 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Rebooting ACGAN: Auxiliary Classifier GANs with Stable Training
Nov 01, 2021
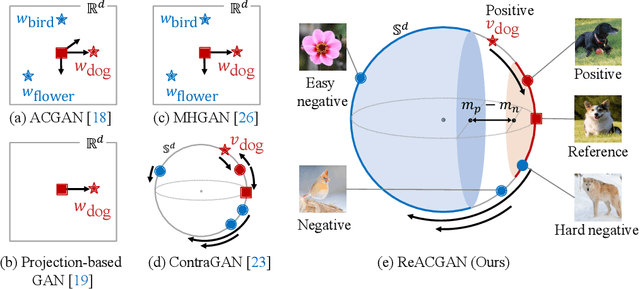
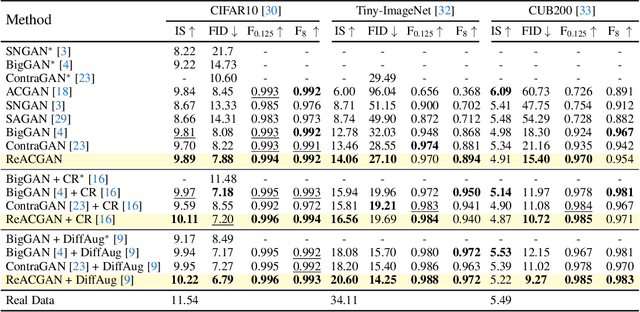
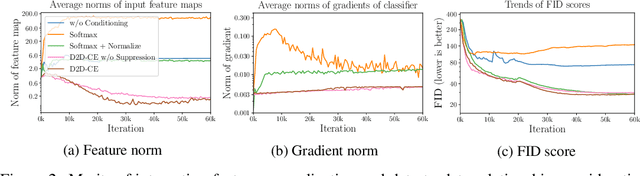
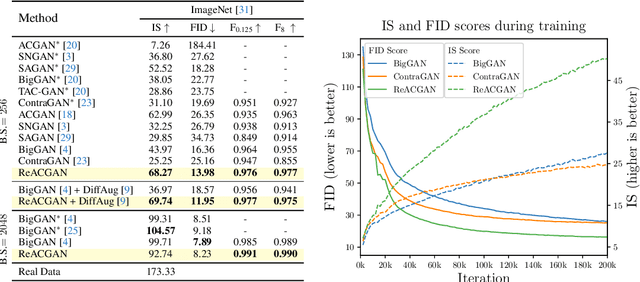
Conditional Generative Adversarial Networks (cGAN) generate realistic images by incorporating class information into GAN. While one of the most popular cGANs is an auxiliary classifier GAN with softmax cross-entropy loss (ACGAN), it is widely known that training ACGAN is challenging as the number of classes in the dataset increases. ACGAN also tends to generate easily classifiable samples with a lack of diversity. In this paper, we introduce two cures for ACGAN. First, we identify that gradient exploding in the classifier can cause an undesirable collapse in early training, and projecting input vectors onto a unit hypersphere can resolve the problem. Second, we propose the Data-to-Data Cross-Entropy loss (D2D-CE) to exploit relational information in the class-labeled dataset. On this foundation, we propose the Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). The experimental results show that ReACGAN achieves state-of-the-art generation results on CIFAR10, Tiny-ImageNet, CUB200, and ImageNet datasets. We also verify that ReACGAN benefits from differentiable augmentations and that D2D-CE harmonizes with StyleGAN2 architecture. Model weights and a software package that provides implementations of representative cGANs and all experiments in our paper are available at https://github.com/POSTECH-CVLab/PyTorch-StudioGAN.
