 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-based inference for singular models and finite sample sizes: A frequentist information criterion
Jun 08, 2018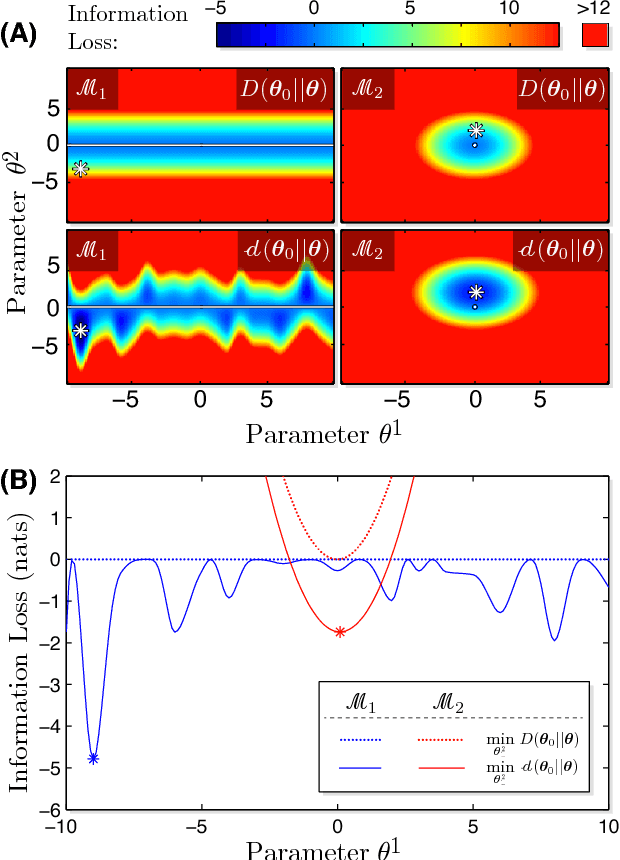
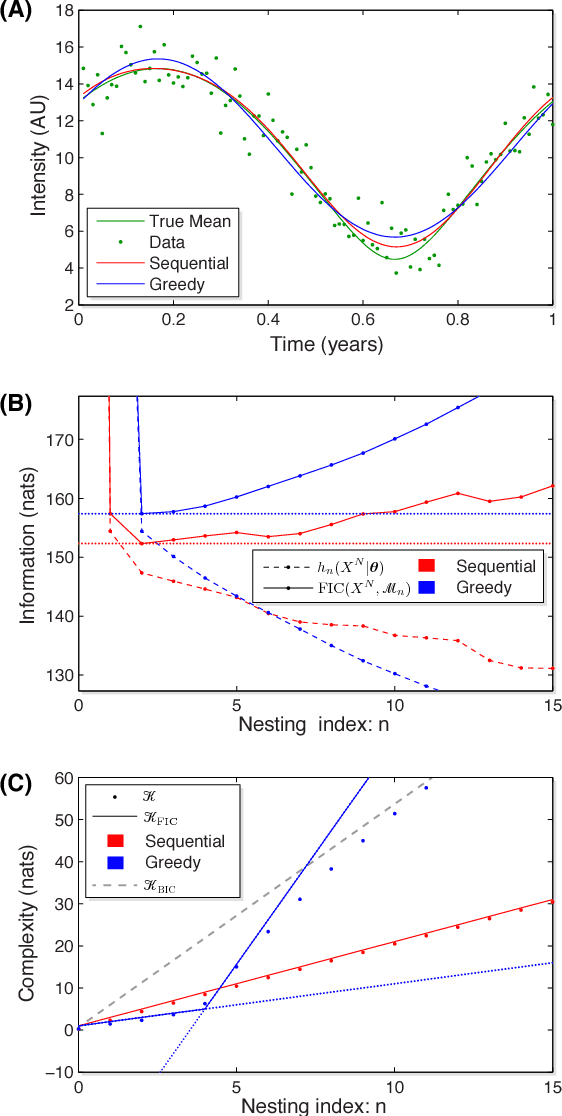
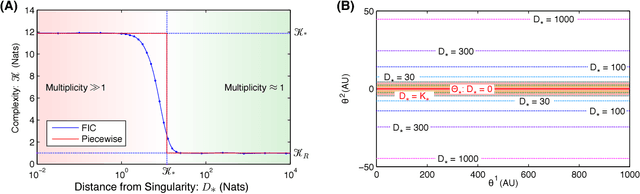
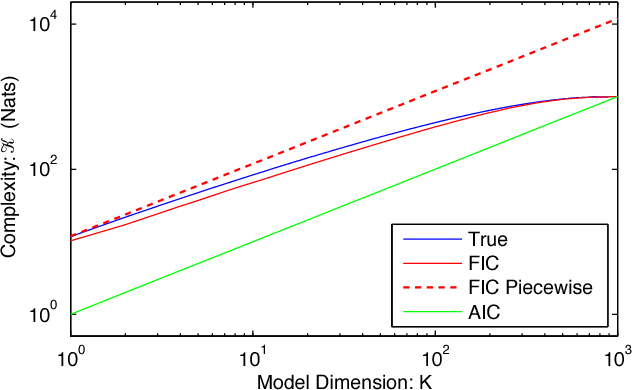
In the information-based paradigm of inference, model selection is performed by selecting the candidate model with the best estimated predictive performance. The success of this approach depends on the accuracy of the estimate of the predictive complexity. In the large-sample-size limit of a regular model, the predictive performance is well estimated by the Akaike Information Criterion (AIC). However, this approximation can either significantly under or over-estimating the complexity in a wide range of important applications where models are either non-regular or finite-sample-size corrections are significant. We introduce an improved approximation for the complexity that is used to define a new information criterion: the Frequentist Information Criterion (QIC). QIC extends the applicability of information-based inference to the finite-sample-size regime of regular models and to singular models. We demonstrate the power and the comparative advantage of QIC in a number of example analyses.
