 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Random Ferns for Semantic Segmentation of PolSAR Images
Feb 07, 2022
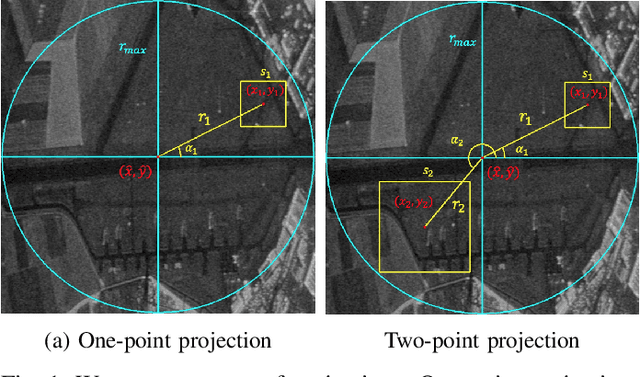
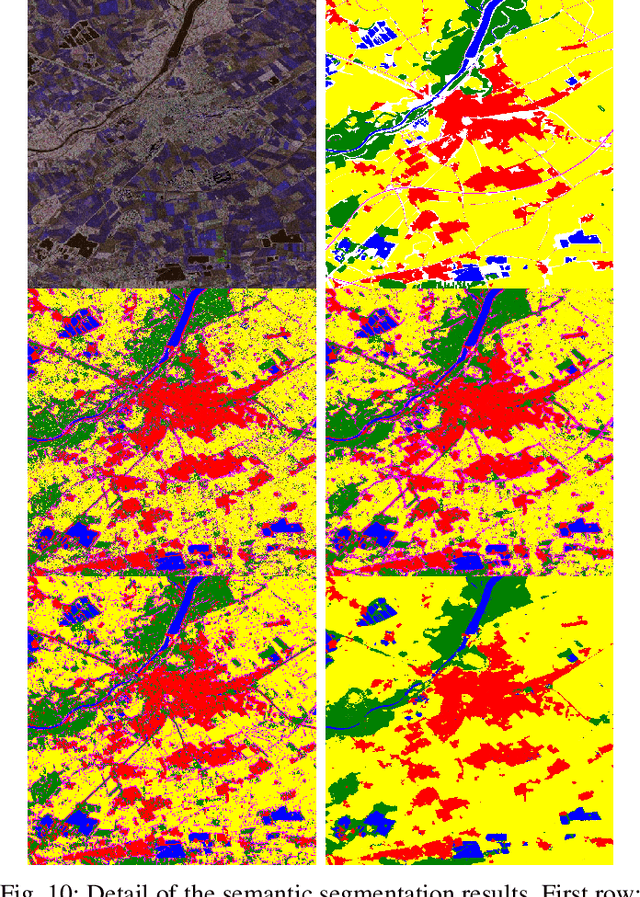
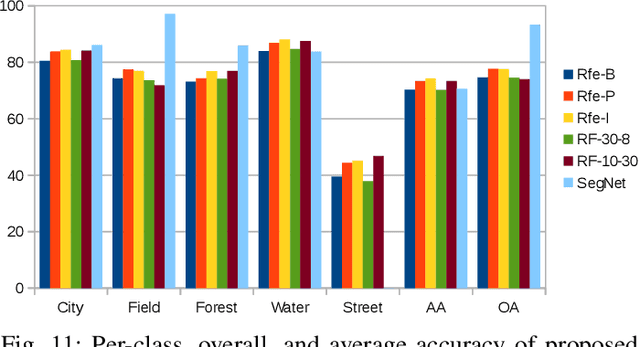
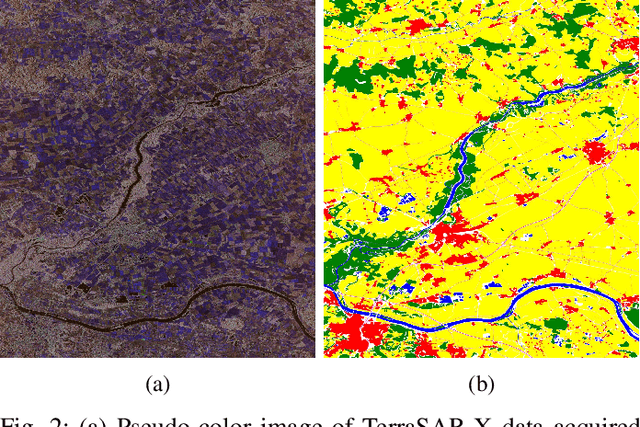
Random Ferns -- as a less known example of Ensemble Learning -- have been successfully applied in many Computer Vision applications ranging from keypoint matching to object detection. This paper extends the Random Fern framework to the semantic segmentation of polarimetric synthetic aperture radar images. By using internal projections that are defined over the space of Hermitian matrices, the proposed classifier can be directly applied to the polarimetric covariance matrices without the need to explicitly compute predefined image features. Furthermore, two distinct optimization strategies are proposed: The first based on pre-selection and grouping of internal binary features before the creation of the classifier; and the second based on iteratively improving the properties of a given Random Fern. Both strategies are able to boost the performance by filtering features that are either redundant or have a low information content and by grouping correlated features to best fulfill the independence assumptions made by the Random Fern classifier. Experiments show that results can be achieved that are similar to a more complex Random Forest model and competitive to a deep learning baseline.