Guiding Non-Autoregressive Neural Machine Translation Decoding with Reordering Information
Nov 06, 2019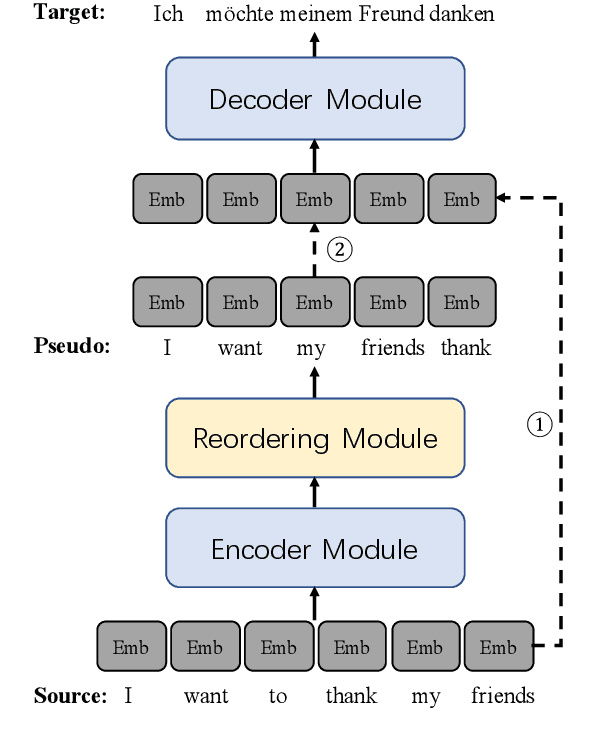
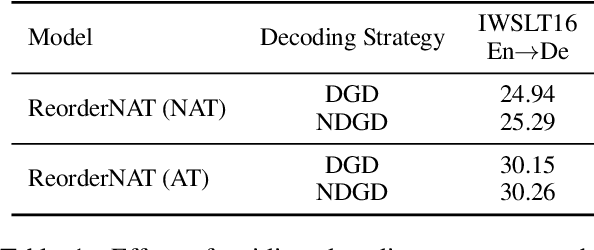
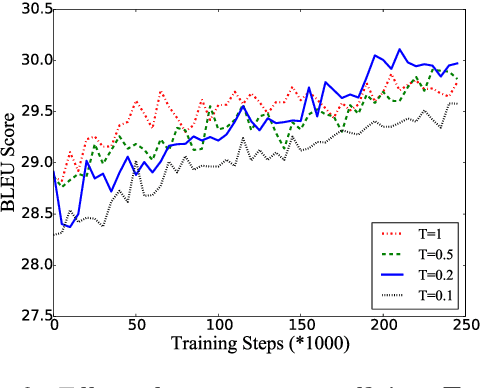
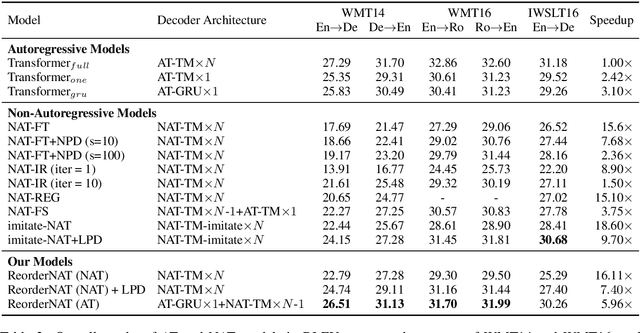
Non-autoregressive neural machine translation (NAT) generates each target word in parallel and has achieved promising inference acceleration. However, existing NAT models still have a big gap in translation quality compared to autoregressive neural machine translation models due to the enormous decoding space. To address this problem, we propose a novel NAT framework named ReorderNAT which explicitly models the reordering information in the decoding procedure. We further introduce deterministic and non-deterministic decoding strategies that utilize reordering information to narrow the decoding search space in our proposed ReorderNAT. Experimental results on various widely-used datasets show that our proposed model achieves better performance compared to existing NAT models, and even achieves comparable translation quality as autoregressive translation models with a significant speedup.
