 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Step Is Enough: Dispersive MeanFlow Policy Optimization
Jan 28, 2026Real-time robotic control demands fast action generation. However, existing generative policies based on diffusion and flow matching require multi-step sampling, fundamentally limiting deployment in time-critical scenarios. We propose Dispersive MeanFlow Policy Optimization (DMPO), a unified framework that enables true one-step generation through three key components: MeanFlow for mathematically-derived single-step inference without knowledge distillation, dispersive regularization to prevent representation collapse, and reinforcement learning (RL) fine-tuning to surpass expert demonstrations. Experiments across RoboMimic manipulation and OpenAI Gym locomotion benchmarks demonstrate competitive or superior performance compared to multi-step baselines. With our lightweight model architecture and the three key algorithmic components working in synergy, DMPO exceeds real-time control requirements (>120Hz) with 5-20x inference speedup, reaching hundreds of Hertz on high-performance GPUs. Physical deployment on a Franka-Emika-Panda robot validates real-world applicability.
DM1: MeanFlow with Dispersive Regularization for 1-Step Robotic Manipulation
Oct 09, 2025The ability to learn multi-modal action distributions is indispensable for robotic manipulation policies to perform precise and robust control. Flow-based generative models have recently emerged as a promising solution to learning distributions of actions, offering one-step action generation and thus achieving much higher sampling efficiency compared to diffusion-based methods. However, existing flow-based policies suffer from representation collapse, the inability to distinguish similar visual representations, leading to failures in precise manipulation tasks. We propose DM1 (MeanFlow with Dispersive Regularization for One-Step Robotic Manipulation), a novel flow matching framework that integrates dispersive regularization into MeanFlow to prevent collapse while maintaining one-step efficiency. DM1 employs multiple dispersive regularization variants across different intermediate embedding layers, encouraging diverse representations across training batches without introducing additional network modules or specialized training procedures. Experiments on RoboMimic benchmarks show that DM1 achieves 20-40 times faster inference (0.07s vs. 2-3.5s) and improves success rates by 10-20 percentage points, with the Lift task reaching 99% success over 85% of the baseline. Real-robot deployment on a Franka Panda further validates that DM1 transfers effectively from simulation to the physical world. To the best of our knowledge, this is the first work to leverage representation regularization to enable flow-based policies to achieve strong performance in robotic manipulation, establishing a simple yet powerful approach for efficient and robust manipulation.
Thinking Before You Speak: A Proactive Test-time Scaling Approach
Aug 27, 2025



Large Language Models (LLMs) often exhibit deficiencies with complex reasoning tasks, such as maths, which we attribute to the discrepancy between human reasoning patterns and those presented in the LLMs' training data. When dealing with complex problems, humans tend to think carefully before expressing solutions. However, they often do not articulate their inner thoughts, including their intentions and chosen methodologies. Consequently, critical insights essential for bridging reasoning steps may be absent in training data collected from human sources. To bridge this gap, we proposes inserting \emph{insight}s between consecutive reasoning steps, which review the status and initiate the next reasoning steps. Unlike prior prompting strategies that rely on a single or a workflow of static prompts to facilitate reasoning, \emph{insight}s are \emph{proactively} generated to guide reasoning processes. We implement our idea as a reasoning framework, named \emph{Thinking Before You Speak} (TBYS), and design a pipeline for automatically collecting and filtering in-context examples for the generation of \emph{insight}s, which alleviates human labeling efforts and fine-tuning overheads. Experiments on challenging mathematical datasets verify the effectiveness of TBYS. Project website: https://gitee.com/jswrt/TBYS
VisRec: A Semi-Supervised Approach to Radio Interferometric Data Reconstruction
Mar 01, 2024



Radio telescopes produce visibility data about celestial objects, but these data are sparse and noisy. As a result, images created on raw visibility data are of low quality. Recent studies have used deep learning models to reconstruct visibility data to get cleaner images. However, these methods rely on a substantial amount of labeled training data, which requires significant labeling effort from radio astronomers. Addressing this challenge, we propose VisRec, a model-agnostic semi-supervised learning approach to the reconstruction of visibility data. Specifically, VisRec consists of both a supervised learning module and an unsupervised learning module. In the supervised learning module, we introduce a set of data augmentation functions to produce diverse training examples. In comparison, the unsupervised learning module in VisRec augments unlabeled data and uses reconstructions from non-augmented visibility data as pseudo-labels for training. This hybrid approach allows VisRec to effectively leverage both labeled and unlabeled data. This way, VisRec performs well even when labeled data is scarce. Our evaluation results show that VisRec outperforms all baseline methods in reconstruction quality, robustness against common observation perturbation, and generalizability to different telescope configurations.
