 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Deep Neural Networks Improve Compression of Very Large Scientific Data?
Jun 12, 2026Error-bounded lossy compression is a fundamental technique for managing the rapidly growing volumes of scientific data produced by modern simulations and observational instruments. Most state-of-the-art-compressors follow a prediction-residual paradigm, where compression effectiveness depends on the quality of the predictor: more accurate predictions generate smaller residuals that are easier to compress. This observation raises a question: can modern machine learning models serve as superior predictors for scientific data compression? Answering this question directly is challenging because developing compression-specific ML predictors requires substantial resources. Instead, we leverage the climate domain where highly accurate pretrained weather forecasting foundation models already exist, making them an ideal testbed. We present a framework that integrates spatial and temporal deep learning models into a conventional error-bounded compression pipeline. The framework supports auto-regressive forecasting models and avoids error accumulation. Using ERA5 climate data as a representative large-scale scientific dataset, we evaluate three distinct ML predictors: a VAEformer-based codec (CRA5), a graph neural network forecaster (GraphCast), and a vision-transformer forecaster (Aurora), against the state-of-the-art compressor SZ3.1 under identical quantization and entropy-coding backends. Our evaluation over approximately 1.7 TB of data reveals a surprising result: although ML predictors generate more accurate predictions and can improve reconstruction quality by up to 91% while achieving up to 9.6x higher compression ratios for highly predictable variables, they do not improve overall dataset-level compression ratio. We show that prediction accuracy alone is insufficient: the spatial structure of the resulting residuals plays a decisive role in entropy coding efficiency.
GraphComp: Extreme Error-bounded Compression of Scientific Data via Temporal Graph Autoencoders
May 08, 2025



The generation of voluminous scientific data poses significant challenges for efficient storage, transfer, and analysis. Recently, error-bounded lossy compression methods emerged due to their ability to achieve high compression ratios while controlling data distortion. However, they often overlook the inherent spatial and temporal correlations within scientific data, thus missing opportunities for higher compression. In this paper we propose GRAPHCOMP, a novel graph-based method for error-bounded lossy compression of scientific data. We perform irregular segmentation of the original grid data and generate a graph representation that preserves the spatial and temporal correlations. Inspired by Graph Neural Networks (GNNs), we then propose a temporal graph autoencoder to learn latent representations that significantly reduce the size of the graph, effectively compressing the original data. Decompression reverses the process and utilizes the learnt graph model together with the latent representation to reconstruct an approximation of the original data. The decompressed data are guaranteed to satisfy a user-defined point-wise error bound. We compare our method against the state-of-the-art error-bounded lossy methods (i.e., HPEZ, SZ3.1, SPERR, and ZFP) on large-scale real and synthetic data. GRAPHCOMP consistently achieves the highest compression ratio across most datasets, outperforming the second-best method by margins ranging from 22% to 50%.
A Crawler Architecture for Harvesting the Clear, Social, and Dark Web for IoT-Related Cyber-Threat Intelligence
Sep 14, 2021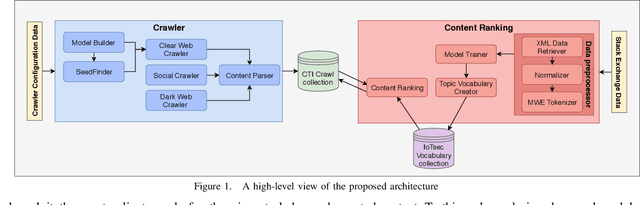

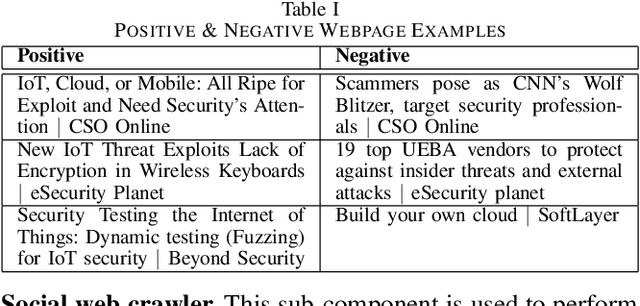

The clear, social, and dark web have lately been identified as rich sources of valuable cyber-security information that -given the appropriate tools and methods-may be identified, crawled and subsequently leveraged to actionable cyber-threat intelligence. In this work, we focus on the information gathering task, and present a novel crawling architecture for transparently harvesting data from security websites in the clear web, security forums in the social web, and hacker forums/marketplaces in the dark web. The proposed architecture adopts a two-phase approach to data harvesting. Initially a machine learning-based crawler is used to direct the harvesting towards websites of interest, while in the second phase state-of-the-art statistical language modelling techniques are used to represent the harvested information in a latent low-dimensional feature space and rank it based on its potential relevance to the task at hand. The proposed architecture is realised using exclusively open-source tools, and a preliminary evaluation with crowdsourced results demonstrates its effectiveness.
* 6 pages, 2 figures