 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CLIPstyler: Image Style Transfer with a Single Text Condition
Dec 01, 2021
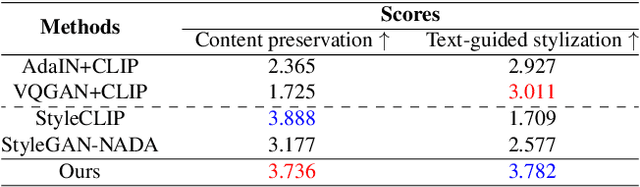
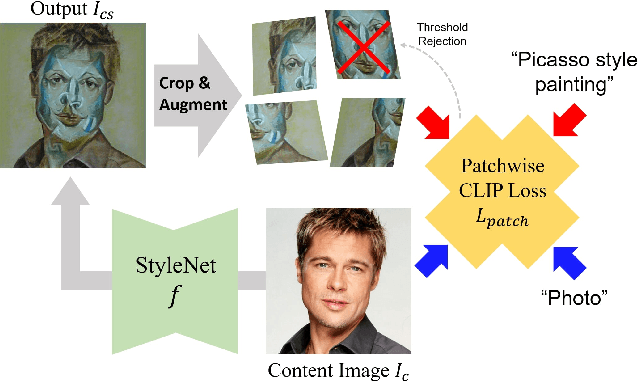


Existing neural style transfer methods require reference style images to transfer texture information of style images to content images. However, in many practical situations, users may not have reference style images but still be interested in transferring styles by just imagining them. In order to deal with such applications, we propose a new framework that enables a style transfer `without' a style image, but only with a text description of the desired style. Using the pre-trained text-image embedding model of CLIP, we demonstrate the modulation of the style of content images only with a single text condition. Specifically, we propose a patch-wise text-image matching loss with multiview augmentations for realistic texture transfer. Extensive experimental results confirmed the successful image style transfer with realistic textures that reflect semantic query texts.
Evolutionary Multitasking AUC Optimization
Jan 04, 2022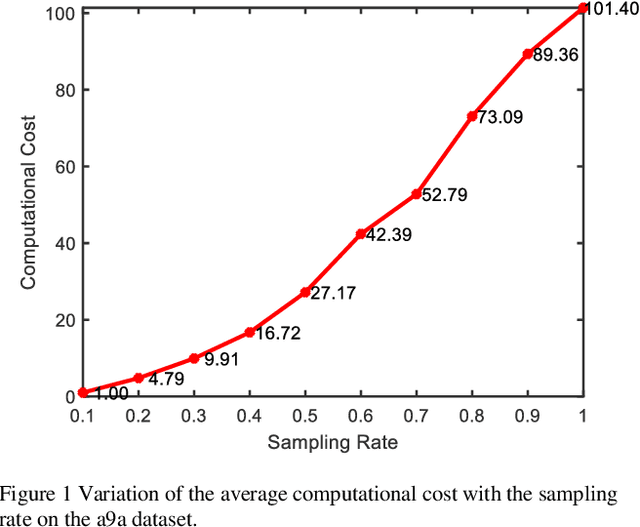
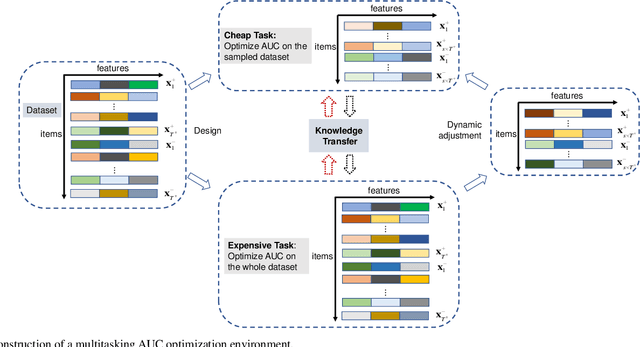
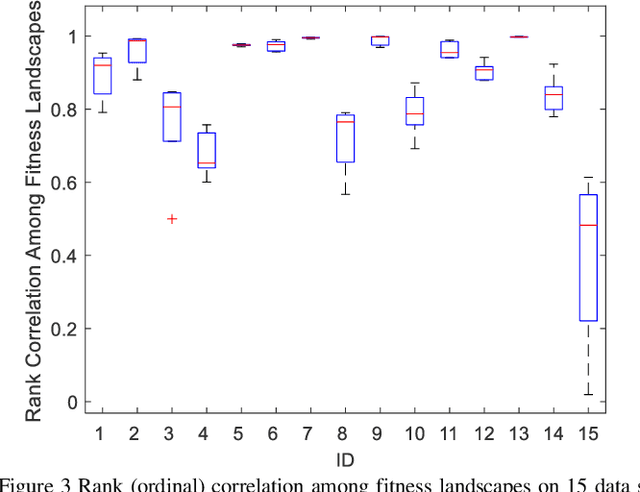
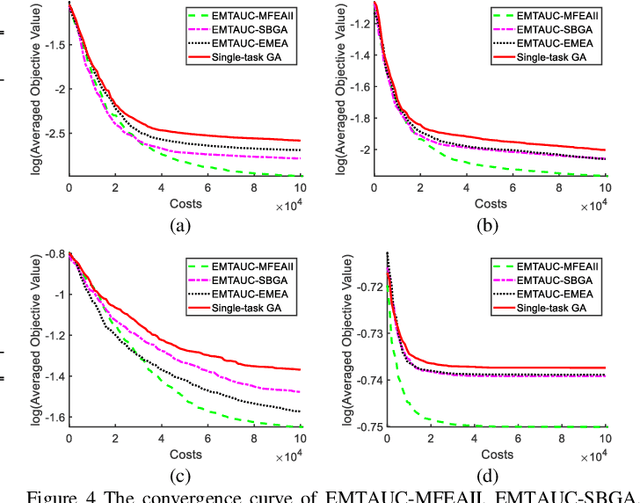
Learning to optimize the area under the receiver operating characteristics curve (AUC) performance for imbalanced data has attracted much attention in recent years. Although there have been several methods of AUC optimization, scaling up AUC optimization is still an open issue due to its pairwise learning style. Maximizing AUC in the large-scale dataset can be considered as a non-convex and expensive problem. Inspired by the characteristic of pairwise learning, the cheap AUC optimization task with a small-scale dataset sampled from the large-scale dataset is constructed to promote the AUC accuracy of the original, large-scale, and expensive AUC optimization task. This paper develops an evolutionary multitasking framework (termed EMTAUC) to make full use of information among the constructed cheap and expensive tasks to obtain higher performance. In EMTAUC, one mission is to optimize AUC from the sampled dataset, and the other is to maximize AUC from the original dataset. Moreover, due to the cheap task containing limited knowledge, a strategy for dynamically adjusting the data structure of inexpensive tasks is proposed to introduce more knowledge into the multitasking AUC optimization environment. The performance of the proposed method is evaluated on a series of binary classification datasets. The experimental results demonstrate that EMTAUC is highly competitive to single task methods and online methods. Supplementary materials and source code implementation of EMTAUC can be accessed at https://github.com/xiaofangxd/EMTAUC.
