 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Differential Modulation in Massive MIMO With Low-Resolution ADCs
Dec 02, 2021
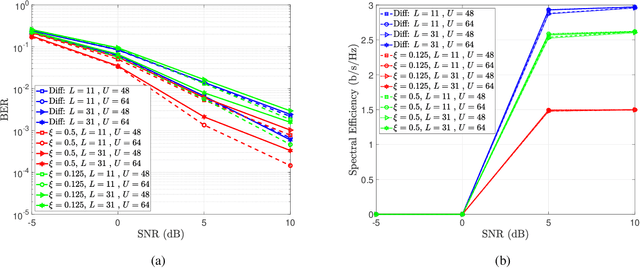
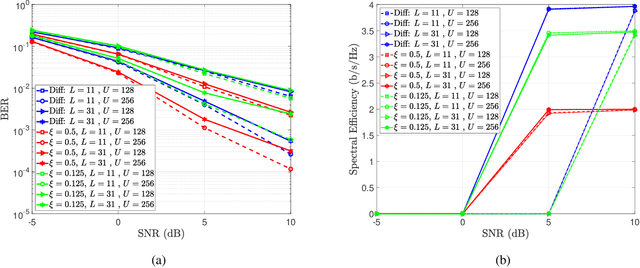
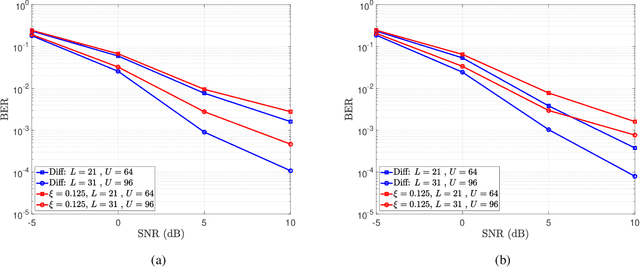
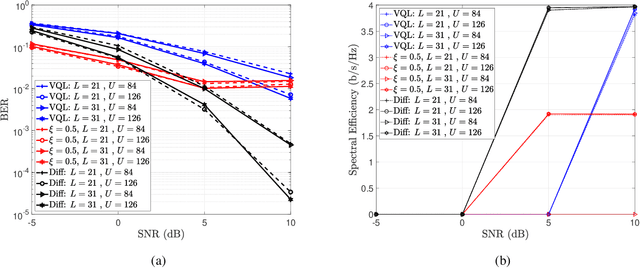
In this paper, we present a differential modulation and detection scheme for use in the uplink of a system with a large number of antennas at the base station, each equipped with low-resolution analog-to-digital converters (ADCs). We derive an expression for the maximum likelihood (ML) detector of a differentially encoded phase information symbol received by a base station operating in the low-resolution ADC regime. We also present an equal performing reduced complexity receiver for detecting the phase information. To increase the supported data rate, we also present a maximum likelihood expression to detect differential amplitude phase shift keying symbols with low-resolution ADCs. We note that the derived detectors are unable to detect the amplitude information. To overcome this limitation, we use the Bussgang Theorem and the Central Limit Theorem (CLT) to develop two detectors capable of detecting the amplitude information. We numerically show that while the first amplitude detector requires multiple quantization bits for acceptable performance, similar performance can be achieved using one-bit ADCs by grouping the receive antennas and employing variable quantization levels (VQL) across distinct antenna groups. We validate the performance of the proposed detectors through simulations and show a comparison with corresponding coherent detectors. Finally, we present a complexity analysis of the proposed low-resolution differential detectors
Similarity-based prediction of Ejection Fraction in Heart Failure Patients
