 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Topic Modeling the Reading and Writing Behavior of Information Foragers
Jun 30, 2019
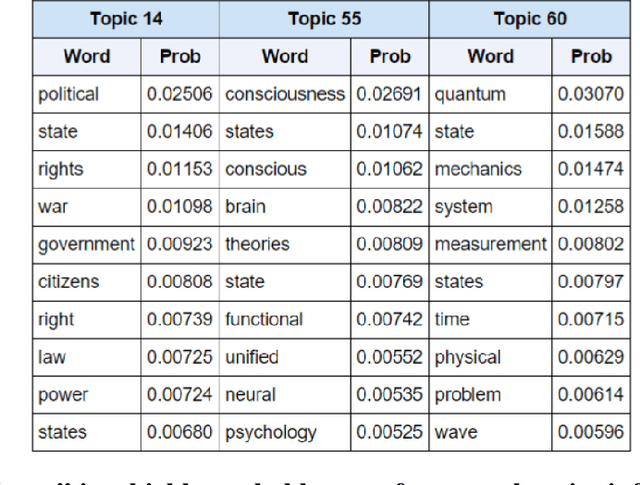
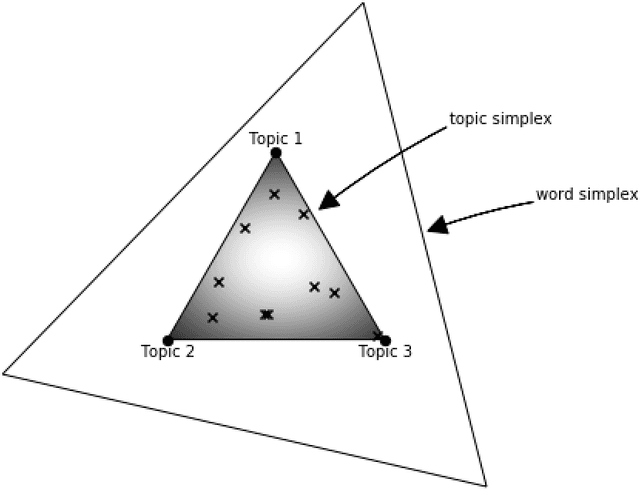

The general problem of "information foraging" in an environment about which agents have incomplete information has been explored in many fields, including cognitive psychology, neuroscience, economics, finance, ecology, and computer science. In all of these areas, the searcher aims to enhance future performance by surveying enough of existing knowledge to orient themselves in the information space. Individuals can be viewed as conducting a cognitive search in which they must balance exploration of ideas that are novel to them against exploitation of knowledge in domains in which they are already expert. In this dissertation, I present several case studies that demonstrate how reading and writing behaviors interact to construct personal knowledge bases. These studies use LDA topic modeling to represent the information environment of the texts each author read and wrote. Three studies revolve around Charles Darwin. Darwin left detailed records of every book he read for 23 years, from disembarking from the H.M.S. Beagle to just after publication of The Origin of Species. Additionally, he left copies of his drafts before publication. I characterize his reading behavior, then show how that reading behavior interacted with the drafts and subsequent revisions of The Origin of Species, and expand the dataset to include later readings and writings. Then, through a study of Thomas Jefferson's correspondence, I expand the study to non-book data. Finally, through an examination of neuroscience citation data, I move from individual behavior to collective behavior in constructing an information environment. Together, these studies reveal "the interplay between individual and collective phenomena where innovation takes place" (Tria et al. 2014).