Effective prevention of semantic drift as angular distance in memory-less continual deep neural networks
Dec 16, 2021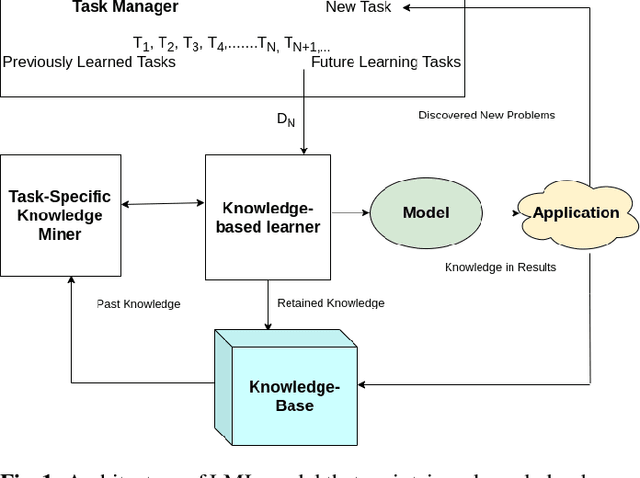
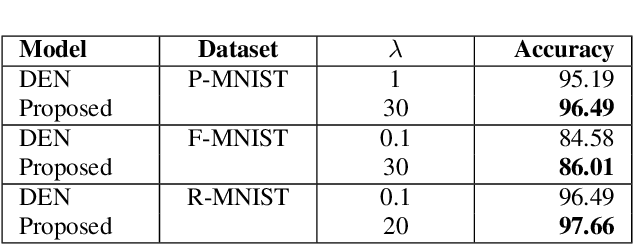

Lifelong machine learning or continual learning models attempt to learn incrementally by accumulating knowledge across a sequence of tasks. Therefore, these models learn better and faster. They are used in various intelligent systems that have to interact with humans or any dynamic environment e.g., chatbots and self-driving cars. Memory-less approach is more often used with deep neural networks that accommodates incoming information from tasks within its architecture. It allows them to perform well on all the seen tasks. These models suffer from semantic drift or the plasticity-stability dilemma. The existing models use Minkowski distance measures to decide which nodes to freeze, update or duplicate. These distance metrics do not provide better separation of nodes as they are susceptible to high dimensional sparse vectors. In our proposed approach, we use angular distance to evaluate the semantic drift in individual nodes that provide better separation of nodes and thus better balancing between stability and plasticity. The proposed approach outperforms state-of-the art models by maintaining higher accuracy on standard datasets.
High Fidelity Visualization of What Your Self-Supervised Representation Knows About
Dec 16, 2021

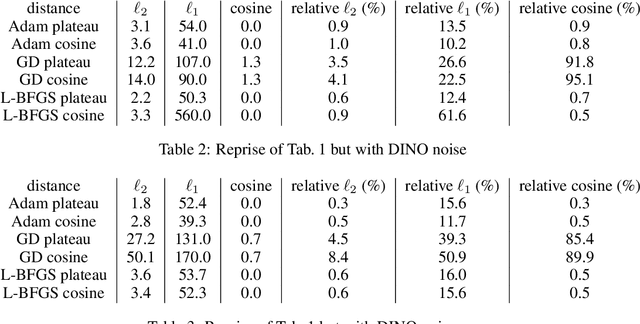

Discovering what is learned by neural networks remains a challenge. In self-supervised learning, classification is the most common task used to evaluate how good a representation is. However, relying only on such downstream task can limit our understanding of how much information is retained in the representation of a given input. In this work, we showcase the use of a conditional diffusion based generative model (RCDM) to visualize representations learned with self-supervised models. We further demonstrate how this model's generation quality is on par with state-of-the-art generative models while being faithful to the representation used as conditioning. By using this new tool to analyze self-supervised models, we can show visually that i) SSL (backbone) representation are not really invariant to many data augmentation they were trained on. ii) SSL projector embedding appear too invariant for tasks like classifications. iii) SSL representations are more robust to small adversarial perturbation of their inputs iv) there is an inherent structure learned with SSL model that can be used for image manipulation.