Explaining Graph-level Predictions with Communication Structure-Aware Cooperative Games
Feb 16, 2022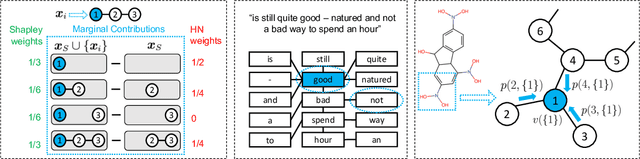
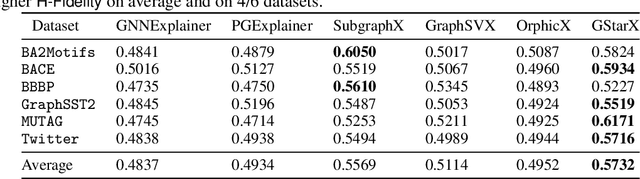
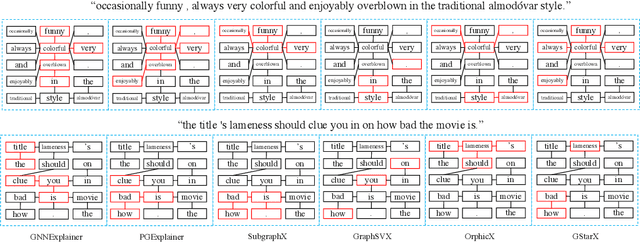
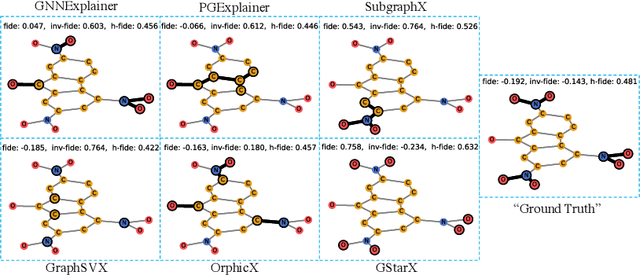
Explaining predictions made by machine learning models is important and have attracted an increased interest. The Shapley value from cooperative game theory has been proposed as a prime approach to compute feature importances towards predictions, especially for images, text, tabular data, and recently graph neural networks (GNNs) on graphs. In this work, we revisit the appropriateness of the Shapley value for graph explanation, where the task is to identify the most important subgraph and constituent nodes for graph-level predictions. We purport that the Shapley value is a no-ideal choice for graph data because it is by definition not structure-aware. We propose a Graph Structure-aware eXplanation (GStarX) method to leverage the critical graph structure information to improve the explanation. Specifically, we propose a scoring function based on a new structure-aware value from the cooperative game theory called the HN value. When used to score node importance, the HN value utilizes graph structures to attribute cooperation surplus between neighbor nodes, resembling message passing in GNNs, so that node importance scores reflect not only the node feature importance, but also the structural roles. We demonstrate that GstarX produces qualitatively more intuitive explanations, and quantitatively improves over strong baselines on chemical graph property prediction and text graph sentiment classification.
