 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Deep Graph Learning for Spatially-Varying Indoor Lighting Prediction
Feb 13, 2022

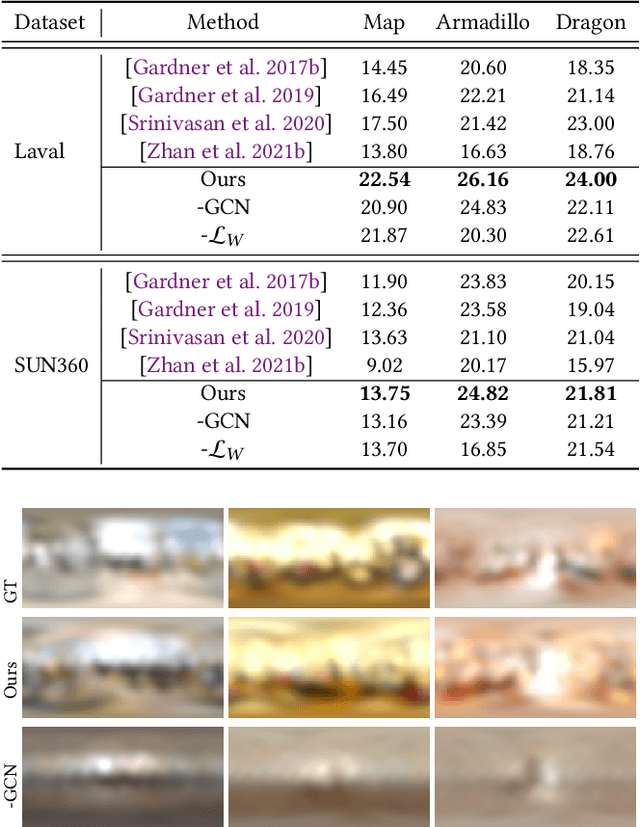


Lighting prediction from a single image is becoming increasingly important in many vision and augmented reality (AR) applications in which shading and shadow consistency between virtual and real objects should be guaranteed. However, this is a notoriously ill-posed problem, especially for indoor scenarios, because of the complexity of indoor luminaires and the limited information involved in 2D images. In this paper, we propose a graph learning-based framework for indoor lighting estimation. At its core is a new lighting model (dubbed DSGLight) based on depth-augmented Spherical Gaussians (SG) and a Graph Convolutional Network (GCN) that infers the new lighting representation from a single LDR image of limited field-of-view. Our lighting model builds 128 evenly distributed SGs over the indoor panorama, where each SG encoding the lighting and the depth around that node. The proposed GCN then learns the mapping from the input image to DSGLight. Compared with existing lighting models, our DSGLight encodes both direct lighting and indirect environmental lighting more faithfully and compactly. It also makes network training and inference more stable. The estimated depth distribution enables temporally stable shading and shadows under spatially-varying lighting. Through thorough experiments, we show that our method obviously outperforms existing methods both qualitatively and quantitatively.