Mar 14, 2022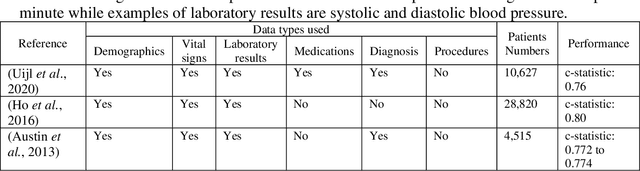
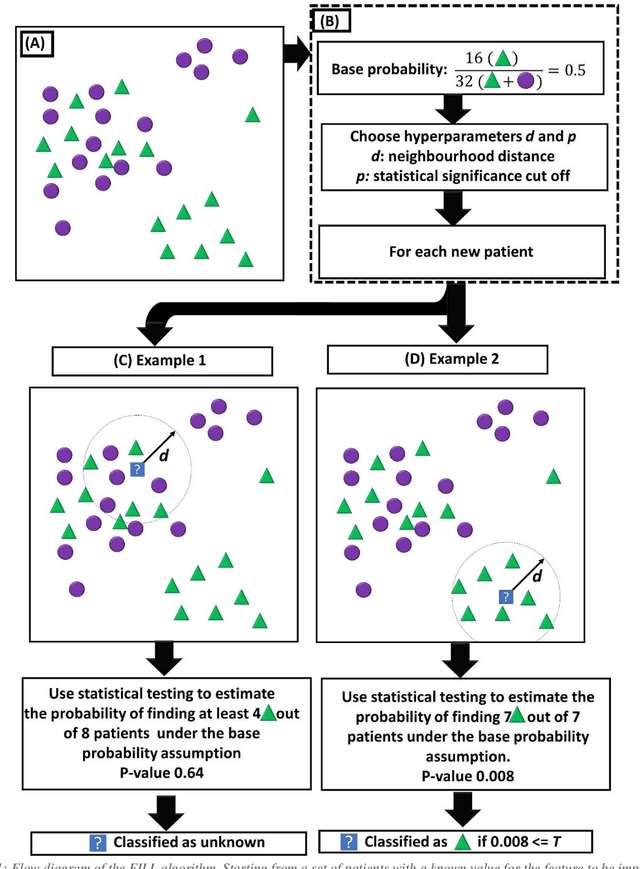


Biomedical research is increasingly employing real world evidence (RWE) to foster discoveries of novel clinical phenotypes and to better characterize long term effect of medical treatments. However, due to limitations inherent in the collection process, RWE often lacks key features of patients, particularly when these features cannot be directly encoded using data standards such as ICD-10. Here we propose a novel data-driven statistical machine learning approach, named Feature Imputation via Local Likelihood (FILL), designed to infer missing features by exploiting feature similarity between patients. We test our method using a particularly challenging problem: differentiating heart failure patients with reduced versus preserved ejection fraction (HFrEF and HFpEF respectively). The complexity of the task stems from three aspects: the two share many common characteristics and treatments, only part of the relevant diagnoses may have been recorded, and the information on ejection fraction is often missing from RWE datasets. Despite these difficulties, our method is shown to be capable of inferring heart failure patients with HFpEF with a precision above 80% when considering multiple scenarios across two RWE datasets containing 11,950 and 10,051 heart failure patients. This is an improvement when compared to classical approaches such as logistic regression and random forest which were only able to achieve a precision < 73%. Finally, this approach allows us to analyse which features are commonly associated with HFpEF patients. For example, we found that specific diagnostic codes for atrial fibrillation and personal history of long-term use of anticoagulants are often key in identifying HFpEF patients.
