 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Centric Benchmark for Label Noise Estimation and Ranking in Remote Sensing Image Segmentation
Feb 28, 2026High-quality pixel-level annotations are essential for the semantic segmentation of remote sensing imagery. However, such labels are expensive to obtain and often affected by noise due to the labor-intensive and time-consuming nature of pixel-wise annotation, which makes it challenging for human annotators to label every pixel accurately. Annotation errors can significantly degrade the performance and robustness of modern segmentation models, motivating the need for reliable mechanisms to identify and quantify noisy training samples. This paper introduces a novel Data-Centric benchmark, together with a novel, publicly available dataset and two techniques for identifying, quantifying, and ranking training samples according to their level of label noise in remote sensing semantic segmentation. Such proposed methods leverage complementary strategies based on model uncertainty, prediction consistency, and representation analysis, and consistently outperform established baselines across a range of experimental settings. The outcomes of this work are publicly available at https://github.com/keillernogueira/label_noise_segmentation.
Very High-Resolution Forest Mapping with TanDEM-X InSAR Data and Self-Supervised Learning
May 06, 2025Deep learning models have shown encouraging capabilities for mapping accurately forests at medium resolution with TanDEM-X interferometric SAR data. Such models, as most of current state-of-the-art deep learning techniques in remote sensing, are trained in a fully-supervised way, which requires a large amount of labeled data for training and validation. In this work, our aim is to exploit the high-resolution capabilities of the TanDEM-X mission to map forests at 6 m. The goal is to overcome the intrinsic limitations posed by midresolution products, which affect, e.g., the detection of narrow roads within vegetated areas and the precise delineation of forested regions contours. To cope with the lack of extended reliable reference datasets at such a high resolution, we investigate self-supervised learning techniques for extracting highly informative representations from the input features, followed by a supervised training step with a significantly smaller number of reliable labels. A 1 m resolution forest/non-forest reference map over Pennsylvania, USA, allows for comparing different training approaches for the development of an effective forest mapping framework with limited labeled samples. We select the best-performing approach over this test region and apply it in a real-case forest mapping scenario over the Amazon rainforest, where only very few labeled data at high resolution are available. In this challenging scenario, the proposed self-supervised framework significantly enhances the classification accuracy with respect to fully-supervised methods, trained using the same amount of labeled data, representing an extremely promising starting point for large-scale, very high-resolution forest mapping with TanDEM-X data.
Core-Set Selection for Data-efficient Land Cover Segmentation
May 02, 2025



The increasing accessibility of remotely sensed data and the potential of such data to inform large-scale decision-making has driven the development of deep learning models for many Earth Observation tasks. Traditionally, such models must be trained on large datasets. However, the common assumption that broadly larger datasets lead to better outcomes tends to overlook the complexities of the data distribution, the potential for introducing biases and noise, and the computational resources required for processing and storing vast datasets. Therefore, effective solutions should consider both the quantity and quality of data. In this paper, we propose six novel core-set selection methods for selecting important subsets of samples from remote sensing image segmentation datasets that rely on imagery only, labels only, and a combination of each. We benchmark these approaches against a random-selection baseline on three commonly used land cover classification datasets: DFC2022, Vaihingen, and Potsdam. In each of the datasets, we demonstrate that training on a subset of samples outperforms the random baseline, and some approaches outperform training on all available data. This result shows the importance and potential of data-centric learning for the remote sensing domain. The code is available at https://github.com/keillernogueira/data-centric-rs-classification/.
Better Coherence, Better Height: Fusing Physical Models and Deep Learning for Forest Height Estimation from Interferometric SAR Data
Apr 14, 2025



Estimating forest height from Synthetic Aperture Radar (SAR) images often relies on traditional physical models, which, while interpretable and data-efficient, can struggle with generalization. In contrast, Deep Learning (DL) approaches lack physical insight. To address this, we propose CoHNet - an end-to-end framework that combines the best of both worlds: DL optimized with physics-informed constraints. We leverage a pre-trained neural surrogate model to enforce physical plausibility through a unique training loss. Our experiments show that this approach not only improves forest height estimation accuracy but also produces meaningful features that enhance the reliability of predictions.