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022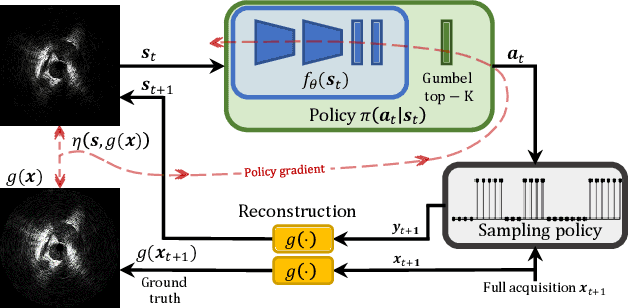
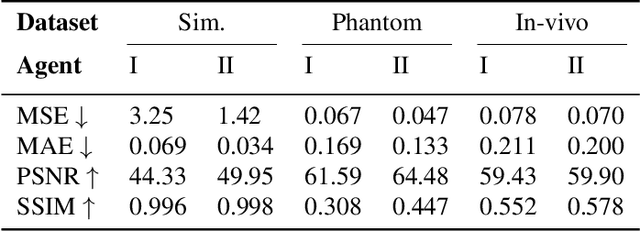

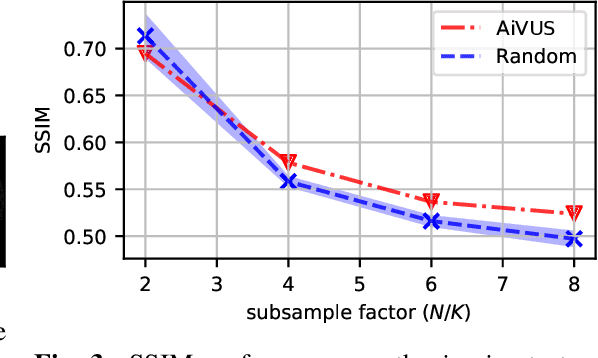
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference
Estimating Information-Theoretic Quantities with Random Forests
Jul 03, 2019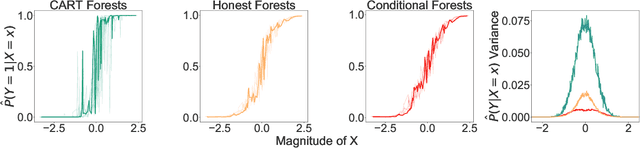
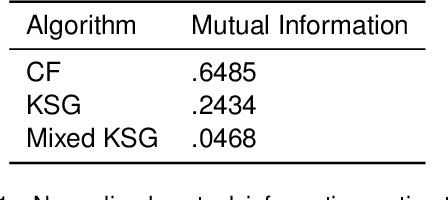
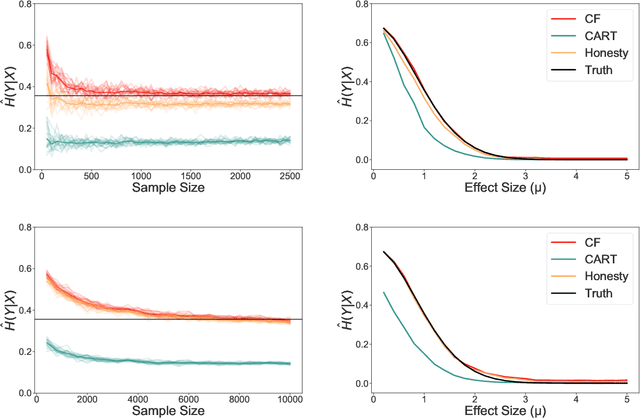

Information-theoretic quantities, such as mutual information and conditional entropy, are useful statistics for measuring the dependence between two random variables. However, estimating these quantities in a non-parametric fashion is difficult, especially when the variables are high-dimensional, a mixture of continuous and discrete values, or both. In this paper, we propose a decision forest method, Conditional Forests (CF), to estimate these quantities. By combining quantile regression forests with honest sampling, and introducing a finite sample correction, CF improves finite sample bias in a range of settings. We demonstrate through simulations that CF achieves smaller bias and variance in both low- and high-dimensional settings for estimating posteriors, conditional entropy, and mutual information. We then use CF to estimate the amount of information between neuron class and other ceulluar feautres.