Partial recovery and weak consistency in the non-uniform hypergraph Stochastic Block Model
Dec 22, 2021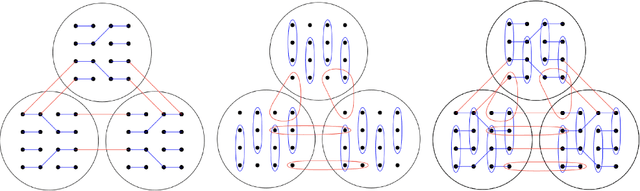
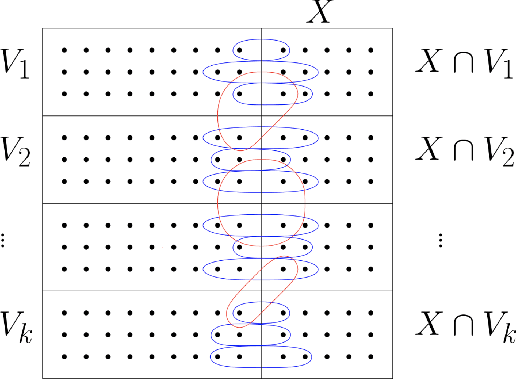
We consider the community detection problem in sparse random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), a general model of random networks with community structure and higher-order interactions. When the random hypergraph has bounded expected degrees, we provide a spectral algorithm that outputs a partition with at least a $\gamma$ fraction of the vertices classified correctly, where $\gamma\in (0.5,1)$ depends on the signal-to-noise ratio (SNR) of the model. When the SNR grows slowly as the number of vertices goes to infinity, our algorithm achieves weak consistency, which improves the previous results in Ghoshdastidar and Dukkipati (2017) for non-uniform HSBMs. Our spectral algorithm consists of three major steps: (1) Hyperedge selection: select hyperedges of certain sizes to provide the maximal signal-to-noise ratio for the induced sub-hypergraph; (2) Spectral partition: construct a regularized adjacency matrix and obtain an approximate partition based on singular vectors; (3) Correction and merging: incorporate the hyperedge information from adjacency tensors to upgrade the error rate guarantee. The theoretical analysis of our algorithm relies on the concentration and regularization of the adjacency matrix for sparse non-uniform random hypergraphs, which can be of independent interest.
CamLessMonoDepth: Monocular Depth Estimation with Unknown Camera Parameters
Oct 27, 2021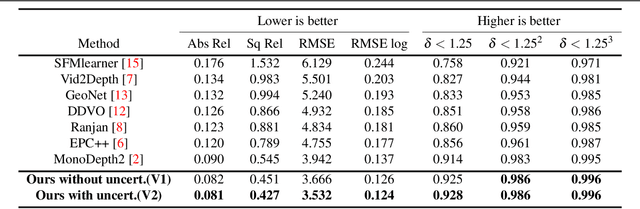
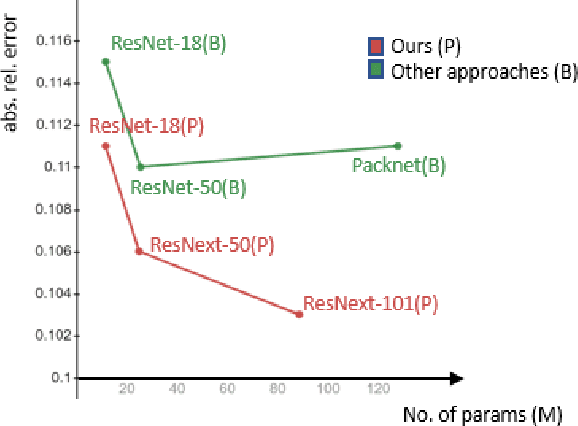
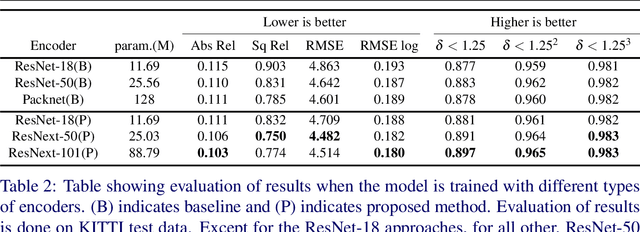
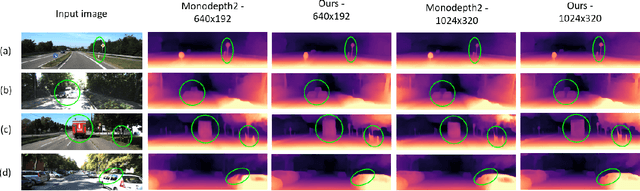
Perceiving 3D information is of paramount importance in many applications of computer vision. Recent advances in monocular depth estimation have shown that gaining such knowledge from a single camera input is possible by training deep neural networks to predict inverse depth and pose, without the necessity of ground truth data. The majority of such approaches, however, require camera parameters to be fed explicitly