 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Based Adaptive Transmit Beamforming for Efficient Ultrasound Quantification
Jan 28, 2026Wireless and wearable ultrasound devices promise to enable continuous ultrasound monitoring, but power consumption and data throughput remain critical challenges. Reducing the number of transmit events per second directly impacts both. We propose a task-based adaptive transmit beamforming method, formulated as a Bayesian active perception problem, that adaptively chooses where to scan in order to gain information about downstream quantitative measurements, avoiding redundant transmit events. Our proposed Task-Based Information Gain (TBIG) strategy applies to any differentiable downstream task function. When applied to recovering ventricular dimensions from echocardiograms, TBIG recovers accurate results using fewer than 2% of scan lines typically used, showing potential for large reductions in the power usage and data rates necessary for monitoring. Code is available at https://github.com/tue-bmd/task-based-ulsa.
Semantic Diffusion Posterior Sampling for Cardiac Ultrasound Dehazing
Aug 24, 2025Echocardiography plays a central role in cardiac imaging, offering dynamic views of the heart that are essential for diagnosis and monitoring. However, image quality can be significantly degraded by haze arising from multipath reverberations, particularly in difficult-to-image patients. In this work, we propose a semantic-guided, diffusion-based dehazing algorithm developed for the MICCAI Dehazing Echocardiography Challenge (DehazingEcho2025). Our method integrates a pixel-wise noise model, derived from semantic segmentation of hazy inputs into a diffusion posterior sampling framework guided by a generative prior trained on clean ultrasound data. Quantitative evaluation on the challenge dataset demonstrates strong performance across contrast and fidelity metrics. Code for the submitted algorithm is available at https://github.com/tristan-deep/semantic-diffusion-echo-dehazing.
Patient-Adaptive Focused Transmit Beamforming using Cognitive Ultrasound
Aug 12, 2025Focused transmit beamforming is the most commonly used acquisition scheme for echocardiograms, but suffers from relatively low frame rates, and in 3D, even lower volume rates. Fast imaging based on unfocused transmits has disadvantages such as motion decorrelation and limited harmonic imaging capabilities. This work introduces a patient-adaptive focused transmit scheme that has the ability to drastically reduce the number of transmits needed to produce a high-quality ultrasound image. The method relies on posterior sampling with a temporal diffusion model to perceive and reconstruct the anatomy based on partial observations, while subsequently taking an action to acquire the most informative transmits. This active perception modality outperforms random and equispaced subsampling on the 2D EchoNet-Dynamic dataset and a 3D Philips dataset, where we actively select focused elevation planes. Furthermore, we show it achieves better performance in terms of generalized contrast-to-noise ratio when compared to the same number of diverging waves transmits on three in-house echocardiograms. Additionally, we can estimate ejection fraction using only 2% of the total transmits and show that the method is robust to outlier patients. Finally, our method can be run in real-time on GPU accelerators from 2023. The code is publicly available at https://tue-bmd.github.io/ulsa/
High Volume Rate 3D Ultrasound Reconstruction with Diffusion Models
May 28, 2025Three-dimensional ultrasound enables real-time volumetric visualization of anatomical structures. Unlike traditional 2D ultrasound, 3D imaging reduces the reliance on precise probe orientation, potentially making ultrasound more accessible to clinicians with varying levels of experience and improving automated measurements and post-exam analysis. However, achieving both high volume rates and high image quality remains a significant challenge. While 3D diverging waves can provide high volume rates, they suffer from limited tissue harmonic generation and increased multipath effects, which degrade image quality. One compromise is to retain the focusing in elevation while leveraging unfocused diverging waves in the lateral direction to reduce the number of transmissions per elevation plane. Reaching the volume rates achieved by full 3D diverging waves, however, requires dramatically undersampling the number of elevation planes. Subsequently, to render the full volume, simple interpolation techniques are applied. This paper introduces a novel approach to 3D ultrasound reconstruction from a reduced set of elevation planes by employing diffusion models (DMs) to achieve increased spatial and temporal resolution. We compare both traditional and supervised deep learning-based interpolation methods on a 3D cardiac ultrasound dataset. Our results show that DM-based reconstruction consistently outperforms the baselines in image quality and downstream task performance. Additionally, we accelerate inference by leveraging the temporal consistency inherent to ultrasound sequences. Finally, we explore the robustness of the proposed method by exploiting the probabilistic nature of diffusion posterior sampling to quantify reconstruction uncertainty and demonstrate improved recall on out-of-distribution data with synthetic anomalies under strong subsampling.
