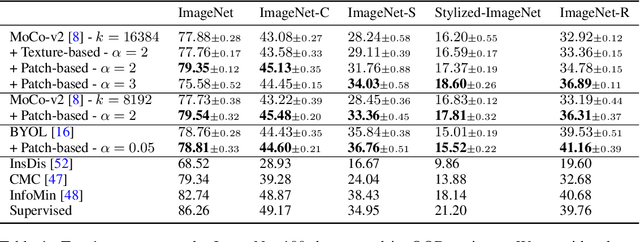
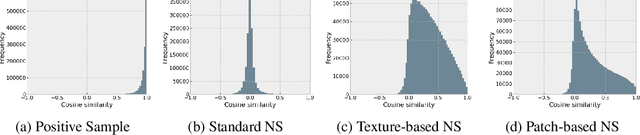

Unsupervised learning has recently made exceptional progress because of the development of more effective contrastive learning methods. However, CNNs are prone to depend on low-level features that humans deem non-semantic. This dependency has been conjectured to induce a lack of robustness to image perturbations or domain shift. In this paper, we show that by generating carefully designed negative samples, contrastive learning can learn more robust representations with less dependence on such features. Contrastive learning utilizes positive pairs that preserve semantic information while perturbing superficial features in the training images. Similarly, we propose to generate negative samples in a reversed way, where only the superfluous instead of the semantic features are preserved. We develop two methods, texture-based and patch-based augmentations, to generate negative samples. These samples achieve better generalization, especially under out-of-domain settings. We also analyze our method and the generated texture-based samples, showing that texture features are indispensable in classifying particular ImageNet classes and especially finer classes. We also show that model bias favors texture and shape features differently under different test settings. Our code, trained models, and ImageNet-Texture dataset can be found at https://github.com/SongweiGe/Contrastive-Learning-with-Non-Semantic-Negatives.
DMRST: A Joint Framework for Document-Level Multilingual RST Discourse Segmentation and Parsing
Oct 09, 2021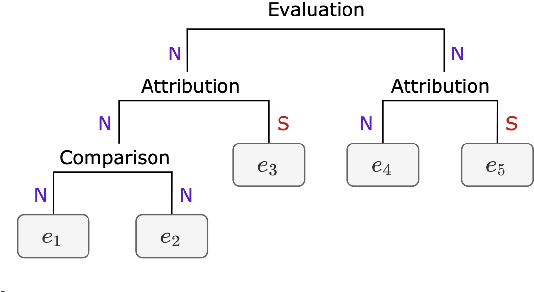
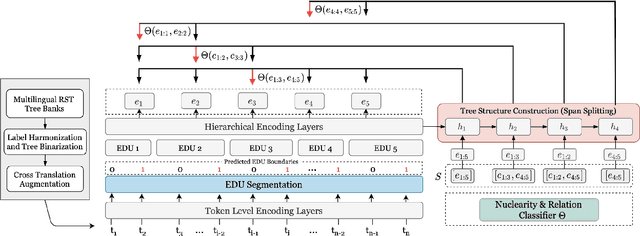
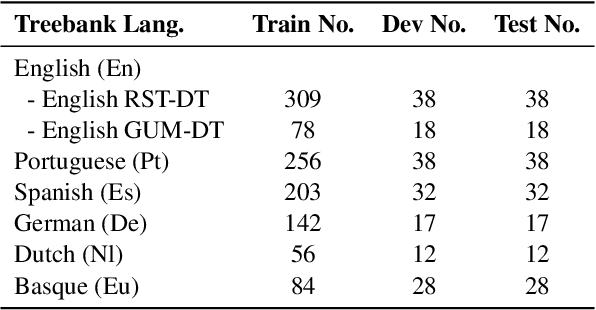
Text discourse parsing weighs importantly in understanding information flow and argumentative structure in natural language, making it beneficial for downstream tasks. While previous work significantly improves the performance of RST discourse parsing, they are not readily applicable to practical use cases: (1) EDU segmentation is not integrated into most existing tree parsing frameworks, thus it is not straightforward to apply such models on newly-coming data. (2) Most parsers cannot be used in multilingual scenarios, because they are developed only in English. (3) Parsers trained from single-domain treebanks do not generalize well on out-of-domain inputs. In this work, we propose a document-level multilingual RST discourse parsing framework, which conducts EDU segmentation and discourse tree parsing jointly. Moreover, we propose a cross-translation augmentation strategy to enable the framework to support multilingual parsing and improve its domain generality. Experimental results show that our model achieves state-of-the-art performance on document-level multilingual RST parsing in all sub-tasks.