Learning Multi-granularity User Intent Unit for Session-based Recommendation
Jan 10, 2022
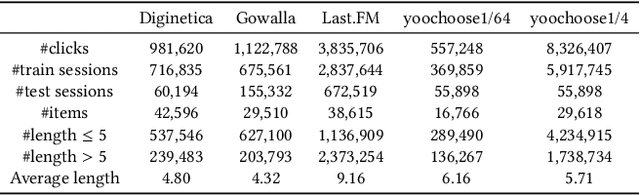
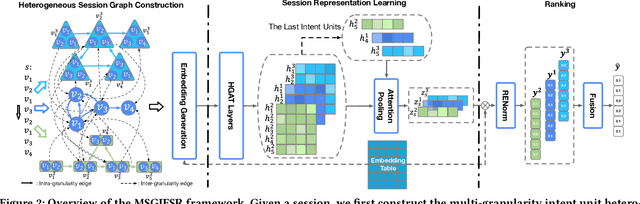
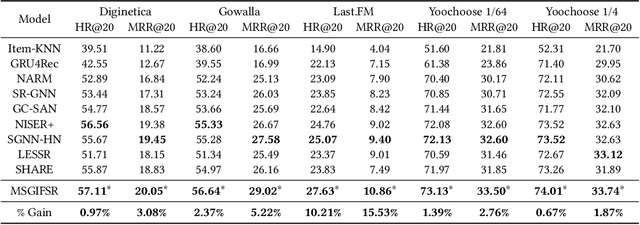
Session-based recommendation aims to predict a user's next action based on previous actions in the current session. The major challenge is to capture authentic and complete user preferences in the entire session. Recent work utilizes graph structure to represent the entire session and adopts Graph Neural Network to encode session information. This modeling choice has been proved to be effective and achieved remarkable results. However, most of the existing studies only consider each item within the session independently and do not capture session semantics from a high-level perspective. Such limitation often leads to severe information loss and increases the difficulty of capturing long-range dependencies within a session. Intuitively, compared with individual items, a session snippet, i.e., a group of locally consecutive items, is able to provide supplemental user intents which are hardly captured by existing methods. In this work, we propose to learn multi-granularity consecutive user intent unit to improve the recommendation performance. Specifically, we creatively propose Multi-granularity Intent Heterogeneous Session Graph which captures the interactions between different granularity intent units and relieves the burden of long-dependency. Moreover, we propose the Intent Fusion Ranking module to compose the recommendation results from various granularity user intents. Compared with current methods that only leverage intents from individual items, IFR benefits from different granularity user intents to generate more accurate and comprehensive session representation, thus eventually boosting recommendation performance. We conduct extensive experiments on five session-based recommendation datasets and the results demonstrate the effectiveness of our method.
Socially-Optimal Mechanism Design for Incentivized Online Learning
Dec 29, 2021
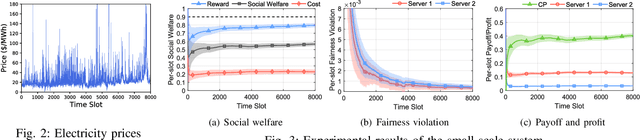
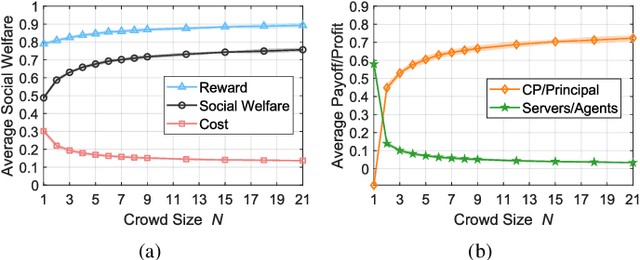

Multi-arm bandit (MAB) is a classic online learning framework that studies the sequential decision-making in an uncertain environment. The MAB framework, however, overlooks the scenario where the decision-maker cannot take actions (e.g., pulling arms) directly. It is a practically important scenario in many applications such as spectrum sharing, crowdsensing, and edge computing. In these applications, the decision-maker would incentivize other selfish agents to carry out desired actions (i.e., pulling arms on the decision-maker's behalf). This paper establishes the incentivized online learning (IOL) framework for this scenario. The key challenge to design the IOL framework lies in the tight coupling of the unknown environment learning and asymmetric information revelation. To address this, we construct a special Lagrangian function based on which we propose a socially-optimal mechanism for the IOL framework. Our mechanism satisfies various desirable properties such as agent fairness, incentive compatibility, and voluntary participation. It achieves the same asymptotic performance as the state-of-art benchmark that requires extra information. Our analysis also unveils the power of crowd in the IOL framework: a larger agent crowd enables our mechanism to approach more closely the theoretical upper bound of social performance. Numerical results demonstrate the advantages of our mechanism in large-scale edge computing.