Learning to acquire novel cognitive tasks with evolution, plasticity and meta-meta-learning
Jan 17, 2022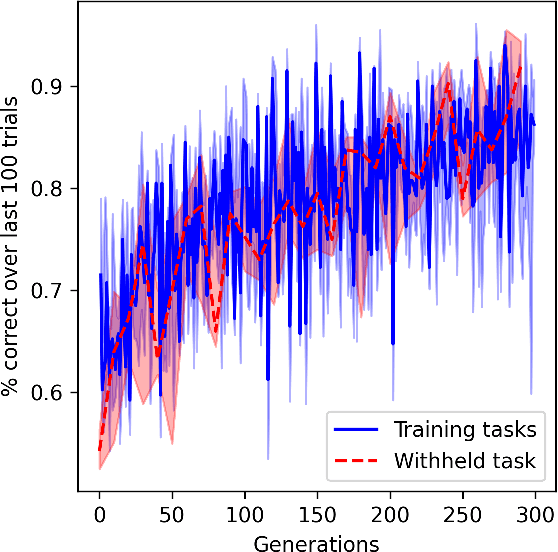
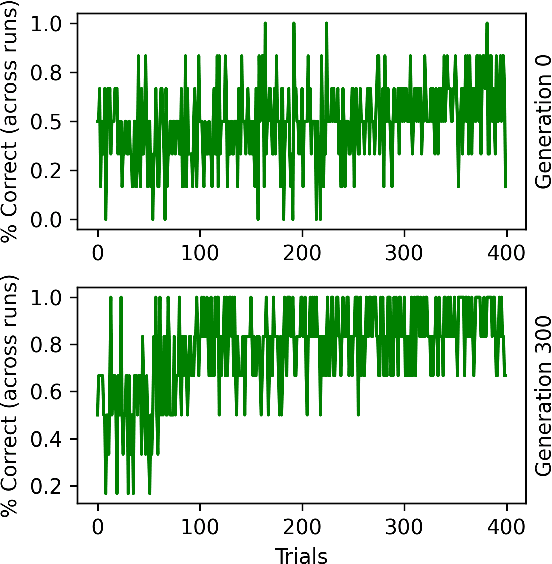
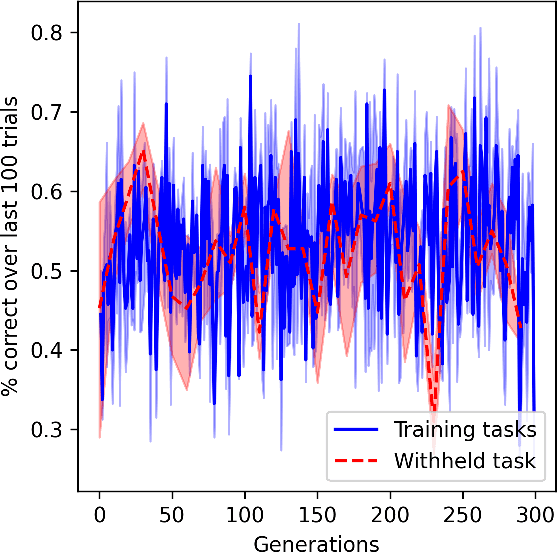
In meta-learning, networks are trained with external algorithms to learn tasks that require acquiring, storing and exploiting unpredictable information for each new instance of the task. However, animals are able to pick up such cognitive tasks automatically, as a result of their evolved neural architecture and synaptic plasticity mechanisms. Here we evolve neural networks, endowed with plastic connections, over a sizeable set of simple meta-learning tasks based on a framework from computational neuroscience. The resulting evolved network can automatically acquire a novel simple cognitive task, never seen during training, through the spontaneous operation of its evolved neural organization and plasticity structure. We suggest that attending to the multiplicity of loops involved in natural learning may provide useful insight into the emergence of intelligent behavior
Combining Improvements for Exploiting Dependency Trees in Neural Semantic Parsing
Dec 25, 2021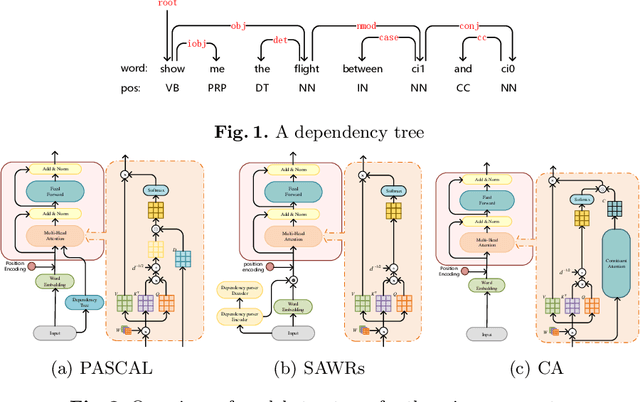
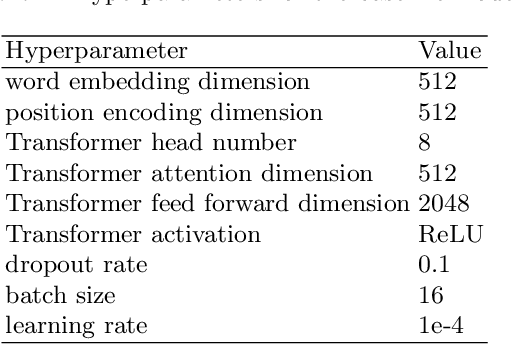
