 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProSPy: A Profiling-Driven SQL-Python Agentic Framework for Enterprise Text-to-SQL
Jun 04, 2026Large language models have substantially advanced Text-to-SQL systems, yet applying them to enterprise-scale databases remains challenging. Real-world databases often contain large and heterogeneous schemas, incomplete metadata, dialect-specific SQL syntax, and complex analytical questions that are difficult to solve with a single SQL query. To address these challenges, we propose ProSPy, a Profiling-driven SQL--Python agentic framework for enterprise-scale Text-to-SQL. ProSPy structures the reasoning process into four stages: it first extracts fine-grained data evidence through automatic profiling, progressively prunes large schemas into task-relevant contexts, fetches intermediate views through a dialect-agnostic SQL interface, and finally performs flexible downstream analysis with Python. This design combines the efficiency of SQL over large databases with the flexibility of Python-based analysis, while reducing reliance on unreliable metadata and improving robustness across SQL dialects. Experiments on Spider 2.0-Lite and Spider 2.0-Snow show that ProSPy consistently outperforms strong baselines with both open-source and proprietary models, achieving execution accuracies of 60.15% and 60.51% with Claude-4.5-Opus, without majority voting. Further analysis shows that ProSPy is robust to SQL dialect variations and achieves a favorable trade-off between schema recall and precision.
EviLink: Multi-Path Schema Linking with Uncertainty-Guided Evidence Acquisition for Large-Scale Text-to-SQL
May 28, 2026Schema linking is a difficult and important step in large-scale Text-to-SQL, where systems must identify a compact yet sufficient schema context from large and ambiguous databases. Existing methods often treat schema linking as deterministic selection around a single SQL path, but complex questions may admit multiple valid realizations with different schema needs. We reframe schema linking as uncertainty-aware schema-need inference over multiple plausible SQL paths, where the system distinguishes required schema items from path-dependent uncertain ones and acquires evidence only where needed. We instantiate this reframing with EviLink, which combines multi-hypothesis schema grounding with uncertainty-guided evidence acquisition. Experiments on BIRD-Dev and Spider2-Snow show that this perspective improves the balance among schema completeness, schema relevance, and token cost. On Spider2-Snow, EviLink achieves 90.15% field-level strict recall rate, uses 123.30K average tokens, and improves downstream SQL generation under a fixed generator.
MCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023



With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.
Edit Everything: A Text-Guided Generative System for Images Editing
Apr 27, 2023



We introduce a new generative system called Edit Everything, which can take image and text inputs and produce image outputs. Edit Everything allows users to edit images using simple text instructions. Our system designs prompts to guide the visual module in generating requested images. Experiments demonstrate that Edit Everything facilitates the implementation of the visual aspects of Stable Diffusion with the use of Segment Anything model and CLIP. Our system is publicly available at https://github.com/DefengXie/Edit_Everything.
Combining Improvements for Exploiting Dependency Trees in Neural Semantic Parsing
Dec 25, 2021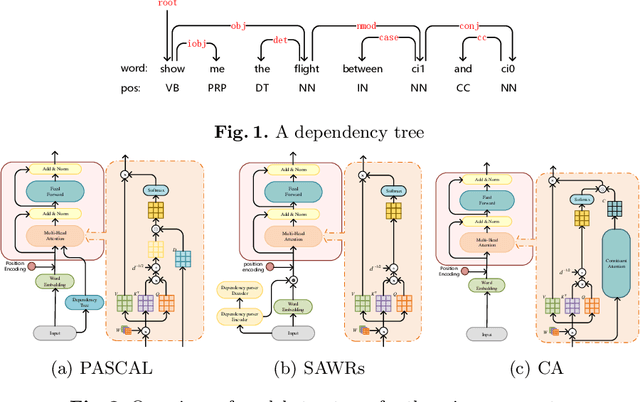
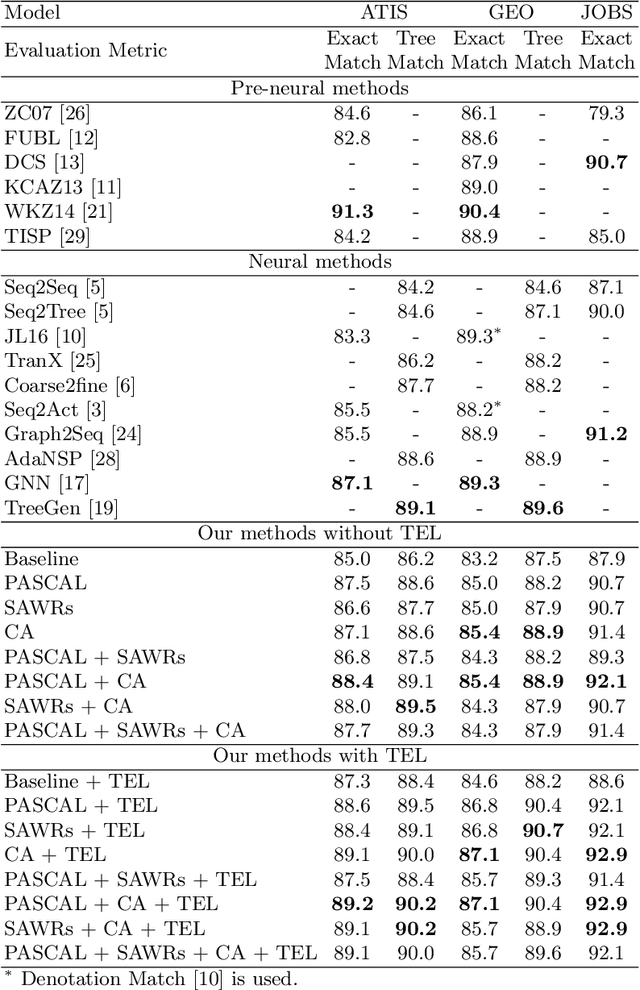
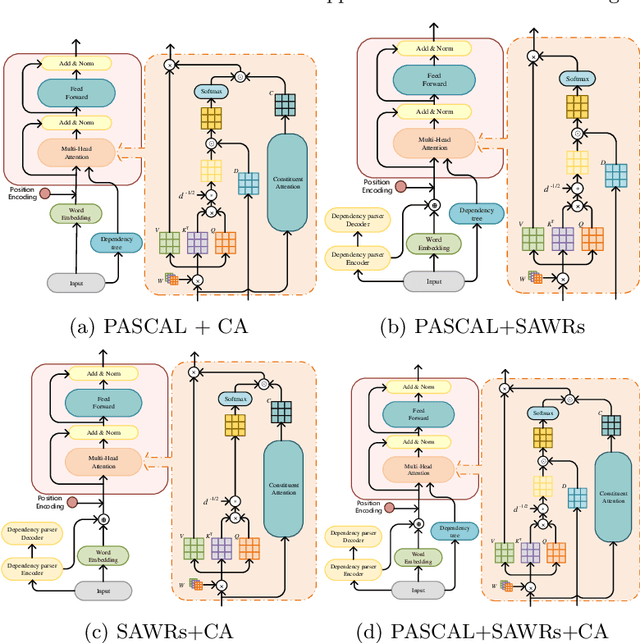
The dependency tree of a natural language sentence can capture the interactions between semantics and words. However, it is unclear whether those methods which exploit such dependency information for semantic parsing can be combined to achieve further improvement and the relationship of those methods when they combine. In this paper, we examine three methods to incorporate such dependency information in a Transformer based semantic parser and empirically study their combinations. We first replace standard self-attention heads in the encoder with parent-scaled self-attention (PASCAL) heads, i.e., the ones that can attend to the dependency parent of each token. Then we concatenate syntax-aware word representations (SAWRs), i.e., the intermediate hidden representations of a neural dependency parser, with ordinary word embedding to enhance the encoder. Later, we insert the constituent attention (CA) module to the encoder, which adds an extra constraint to attention heads that can better capture the inherent dependency structure of input sentences. Transductive ensemble learning (TEL) is used for model aggregation, and an ablation study is conducted to show the contribution of each method. Our experiments show that CA is complementary to PASCAL or SAWRs, and PASCAL + CA provides state-of-the-art performance among neural approaches on ATIS, GEO, and JOBS.