Data-Centric Machine Learning for Geospatial Remote Sensing Data
Dec 08, 2023



Recent developments and research in modern machine learning have led to substantial improvements in the geospatial field. Although numerous deep learning models have been proposed, the majority of them have been developed on benchmark datasets that lack strong real-world relevance. Furthermore, the performance of many methods has already saturated on these datasets. We argue that shifting the focus towards a complementary data-centric perspective is necessary to achieve further improvements in accuracy, generalization ability, and real impact in end-user applications. This work presents a definition and precise categorization of automated data-centric learning approaches for geospatial data. It highlights the complementary role of data-centric learning with respect to model-centric in the larger machine learning deployment cycle. We review papers across the entire geospatial field and categorize them into different groups. A set of representative experiments shows concrete implementation examples. These examples provide concrete steps to act on geospatial data with data-centric machine learning approaches.
Leveraging Citizen Science for Flood Extent Detection using Machine Learning Benchmark Dataset
Nov 15, 2023



Accurate detection of inundated water extents during flooding events is crucial in emergency response decisions and aids in recovery efforts. Satellite Remote Sensing data provides a global framework for detecting flooding extents. Specifically, Sentinel-1 C-Band Synthetic Aperture Radar (SAR) imagery has proven to be useful in detecting water bodies due to low backscatter of water features in both co-polarized and