Deep Generative Models for Bayesian Inference on High-Rate Sensor Data: Applications in Automotive Radar and Medical Imaging
Apr 16, 2025



Deep generative models have been studied and developed primarily in the context of natural images and computer vision. This has spurred the development of (Bayesian) methods that use these generative models for inverse problems in image restoration, such as denoising, inpainting, and super-resolution. In recent years, generative modeling for Bayesian inference on sensory data has also gained traction. Nevertheless, the direct application of generative modeling techniques initially designed for natural images on raw sensory data is not straightforward, requiring solutions that deal with high dynamic range signals acquired from multiple sensors or arrays of sensors that interfere with each other, and that typically acquire data at a very high rate. Moreover, the exact physical data-generating process is often complex or unknown. As a consequence, approximate models are used, resulting in discrepancies between model predictions and the observations that are non-Gaussian, in turn complicating the Bayesian inverse problem. Finally, sensor data is often used in real-time processing or decision-making systems, imposing stringent requirements on, e.g., latency and throughput. In this paper, we will discuss some of these challenges and offer approaches to address them, all in the context of high-rate real-time sensing applications in automotive radar and medical imaging.
Sequential Posterior Sampling with Diffusion Models
Sep 09, 2024



Diffusion models have quickly risen in popularity for their ability to model complex distributions and perform effective posterior sampling. Unfortunately, the iterative nature of these generative models makes them computationally expensive and unsuitable for real-time sequential inverse problems such as ultrasound imaging. Considering the strong temporal structure across sequences of frames, we propose a novel approach that models the transition dynamics to improve the efficiency of sequential diffusion posterior sampling in conditional image synthesis. Through modeling sequence data using a video vision transformer (ViViT) transition model based on previous diffusion outputs, we can initialize the reverse diffusion trajectory at a lower noise scale, greatly reducing the number of iterations required for convergence. We demonstrate the effectiveness of our approach on a real-world dataset of high frame rate cardiac ultrasound images and show that it achieves the same performance as a full diffusion trajectory while accelerating inference 25$\times$, enabling real-time posterior sampling. Furthermore, we show that the addition of a transition model improves the PSNR up to 8\% in cases with severe motion. Our method opens up new possibilities for real-time applications of diffusion models in imaging and other domains requiring real-time inference.
Active Diffusion Subsampling
Jun 20, 2024



Subsampling is commonly used to mitigate costs associated with data acquisition, such as time or energy requirements, motivating the development of algorithms for estimating the fully-sampled signal of interest $x$ from partially observed measurements $y$. In maximum-entropy sampling, one selects measurement locations that are expected to have the highest entropy, so as to minimize uncertainty about $x$. This approach relies on an accurate model of the posterior distribution over future measurements, given the measurements observed so far. Recently, diffusion models have been shown to produce high-quality posterior samples of high-dimensional signals using guided diffusion. In this work, we propose Active Diffusion Subsampling (ADS), a method for performing active subsampling using guided diffusion in which the model tracks a distribution of beliefs over the true state of $x$ throughout the reverse diffusion process, progressively decreasing its uncertainty by choosing to acquire measurements with maximum expected entropy, and ultimately generating the posterior distribution $p(x | y)$. ADS can be applied using pre-trained diffusion models for any subsampling rate, and does not require task-specific retraining - just the specification of a measurement model. Furthermore, the maximum entropy sampling policy employed by ADS is interpretable, enhancing transparency relative to existing methods using black-box policies. Experimentally, we show that ADS outperforms fixed sampling strategies, and study an application of ADS in Magnetic Resonance Imaging acceleration using the fastMRI dataset, finding that ADS performs competitively with supervised methods. Code available at https://active-diffusion-subsampling.github.io/.