An objective prior that unifies objective Bayes and information-based inference
Jun 25, 2015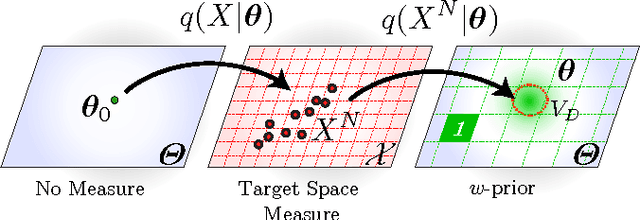
There are three principle paradigms of statistical inference: (i) Bayesian, (ii) information-based and (iii) frequentist inference. We describe an objective prior (the weighting or $w$-prior) which unifies objective Bayes and information-based inference. The $w$-prior is chosen to make the marginal probability an unbiased estimator of the predictive performance of the model. This definition has several other natural interpretations. From the perspective of the information content of the prior, the $w$-prior is both uniformly and maximally uninformative. The $w$-prior can also be understood to result in a uniform density of distinguishable models in parameter space. Finally we demonstrate the the $w$-prior is equivalent to the Akaike Information Criterion (AIC) for regular models in the asymptotic limit. The $w$-prior appears to be generically applicable to statistical inference and is free of {\it ad hoc} regularization. The mechanism for suppressing complexity is analogous to AIC: model complexity reduces model predictivity. We expect this new objective-Bayes approach to inference to be widely-applicable to machine-learning problems including singular models.
A simple application of FIC to model selection
Jun 19, 2015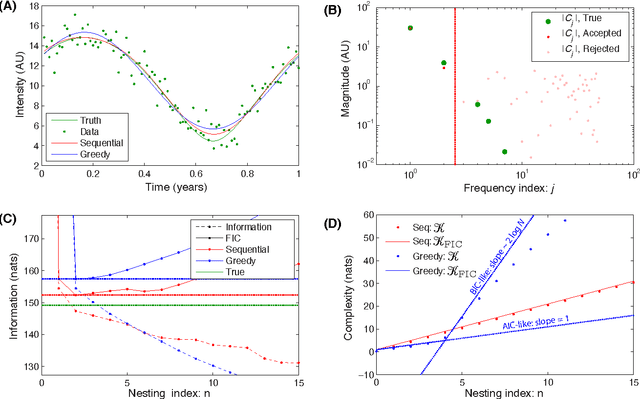
We have recently proposed a new information-based approach to model selection, the Frequentist Information Criterion (FIC), that reconciles information-based and frequentist inference. The purpose of this current paper is to provide a simple example of the application of this criterion and a demonstration of the natural emergence of model complexities with both AIC-like ($N^0$) and BIC-like ($\log N$) scaling with observation number $N$. The application developed is deliberately simplified to make the analysis analytically tractable.
The development of an information criterion for Change-Point Analysis
May 21, 2015Change-point analysis is a flexible and computationally tractable tool for the analysis of times series data from systems that transition between discrete states and whose observables are corrupted by noise. The change-point algorithm is used to identify the time indices (change points) at which the system transitions between these discrete states. We present a unified information-based approach to testing for the existence of change points. This new approach reconciles two previously disparate approaches to Change-Point Analysis (frequentist and information-based) for testing transitions between states. The resulting method is statistically principled, parameter and prior free and widely applicable to a wide range of change-point problems.