during training. As a result, image sequences from wild cannot be used during training. While there exist methods which also predict camera intrinsics, their performance is not on par with novel methods taking camera parameters as input. In this work, we propose a method for implicit estimation of pinhole camera intrinsics along with depth and pose, by learning from monocular image sequences alone. In addition, by utilizing efficient sub-pixel convolutions, we show that high fidelity depth estimates can be obtained. We also embed pixel-wise uncertainty estimation into the framework, to emphasize the possible applicability of this work in practical domain. Finally, we demonstrate the possibility of accurate prediction of depth information without prior knowledge of camera intrinsics, while outperforming the existing state-of-the-art approaches on KITTI benchmark.
Improving Zero-Shot Translation by Disentangling Positional Information
Dec 30, 2020
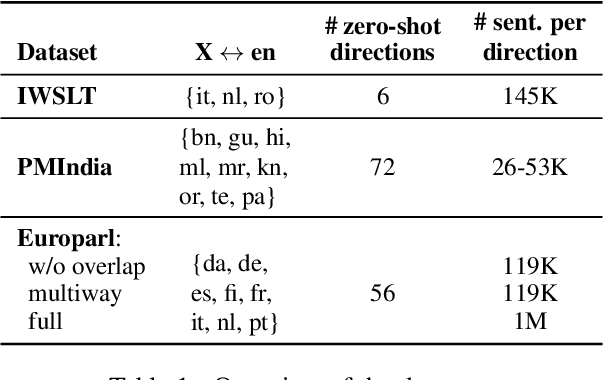
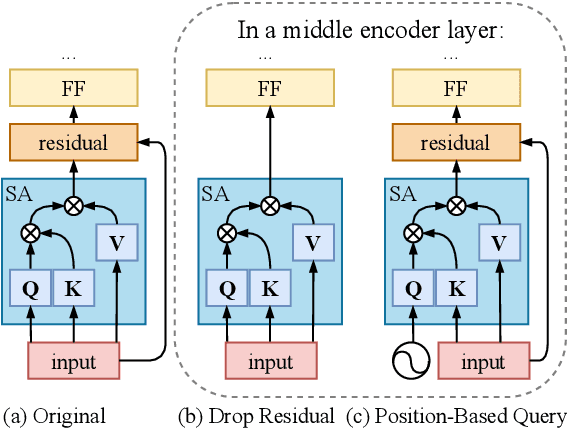

Multilingual neural machine translation has shown the capability of directly translating between language pairs unseen in training, i.e. zero-shot translation. Despite being conceptually attractive, it often suffers from low output quality. The difficulty of generalizing to new translation directions suggests the model representations are highly specific to those language pairs seen in training. We demonstrate that a main factor causing the language-specific representations is the positional correspondence to input tokens. We show that this can be easily alleviated by removing residual connections in an encoder layer. With this modification, we gain up to 18.5 BLEU points on zero-shot translation while retaining quality on supervised directions. The improvements are particularly prominent between related languages, where our proposed model outperforms pivot-based translation. Moreover, our approach allows easy integration of new languages, which substantially expands translation coverage. By thorough inspections of the hidden layer outputs, we show that our approach indeed leads to more language-independent representations.