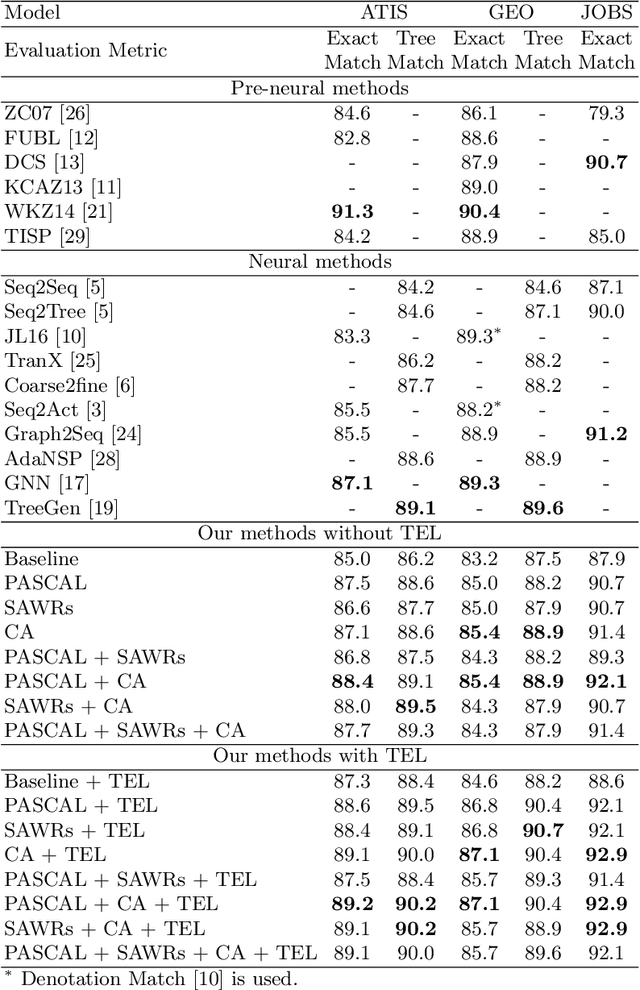
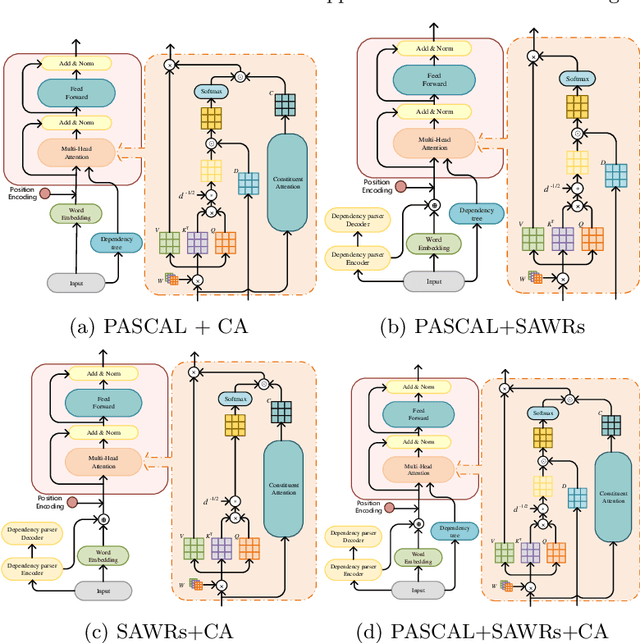
The dependency tree of a natural language sentence can capture the interactions between semantics and words. However, it is unclear whether those methods which exploit such dependency information for semantic parsing can be combined to achieve further improvement and the relationship of those methods when they combine. In this paper, we examine three methods to incorporate such dependency information in a Transformer based semantic parser and empirically study their combinations. We first replace standard self-attention heads in the encoder with parent-scaled self-attention (PASCAL) heads, i.e., the ones that can attend to the dependency parent of each token. Then we concatenate syntax-aware word representations (SAWRs), i.e., the intermediate hidden representations of a neural dependency parser, with ordinary word embedding to enhance the encoder. Later, we insert the constituent attention (CA) module to the encoder, which adds an extra constraint to attention heads that can better capture the inherent dependency structure of input sentences. Transductive ensemble learning (TEL) is used for model aggregation, and an ablation study is conducted to