 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning with less labels in Digital Pathology via Scribble Supervision from natural images
Jan 07, 2022
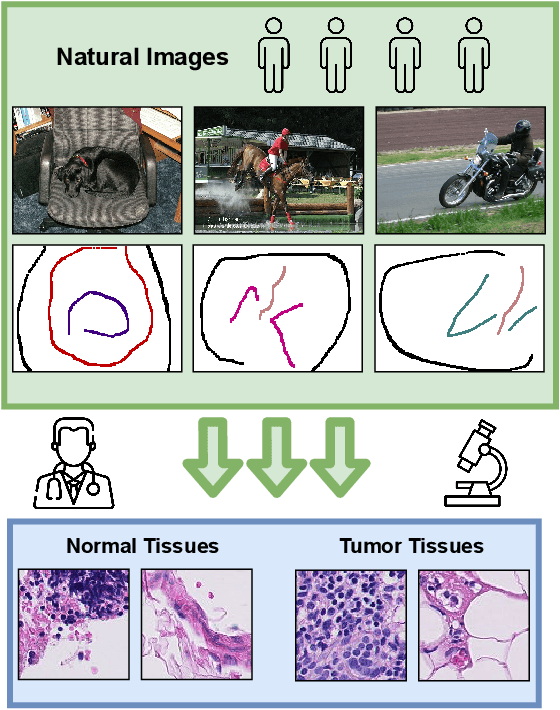
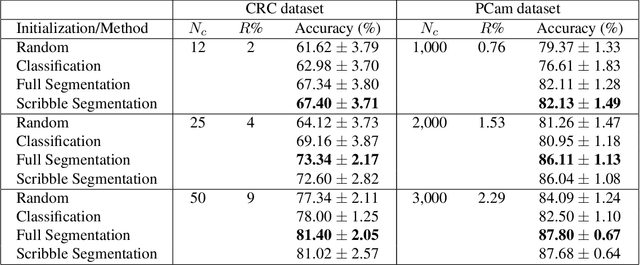
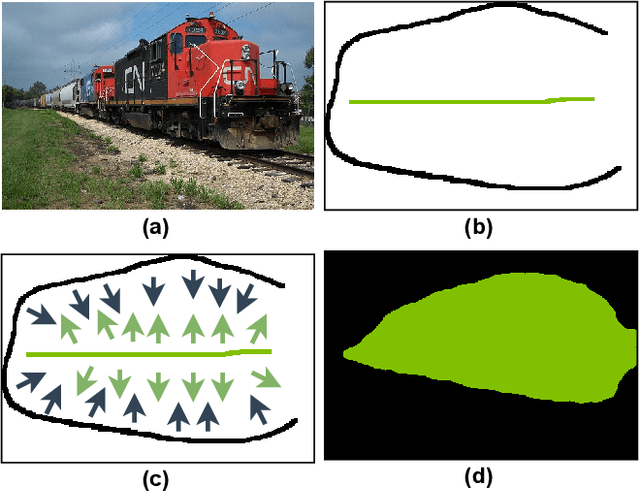

A critical challenge of training deep learning models in the Digital Pathology (DP) domain is the high annotation cost by medical experts. One way to tackle this issue is via transfer learning from the natural image domain (NI), where the annotation cost is considerably cheaper. Cross-domain transfer learning from NI to DP is shown to be successful via class labels~\cite{teh2020learning}. One potential weakness of relying on class labels is the lack of spatial information, which can be obtained from spatial labels such as full pixel-wise segmentation labels and scribble labels. We demonstrate that scribble labels from NI domain can boost the performance of DP models on two cancer classification datasets (Patch Camelyon Breast Cancer and Colorectal Cancer dataset). Furthermore, we show that models trained with scribble labels yield the same performance boost as full pixel-wise segmentation labels despite being significantly easier and faster to collect.