Video and Text Matching with Conditioned Embeddings
Oct 21, 2021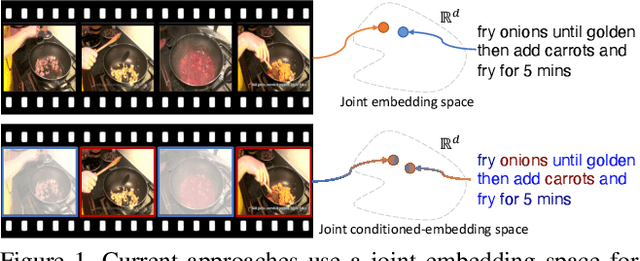
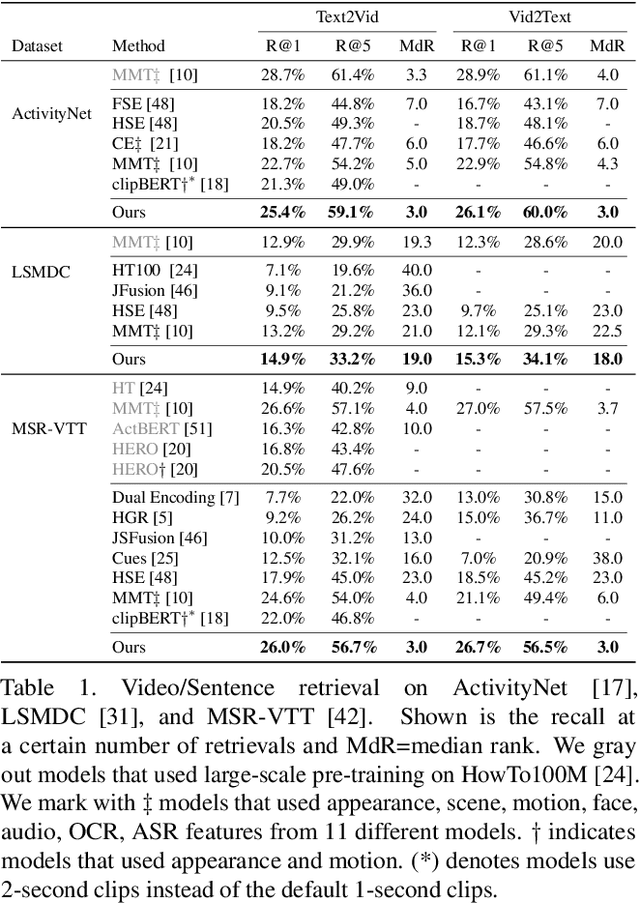
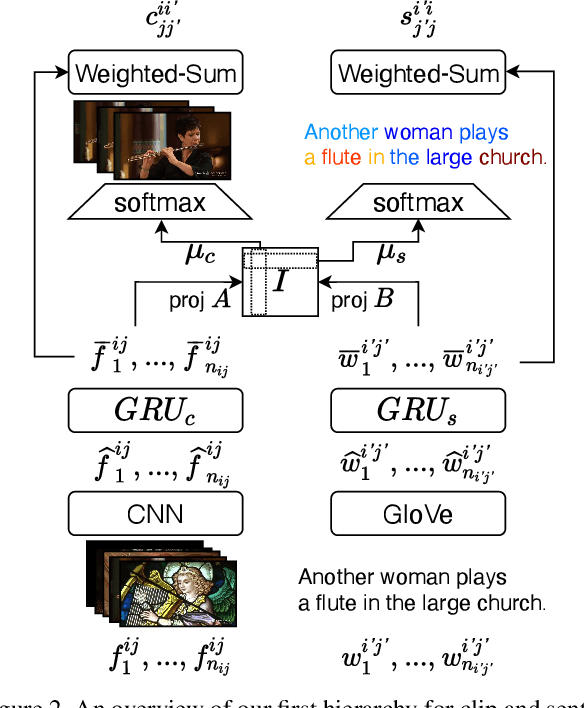
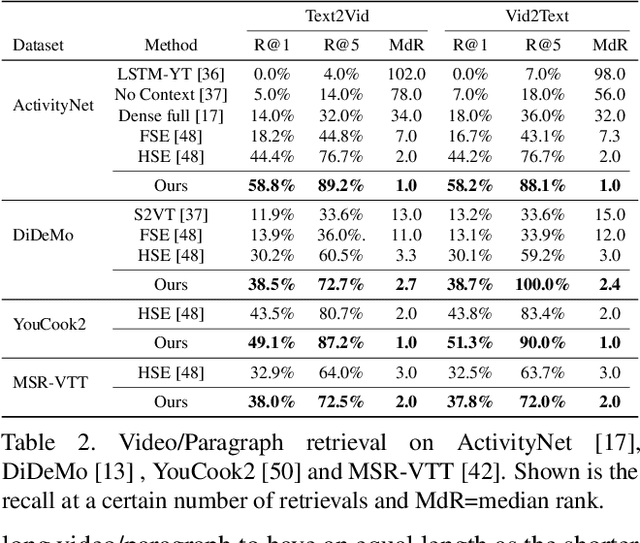
We present a method for matching a text sentence from a given corpus to a given video clip and vice versa. Traditionally video and text matching is done by learning a shared embedding space and the encoding of one modality is independent of the other. In this work, we encode the dataset data in a way that takes into account the query's relevant information. The power of the method is demonstrated to arise from pooling the interaction data between words and frames. Since the encoding of the video clip depends on the sentence compared to it, the representation needs to be recomputed for each potential match. To this end, we propose an efficient shallow neural network. Its training employs a hierarchical triplet loss that is extendable to paragraph/video matching. The method is simple, provides explainability, and achieves state-of-the-art results for both sentence-clip and video-text by a sizable margin across five different datasets: ActivityNet, DiDeMo, YouCook2, MSR-VTT, and LSMDC. We also show that our conditioned representation can be transferred to video-guided machine translation, where we improved the current results on VATEX. Source code is available at https://github.com/AmeenAli/VideoMatch.
SINet: Extreme Lightweight Portrait Segmentation Networks with Spatial Squeeze Modules and Information Blocking Decoder