show the contribution of each method. Our experiments show that CA is complementary to PASCAL or SAWRs, and PASCAL + CA provides state-of-the-art performance among neural approaches on ATIS, GEO, and JOBS.
LRSVRG-IMC: An SVRG-Based Algorithm for LowRank Inductive Matrix Completion
Jan 21, 2022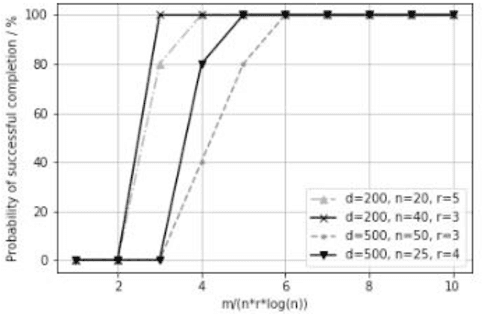
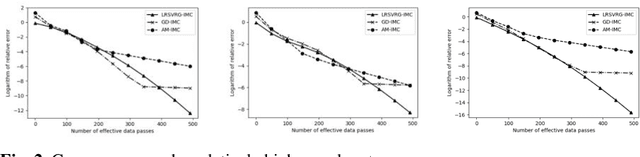
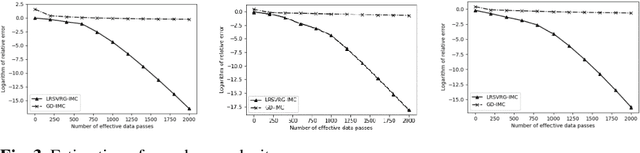
Low-rank inductive matrix completion (IMC) is currently widely used in IoT data completion, recommendation systems, and so on, as the side information in IMC has demonstrated great potential in reducing sample point remains a major obstacle for the convergence of the nonconvex solutions to IMC. What's more, carefully choosing the initial solution alone does not usually help remove the saddle points. To address this problem, we propose a stocastic variance reduction gradient-based algorithm called LRSVRG-IMC. LRSVRG-IMC can escape from the saddle points under various low-rank and sparse conditions with a properly chosen initial input. We also prove that LRSVVRG-IMC achieves both a linear convergence rate and a near-optimal sample complexity. The superiority and applicability of LRSVRG-IMC are verified via experiments on synthetic datasets.