Patent Sentiment Analysis to Highlight Patent Paragraphs
Nov 06, 2021
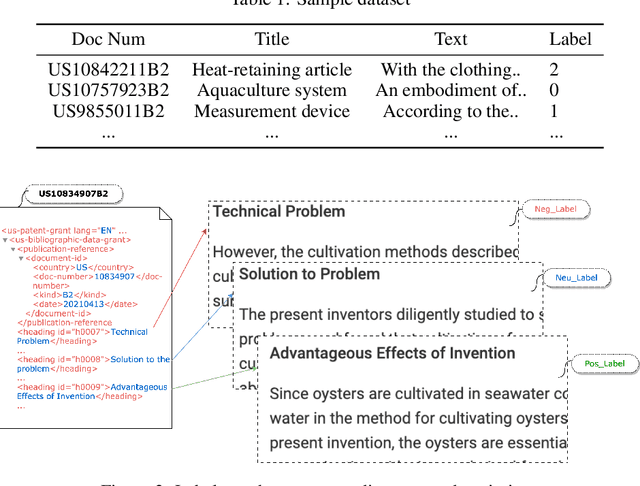
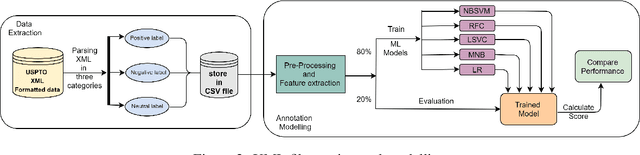
Given a patent document, identifying distinct semantic annotations is an interesting research aspect. Text annotation helps the patent practitioners such as examiners and patent attorneys to quickly identify the key arguments of any invention, successively providing a timely marking of a patent text. In the process of manual patent analysis, to attain better readability, recognising the semantic information by marking paragraphs is in practice. This semantic annotation process is laborious and time-consuming. To alleviate such a problem, we proposed a novel dataset to train Machine Learning algorithms to automate the highlighting process. The contributions of this work are: i) we developed a multi-class, novel dataset of size 150k samples by traversing USPTO patents over a decade, ii) articulated statistics and distributions of data using imperative exploratory data analysis, iii) baseline Machine Learning models are developed to utilize the dataset to address patent paragraph highlighting task, iv) dataset and codes relating to this task are open-sourced through a dedicated GIT web page: https://github.com/Renuk9390/Patent_Sentiment_Analysis and v) future path to extend this work using Deep Learning and domain specific pre-trained language models to develop a tool to highlight is provided. This work assist patent practitioners in highlighting semantic information automatically and aid to create a sustainable and efficient patent analysis using the aptitude of Machine Learning.