SIA-GCN: A Spatial Information Aware Graph Neural Network with 2D Convolutions for Hand Pose Estimation
Sep 25, 2020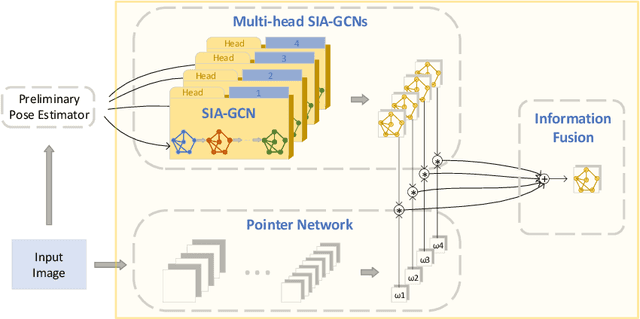
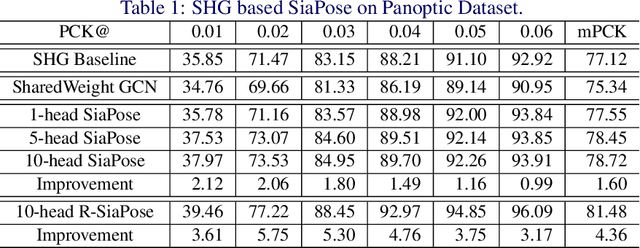
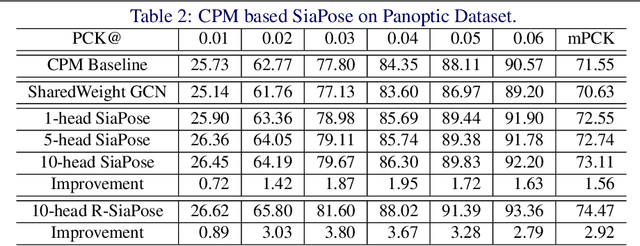
Graph Neural Networks (GNNs) generalize neural networks from applications on regular structures to applications on arbitrary graphs, and have shown success in many application domains such as computer vision, social networks and chemistry. In this paper, we extend GNNs along two directions: a) allowing features at each node to be represented by 2D spatial confidence maps instead of 1D vectors; and b) proposing an efficient operation to integrate information from neighboring nodes through 2D convolutions with different learnable kernels at each edge. The proposed SIA-GCN can efficiently extract spatial information from 2D maps at each node and propagate them through graph convolution. By associating each edge with a designated convolution kernel, the SIA-GCN could capture different spatial relationships for different pairs of neighboring nodes. We demonstrate the utility of SIA-GCN on the task of estimating hand keypoints from single-frame images, where the nodes represent the 2D coordinate heatmaps of keypoints and the edges denote the kinetic relationships between keypoints. Experiments on multiple datasets show that SIA-GCN provides a flexible and yet powerful framework to account for structural constraints between keypoints, and can achieve state-of-the-art performance on the task of hand pose estimation.
Translating Human Mobility Forecasting through Natural Language Generation
Dec 13, 2021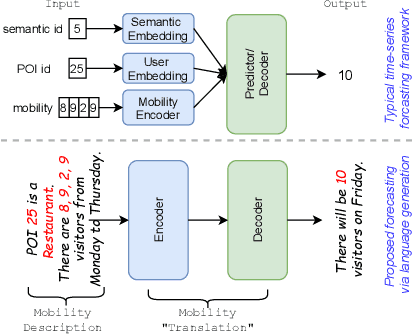

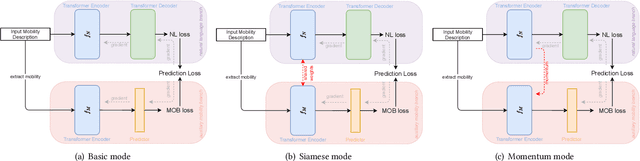
Existing human mobility forecasting models follow the standard design of the time-series prediction model which takes a series of numerical values as input to generate a numerical value as a prediction. Although treating this as a regression problem seems straightforward, incorporating various contextual information such as the semantic category information of each Place-of-Interest (POI) is a necessary step, and often the bottleneck, in designing an effective mobility prediction model. As opposed to the typical approach, we treat forecasting as a translation problem and propose a novel forecasting through a language generation pipeline. The paper aims to address the human mobility forecasting problem as a language translation task in a sequence-to-sequence manner. A mobility-to-language template is first introduced to describe the numerical mobility data as natural language sentences. The core intuition of the human mobility forecasting translation task is to convert the input mobility description sentences into a future mobility description from which the prediction target can be obtained. Under this pipeline, a two-branch network, SHIFT (Translating Human Mobility Forecasting), is designed. Specifically, it consists of one main branch for language generation and one auxiliary branch to directly learn mobility patterns. During the training, we develop a momentum mode for better connecting and training the two branches. Extensive experiments on three real-world datasets demonstrate that the proposed SHIFT is effective and presents a new revolutionary approach to forecasting human mobility.