A Semi-automatic Data Extraction System for Heterogeneous Data Sources: A Case Study from Cotton Industry
Nov 05, 2021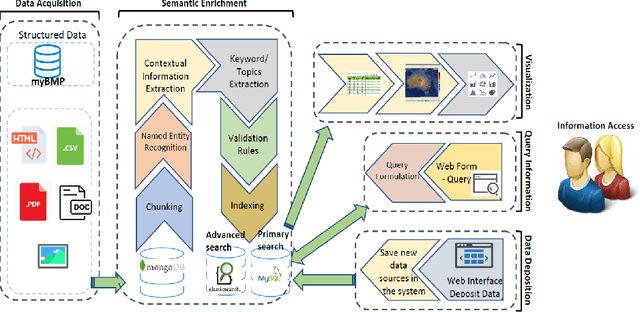
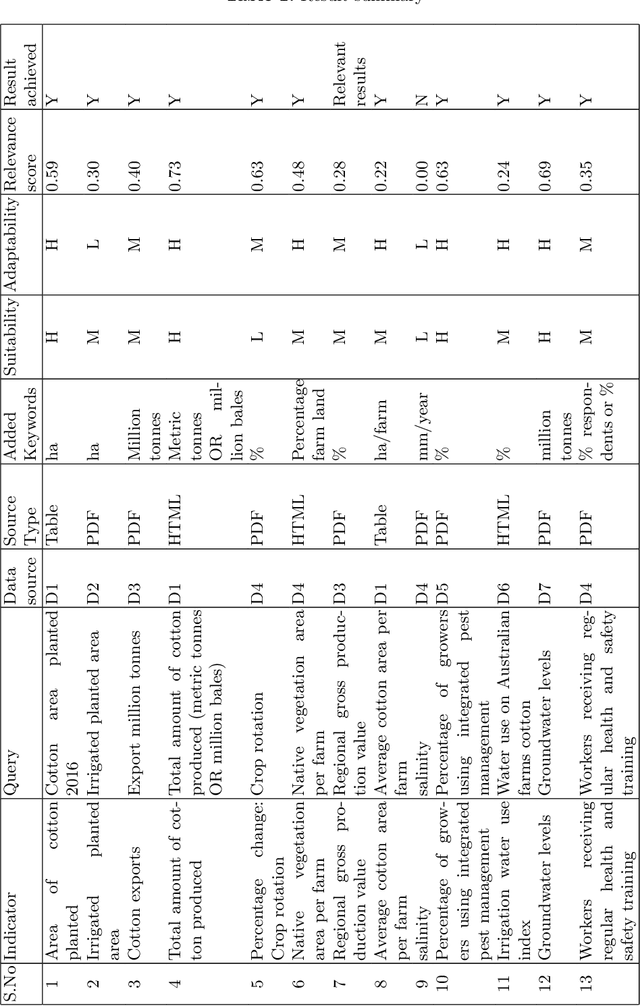

With the recent developments in digitisation, there are increasing number of documents available online. There are several information extraction tools that are available to extract information from digitised documents. However, identifying precise answers to a given query is often a challenging task especially if the data source where the relevant information resides is unknown. This situation becomes more complex when the data source is available in multiple formats such as PDF, table and html. In this paper, we propose a novel data extraction system to discover relevant and focused information from diverse unstructured data sources based on text mining approaches. We perform a qualitative analysis to evaluate the proposed system and its suitability and adaptability using cotton industry.