Nov 26, 2019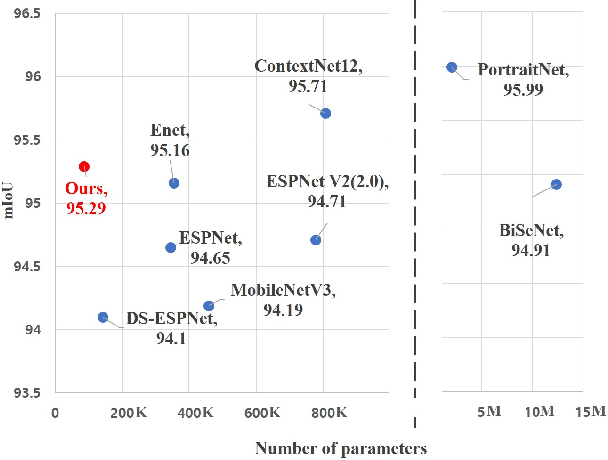


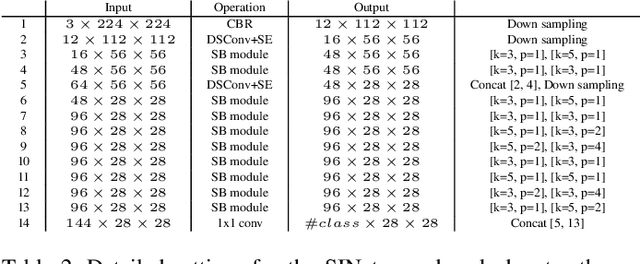
Designing a lightweight and robust portrait segmentation algorithm is an important task for a wide range of face applications. However, the problem has been considered as a subset of the object segmentation problem and less handled in the semantic segmentation field. Obviously, portrait segmentation has its unique requirements. First, because the portrait segmentation is performed in the middle of a whole process of many real-world applications, it requires extremely lightweight models. Second, there has not been any public datasets in this domain that contain a sufficient number of images with unbiased statistics. To solve the first problem, we introduce the new extremely lightweight portrait segmentation model SINet, containing an information blocking decoder and spatial squeeze modules. The information blocking decoder uses confidence estimates to recover local spatial information without spoiling global consistency. The spatial squeeze module uses multiple receptive fields to cope with various sizes of consistency in the image. To tackle the second problem, we propose a simple method to create additional portrait segmentation data which can improve accuracy on the EG1800 dataset. In our qualitative and quantitative analysis on the EG1800 dataset, we show that our method outperforms various existing lightweight segmentation models. Our method reduces the number of parameters from2.1M to 86.9K (around 95.9% reduction), while maintaining