A Convergent ADMM Framework for Efficient Neural Network Training
Dec 22, 2021
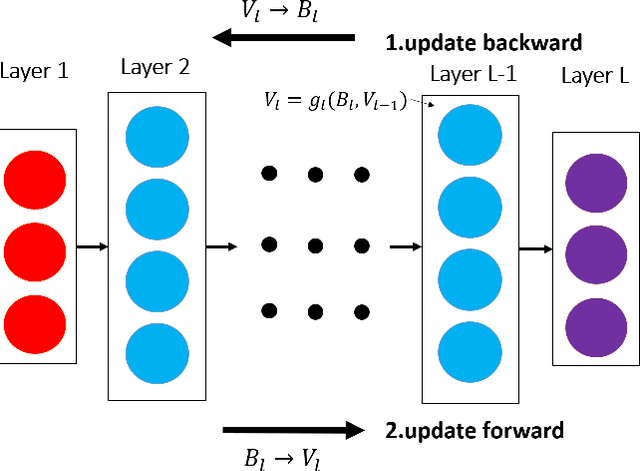

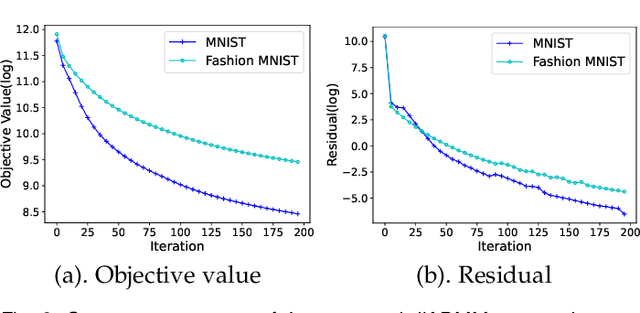
As a well-known optimization framework, the Alternating Direction Method of Multipliers (ADMM) has achieved tremendous success in many classification and regression applications. Recently, it has attracted the attention of deep learning researchers and is considered to be a potential substitute to Gradient Descent (GD). However, as an emerging domain, several challenges remain unsolved, including 1) The lack of global convergence guarantees, 2) Slow convergence towards solutions, and 3) Cubic time complexity with regard to feature dimensions. In this paper, we propose a novel optimization framework to solve a general neural network training problem via ADMM (dlADMM) to address these challenges simultaneously. Specifically, the parameters in each layer are updated backward and then forward so that parameter information in each layer is exchanged efficiently. When the dlADMM is applied to specific architectures, the time complexity of subproblems is reduced from cubic to quadratic via a dedicated algorithm design utilizing quadratic approximations and backtracking techniques. Last but not least, we provide the first proof of convergence to a critical point sublinearly for an ADMM-type method (dlADMM) under mild conditions. Experiments on seven benchmark datasets demonstrate the convergence, efficiency, and effectiveness of our proposed dlADMM algorithm.
Leveraging Sequence Embedding and Convolutional Neural Network for Protein Function Prediction
Dec 01, 2021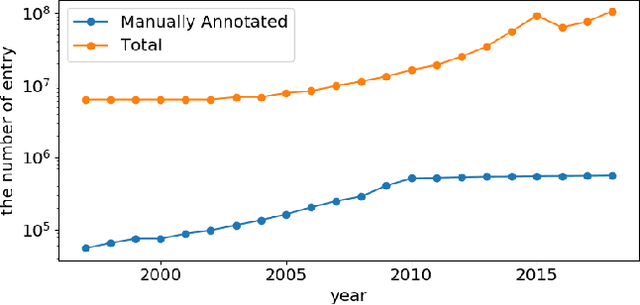
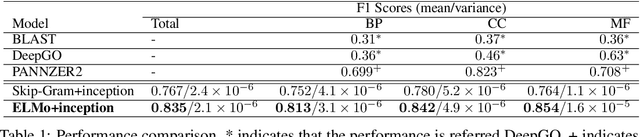
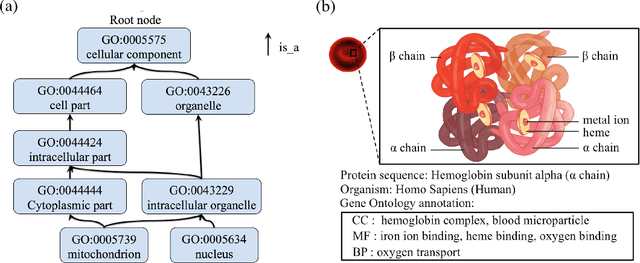
The capability of accurate prediction of protein functions and properties is essential in the biotechnology industry, e.g. drug development and artificial protein synthesis, etc. The main challenges of protein function prediction are the large label space and the lack of labeled training data. Our method leverages unsupervised sequence embedding and the success of deep convolutional neural network to overcome these challenges. In contrast, most of the existing methods delete the rare protein functions to reduce the label space. Furthermore, some existing methods require additional bio-information (e.g., the 3-dimensional structure of the proteins) which is difficult to be determined in biochemical experiments. Our proposed method significantly outperforms the other methods on the publicly available benchmark using only protein sequences as input. This allows the process of identifying protein functions to be sped up.