Ordinal Causal Discovery
Jan 24, 2022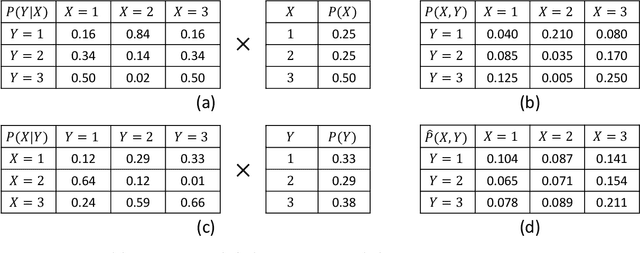
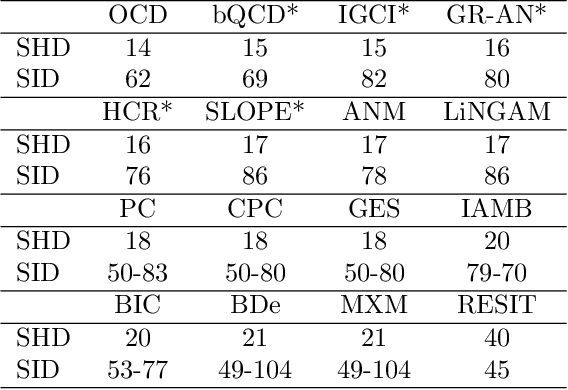
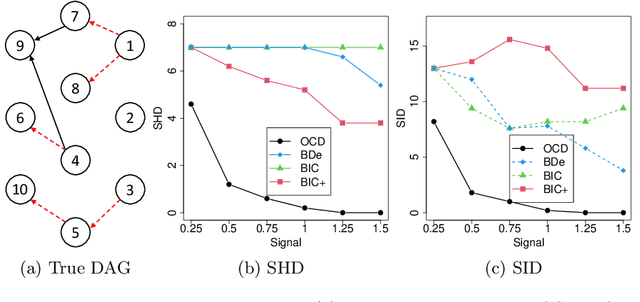
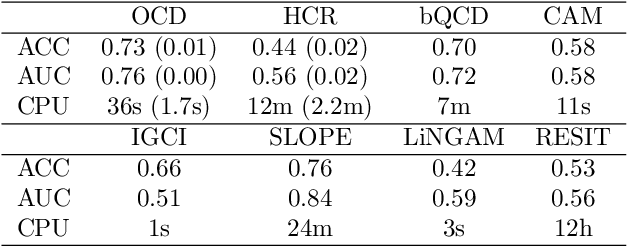
Causal discovery for purely observational, categorical data is a long-standing challenging problem. Unlike continuous data, the vast majority of existing methods for categorical data focus on inferring the Markov equivalence class only, which leaves the direction of some causal relationships undetermined. This paper proposes an identifiable ordinal causal discovery method that exploits the ordinal information contained in many real-world applications to uniquely identify the causal structure. The proposed method is applicable beyond ordinal data via data discretization. Through real-world and synthetic experiments, we demonstrate that the proposed ordinal causal discovery method combined with simple score-and-search algorithms has favorable and robust performance compared to state-of-the-art alternative methods in both ordinal categorical and non-categorical data. An accompanied R package OCD is freely available at https://web.stat.tamu.edu/~yni/files/OCD_0.1.0.tar.gz.
LiDAR-guided Stereo Matching with a Spatial Consistency Constraint
Feb 21, 2022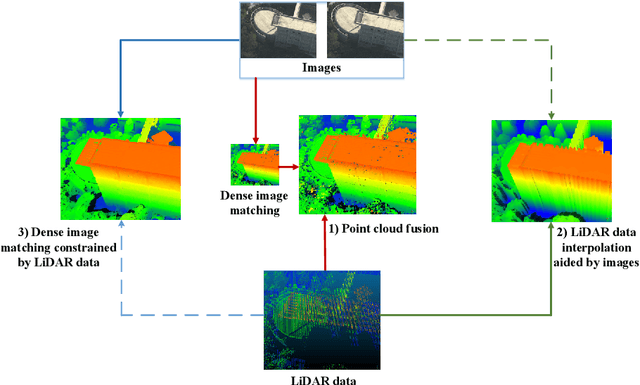
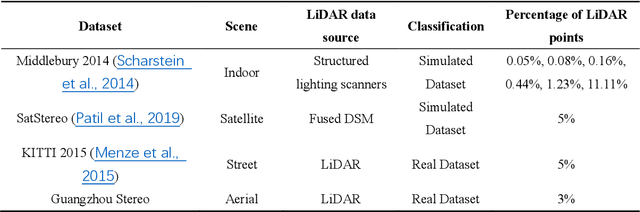
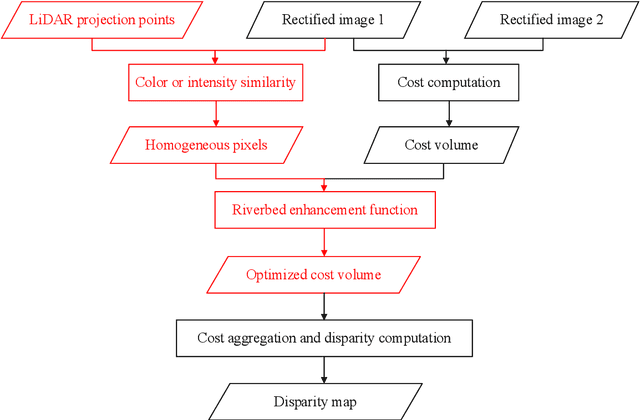
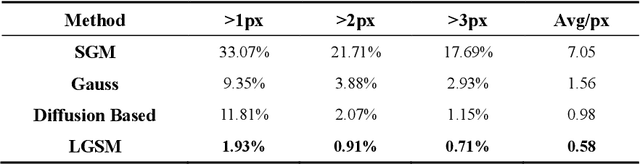
The complementary fusion of light detection and ranging (LiDAR) data and image data is a promising but challenging task for generating high-precision and high-density point clouds. This study proposes an innovative LiDAR-guided stereo matching approach called LiDAR-guided stereo matching (LGSM), which considers the spatial consistency represented by continuous disparity or depth changes in the homogeneous region of an image. The LGSM first detects the homogeneous pixels of each LiDAR projection point based on their color or intensity similarity. Next, we