the accuracy under an 1% margin from the state-of-the-art portrait segmentation method. We also show our model is successfully executed on a real mobile device with 100.6 FPS. In addition, we demonstrate that our method can be used for general semantic segmentation on the Cityscape dataset. The code is available inhttps://github.com/HYOJINPARK/ExtPortraitSeg
Private Retrieval, Computing and Learning: Recent Progress and Future Challenges
Jul 30, 2021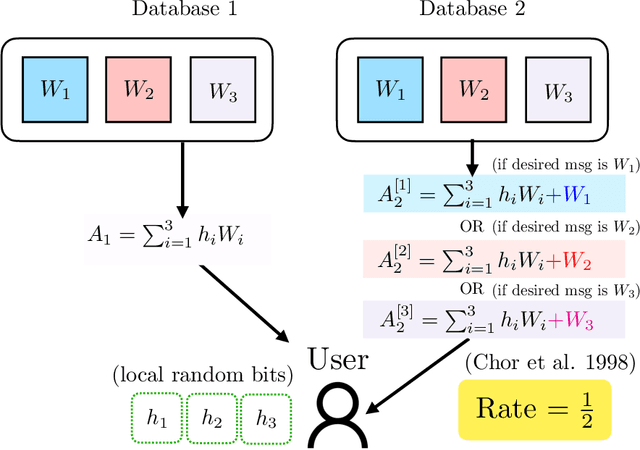
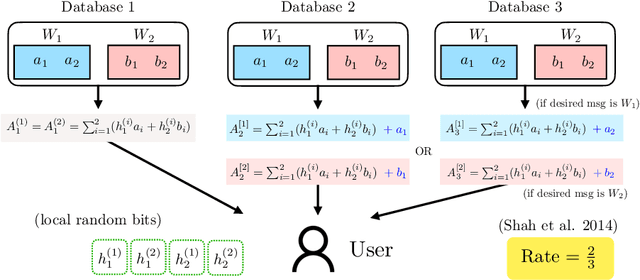
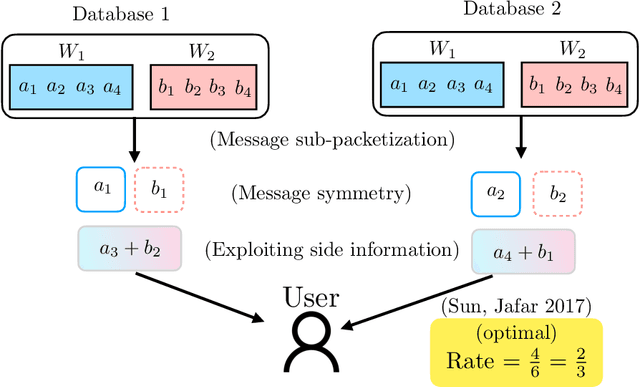
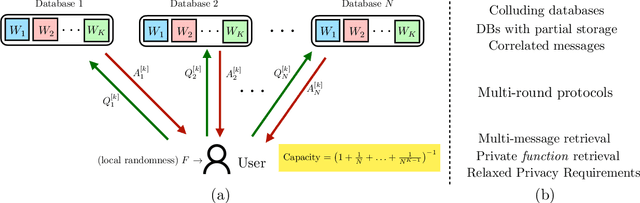
Most of our lives are conducted in the cyberspace. The human notion of privacy translates into a cyber notion of privacy on many functions that take place in the cyberspace. This article focuses on three such functions: how to privately retrieve information from cyberspace (privacy in information retrieval), how to privately leverage large-scale distributed/parallel processing (privacy in distributed computing), and how to learn/train machine learning models from private data spread across multiple users (privacy in distributed (federated) learning). The article motivates each privacy setting, describes the problem formulation, summarizes breakthrough results in the history of each problem, and gives recent results and discusses some of the major ideas that emerged in each field. In addition, the cross-cutting techniques and interconnections between the three topics are discussed along with a set of open problems and challenges.