Dehazing Ultrasound using Diffusion Models
Jul 20, 2023



Echocardiography has been a prominent tool for the diagnosis of cardiac disease. However, these diagnoses can be heavily impeded by poor image quality. Acoustic clutter emerges due to multipath reflections imposed by layers of skin, subcutaneous fat, and intercostal muscle between the transducer and heart. As a result, haze and other noise artifacts pose a real challenge to cardiac ultrasound imaging. In many cases, especially with difficult-to-image patients such as patients with obesity, a diagnosis from B-Mode ultrasound imaging is effectively rendered unusable, forcing sonographers to resort to contrast-enhanced ultrasound examinations or refer patients to other imaging modalities. Tissue harmonic imaging has been a popular approach to combat haze, but in severe cases is still heavily impacted by haze. Alternatively, denoising algorithms are typically unable to remove highly structured and correlated noise, such as haze. It remains a challenge to accurately describe the statistical properties of structured haze, and develop an inference method to subsequently remove it. Diffusion models have emerged as powerful generative models and have shown their effectiveness in a variety of inverse problems. In this work, we present a joint posterior sampling framework that combines two separate diffusion models to model the distribution of both clean ultrasound and haze in an unsupervised manner. Furthermore, we demonstrate techniques for effectively training diffusion models on radio-frequency ultrasound data and highlight the advantages over image data. Experiments on both \emph{in-vitro} and \emph{in-vivo} cardiac datasets show that the proposed dehazing method effectively removes haze while preserving signals from weakly reflected tissue.
Accelerated Intravascular Ultrasound Imaging using Deep Reinforcement Learning
Jan 24, 2022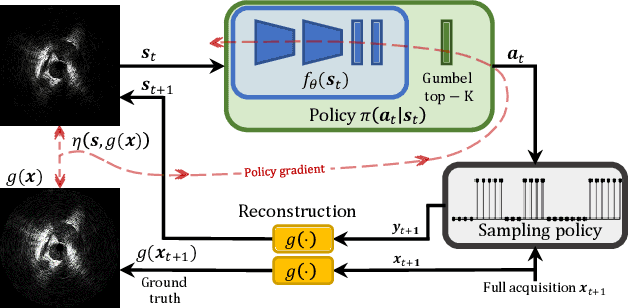
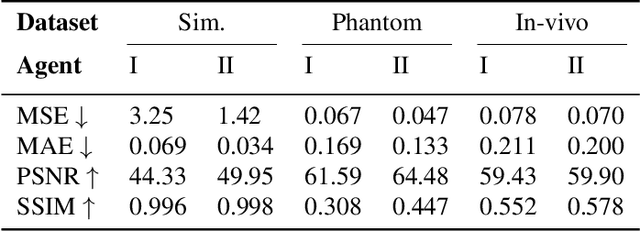

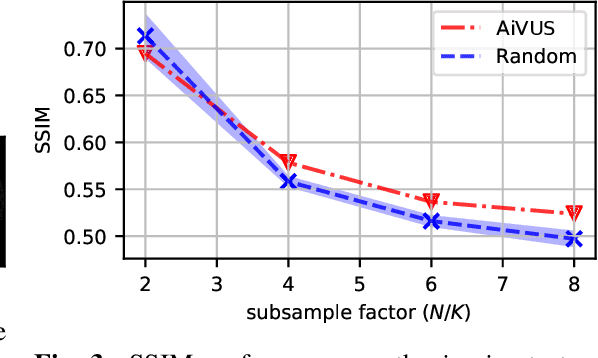
Intravascular ultrasound (IVUS) offers a unique perspective in the treatment of vascular diseases by creating a sequence of ultrasound-slices acquired from within the vessel. However, unlike conventional hand-held ultrasound, the thin catheter only provides room for a small number of physical channels for signal transfer from a transducer-array at the tip. For continued improvement of image quality and frame rate, we present the use of deep reinforcement learning to deal with the current physical information bottleneck. Valuable inspiration has come from the field of magnetic resonance imaging (MRI), where learned acquisition schemes have brought significant acceleration in image acquisition at competing image quality. To efficiently accelerate IVUS imaging, we propose a framework that utilizes deep reinforcement learning for an optimal adaptive acquisition policy on a per-frame basis enabled by actor-critic methods and Gumbel top-$K$ sampling.