LRSVRG-IMC: An SVRG-Based Algorithm for LowRank Inductive Matrix Completion
Jan 21, 2022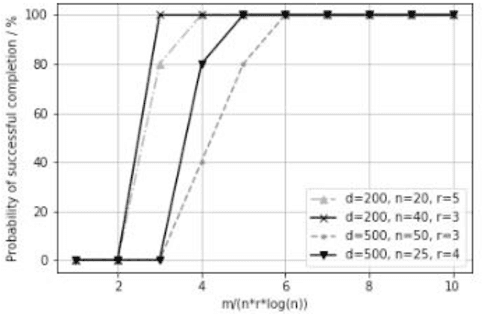
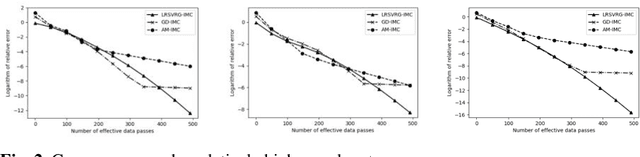
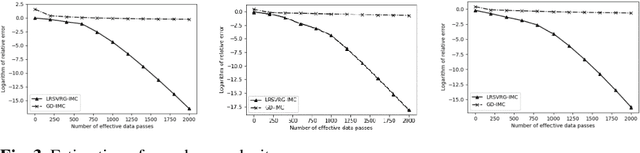
Low-rank inductive matrix completion (IMC) is currently widely used in IoT data completion, recommendation systems, and so on, as the side information in IMC has demonstrated great potential in reducing sample point remains a major obstacle for the convergence of the nonconvex solutions to IMC. What's more, carefully choosing the initial solution alone does not usually help remove the saddle points. To address this problem, we propose a stocastic variance reduction gradient-based algorithm called LRSVRG-IMC. LRSVRG-IMC can escape from the saddle points under various low-rank and sparse conditions with a properly chosen initial input. We also prove that LRSVVRG-IMC achieves both a linear convergence rate and a near-optimal sample complexity. The superiority and applicability of LRSVRG-IMC are verified via experiments on synthetic datasets.
AMMASurv: Asymmetrical Multi-Modal Attention for Accurate Survival Analysis with Whole Slide Images and Gene Expression Data
Aug 28, 2021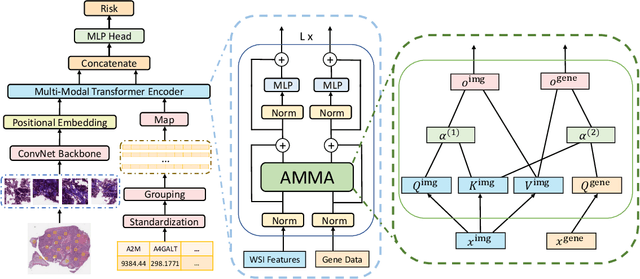
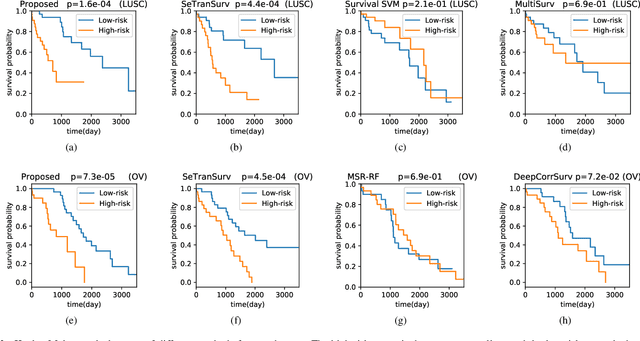
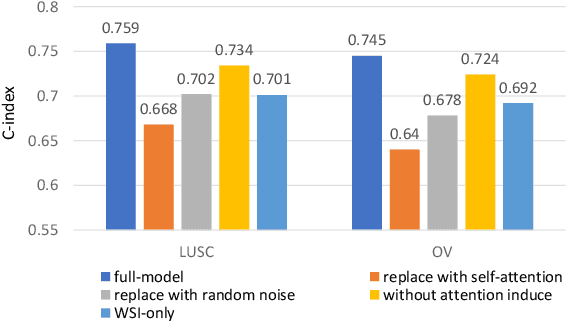
The use of multi-modal data such as the combination of whole slide images (WSIs) and gene expression data for survival analysis can lead to more accurate survival predictions. Previous multi-modal survival models are not able to efficiently excavate the intrinsic information within each modality. Moreover, despite experimental results show that WSIs provide more effective information than gene expression data, previous methods regard the information from different modalities as similarly important so they cannot flexibly utilize the potential connection between the modalities. To address the above problems, we propose a new asymmetrical multi-modal method, termed as AMMASurv. Specifically, we design an asymmetrical