 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
ColDE: A Depth Estimation Framework for Colonoscopy Reconstruction
Nov 19, 2021

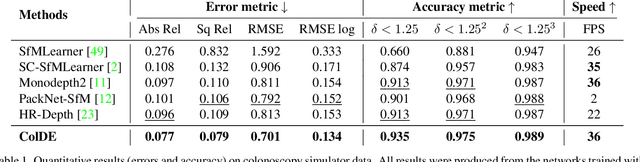
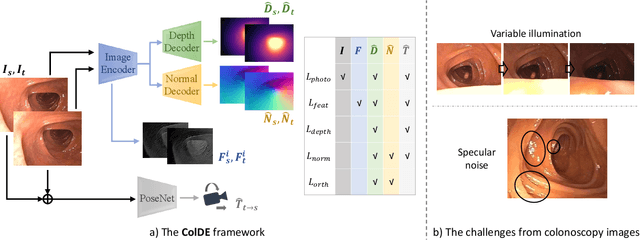
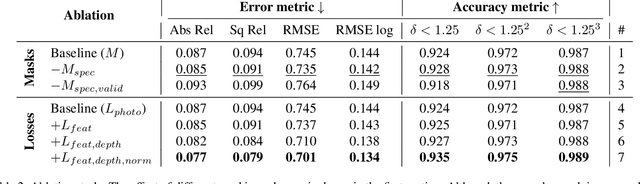
One of the key elements of reconstructing a 3D mesh from a monocular video is generating every frame's depth map. However, in the application of colonoscopy video reconstruction, producing good-quality depth estimation is challenging. Neural networks can be easily fooled by photometric distractions or fail to capture the complex shape of the colon surface, predicting defective shapes that result in broken meshes. Aiming to fundamentally improve the depth estimation quality for colonoscopy 3D reconstruction, in this work we have designed a set of training losses to deal with the special challenges of colonoscopy data. For better training, a set of geometric consistency objectives was developed, using both depth and surface normal information. Also, the classic photometric loss was extended with feature matching to compensate for illumination noise. With the training losses powerful enough, our self-supervised framework named ColDE is able to produce better depth maps of colonoscopy data as compared to the previous work utilizing prior depth knowledge. Used in reconstruction, our network is able to reconstruct good-quality colon meshes in real-time without any post-processing, making it the first to be clinically applicable.
A Road-map Towards Explainable Question Answering A Solution for Information Pollution
Jul 04, 2019

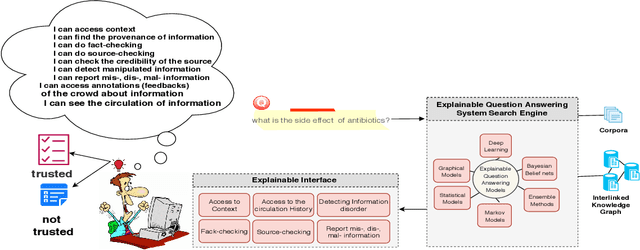

The increasing rate of information pollution on the Web requires novel solutions to tackle that. Question Answering (QA) interfaces are simplified and user-friendly interfaces to access information on the Web. However, similar to other AI applications, they are black boxes which do not manifest the details of the learning or reasoning steps for augmenting an answer. The Explainable Question Answering (XQA) system can alleviate the pain of information pollution where it provides transparency to the underlying computational model and exposes an interface enabling the end-user to access and validate provenance, validity, context, circulation, interpretation, and feedbacks of information. This position paper sheds light on the core concepts, expectations, and challenges in favor of the following questions (i) What is an XQA system?, (ii) Why do we need XQA?, (iii) When do we need XQA? (iv) How to represent the explanations? (iv) How to evaluate XQA systems?