* 5 pages, 3 figures, conference
Automated Gain Control Through Deep Reinforcement Learning for Downstream Radar Object Detection
Jul 08, 2021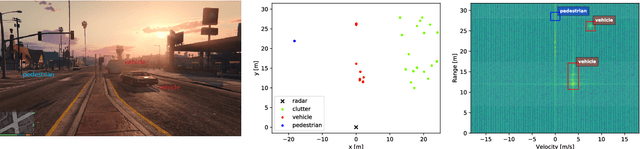
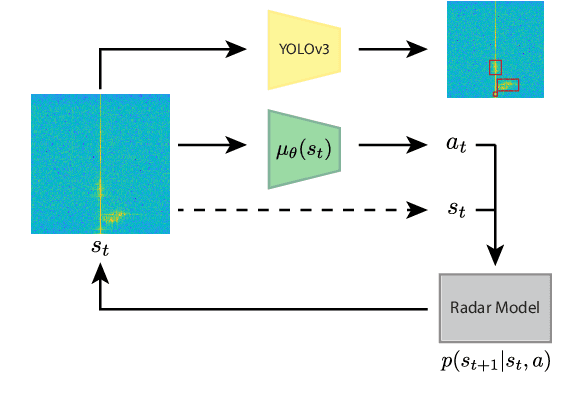
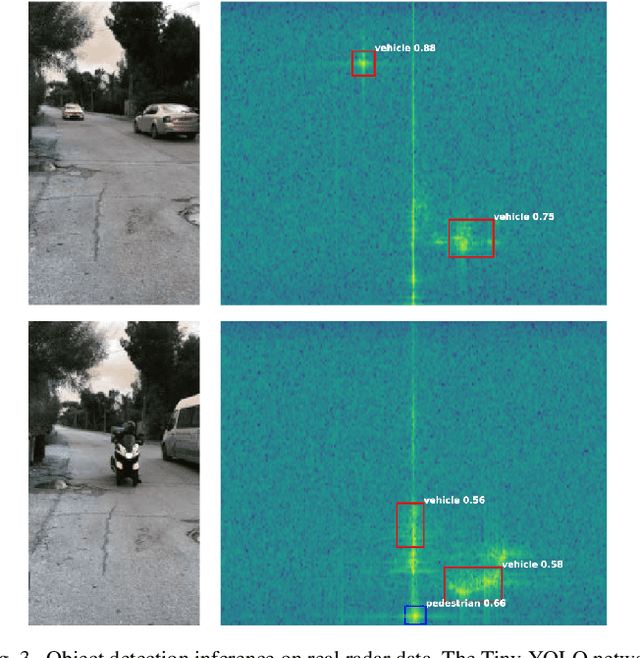

Cognitive radars are systems that rely on learning through interactions of the radar with the surrounding environment. To realize this, radar transmit parameters can be adapted such that they facilitate some downstream task. This paper proposes the use of deep reinforcement learning (RL) to learn policies for gain control under the object detection task. The YOLOv3 single-shot object detector is used for the downstream task and will be concurrently used alongside the RL agent. Furthermore, a synthetic dataset is introduced which models the radar environment with use of the Grand Theft Auto V game engine. This approach allows for simulation of vast amounts of data with flexible assignment of the radar parameters to aid in the active learning process.
* 5 pages, 5 figures, conference