Multi-View Stereo with Transformer
Dec 01, 2021
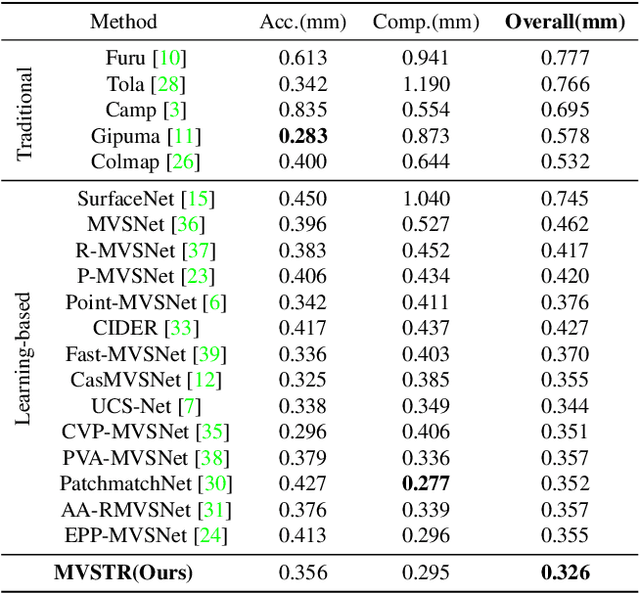
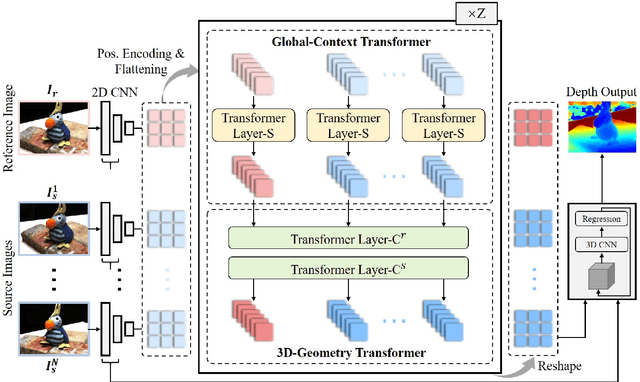
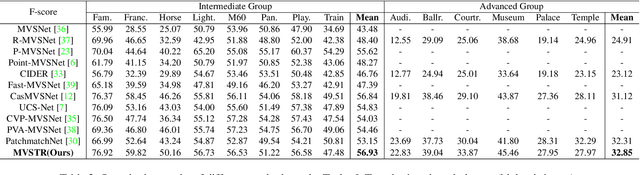
This paper proposes a network, referred to as MVSTR, for Multi-View Stereo (MVS). It is built upon Transformer and is capable of extracting dense features with global context and 3D consistency, which are crucial to achieving reliable matching for MVS. Specifically, to tackle the problem of the limited receptive field of existing CNN-based MVS methods, a global-context Transformer module is first proposed to explore intra-view global context. In addition, to further enable dense features to be 3D-consistent, a 3D-geometry Transformer module is built with a well-designed cross-view attention mechanism to facilitate inter-view information interaction. Experimental results show that the proposed MVSTR achieves the best overall performance on the DTU dataset and strong generalization on the Tanks & Temples benchmark dataset.