Information-based inference for singular models and finite sample sizes: A frequentist information criterion
Jun 08, 2018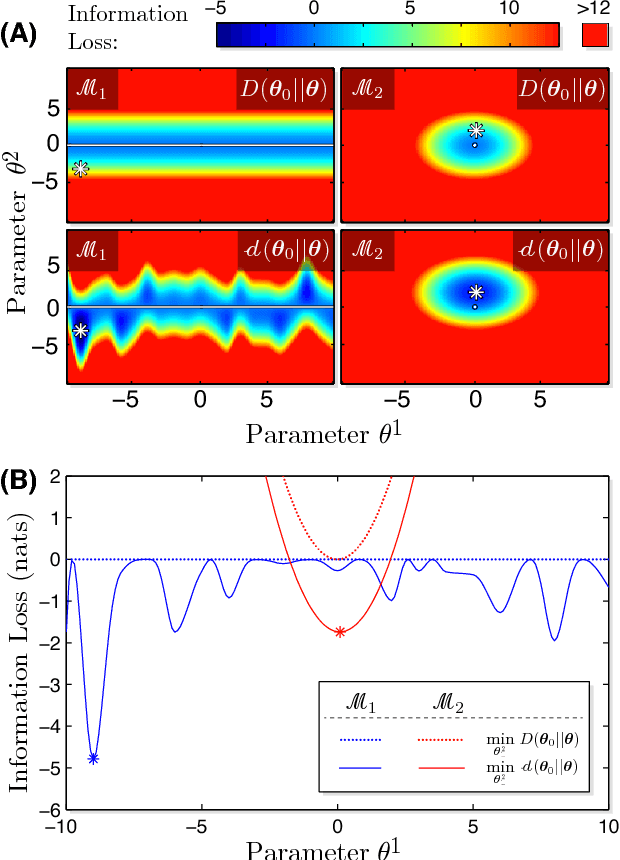
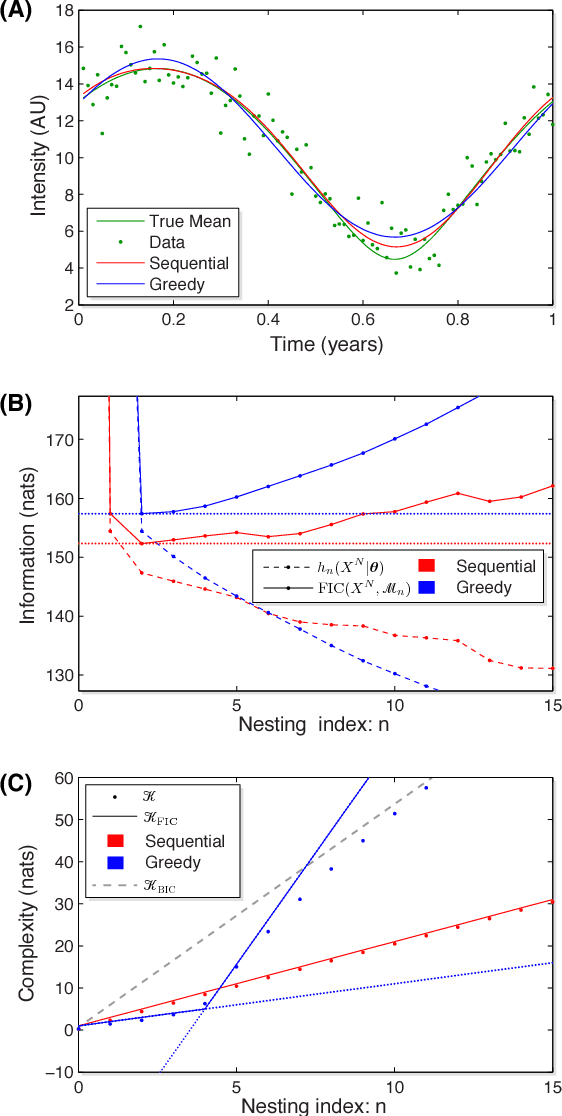
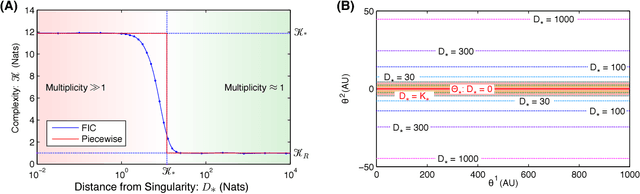
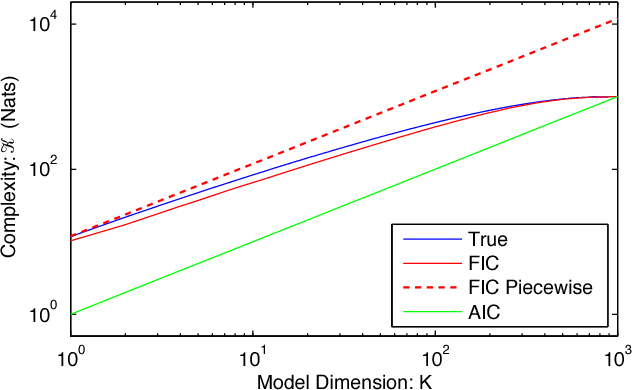
In the information-based paradigm of inference, model selection is performed by selecting the candidate model with the best estimated predictive performance. The success of this approach depends on the accuracy of the estimate of the predictive complexity. In the large-sample-size limit of a regular model, the predictive performance is well estimated by the Akaike Information Criterion (AIC). However, this approximation can either significantly under or over-estimating the complexity in a wide range of important applications where models are either non-regular or finite-sample-size corrections are significant. We introduce an improved approximation for the complexity that is used to define a new information criterion: the Frequentist Information Criterion (QIC). QIC extends the applicability of information-based inference to the finite-sample-size regime of regular models and to singular models. We demonstrate the power and the comparative advantage of QIC in a number of example analyses.