Towards Robust Bisimulation Metric Learning
Oct 27, 2021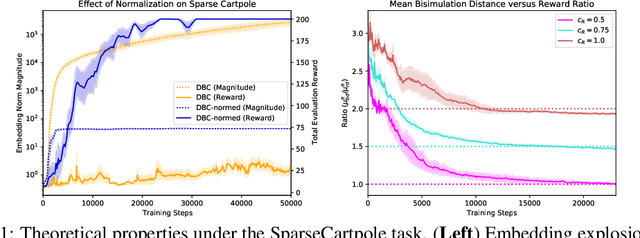

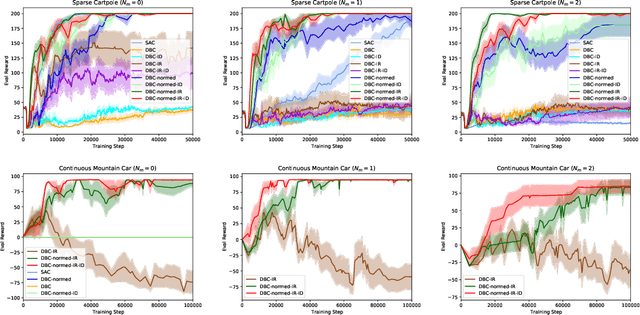
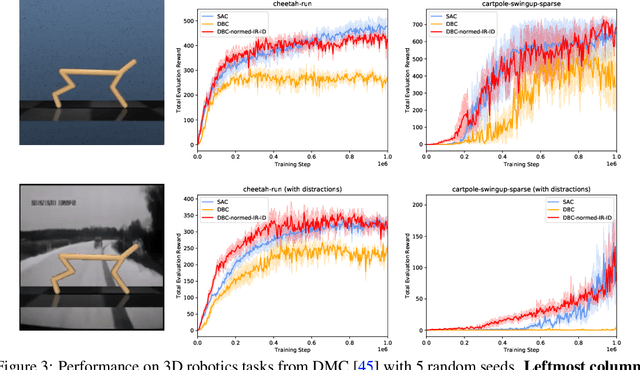
Learned representations in deep reinforcement learning (DRL) have to extract task-relevant information from complex observations, balancing between robustness to distraction and informativeness to the policy. Such stable and rich representations, often learned via modern function approximation techniques, can enable practical application of the policy improvement theorem, even in high-dimensional continuous state-action spaces. Bisimulation metrics offer one solution to this representation learning problem, by collapsing functionally similar states together in representation space, which promotes invariance to noise and distractors. In this work, we generalize value function approximation bounds for on-policy bisimulation metrics to non-optimal policies and approximate environment dynamics. Our theoretical results help us identify embedding pathologies that may occur in practical use. In particular, we find that these issues stem from an underconstrained dynamics model and an unstable dependence of the embedding norm on the reward signal in environments with sparse rewards. Further, we propose a set of practical remedies: (i) a norm constraint on the representation space, and (ii) an extension of prior approaches with intrinsic rewards and latent space regularization. Finally, we provide evidence that the resulting method is not only more robust to sparse reward functions, but also able to solve challenging continuous control tasks with observational distractions, where prior methods fail.