Robust Linear Classification from Limited Training Data
Oct 04, 2021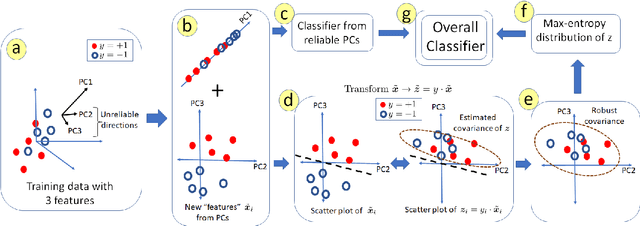
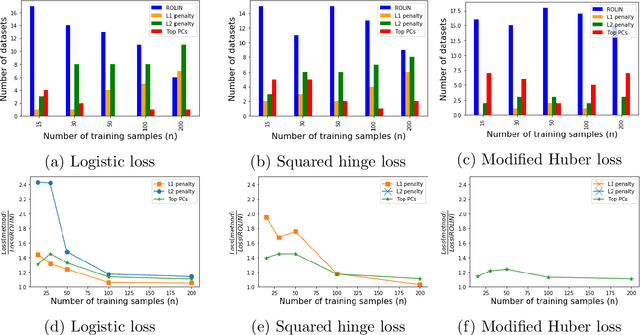
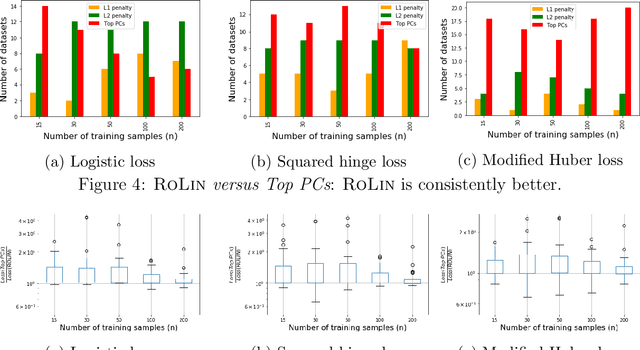
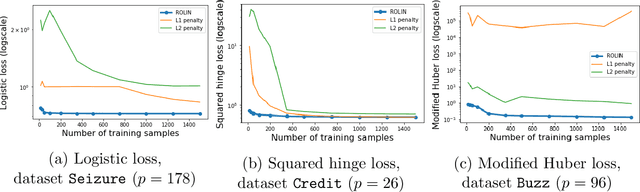
We consider the problem of linear classification under general loss functions in the limited-data setting. Overfitting is a common problem here. The standard approaches to prevent overfitting are dimensionality reduction and regularization. But dimensionality reduction loses information, while regularization requires the user to choose a norm, or a prior, or a distance metric. We propose an algorithm called RoLin that needs no user choice and applies to a large class of loss functions. RoLin combines reliable information from the top principal components with a robust optimization to extract any useful information from unreliable subspaces. It also includes a new robust cross-validation that is better than existing cross-validation methods in the limited-data setting. Experiments on $25$ real-world datasets and three standard loss functions show that RoLin broadly outperforms both dimensionality reduction and regularization. Dimensionality reduction has $14\%-40\%$ worse test loss on average as compared to RoLin. Against $L_1$ and $L_2$ regularization, RoLin can be up to 3x better for logistic loss and 12x better for squared hinge loss. The differences are greatest for small sample sizes, where RoLin achieves the best loss on 2x to 3x more datasets than any competing method. For some datasets, RoLin with $15$ training samples is better than the best norm-based regularization with $1500$ samples.