A Crawler Architecture for Harvesting the Clear, Social, and Dark Web for IoT-Related Cyber-Threat Intelligence
Sep 14, 2021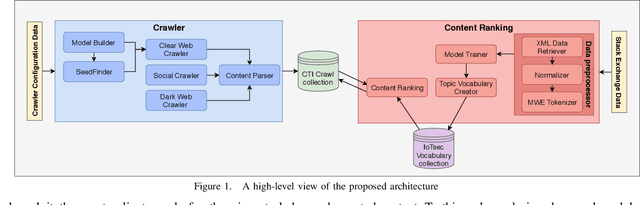

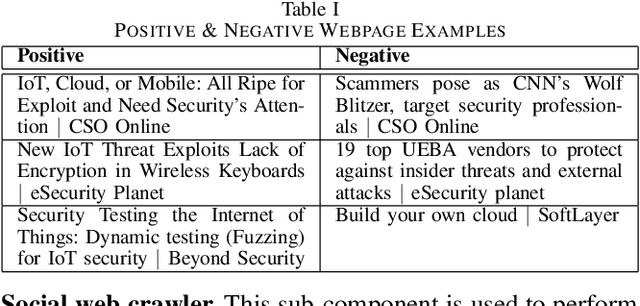

The clear, social, and dark web have lately been identified as rich sources of valuable cyber-security information that -given the appropriate tools and methods-may be identified, crawled and subsequently leveraged to actionable cyber-threat intelligence. In this work, we focus on the information gathering task, and present a novel crawling architecture for transparently harvesting data from security websites in the clear web, security forums in the social web, and hacker forums/marketplaces in the dark web. The proposed architecture adopts a two-phase approach to data harvesting. Initially a machine learning-based crawler is used to direct the harvesting towards websites of interest, while in the second phase state-of-the-art statistical language modelling techniques are used to represent the harvested information in a latent low-dimensional feature space and rank it based on its potential relevance to the task at hand. The proposed architecture is realised using exclusively open-source tools, and a preliminary evaluation with crowdsourced results demonstrates its effectiveness.