Sarcasm Detection in Twitter -- Performance Impact while using Data Augmentation: Word Embeddings
Aug 31, 2021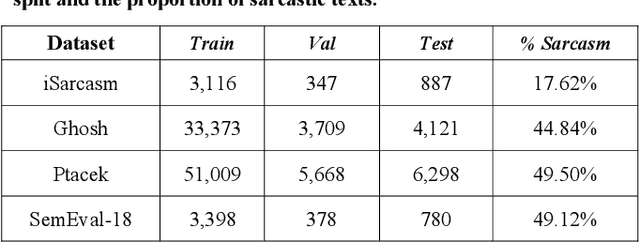
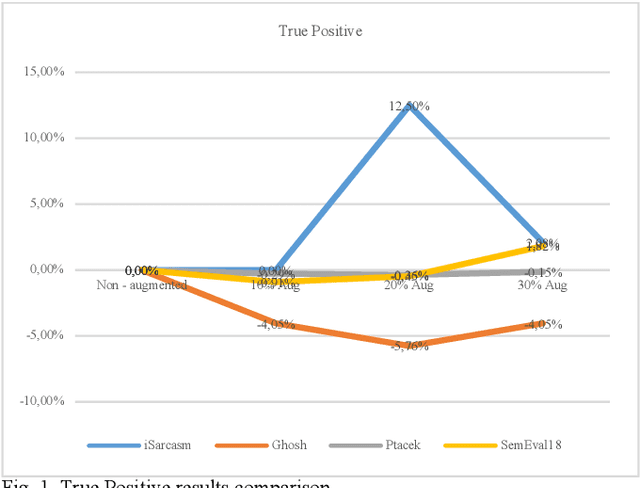
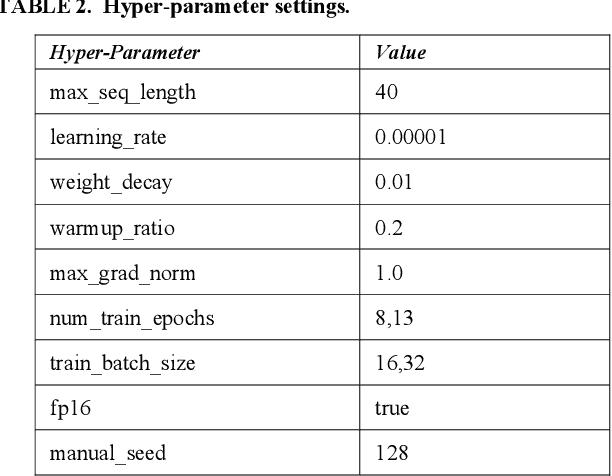
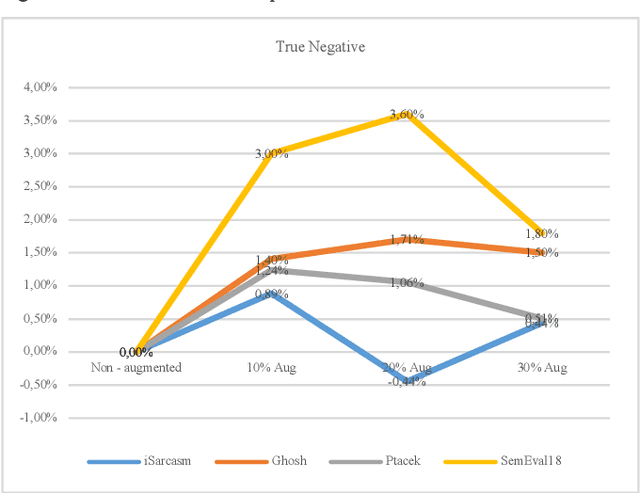
Sarcasm is the use of words usually used to either mock or annoy someone, or for humorous purposes. Sarcasm is largely used in social networks and microblogging websites, where people mock or censure in a way that makes it difficult even for humans to tell if what is said is what is meant. Failure to identify sarcastic utterances in Natural Language Processing applications such as sentiment analysis and opinion mining will confuse classification algorithms and generate false results. Several studies on sarcasm detection have utilized different learning algorithms. However, most of these learning models have always focused on the contents of expression only, leaving the contextual information in isolation. As a result, they failed to capture the contextual information in the sarcastic expression. Moreover, some datasets used in several studies have an unbalanced dataset which impacting the model result. In this paper, we propose a contextual model for sarcasm identification in twitter using RoBERTa, and augmenting the dataset by applying Global Vector representation (GloVe) for the construction of word embedding and context learning to generate more data and balancing the dataset. The effectiveness of this technique is tested with various datasets and data augmentation settings. In particular, we achieve performance gain by 3.2% in the iSarcasm dataset when using data augmentation to increase 20% of data labeled as sarcastic, resulting F-score of 40.4% compared to 37.2% without data augmentation.