CaT: Weakly Supervised Object Detection with Category Transfer
Aug 17, 2021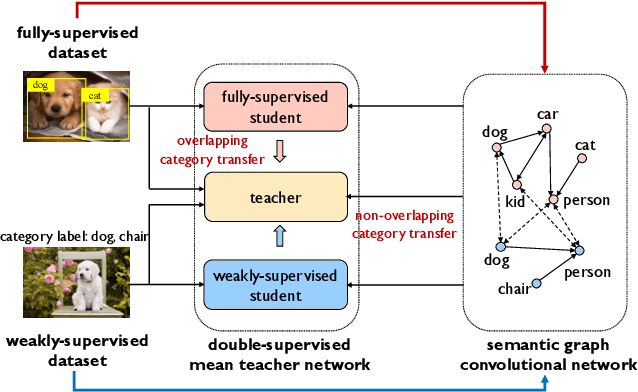
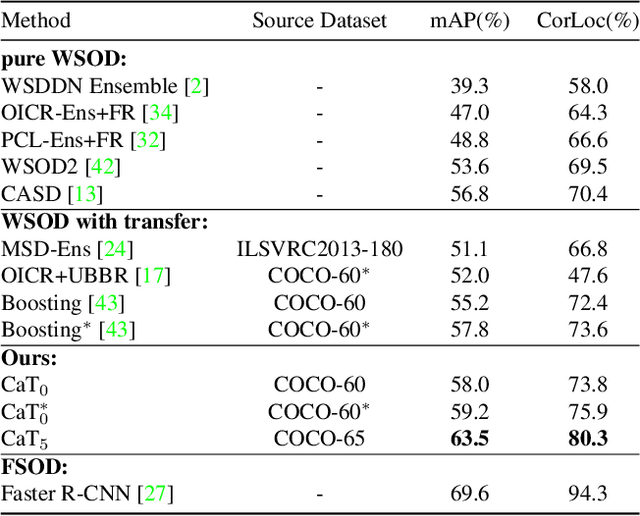
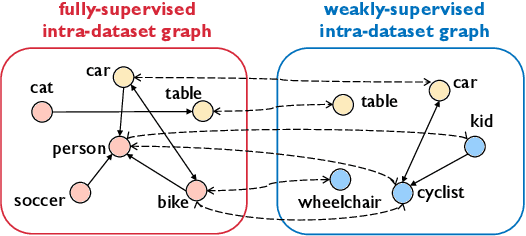
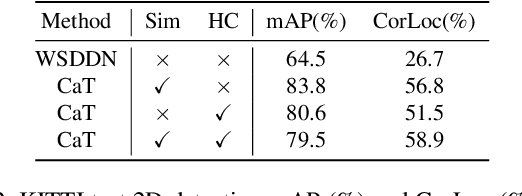
A large gap exists between fully-supervised object detection and weakly-supervised object detection. To narrow this gap, some methods consider knowledge transfer from additional fully-supervised dataset. But these methods do not fully exploit discriminative category information in the fully-supervised dataset, thus causing low mAP. To solve this issue, we propose a novel category transfer framework for weakly supervised object detection. The intuition is to fully leverage both visually-discriminative and semantically-correlated category information in the fully-supervised dataset to enhance the object-classification ability of a weakly-supervised detector. To handle overlapping category transfer, we propose a double-supervision mean teacher to gather common category information and bridge the domain gap between two datasets. To handle non-overlapping category transfer, we propose a semantic graph convolutional network to promote the aggregation of semantic features between correlated categories. Experiments are conducted with Pascal VOC 2007 as the target weakly-supervised dataset and COCO as the source fully-supervised dataset. Our category transfer framework achieves 63.5% mAP and 80.3% CorLoc with 5 overlapping categories between two datasets, which outperforms the state-of-the-art methods. Codes are avaliable at https://github.com/MediaBrain-SJTU/CaT.