3DVNet: Multi-View Depth Prediction and Volumetric Refinement
Dec 01, 2021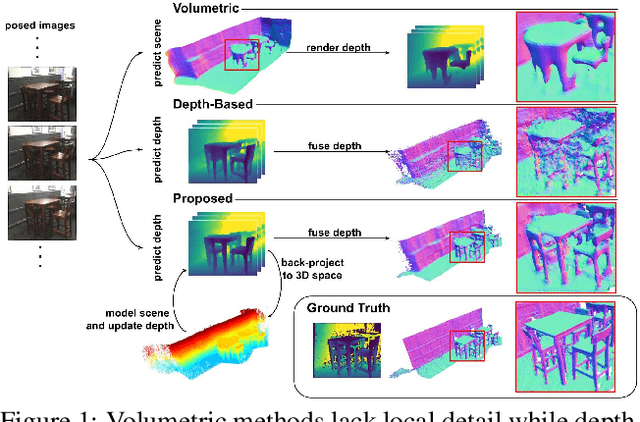
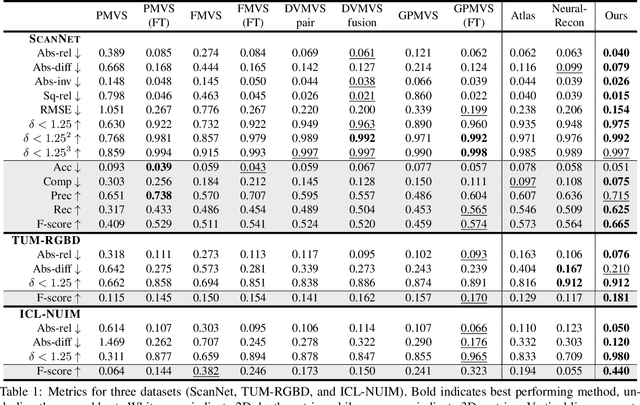
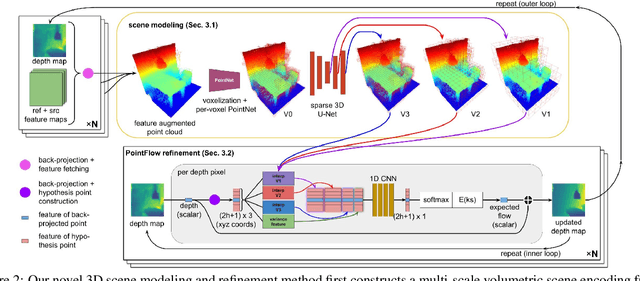
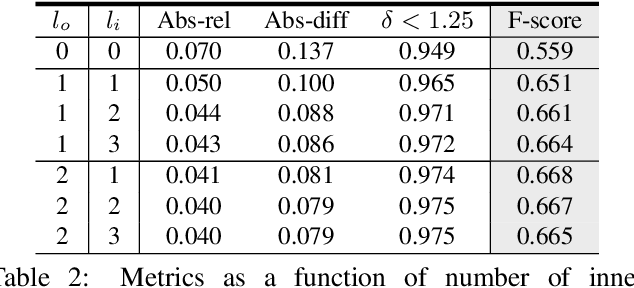
We present 3DVNet, a novel multi-view stereo (MVS) depth-prediction method that combines the advantages of previous depth-based and volumetric MVS approaches. Our key idea is the use of a 3D scene-modeling network that iteratively updates a set of coarse depth predictions, resulting in highly accurate predictions which agree on the underlying scene geometry. Unlike existing depth-prediction techniques, our method uses a volumetric 3D convolutional neural network (CNN) that operates in world space on all depth maps jointly. The network can therefore learn meaningful scene-level priors. Furthermore, unlike existing volumetric MVS techniques, our 3D CNN operates on a feature-augmented point cloud, allowing for effective aggregation of multi-view information and flexible iterative refinement of depth maps. Experimental results show our method exceeds state-of-the-art accuracy in both depth prediction and 3D reconstruction metrics on the ScanNet dataset, as well as a selection of scenes from the TUM-RGBD and ICL-NUIM datasets. This shows that our method is both effective and generalizes to new settings.
Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning
Dec 31, 2021
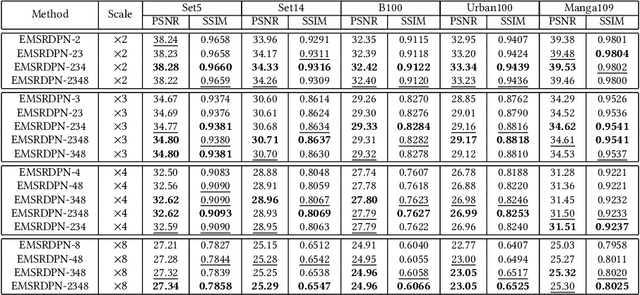
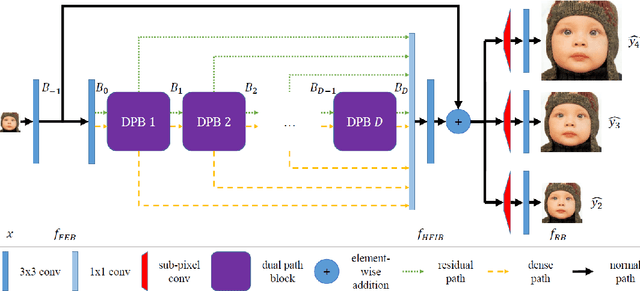
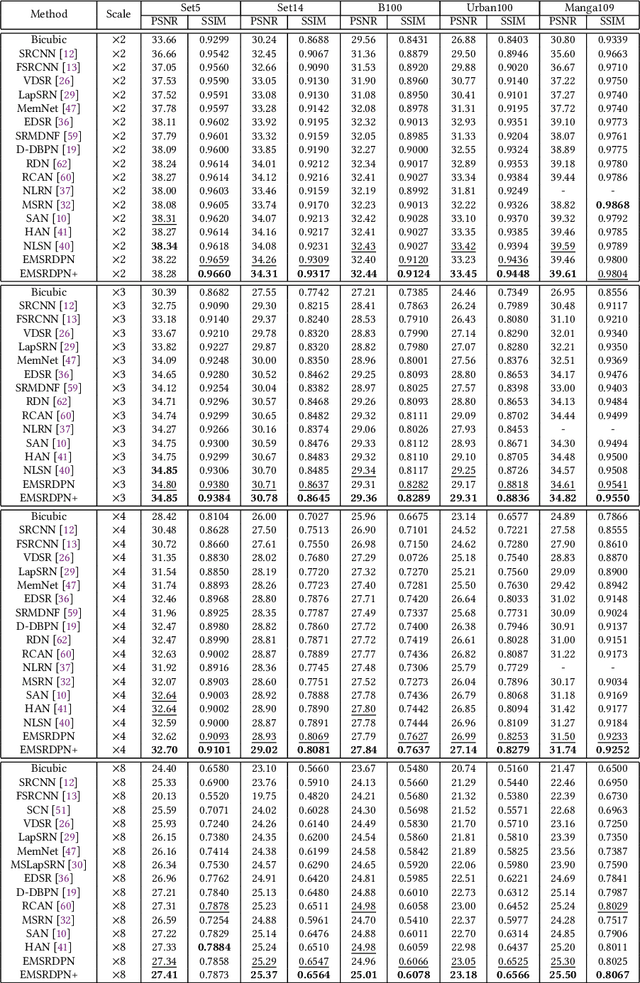
Deep convolutional neural networks have been demonstrated to be effective for SISR in recent years. On the one hand, residual connections and dense connections have been used widely to ease forward information and backward gradient flows to boost performance. However, current methods use residual connections and dense connections separately in most network layers in a sub-optimal way. On the other hand, although various networks and methods have been designed to improve computation efficiency, save parameters, or utilize training data of multiple scale factors for each other to boost performance, it either do super-resolution in HR space to have a high computation cost or can not share parameters between models of different scale factors to save parameters and inference time. To tackle these challenges, we propose an efficient single image super-resolution network using dual path connections with multiple scale learning named as EMSRDPN. By introducing dual path connections inspired by Dual Path Networks into EMSRDPN, it uses residual connections and dense connections in an integrated way in most network layers. Dual path connections have the benefits of both reusing common features of residual connections and exploring new features of dense connections to learn a good representation for SISR. To utilize the feature correlation of multiple scale factors, EMSRDPN shares all network units in LR space between different scale factors to learn shared features and only uses a separate reconstruction unit for each scale factor, which can utilize training data of multiple scale factors to help each other to boost performance, meanwhile which can save parameters and support shared inference for multiple scale factors to improve efficiency. Experiments show EMSRDPN achieves better performance and comparable or even better parameter and inference efficiency over SOTA methods.