* 6 pages, 2 figures
Controllable and Interpretable Singing Voice Decomposition via Assem-VC
Oct 25, 2021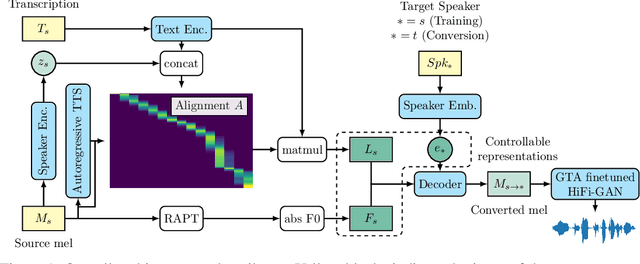

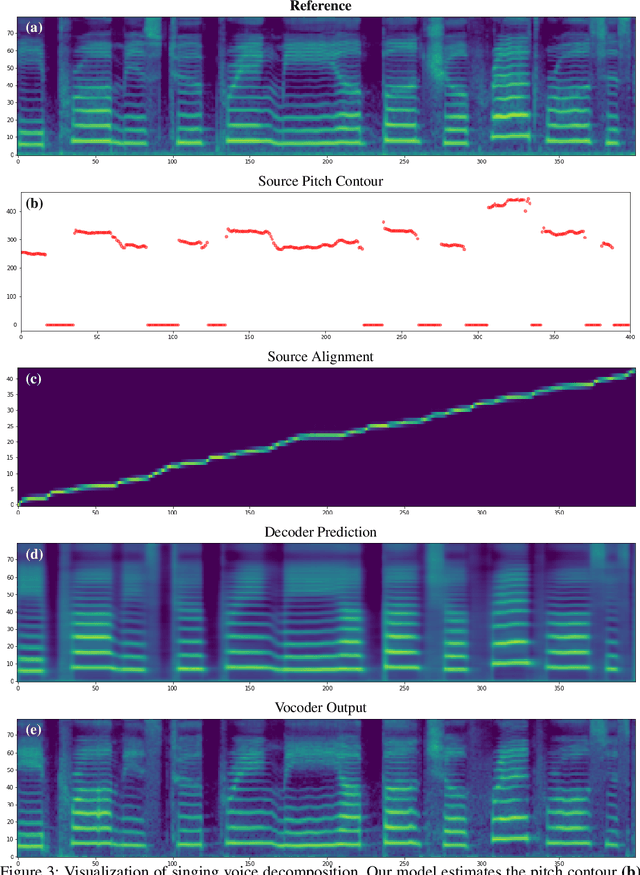
We propose a singing decomposition system that encodes time-aligned linguistic content, pitch, and source speaker identity via Assem-VC. With decomposed speaker-independent information and the target speaker's embedding, we could synthesize the singing voice of the target speaker. In conclusion, we made a perfectly synced duet with the user's singing voice and the target singer's converted singing voice.
CLIPstyler: Image Style Transfer with a Single Text Condition
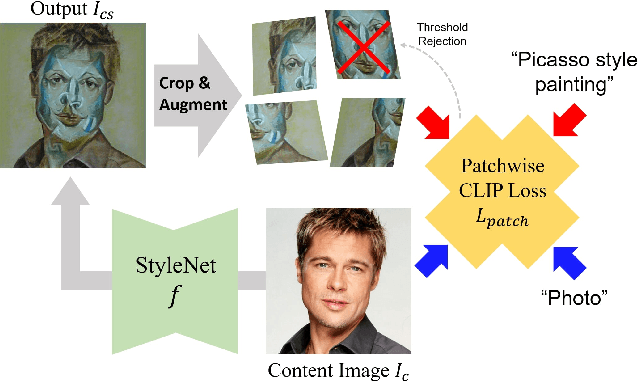
Dec 01, 2021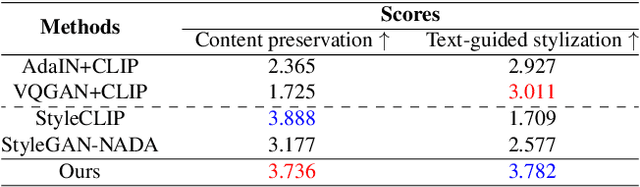


Existing neural style transfer methods require reference style images to transfer texture information of style images to content images. However, in many practical situations, users may not have reference style images but still be interested in transferring styles by just imagining them. In order to deal with such applications, we propose a new framework that enables a style transfer `without' a style image, but only with a text description of the desired style. Using the pre-trained text-image embedding model of CLIP, we demonstrate the modulation of the style of content images only with a single text condition. Specifically, we propose a patch-wise text-image matching loss with multiview augmentations for realistic texture transfer. Extensive experimental results confirmed the successful image style transfer with realistic textures that reflect semantic query texts.