Multivariate feature ranking of gene expression data
Nov 07, 2021

Gene expression datasets are usually of high dimensionality and therefore require efficient and effective methods for identifying the relative importance of their attributes. Due to the huge size of the search space of the possible solutions, the attribute subset evaluation feature selection methods tend to be not applicable, so in these scenarios feature ranking methods are used. Most of the feature ranking methods described in the literature are univariate methods, so they do not detect interactions between factors. In this paper we propose two new multivariate feature ranking methods based on pairwise correlation and pairwise consistency, which we have applied in three gene expression classification problems. We statistically prove that the proposed methods outperform the state of the art feature ranking methods Clustering Variation, Chi Squared, Correlation, Information Gain, ReliefF and Significance, as well as feature selection methods of attribute subset evaluation based on correlation and consistency with multi-objective evolutionary search strategy.
Development of an R-Mode Simulator Using MF DGNSS Signals
Aug 21, 2021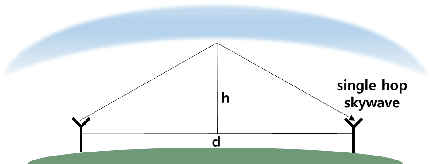
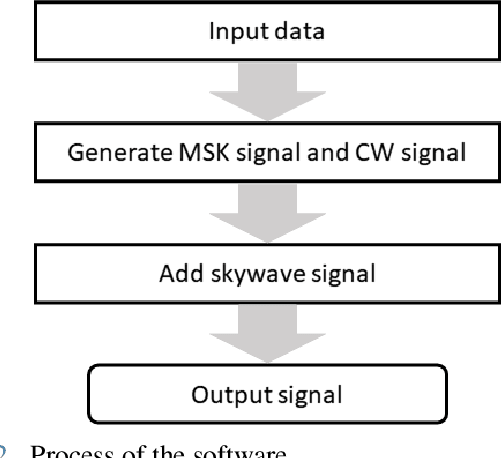
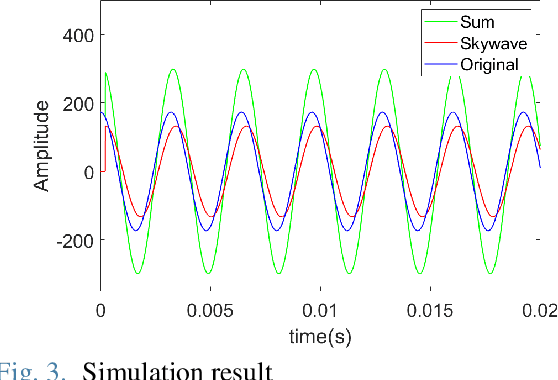
With the development of positioning, navigation, and timing (PNT) information-based industries, PNT information is becoming increasingly important. Therefore, various navigation studies have been actively conducted to back up global positioning system (GPS) in scenarios in which it is disabled. Ranging using signals of opportunity (SoOP) has the advantage of infrastructure already being in place. Among them, the ranging mode (R-Mode) is a technology that uses available SoOPs such as a medium frequency (MF) differential global navigation satellite System (DGNSS) signal that has recently been recognized for its potential for navigation and is currently under research. In this study, we developed a signal simulator that considers the characteristics of MF DGNSS signals and skywaves used in R-Mode.