Weakly-Supervised Opinion Summarization by Leveraging External Information
Nov 22, 2019
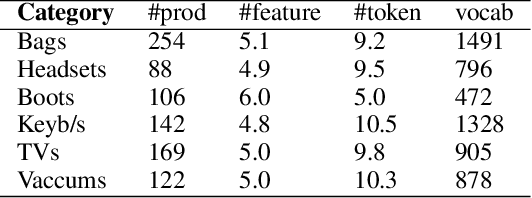

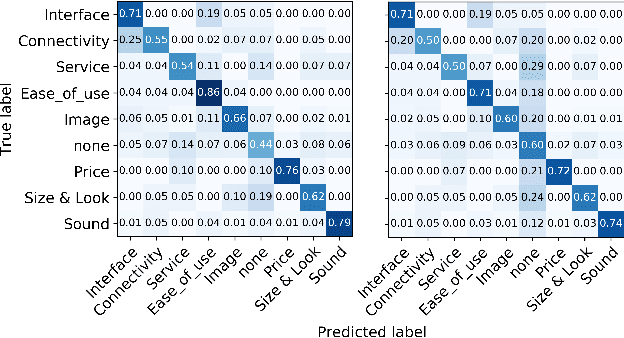
Opinion summarization from online product reviews is a challenging task, which involves identifying opinions related to various aspects of the product being reviewed. While previous works require additional human effort to identify relevant aspects, we instead apply domain knowledge from external sources to automatically achieve the same goal. This work proposes AspMem, a generative method that contains an array of memory cells to store aspect-related knowledge. This explicit memory can help obtain a better opinion representation and infer the aspect information more precisely. We evaluate this method on both aspect identification and opinion summarization tasks. Our experiments show that AspMem outperforms the state-of-the-art methods even though, unlike the baselines, it does not rely on human supervision which is carefully handcrafted for the given tasks.
Scale-aware direct monocular odometry
Sep 21, 2021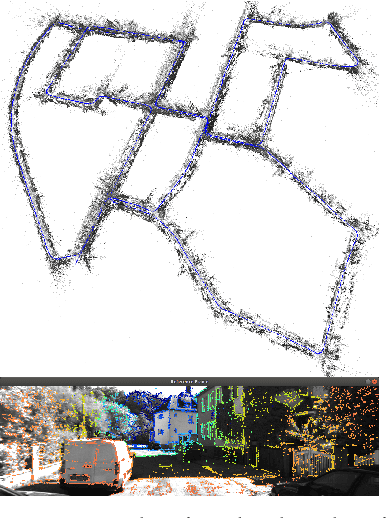
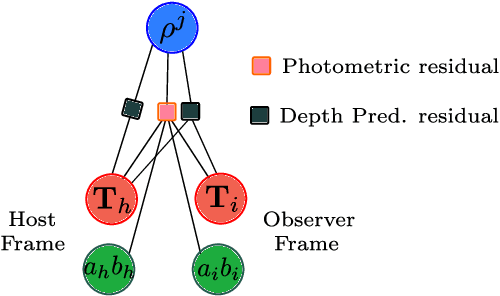
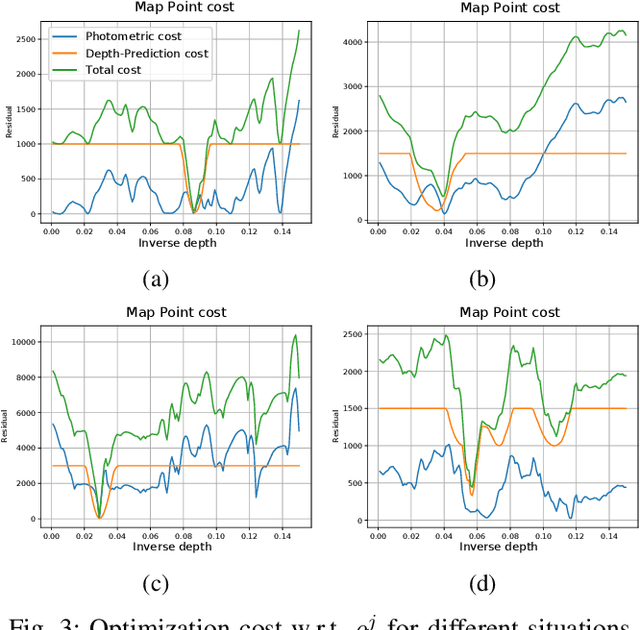
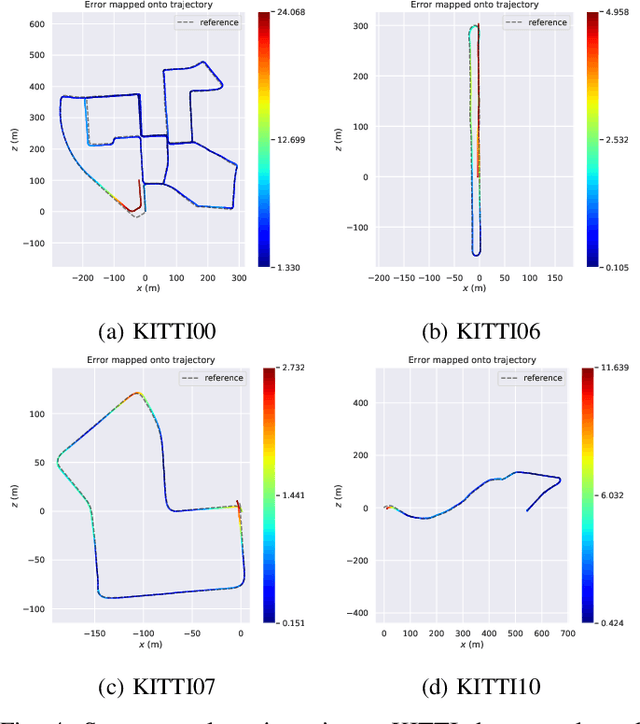
We present a framework for direct monocular odometry based on depth prediction from a deep neural network. In contrast with existing methods where depth information is only partially exploited, we formulate a novel depth prediction residual which allows us to incorporate multi-view depth information. In addition, we propose to use a