MI^2GAN: Generative Adversarial Network for Medical Image Domain Adaptation using Mutual Information Constraint
Jul 22, 2020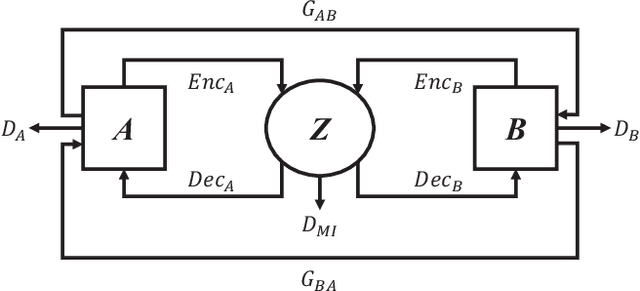
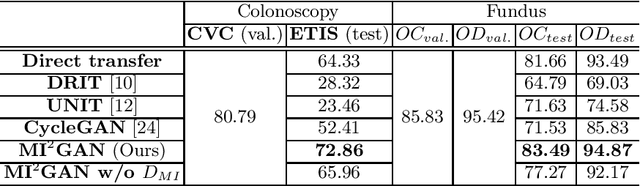
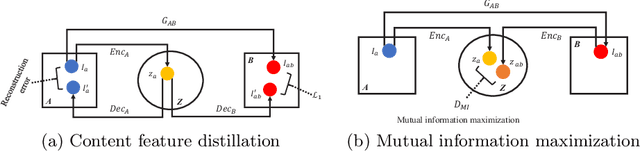
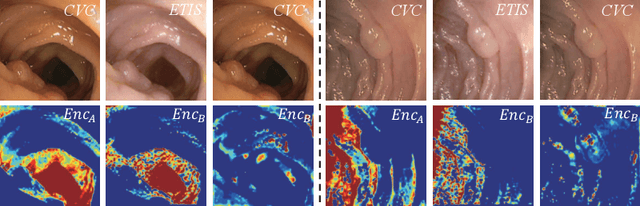
Domain shift between medical images from multicentres is still an open question for the community, which degrades the generalization performance of deep learning models. Generative adversarial network (GAN), which synthesize plausible images, is one of the potential solutions to address the problem. However, the existing GAN-based approaches are prone to fail at preserving image-objects in image-to-image (I2I) translation, which reduces their practicality on domain adaptation tasks. In this paper, we propose a novel GAN (namely MI$^2$GAN) to maintain image-contents during cross-domain I2I translation. Particularly, we disentangle the content features from domain information for both the source and translated images, and then maximize the mutual information between the disentangled content features to preserve the image-objects. The proposed MI$^2$GAN is evaluated on two tasks---polyp segmentation using colonoscopic images and the segmentation of optic disc and cup in fundus images. The experimental results demonstrate that the proposed MI$^2$GAN can not only generate elegant translated images, but also significantly improve the generalization performance of widely used deep learning networks (e.g., U-Net).