State of Security and Privacy Practices of Top Websites in the East African Community (EAC)
Oct 13, 2021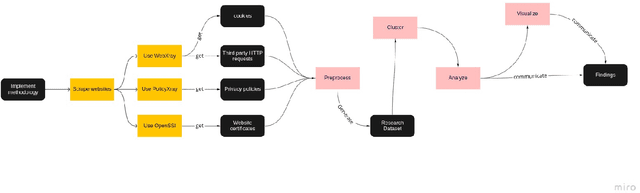
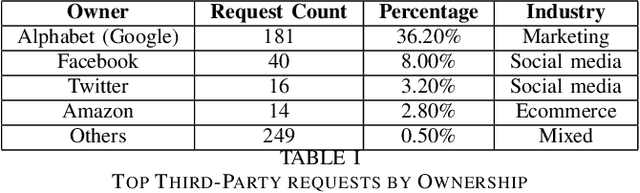
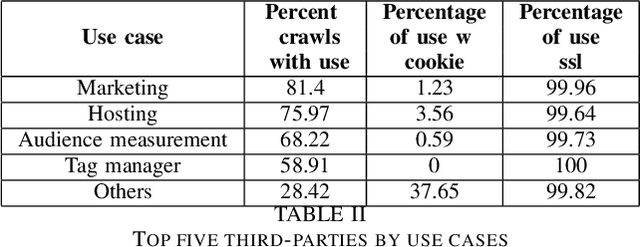
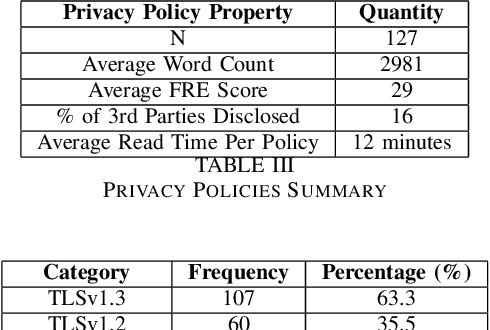
Growth in technology has resulted in the large-scale collection and processing of Personally Identifiable Information by organizations that run digital services such as websites, which led to the emergence of new legislation to regulate PII collection and processing by organizations. Subsequently, several African countries have recently started enacting new data protection regulations due to recent technological innovations. However, there is little information about the security and privacy practices of top websites serving content to EAC citizens. We, therefore, analyze the website operators' patterns in terms of third-party tracking, security of data transmission, cookie information, and privacy policies for 169 top EAC website operators using WebXray, OpenSSL, and Alexa top websites API. Our results show that only 75 percent of the analyzed websites have a privacy policy in place. Out of this, only 16 percent of the third-party tracking companies that track users on a particular website are disclosed in the site's privacy policy statements which means that users don not have a way of knowing which third parties collect data about them when they visit a website. Such privacy policies take time to read and are difficult to understand; on average, it takes a college graduate to comprehend the policy and a user spends 12 minutes to read the policy. Additionally, most third-party tracking on EAC websites is related to advertisement and belongs to companies outside the EAC. This means that EAC lawmakers need to enact suitable laws to ensure that people's privacy is protected as the rate of technology adoption continues to increase.
Soft-Output Joint Channel Estimation and Data Detection using Deep Unfolding
Dec 01, 2021
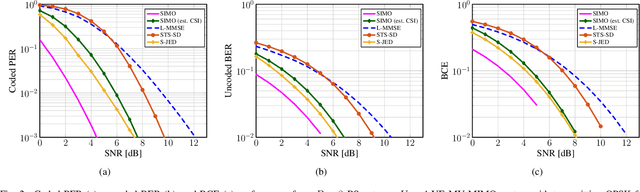
We propose a novel soft-output joint channel estimation and data detection (JED) algorithm for multiuser (MU) multiple-input multiple-output (MIMO) wireless communication systems. Our algorithm approximately solves a maximum a-posteriori JED optimization problem using deep unfolding and generates soft-output information for the transmitted bits in every iteration. The parameters of the unfolded algorithm are computed by a hyper-network that is trained with a binary cross entropy (BCE) loss. We evaluate the performance of our algorithm in a coded MU-MIMO system with 8 basestation antennas and 4 user equipments and compare it to state-of-the-art algorithms separate channel estimation from soft-output data detection. Our results demonstrate that our JED algorithm outperforms such data detectors with as few as 10 iterations.