Visual Attention Prediction Improves Performance of Autonomous Drone Racing Agents
Jan 10, 2022



Humans race drones faster than neural networks trained for end-to-end autonomous flight. This may be related to the ability of human pilots to select task-relevant visual information effectively. This work investigates whether neural networks capable of imitating human eye gaze behavior and attention can improve neural network performance for the challenging task of vision-based autonomous drone racing. We hypothesize that gaze-based attention prediction can be an efficient mechanism for visual information selection and decision making in a simulator-based drone racing task. We test this hypothesis using eye gaze and flight trajectory data from 18 human drone pilots to train a visual attention prediction model. We then use this visual attention prediction model to train an end-to-end controller for vision-based autonomous drone racing using imitation learning. We compare the drone racing performance of the attention-prediction controller to those using raw image inputs and image-based abstractions (i.e., feature tracks). Our results show that attention-prediction based controllers outperform the baselines and are able to complete a challenging race track consistently with up to 88% success rate. Furthermore, visual attention-prediction and feature-track based models showed better generalization performance than image-based models when evaluated on hold-out reference trajectories. Our results demonstrate that human visual attention prediction improves the performance of autonomous vision-based drone racing agents and provides an essential step towards vision-based, fast, and agile autonomous flight that eventually can reach and even exceed human performances.
Collaborative Training of Heterogeneous Reinforcement Learning Agents in Environments with Sparse Rewards: What and When to Share?
Feb 24, 2022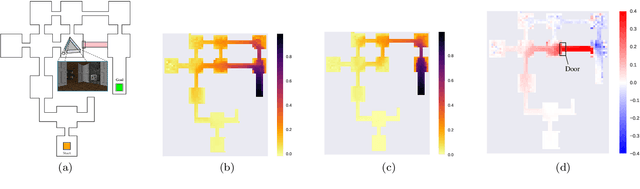
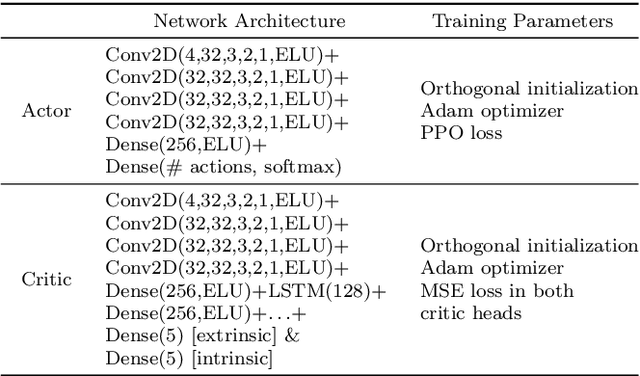
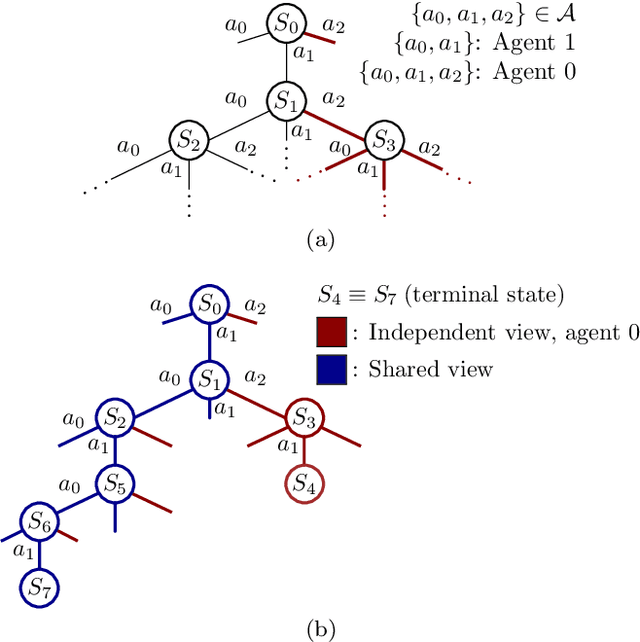