Deep Reinforcement Learning for Decentralized Multi-Robot Exploration with Macro Actions
Oct 05, 2021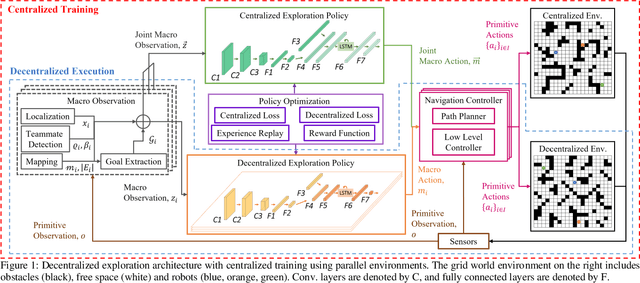
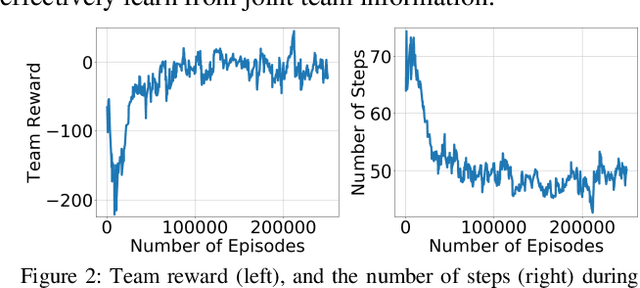
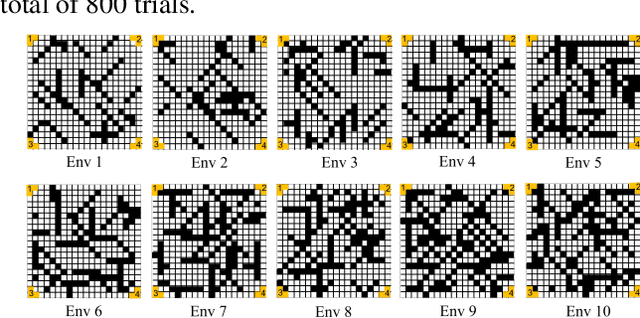
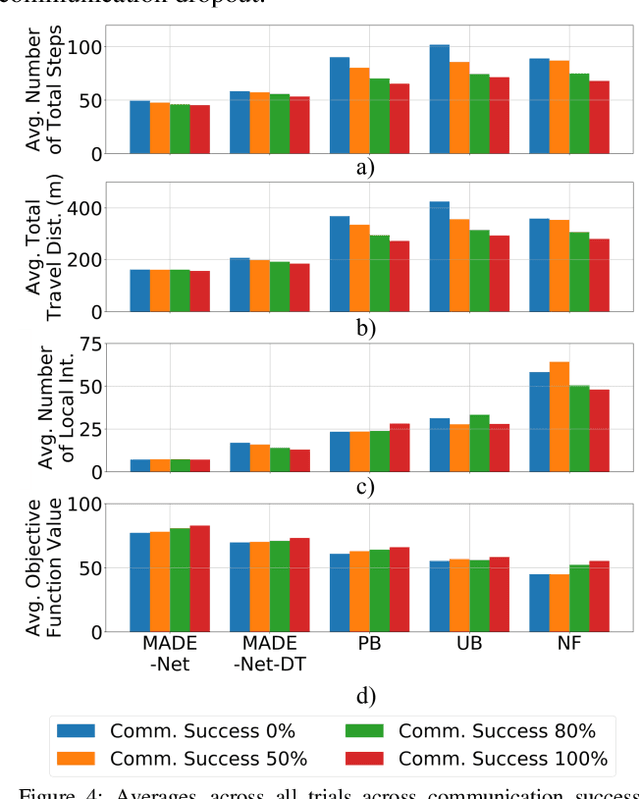
Cooperative multi-robot teams need to be able to explore cluttered and unstructured environments together while dealing with communication challenges. Specifically, during communication dropout, local information about robots can no longer be exchanged to maintain robot team coordination. Therefore, robots need to consider high-level teammate intentions during action selection. In this paper, we present the first Macro Action Decentralized Exploration Network (MADE-Net) using multi-agent deep reinforcement learning to address the challenges of communication dropouts during multi-robot exploration in unseen, unstructured, and cluttered environments. Simulated robot team exploration experiments were conducted and compared to classical and deep reinforcement learning methods. The results showed that our MADE-Net method was able to outperform all benchmark methods in terms of computation time, total travel distance, number of local interactions between robots, and exploration rate across various degrees of communication dropouts; highlighting the effectiveness and robustness of our method.