propose a riverbed enhancement function to optimize the cost volume of the LiDAR projection points and their homogeneous pixels to improve the matching robustness. Our formulation expands the constraint scopes of sparse LiDAR projection points with the guidance of image information to optimize the cost volume of pixels as much as possible. We applied LGSM to semi-global matching and AD-Census on both simulated and real datasets. When the percentage of LiDAR points in the simulated datasets was 0.16%, the matching accuracy of our method achieved a subpixel level, while that of the original stereo matching algorithm was 3.4 pixels. The experimental results show that LGSM is suitable for indoor, street, aerial, and satellite image datasets and provides good transferability across semi-global matching and AD-Census. Furthermore, the qualitative and quantitative evaluations demonstrate that LGSM is superior to two state-of-the-art optimizing cost volume methods, especially in reducing mismatches in difficult matching areas and refining the boundaries of objects.
Feels Bad Man: Dissecting Automated Hateful Meme Detection Through the Lens of Facebook's Challenge
Feb 17, 2022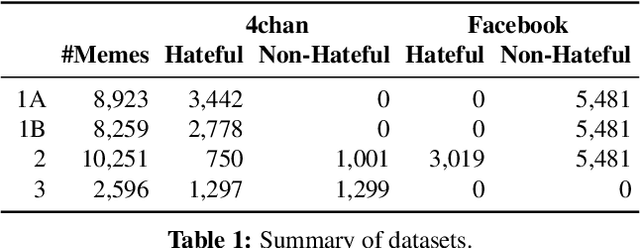
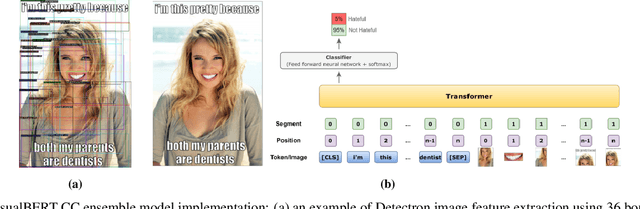

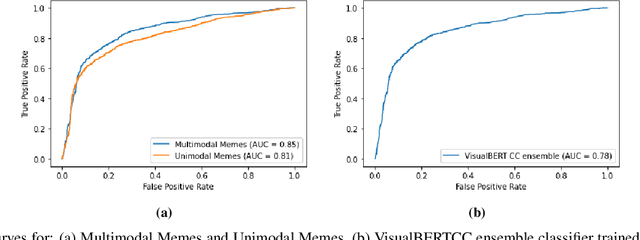
Internet memes have become a dominant method of communication; at the same time, however, they are also increasingly being used to advocate extremism and foster derogatory beliefs. Nonetheless, we do not have a firm understanding as to which perceptual aspects of memes cause this phenomenon. In this work, we assess the efficacy of current state-of-the-art multimodal machine learning models toward hateful meme detection, and in particular with respect to their generalizability across platforms. We use two benchmark datasets comprising 12,140 and 10,567 images from 4chan's "Politically Incorrect" board (/pol/) and Facebook's Hateful Memes Challenge dataset to