CEM-GD: Cross-Entropy Method with Gradient Descent Planner for Model-Based Reinforcement Learning
Dec 14, 2021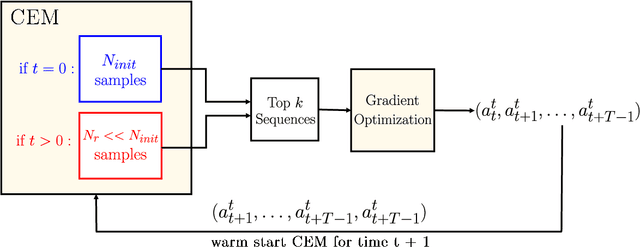
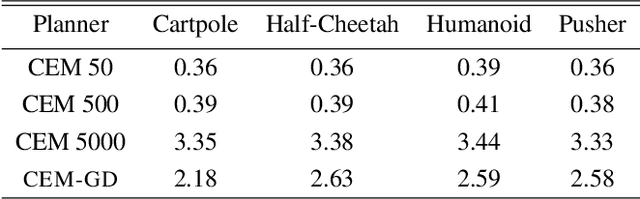
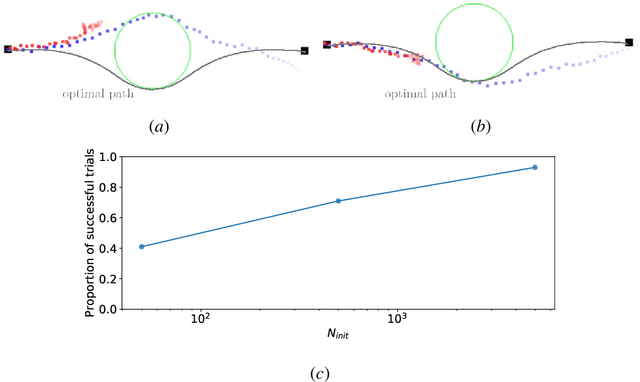
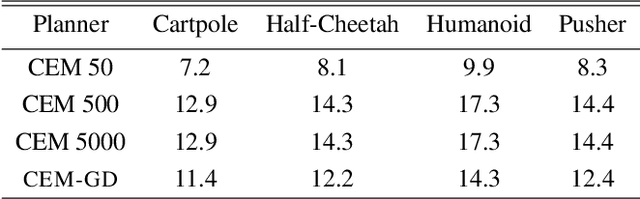
Current state-of-the-art model-based reinforcement learning algorithms use trajectory sampling methods, such as the Cross-Entropy Method (CEM), for planning in continuous control settings. These zeroth-order optimizers require sampling a large number of trajectory rollouts to select an optimal action, which scales poorly for large prediction horizons or high dimensional action spaces. First-order methods that use the gradients of the rewards with respect to the actions as an update can mitigate this issue, but suffer from local optima due to the non-convex optimization landscape. To overcome these issues and achieve the best of both worlds, we propose a novel planner, Cross-Entropy Method with Gradient Descent (CEM-GD), that combines first-order methods with CEM. At the beginning of execution, CEM-GD uses CEM to sample a significant amount of trajectory rollouts to explore the optimization landscape and avoid poor local minima. It then uses the top trajectories as initialization for gradient descent and applies gradient updates to each of these trajectories to find the optimal action sequence. At each subsequent time step, however, CEM-GD samples much fewer trajectories from CEM before applying gradient updates. We show that as the dimensionality of the planning problem increases, CEM-GD maintains desirable performance with a constant small number of samples by using the gradient information, while avoiding local optima using initially well-sampled trajectories. Furthermore, CEM-GD achieves better performance than CEM on a variety of continuous control benchmarks in MuJoCo with 100x fewer samples per time step, resulting in around 25% less computation time and 10% less memory usage. The implementation of CEM-GD is available at $\href{https://github.com/KevinHuang8/CEM-GD}{\text{https://github.com/KevinHuang8/CEM-GD}}$.
Policies for constraining the behaviour of coalitions of agents in the context of algebraic information theory
Nov 28, 2019
This article takes an oblique sidestep from two previous papers, wherein an approach to reformulation of game theory in terms of information theory, topology, as well as a few other notions was indicated. In this document a description is provided as to how one might determine an approach for an agent to choose a policy concerning which actions to take in a game that constrains behaviour of subsidiary agents. It is then demonstrated how these results in algebraic information theory, together with previous investigations in geometric and topological information theory, can be unified into a single cohesive framework.