In the early stages of human life, babies develop their skills by exploring different scenarios motivated by their inherent satisfaction rather than by extrinsic rewards from the environment. This behavior, referred to as intrinsic motivation, has emerged as one solution to address the exploration challenge derived from reinforcement learning environments with sparse rewards. Diverse exploration approaches have been proposed to accelerate the learning process over single- and multi-agent problems with homogeneous agents. However, scarce studies have elaborated on collaborative learning frameworks between heterogeneous agents deployed into the same environment, but interacting with different instances of the latter without any prior knowledge. Beyond the heterogeneity, each agent's characteristics grant access only to a subset of the full state space, which may hide different exploration strategies and optimal solutions. In this work we combine ideas from intrinsic motivation and transfer learning. Specifically, we focus on sharing parameters in actor-critic model architectures and on combining information obtained through intrinsic motivation with the aim of having a more efficient exploration and faster learning. We test our strategies through experiments performed over a modified ViZDooM's My Way Home scenario, which is more challenging than its original version and allows evaluating the heterogeneity between agents. Our results reveal different ways in which a collaborative framework with little additional computational cost can outperform an independent learning process without knowledge sharing. Additionally, we depict the need for modulating correctly the importance between the extrinsic and intrinsic rewards to avoid undesired agent behaviors.
Towards Further Understanding of Sparse Filtering via Information Bottleneck
Oct 20, 2019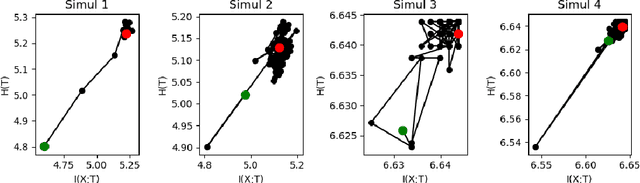
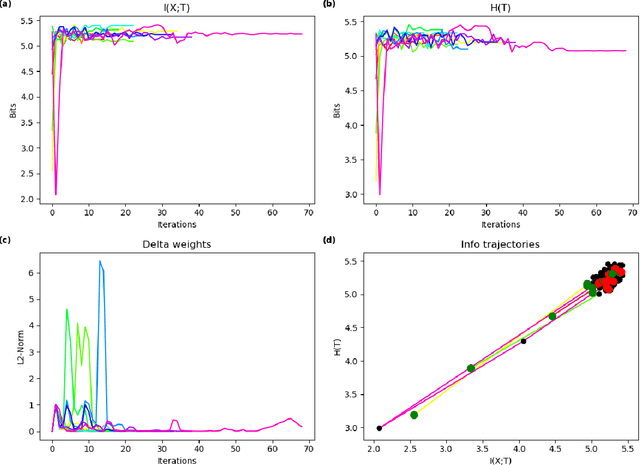
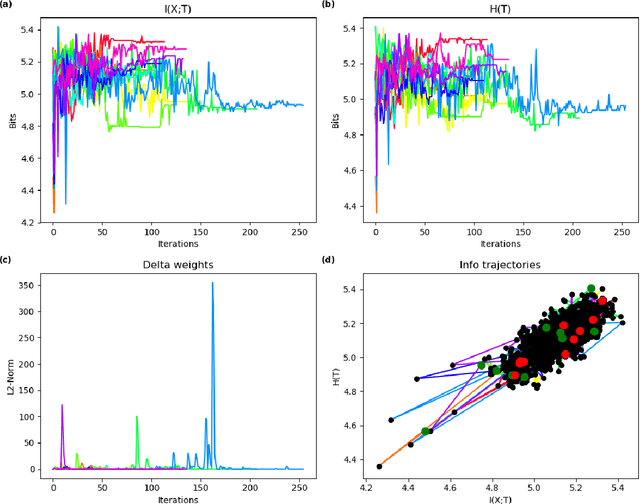
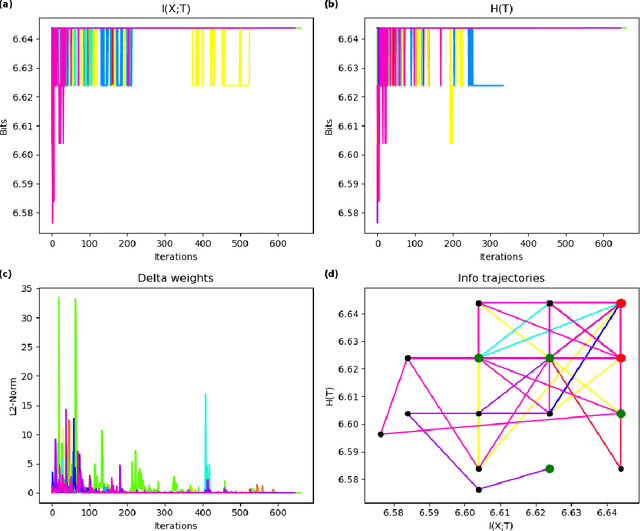