truncated robust cost function which prevents considering inconsistent depth estimations. The photometric and depth-prediction measurements are integrated in a tightly-coupled optimization leading to a scale-aware monocular system which does not accumulate scale drift. We demonstrate the validity of our proposal evaluating it on the KITTI odometry dataset and comparing it with state-of-the-art monocular and stereo SLAM systems. Experiments show that our proposal largely outperforms classic monocular SLAM, being 5 to 9 times more precise, with an accuracy which is closer to that of stereo systems.
Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction
Nov 03, 2021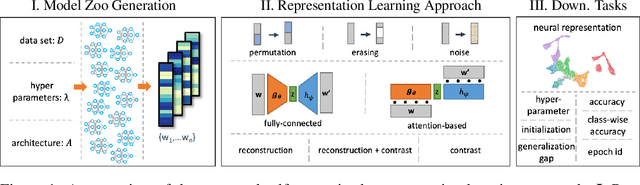
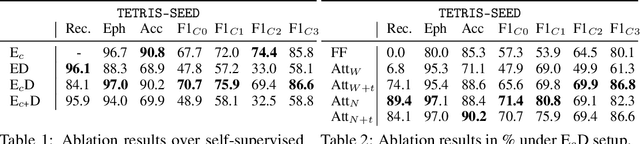
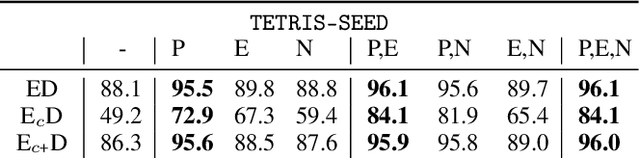
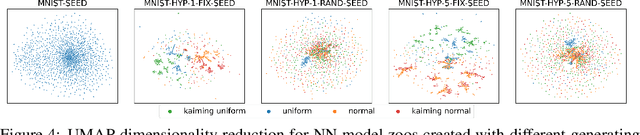
Self-Supervised Learning (SSL) has been shown to learn useful and information-preserving representations. Neural Networks (NNs) are widely applied, yet their weight space is still not fully understood. Therefore, we propose to use SSL to learn neural representations of the weights of populations of NNs. To that end, we introduce domain specific data augmentations and an adapted attention architecture. Our empirical evaluation demonstrates that self-supervised representation learning in this domain is able to recover diverse NN model characteristics. Further, we show that the proposed learned representations outperform prior work for predicting hyper-parameters, test accuracy, and generalization gap as well as transfer to out-of-distribution settings.