Using Spatio-temporal Deep Learning for Forecasting Demand and Supply-demand Gap in Ride-hailing System with Anonymized Spatial Adjacency Information
Dec 16, 2020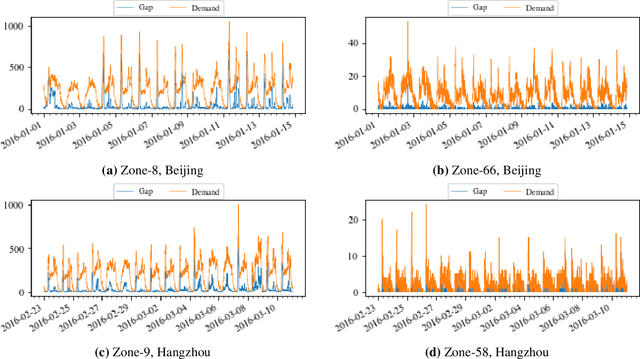

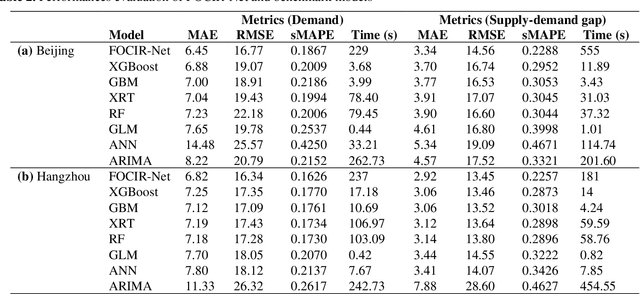
To reduce passenger waiting time and driver search friction, ride-hailing companies need to accurately forecast spatio-temporal demand and supply-demand gap. However, due to spatio-temporal dependencies pertaining to demand and supply-demand gap in a ride-hailing system, making accurate forecasts for both demand and supply-demand gap is a difficult task. Furthermore, due to confidentiality and privacy issues, ride-hailing data are sometimes released to the researchers by removing spatial adjacency information of the zones, which hinders the detection of spatio-temporal dependencies. To that end, a novel spatio-temporal deep learning architecture is proposed in this paper for forecasting demand and supply-demand gap in a ride-hailing system with anonymized spatial adjacency information, which integrates feature importance layer with a spatio-temporal deep learning architecture containing one-dimensional convolutional neural network (CNN) and zone-distributed independently recurrent neural network (IndRNN). The developed architecture is tested with real-world datasets of Didi Chuxing, which shows that our models based on the proposed architecture can outperform conventional time-series models (e.g., ARIMA) and machine learning models (e.g., gradient boosting machine, distributed random forest, generalized linear model, artificial neural network). Additionally, the feature importance layer provides an interpretation of the model by revealing the contribution of the input features utilized in prediction.
S2MS: Self-Supervised Learning Driven Multi-Spectral CT Image Enhancement
Jan 25, 2022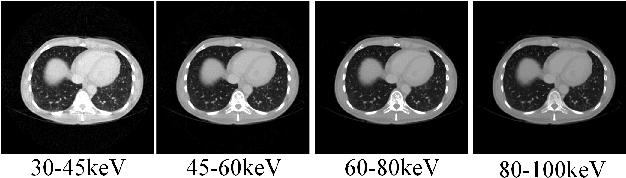
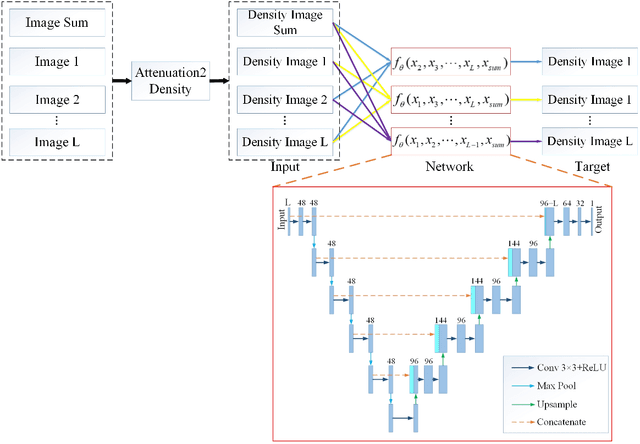
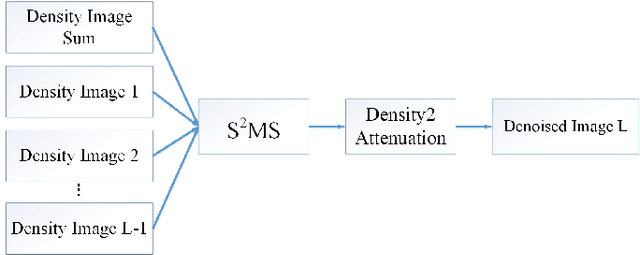