In this paper we examine a formalization of feature distribution learning (FDL) in information-theoretic terms relying on the analytical approach and on the tools already used in the study of the information bottleneck (IB). It has been conjectured that the behavior of FDL algorithms could be expressed as an optimization problem over two information-theoretic quantities: the mutual information of the data with the learned representations and the entropy of the learned distribution. In particular, such a formulation was offered in order to explain the success of the most prominent FDL algorithm, sparse filtering (SF). This conjecture was, however, left unproven. In this work, we aim at providing preliminary empirical support to this conjecture by performing experiments reminiscent of the work done on deep neural networks in the context of the IB research. Specifically, we borrow the idea of using information planes to analyze the behavior of the SF algorithm and gain insights on its dynamics. A confirmation of the conjecture about the dynamics of FDL may provide solid ground to develop information-theoretic tools to assess the quality of the learning process in FDL, and it may be extended to other unsupervised learning algorithms.
Ordinal-Quadruplet: Retrieval of Missing Classes in Ordinal Time Series
Jan 24, 2022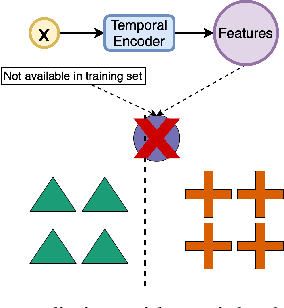

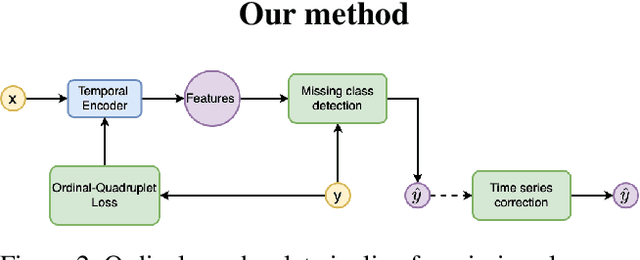
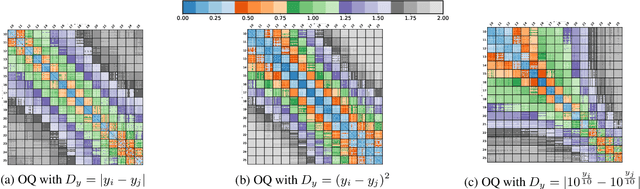
In this paper, we propose an ordered time series classification framework that is robust against missing classes in the training data, i.e., during testing we can prescribe classes that are missing during training. This framework relies on two main components: (1) our newly proposed ordinal-quadruplet loss, which forces the model to learn latent representation while preserving the ordinal relation among labels, (2) testing procedure, which utilizes the property of latent representation (order preservation). We conduct experiments based on real world multivariate time series data and show the significant improvement in the prediction of missing labels even with 40% of the classes are missing from training. Compared with the well-known triplet loss optimization augmented with interpolation for missing information, in some cases, we nearly double the accuracy.
