 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-Shot Translation by Disentangling Positional Information
Paper and Code
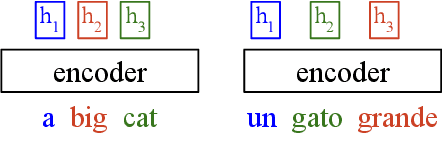
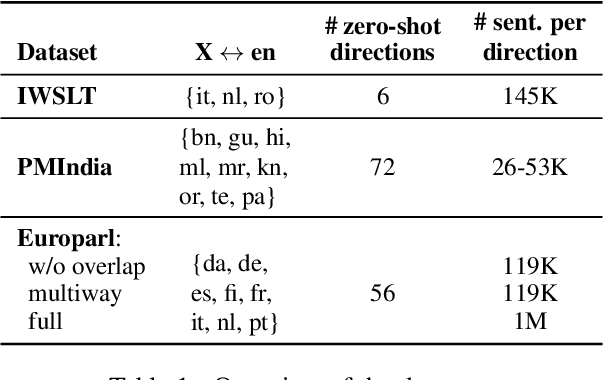
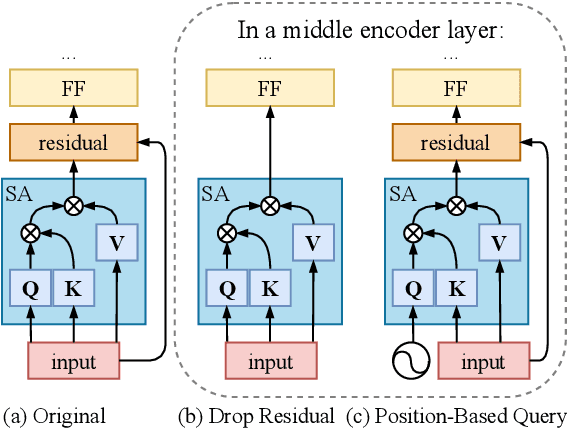

Multilingual neural machine translation has shown the capability of directly translating between language pairs unseen in training, i.e. zero-shot translation. Despite being conceptually attractive, it often suffers from low output quality. The difficulty of generalizing to new translation directions suggests the model representations are highly specific to those language pairs seen in training. We demonstrate that a main factor causing the language-specific representations is the positional correspondence to input tokens. We show that this can be easily alleviated by removing residual connections in an encoder layer. With this modification, we gain up to 18.5 BLEU points on zero-shot translation while retaining quality on supervised directions. The improvements are particularly prominent between related languages, where our proposed model outperforms pivot-based translation. Moreover, our approach allows easy integration of new languages, which substantially expands translation coverage. By thorough inspections of the hidden layer outputs, we show that our approach indeed leads to more language-independent representations.