End-to-End Learning of Deep Kernel Acquisition Functions for Bayesian Optimization
Nov 01, 2021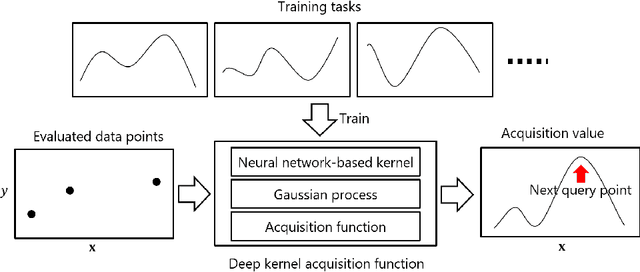
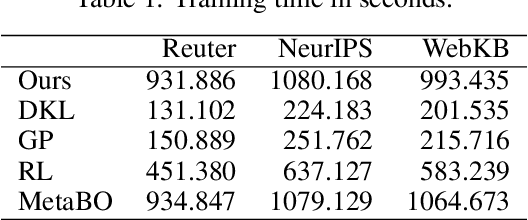
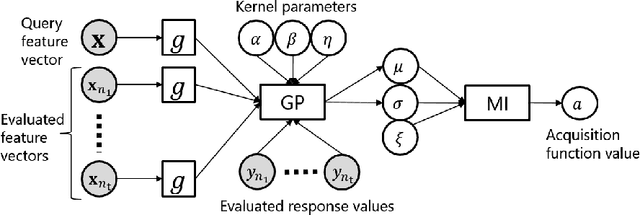
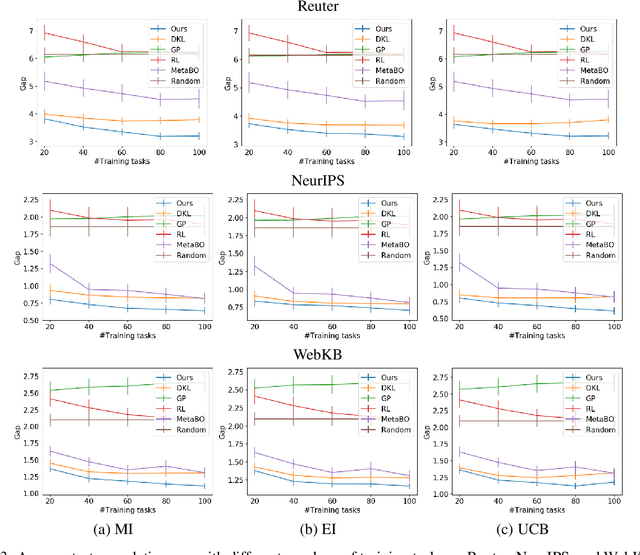
For Bayesian optimization (BO) on high-dimensional data with complex structure, neural network-based kernels for Gaussian processes (GPs) have been used to learn flexible surrogate functions by the high representation power of deep learning. However, existing methods train neural networks by maximizing the marginal likelihood, which do not directly improve the BO performance. In this paper, we propose a meta-learning method for BO with neural network-based kernels that minimizes the expected gap between the true optimum value and the best value found by BO. We model a policy, which takes the current evaluated data points as input and outputs the next data point to be evaluated, by a neural network, where neural network-based kernels, GPs, and mutual information-based acquisition functions are used as its layers. With our model, the neural network-based kernel is trained to be appropriate for the acquisition function by backpropagating the gap through the acquisition function and GP. Our model is trained by a reinforcement learning framework from multiple tasks. Since the neural network is shared across different tasks, we can gather knowledge on BO from multiple training tasks, and use the knowledge for unseen test tasks. In experiments using three text document datasets, we demonstrate that the proposed method achieves better BO performance than the existing methods.