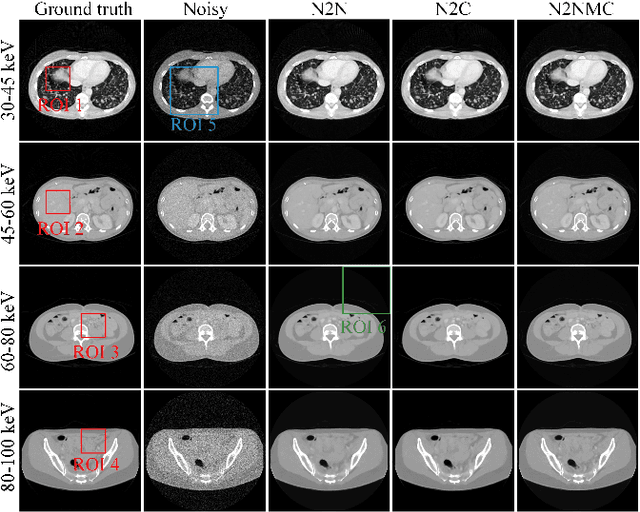
Photon counting spectral CT (PCCT) can produce reconstructed attenuation maps in different energy channels, reflecting energy properties of the scanned object. Due to the limited photon numbers and the non-ideal detector response of each energy channel, the reconstructed images usually contain much noise. With the development of Deep Learning (DL) technique, different kinds of DL-based models have been proposed for noise reduction. However, most of the models require clean data set as the training labels, which are not always available in medical imaging field. Inspiring by the similarities of each channel's reconstructed image, we proposed a self-supervised learning based PCCT image enhancement framework via multi-spectral channels (S2MS). In S2MS framework, both the input and output labels are noisy images. Specifically, one single channel image was used as output while images of other single channels and channel-sum image were used as input to train the network, which can fully use the spectral data information without extra cost. The simulation results based on the AAPM Low-dose CT Challenge database showed that the proposed S2MS model can suppress the noise and preserve details more effectively in comparison with the traditional DL models, which has potential to improve the image quality of PCCT in clinical applications.
Instance-Conditional Knowledge Distillation for Object Detection
Oct 25, 2021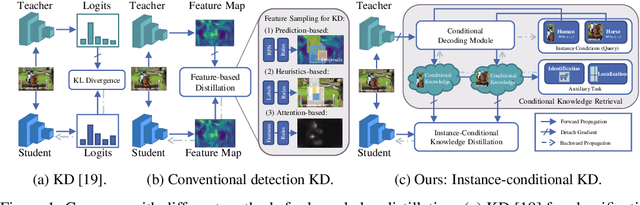
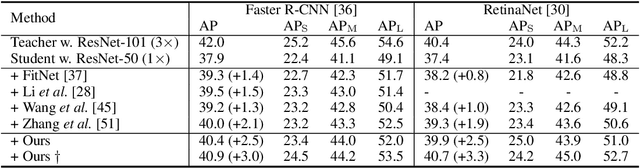
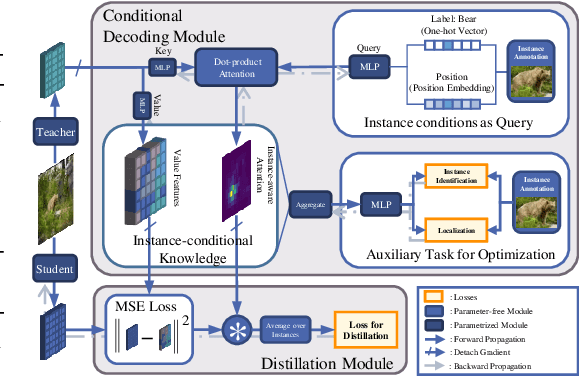
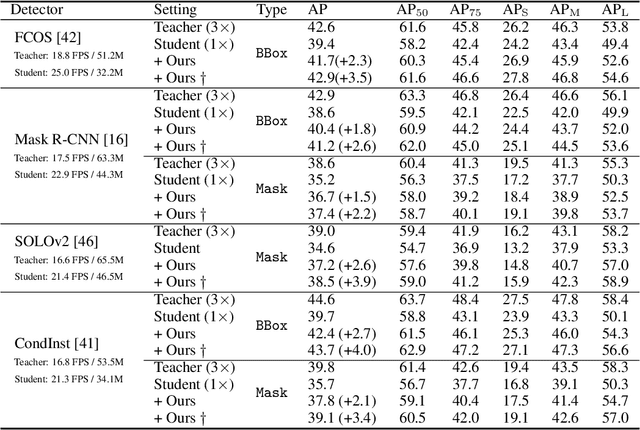
Despite the success of Knowledge Distillation (KD) on image classification, it is still challenging to apply KD on object detection due to the difficulty in locating knowledge. In this paper, we propose an instance-conditional distillation framework to find desired knowledge. To locate knowledge of each instance, we use observed instances as condition