Information-Theoretic Generalization Bounds for Meta-Learning and Applications
May 14, 2020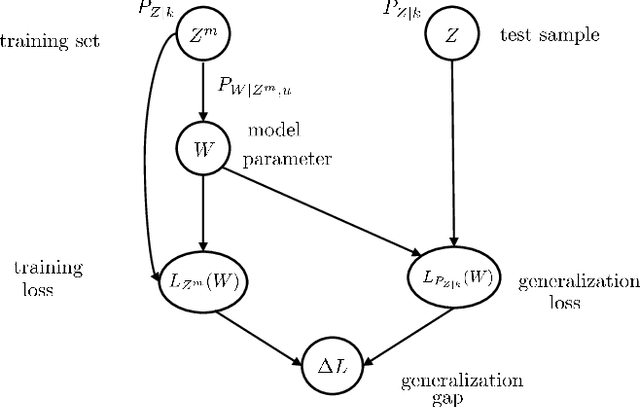
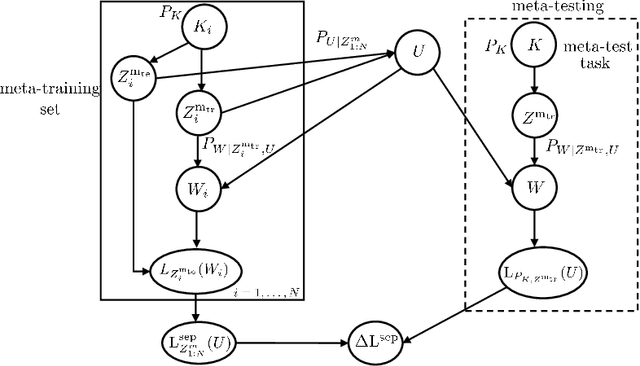
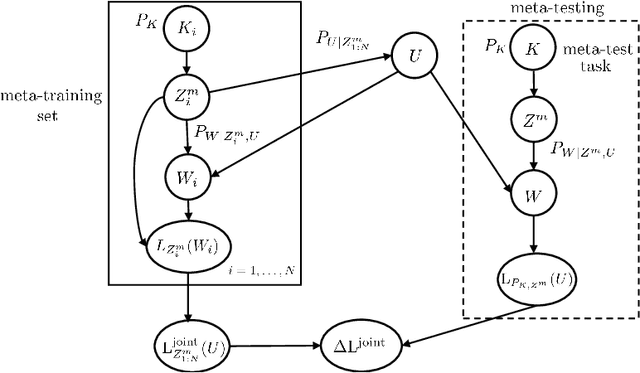
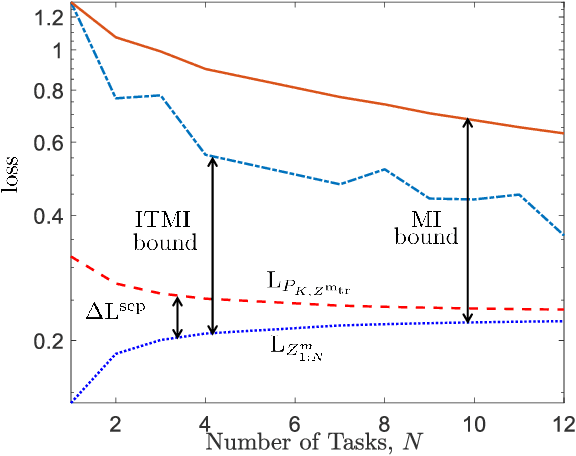
Meta-learning, or "learning to learn", refers to techniques that infer an inductive bias from data corresponding to multiple related tasks with the goal of improving the sample efficiency for new, previously unobserved, tasks. A key performance measure for meta-learning is the meta-generalization gap, that is, the difference between the average loss measured on the meta-training data and on a new, randomly selected task. This paper presents novel information-theoretic upper bounds on the meta-generalization gap. Two broad classes of meta-learning algorithms are considered that uses either separate within-task training and test sets, like MAML, or joint within-task training and test sets, like Reptile. Extending the existing work for conventional learning, an upper bound on the meta-generalization gap is derived for the former class that depends on the mutual information (MI) between the output of the meta-learning algorithm and its input meta-training data. For the latter, the derived bound includes an additional MI between the output of the per-task learning procedure and corresponding data set to capture within-task uncertainty. Tighter bounds are then developed, under given technical conditions, for the two classes via novel Individual Task MI (ITMI) bounds. Applications of the derived bounds are finally discussed, including a broad class of noisy iterative algorithms for meta-learning.