train the competition's top-ranking machine learning models for the discovery of the most prominent features that distinguish viral hateful memes from benign ones. We conduct three experiments to determine the importance of multimodality on classification performance, the influential capacity of fringe Web communities on mainstream social platforms and vice versa, and the models' learning transferability on 4chan memes. Our experiments show that memes' image characteristics provide a greater wealth of information than its textual content. We also find that current systems developed for online detection of hate speech in memes necessitate further concentration on its visual elements to improve their interpretation of underlying cultural connotations, implying that multimodal models fail to adequately grasp the intricacies of hate speech in memes and generalize across social media platforms.
SciBERTSUM: Extractive Summarization for Scientific Documents
Jan 21, 2022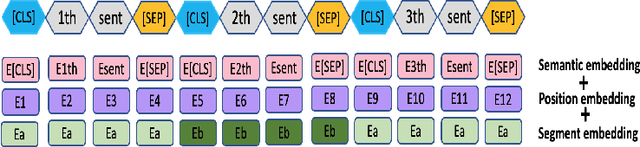
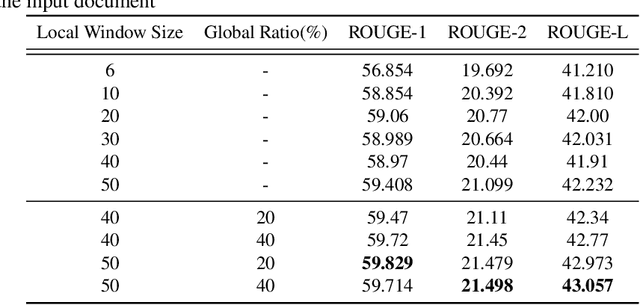
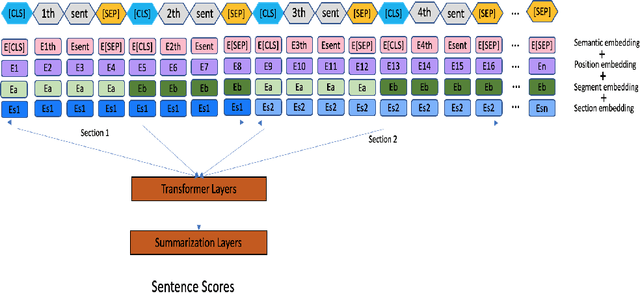

The summarization literature focuses on the summarization of news articles. The news articles in the CNN-DailyMail are relatively short documents with about 30 sentences per document on average. We introduce SciBERTSUM, our summarization framework designed for the summarization of long documents like scientific papers with more than 500 sentences. SciBERTSUM extends BERTSUM to long documents by 1) adding a section embedding layer to include section information in the sentence vector and 2) applying a sparse attention mechanism where each sentences will attend locally to nearby sentences and only a small number of sentences attend globally to all other sentences. We used slides generated by the authors of scientific papers as reference summaries since they contain the technical details from the paper. The results show the superiority of our model in terms of ROUGE scores.