Global Context with Discrete Diffusion in Vector Quantised Modelling for Image Generation
Dec 03, 2021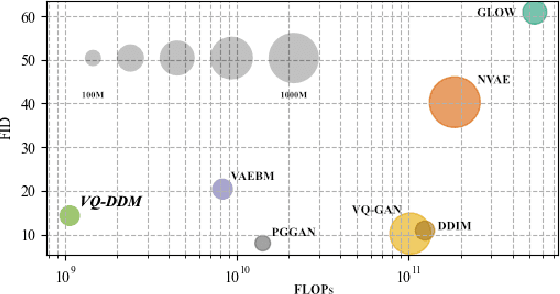
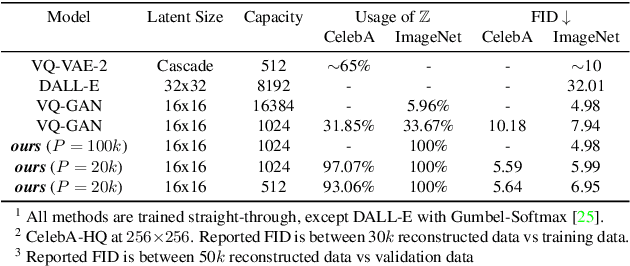
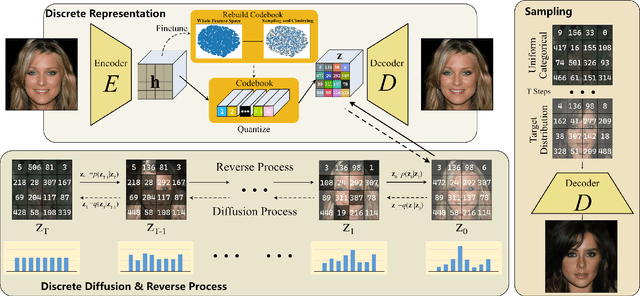
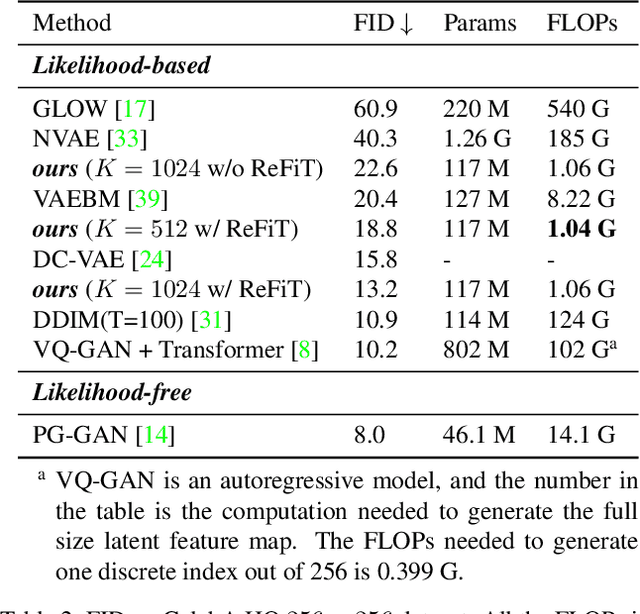
The integration of Vector Quantised Variational AutoEncoder (VQ-VAE) with autoregressive models as generation part has yielded high-quality results on image generation. However, the autoregressive models will strictly follow the progressive scanning order during the sampling phase. This leads the existing VQ series models to hardly escape the trap of lacking global information. Denoising Diffusion Probabilistic Models (DDPM) in the continuous domain have shown a capability to capture the global context, while generating high-quality images. In the discrete state space, some works have demonstrated the potential to perform text generation and low resolution image generation. We show that with the help of a content-rich discrete visual codebook from VQ-VAE, the discrete diffusion model can also generate high fidelity images with global context, which compensates for the deficiency of the classical autoregressive model along pixel space. Meanwhile, the integration of the discrete VAE with the diffusion model resolves the drawback of conventional autoregressive models being oversized, and the diffusion model which demands excessive time in the sampling process when generating images. It is found that the quality of the generated images is heavily dependent on the discrete visual codebook. Extensive experiments demonstrate that the proposed Vector Quantised Discrete Diffusion Model (VQ-DDM) is able to achieve comparable performance to top-tier methods with low complexity. It also demonstrates outstanding advantages over other vectors quantised with autoregressive models in terms of image inpainting tasks without additional training.