How does a Pre-Trained Transformer Integrate Contextual Keywords? Application to Humanitarian Computing
Nov 07, 2021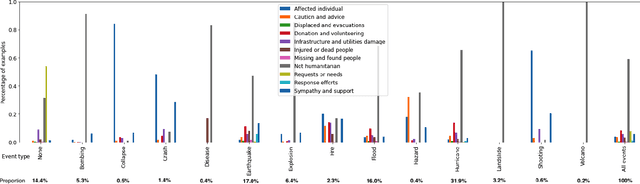
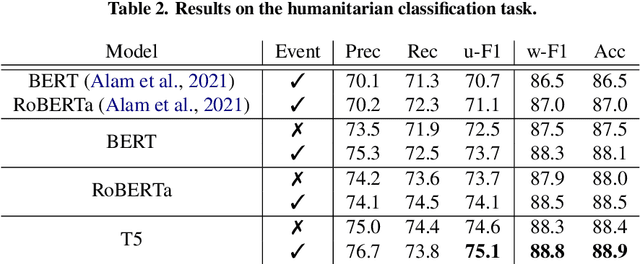
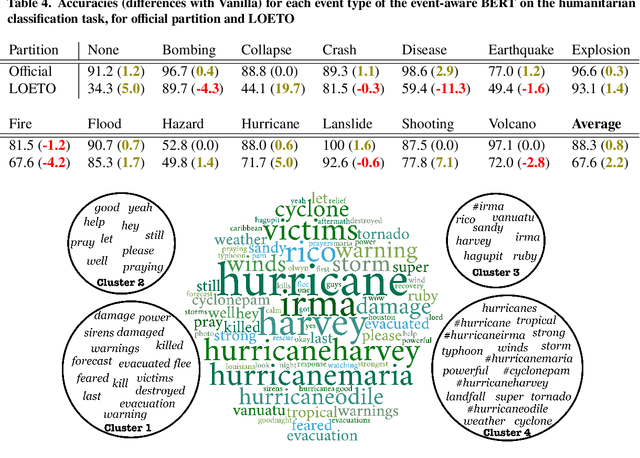
In a classification task, dealing with text snippets and metadata usually requires dealing with multimodal approaches. When those metadata are textual, it is tempting to use them intrinsically with a pre-trained transformer, in order to leverage the semantic information encoded inside the model. This paper describes how to improve a humanitarian classification task by adding the crisis event type to each tweet to be classified. Based on additional experiments of the model weights and behavior, it identifies how the proposed neural network approach is partially over-fitting the particularities of the Crisis Benchmark, to better highlight how the model is still undoubtedly learning to use and take advantage of the metadata's textual semantics.
VPN: Video Provenance Network for Robust Content Attribution
Sep 21, 2021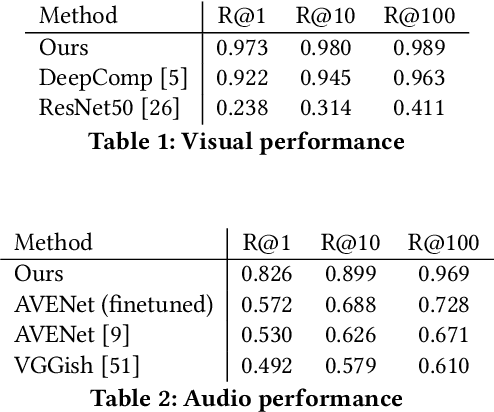
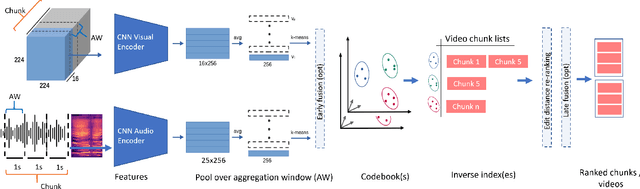
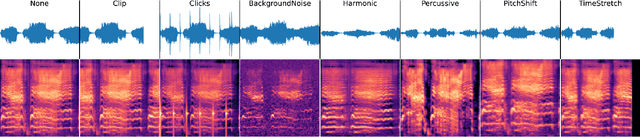

We present VPN - a content attribution method for recovering provenance information from videos shared online. Platforms, and users, often transform video into different quality, codecs, sizes, shapes, etc. or slightly edit its content such as adding text or emoji, as they are redistributed online. We learn a robust search embedding for matching such video, invariant to these transformations, using full-length or truncated video queries. Once matched against a trusted database of video clips, associated information on the provenance of the clip is presented to the user. We use an inverted index to match temporal chunks of video using late-fusion to combine both visual and audio features. In both cases, features are extracted via a deep neural network trained using contrastive learning on a dataset of original and augmented video clips. We demonstrate high accuracy recall over a corpus of 100,000 videos.