Probabilistic Consensus on Feature Distribution for Multi-robot Systems with Markovian Exploration Dynamics
Feb 07, 2022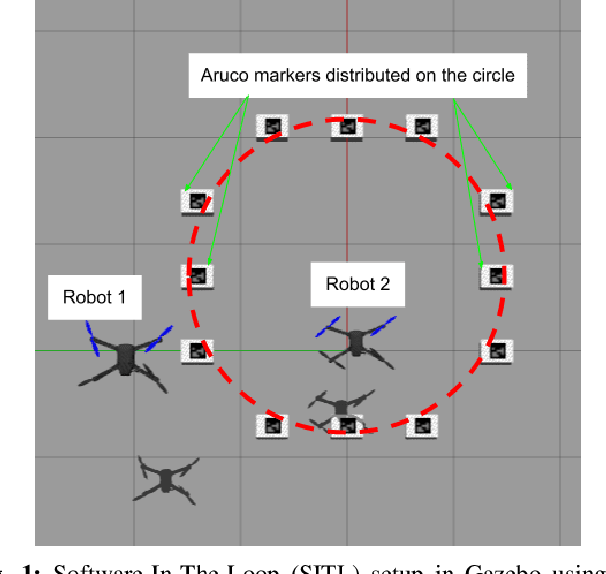
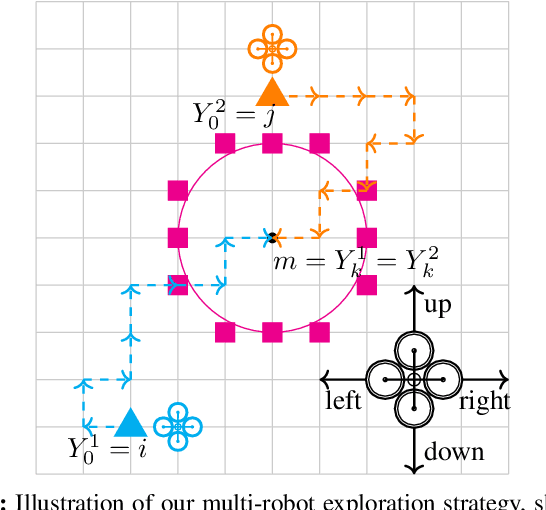
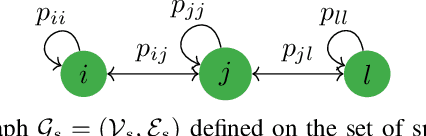
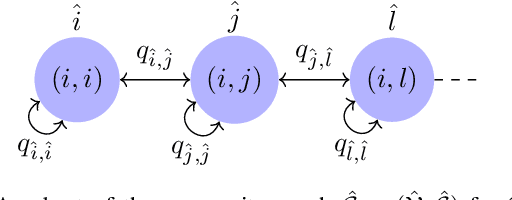
In this paper, we present a consensus-based decentralized multi-robot approach to reconstruct a discrete distribution of features, modeled as an occupancy grid map, that represent information contained in a bounded planar environment, such as visual cues used for navigation or semantic labels associated with object detection. The robots explore the environment according to a random walk modeled by a discrete-time discrete-state (DTDS) Markov chain and estimate the feature distribution from their own measurements and the estimates communicated by neighboring robots, using a distributed Chernoff fusion protocol. We prove that under this decentralized fusion protocol, each robot's feature distribution converges to the actual distribution in an almost sure sense. We verify this result in numerical simulations that show that the Hellinger distance between the estimated and actual feature distributions converges to zero over time for each robot. We also validate our strategy through Software-In-The-Loop (SITL) simulations of quadrotors that search a bounded square grid for a set of visual features distributed on a discretized circle.