DeMFI: Deep Joint Deblurring and Multi-Frame Interpolation with Flow-Guided Attentive Correlation and Recursive Boosting
Nov 19, 2021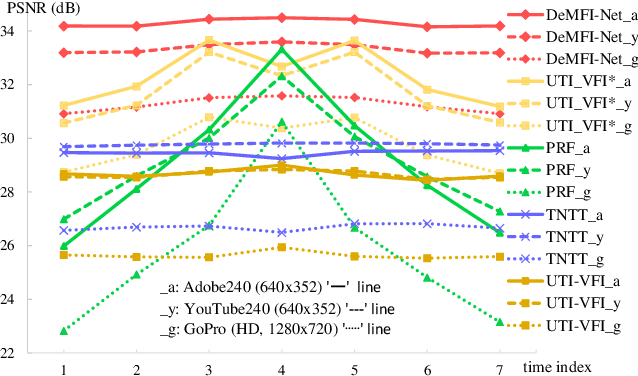
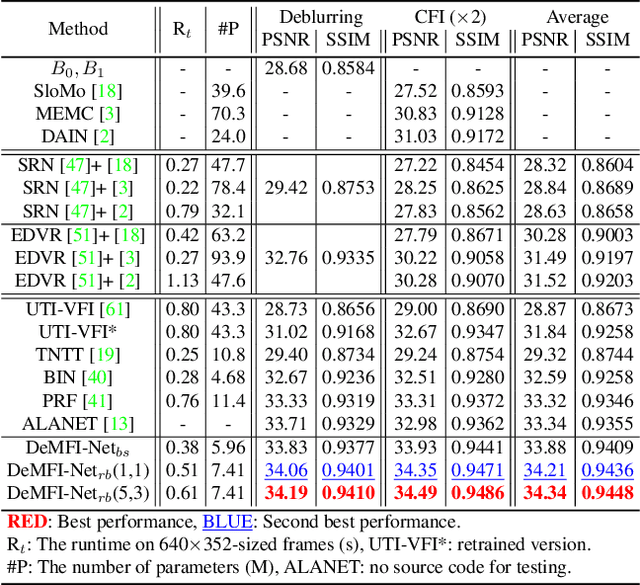
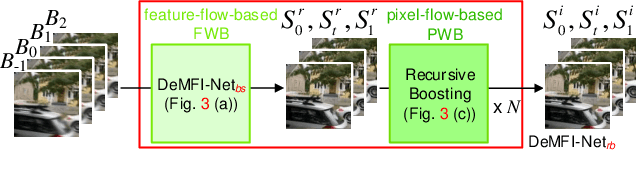

In this paper, we propose a novel joint deblurring and multi-frame interpolation (DeMFI) framework, called DeMFI-Net, which accurately converts blurry videos of lower-frame-rate to sharp videos at higher-frame-rate based on flow-guided attentive-correlation-based feature bolstering (FAC-FB) module and recursive boosting (RB), in terms of multi-frame interpolation (MFI). The DeMFI-Net jointly performs deblurring and MFI where its baseline version performs feature-flow-based warping with FAC-FB module to obtain a sharp-interpolated frame as well to deblur two center-input frames. Moreover, its extended version further improves the joint task performance based on pixel-flow-based warping with GRU-based RB. Our FAC-FB module effectively gathers the distributed blurry pixel information over blurry input frames in feature-domain to improve the overall joint performances, which is computationally efficient since its attentive correlation is only focused pointwise. As a result, our DeMFI-Net achieves state-of-the-art (SOTA) performances for diverse datasets with significant margins compared to the recent SOTA methods, for both deblurring and MFI. All source codes including pretrained DeMFI-Net are publicly available at https://github.com/JihyongOh/DeMFI.