information and formulate the retrieval process as an instance-conditional decoding process. Specifically, information of each instance that specifies a condition is encoded as query, and teacher's information is presented as key, we use the attention between query and key to measure the correlation, formulated by the transformer decoder. To guide this module, we further introduce an auxiliary task that directs to instance localization and identification, which are fundamental for detection. Extensive experiments demonstrate the efficacy of our method: we observe impressive improvements under various settings. Notably, we boost RetinaNet with ResNet-50 backbone from 37.4 to 40.7 mAP (+3.3) under 1x schedule, that even surpasses the teacher (40.4 mAP) with ResNet-101 backbone under 3x schedule. Code will be released soon.
Microdosing: Knowledge Distillation for GAN based Compression
Jan 07, 2022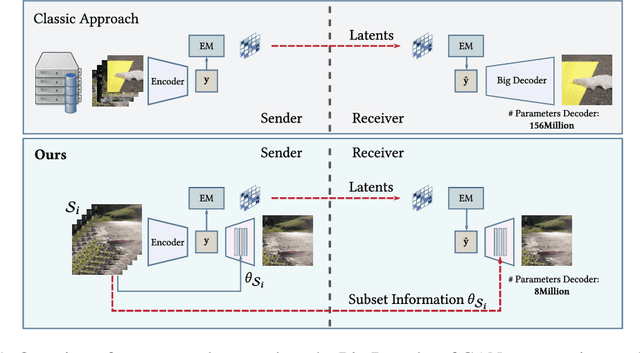
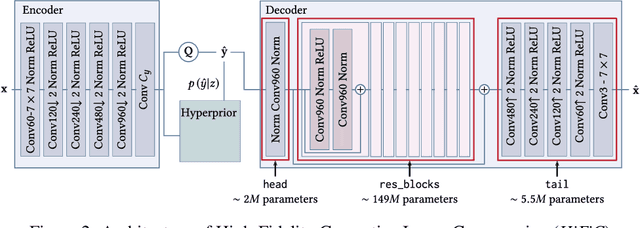
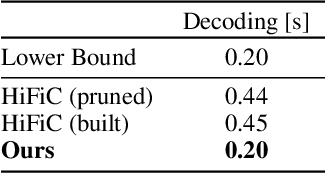

Recently, significant progress has been made in learned image and video compression. In particular the usage of Generative Adversarial Networks has lead to impressive results in the low bit rate regime. However, the model size remains an important issue in current state-of-the-art proposals and existing solutions require significant computation effort on the decoding side. This limits their usage in realistic scenarios and the extension to video compression. In this paper, we demonstrate how to leverage knowledge distillation to obtain equally capable image decoders at a fraction of the original number of parameters. We investigate several aspects of our solution including sequence specialization with side information for image coding. Finally, we also show how to transfer the obtained benefits into the setting of video compression. Overall, this allows us to reduce the model size by a factor of 20 and to achieve 50% reduction in decoding time.