cross-polarized SAR imagery. However, increased backscatter can be observed in certain flooded regions such as presence of infrastructure and trees - rendering simple methods such as pixel intensity thresholding and time-series differencing inadequate. Machine Learning techniques has been leveraged to precisely capture flood extents in flooded areas with bumps in backscatter but needs high amounts of labelled data to work desirably. Hence, we created a labeled known water body extent and flooded area extents during known flooding events covering about 36,000 sq. kilometers of regions within mainland U.S and Bangladesh. Further, We also leveraged citizen science by open-sourcing the dataset and hosting an open competition based on the dataset to rapidly prototype flood extent detection using community generated models. In this paper we present the information about the dataset, the data processing pipeline, a baseline model and the details about the competition, along with discussion on winning approaches. We believe the dataset adds to already existing datasets based on Sentinel-1C SAR data and leads to more robust modeling of flood extents. We also hope the results from the competition pushes the research in flood extent detection further.
EOD: The IEEE GRSS Earth Observation Database
Sep 26, 2022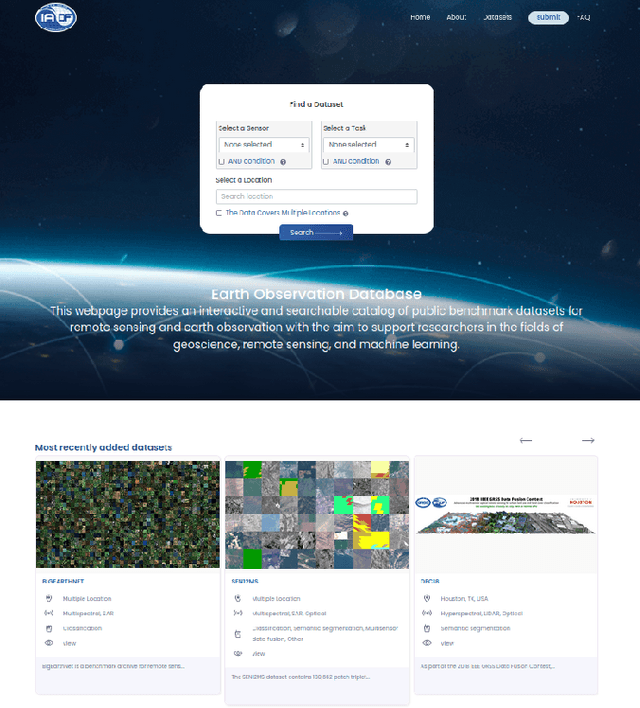
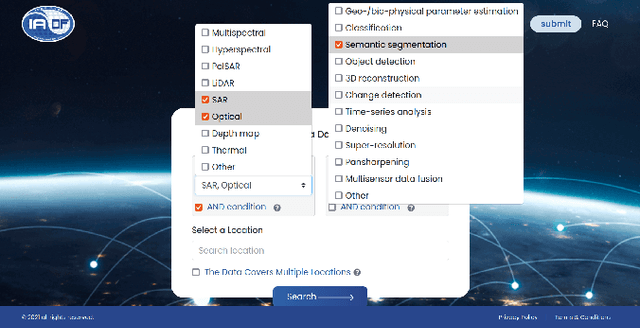
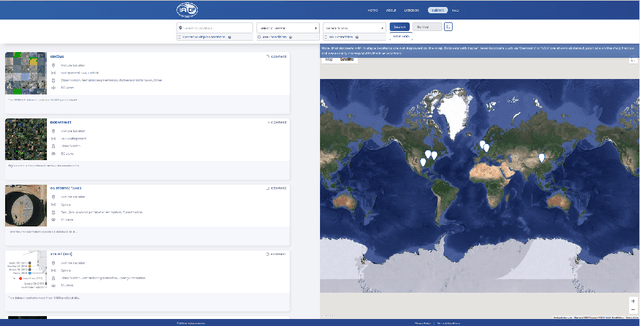
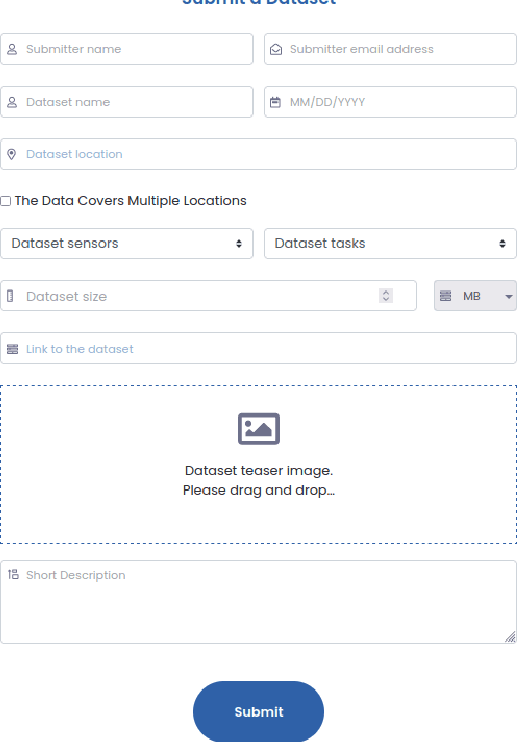