multi-modal attention mechanism (AMMA) in Transformer encoder for multi-modal data to enable a more flexible multi-modal information fusion for survival prediction. Different from previous works, AMMASurv can effectively utilize the intrinsic information within every modality and flexibly adapts to the modalities of different importance. Extensive experiments are conducted to validate the effectiveness of the proposed model. Encouraging results demonstrate the superiority of our method over other state-of-the-art methods.
Cross-Modal Attentional Context Learning for RGB-D Object Detection
Oct 30, 2018
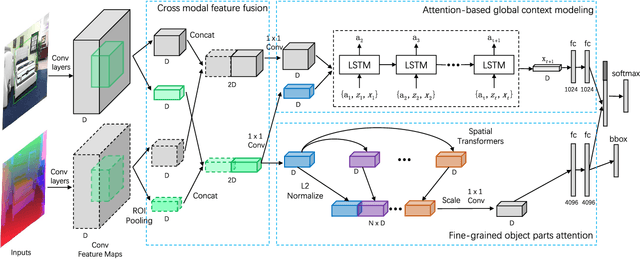
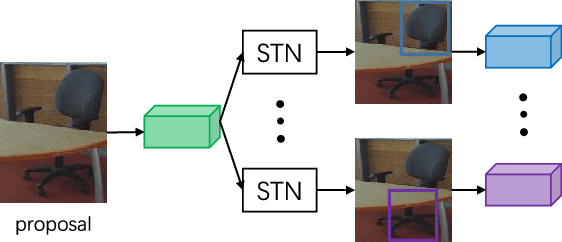
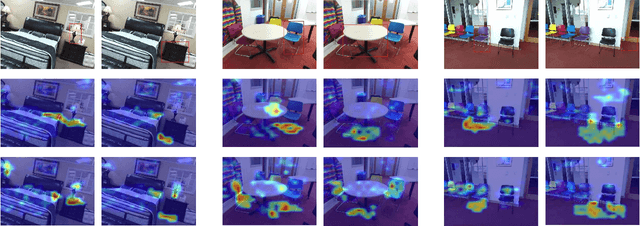
Recognizing objects from simultaneously sensed photometric (RGB) and depth channels is a fundamental yet practical problem in many machine vision applications such as robot grasping and autonomous driving. In this paper, we address this problem by developing a Cross-Modal Attentional Context (CMAC) learning framework, which enables the full exploitation of the context information from both RGB and depth data. Compared to existing RGB-D object detection frameworks, our approach has several appealing properties. First, it consists of an attention-based global context model for exploiting adaptive contextual information and incorporating this information into a region-based CNN (e.g., Fast RCNN) framework to achieve improved object detection performance. Second, our CMAC framework further contains a fine-grained object part attention module to harness multiple discriminative object parts inside each possible object region for superior local feature representation. While greatly improving the accuracy of RGB-D object detection, the effective cross-modal information fusion as well as attentional context modeling in our proposed model provide an interpretable visualization scheme. Experimental results demonstrate that the proposed method significantly improves upon the state of the art on all public benchmarks.