Geometry-Aware Multi-Task Learning for Binaural Audio Generation from Video
Nov 21, 2021
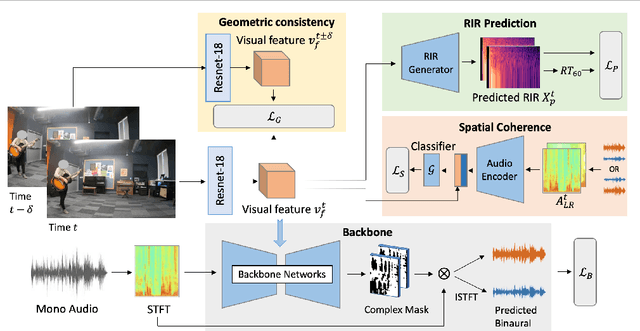
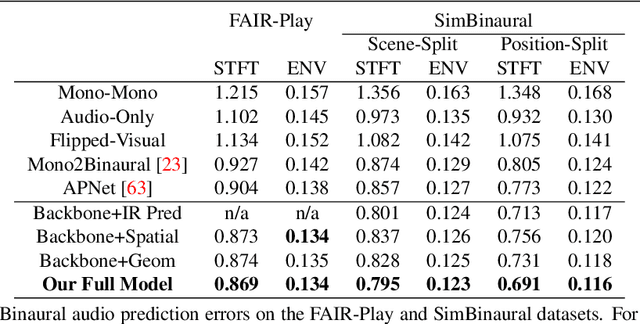

Binaural audio provides human listeners with an immersive spatial sound experience, but most existing videos lack binaural audio recordings. We propose an audio spatialization method that draws on visual information in videos to convert their monaural (single-channel) audio to binaural audio. Whereas existing approaches leverage visual features extracted directly from video frames, our approach explicitly disentangles the geometric cues present in the visual stream to guide the learning process. In particular, we develop a multi-task framework that learns geometry-aware features for binaural audio generation by accounting for the underlying room impulse response, the visual stream's coherence with the sound source(s) positions, and the consistency in geometry of the sounding objects over time. Furthermore, we introduce a new large video dataset with realistic binaural audio simulated for real-world scanned environments. On two datasets, we demonstrate the efficacy of our method, which achieves state-of-the-art results.
DSKReG: Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN
Aug 26, 2021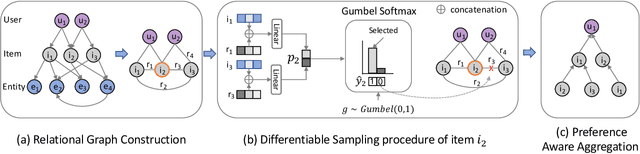
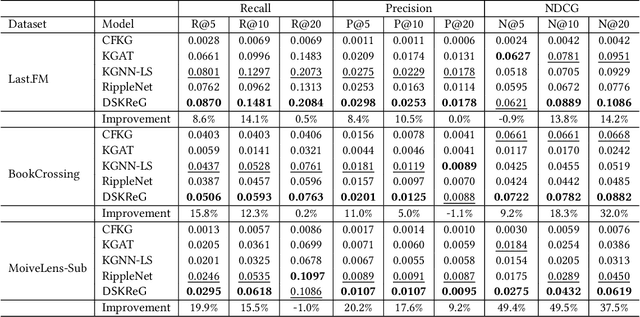
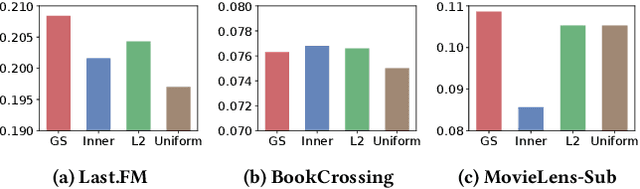
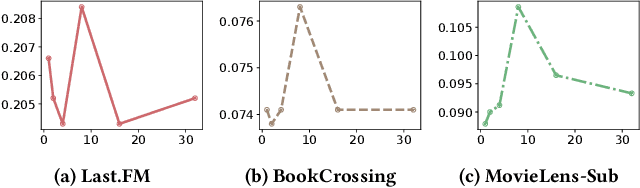
In the information explosion era, recommender systems (RSs) are widely studied and applied to discover user-preferred information. A RS performs poorly when suffering from the cold-start issue, which can be alleviated if incorporating Knowledge Graphs (KGs) as side information. However, most existing works neglect the facts that node degrees in KGs are skewed and massive amount of interactions in KGs are recommendation-irrelevant. To address these problems, in this paper, we propose Differentiable Sampling on Knowledge Graph for Recommendation with Relational GNN (DSKReG) that learns the relevance distribution of connected items from KGs and samples suitable items for recommendation following this distribution. We devise a differentiable sampling strategy, which enables the selection of relevant items to be jointly optimized with the model training procedure. The experimental results demonstrate that our model outperforms state-of-the-art KG-based recommender systems. The code is available online at https://github.com/YuWang-1024/DSKReG.