In the era of deep learning, annotated datasets have become a crucial asset to the remote sensing community. In the last decade, a plethora of different datasets was published, each designed for a specific data type and with a specific task or application in mind. In the jungle of remote sensing datasets, it can be hard to keep track of what is available already. With this paper, we introduce EOD - the IEEE GRSS Earth Observation Database (EOD) - an interactive online platform for cataloguing different types of datasets leveraging remote sensing imagery.
Random Ferns for Semantic Segmentation of PolSAR Images
Feb 07, 2022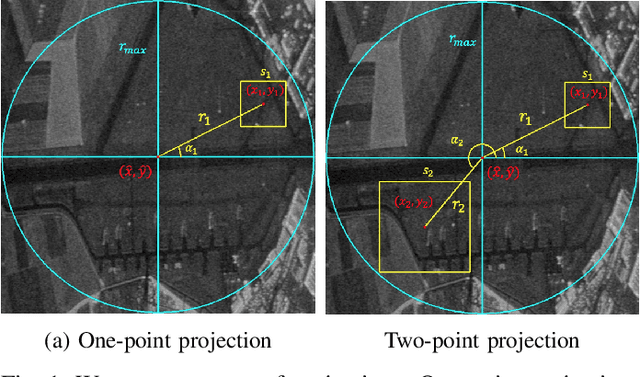
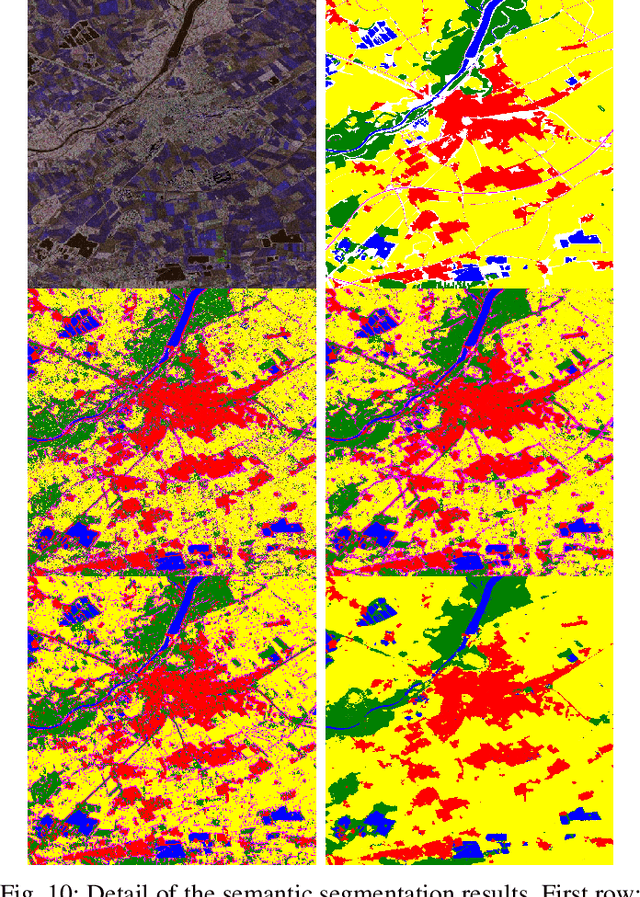
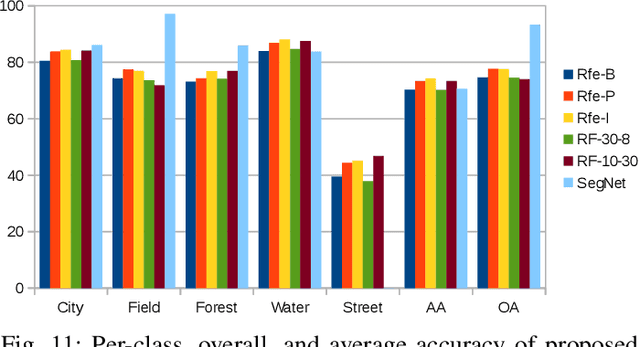
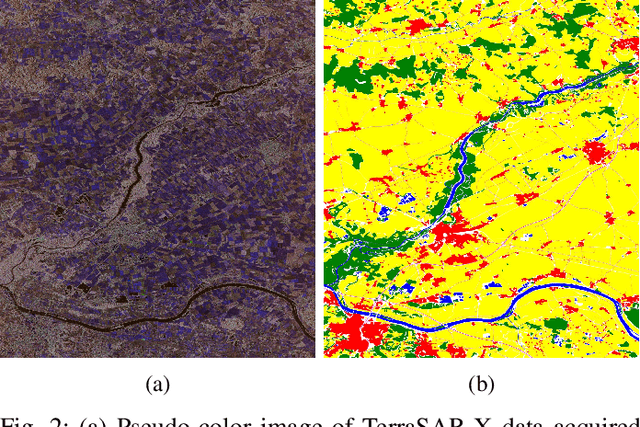
Random Ferns -- as a less known example of Ensemble Learning -- have been successfully applied in many Computer Vision applications ranging from keypoint matching to object detection. This paper extends the Random Fern framework to the semantic segmentation of polarimetric synthetic aperture radar images. By using internal projections that are defined over the space of Hermitian matrices, the proposed classifier can be directly applied to the polarimetric covariance matrices without the need to explicitly compute predefined image features. Furthermore, two distinct optimization strategies are proposed: The first based on pre-selection and grouping of internal binary features before the creation of the classifier; and the second based on iteratively improving the properties of a given Random Fern. Both strategies are able to boost the performance by filtering features that are either redundant or have a low information content and by grouping correlated features to best fulfill the independence assumptions made by the Random Fern classifier. Experiments show that results can be achieved that are similar to a more complex Random Forest model and competitive to a deep learning baseline.