Using Ballistocardiography for Sleep Stage Classification
Feb 02, 2022A practical way of detecting sleep stages has become more necessary as we begin to learn about the vast effects that sleep has on people's lives. The current methods of sleep stage detection are expensive, invasive to a person's sleep, and not practical in a modern home setting. While the method of detecting sleep stages via the monitoring of brain activity, muscle activity, and eye movement, through electroencephalogram in a lab setting, provide the gold standard for detection, this paper aims to investigate a new method that will allow a person to gain similar insight and results with no obtrusion to their normal sleeping habits. Ballistocardiography (BCG) is a non-invasive sensing technology that collects information by measuring the ballistic forces generated by the heart. Using features extracted from BCG such as time of usage, heart rate, respiration rate, relative stroke volume, and heart rate variability, we propose to implement a sleep stage detection algorithm and compare it against sleep stages extracted from a Fitbit Sense Smart Watch. The accessibility, ease of use, and relatively-low cost of the BCG offers many applications and advantages for using this device. By standardizing this device, people will be able to benefit from the BCG in analyzing their own sleep patterns and draw conclusions on their sleep efficiency. This work demonstrates the feasibility of using BCG for an accurate and non-invasive sleep monitoring method that can be set up in the comfort of a one's personal sleep environment.
Developing Smart Web-Search Using RegEx
Oct 10, 2021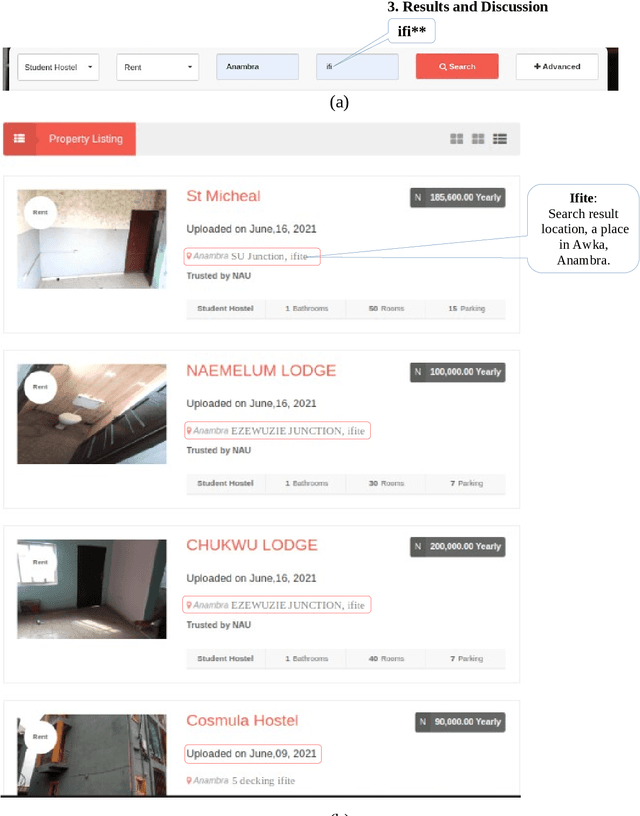
Due to the increasing storage data on Web Applications, it becomes very difficult to use only keyword-based searches to provide comprehensive search results, thus increasing the difficulty for web users to search information on the web. In this paper, we proposed using a combined method of keyword-based and Regular expressions (regEx) searches to perform a search using strings of targeted items for optimal results even as the volume of data around the world on the Internet continues to explode. The idea is to embed regEx patterns as part of the search engine's algorithm in a web application project to provide strings related to the targeted items for more comprehensive coverage of search results. The user's search query is a string of characters guided by search boundaries selected from the entry point. The results returned from the search operation are different results within a category determined by the search boundaries. This is designed to be beneficial to a user who has an obscure idea about the information he/she wanted to search but knows the boundaries within which to get the information. This technique can be applied to data processing tasks such as information extraction and search refinement.