ACD-EDMD: Analytical Construction for Dictionaries of Lifting Functions in Koopman Operator-based Nonlinear Robotic Systems
Nov 24, 2021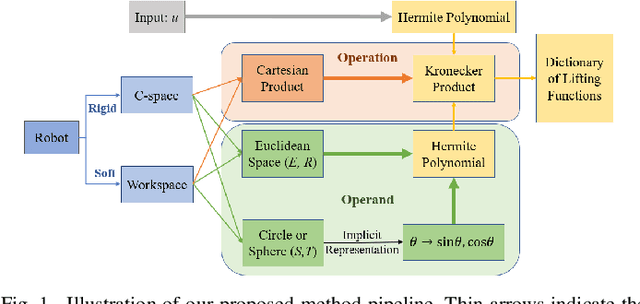
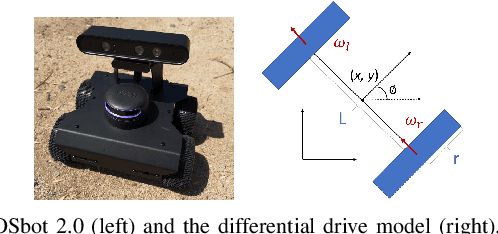
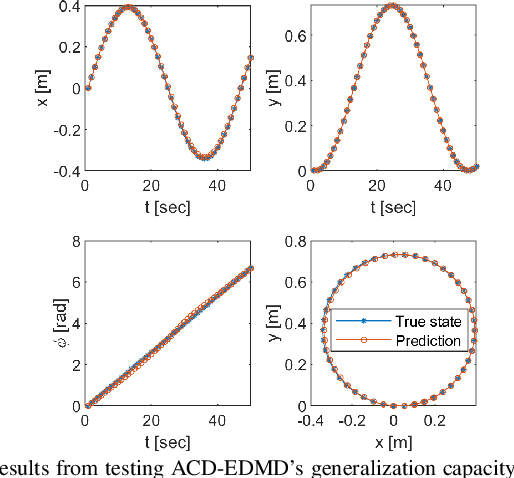
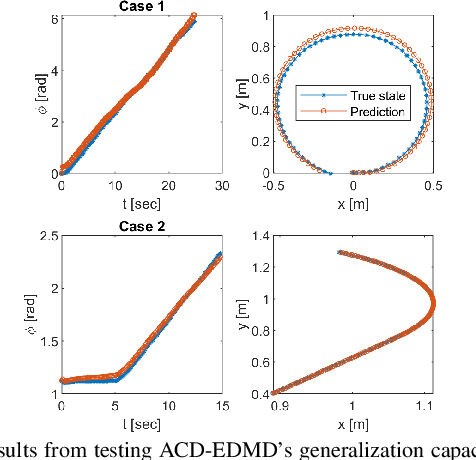
Koopman operator theory has been gaining momentum for model extraction, planning, and control of data-driven robotic systems. The Koopman operator's ability to extract dynamics from data depends heavily on the selection of an appropriate dictionary of lifting functions. In this paper we propose ACD-EDMD, a new method for Analytical Construction of Dictionaries of appropriate lifting functions for a range of data-driven Koopman operator based nonlinear robotic systems. The key insight of this work is that information about fundamental topological spaces of the nonlinear system (such as its configuration space and workspace) can be exploited to steer the construction of Hermite polynomial-based lifting functions. We show that the proposed method leads to dictionaries that are simple to implement while enjoying provable completeness and convergence guarantees when observables are weighted bounded. We evaluate ACD-EDMD using a range of diverse nonlinear robotic systems in both simulated and physical hardware experimentation (a wheeled mobile robot, a two-revolute-joint robotic arm, and a soft robotic leg). Results reveal that our method leads to dictionaries that enable high-accuracy prediction and that can generalize to diverse validation sets. The associated GitHub repository of our algorithm can be accessed at \url{https://github.com/UCR-Robotics/ACD-EDMD}.