Deep Learning and Earth Observation to Support the Sustainable Development Goals
Dec 21, 2021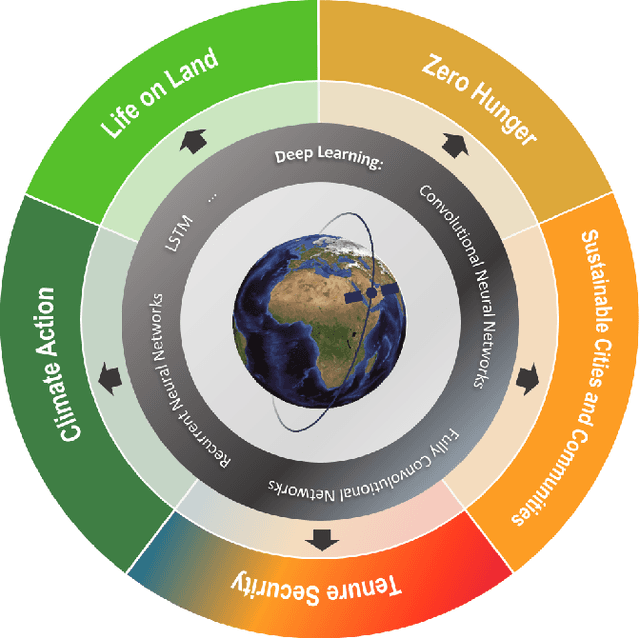

The synergistic combination of deep learning models and Earth observation promises significant advances to support the sustainable development goals (SDGs). New developments and a plethora of applications are already changing the way humanity will face the living planet challenges. This paper reviews current deep learning approaches for Earth observation data, along with their application towards monitoring and achieving the SDGs most impacted by the rapid development of deep learning in Earth observation. We systematically review case studies to 1) achieve zero hunger, 2) sustainable cities, 3) deliver tenure security, 4) mitigate and adapt to climate change, and 5) preserve biodiversity. Important societal, economic and environmental implications are concerned. Exciting times ahead are coming where algorithms and Earth data can help in our endeavor to address the climate crisis and support more sustainable development.
There is no data like more data -- current status of machine learning datasets in remote sensing
May 25, 2021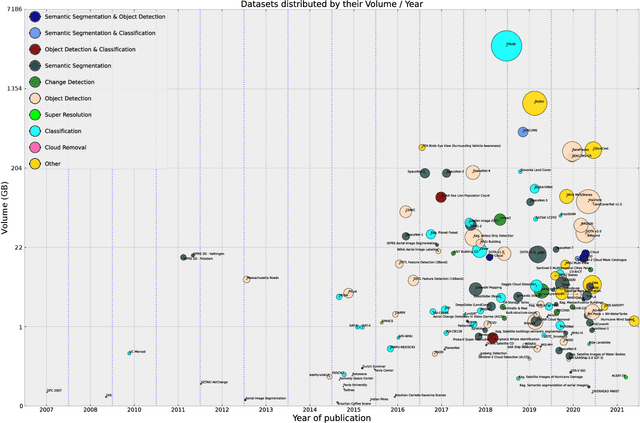
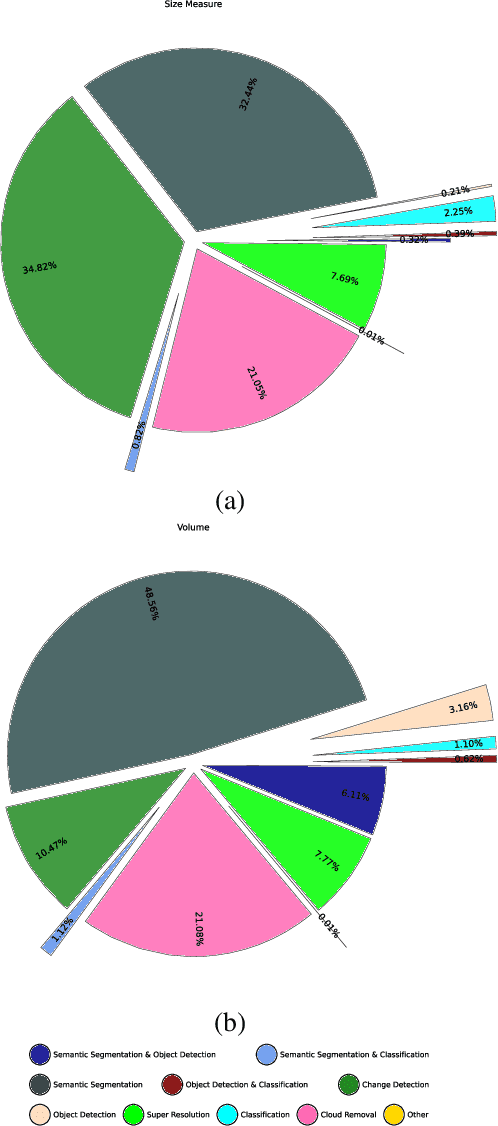
Annotated datasets have become one of the most crucial preconditions for the development and evaluation of machine learning-based methods designed for the automated interpretation of remote sensing data. In this paper, we review the historic development of such datasets, discuss their features based on a few selected examples, and address open issues for future developments.