Continuous Self-Localization on Aerial Images Using Visual and Lidar Sensors
Mar 07, 2022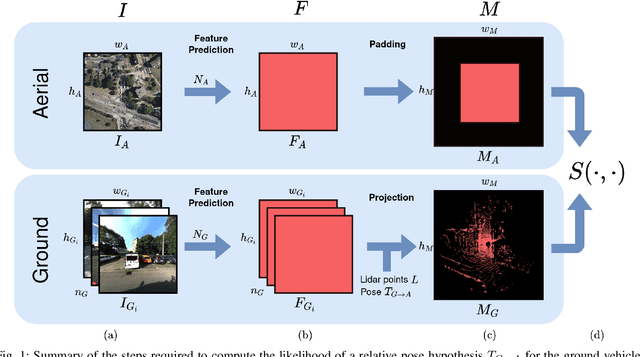
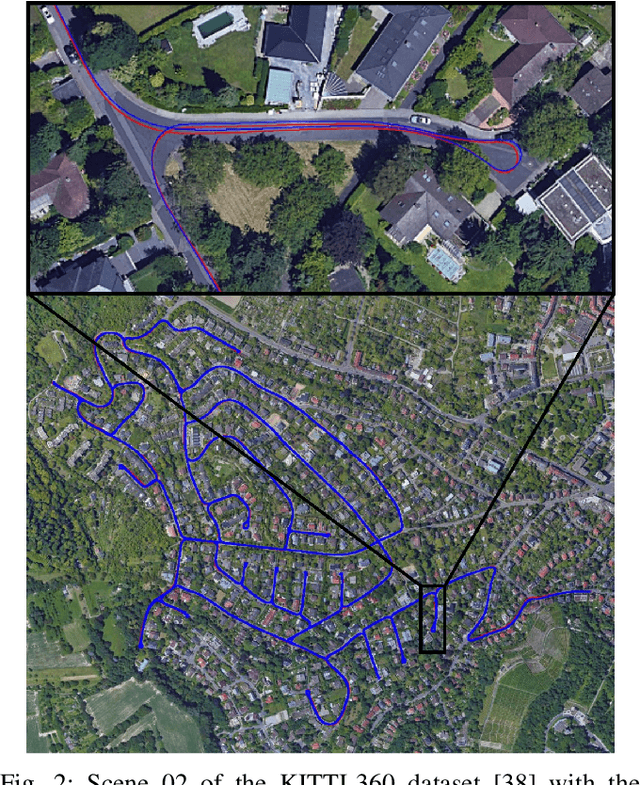
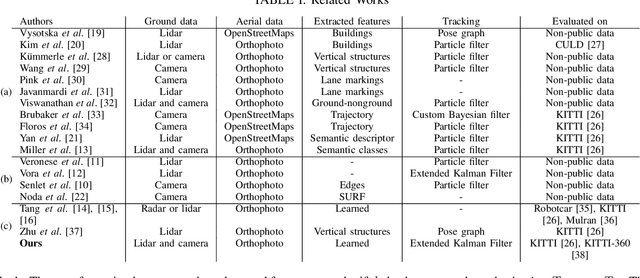
This paper proposes a novel method for geo-tracking, i.e. continuous metric self-localization in outdoor environments by registering a vehicle's sensor information with aerial imagery of an unseen target region. Geo-tracking methods offer the potential to supplant noisy signals from global navigation satellite systems (GNSS) and expensive and hard to maintain prior maps that are typically used for this purpose. The proposed geo-tracking method aligns data from on-board cameras and lidar sensors with geo-registered orthophotos to continuously localize a vehicle. We train a model in a metric learning setting to extract visual features from ground and aerial images. The ground features are projected into a top-down perspective via the lidar points and are matched with the aerial features to determine the relative pose between vehicle and orthophoto. Our method is the first to utilize on-board cameras in an end-to-end differentiable model for metric self-localization on unseen orthophotos. It exhibits strong generalization, is robust to changes in the environment and requires only geo-poses as ground truth. We evaluate our approach on the KITTI-360 dataset and achieve a mean absolute position error (APE) of 0.94m. We further compare with previous approaches on the KITTI odometry dataset and achieve state-of-the-art results on the geo-tracking task.
Affect Expression Behaviour Analysis in the Wild using Spatio-Channel Attention and Complementary Context Information
Sep 29, 2020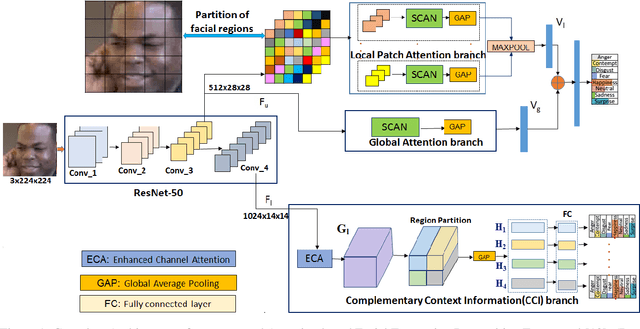
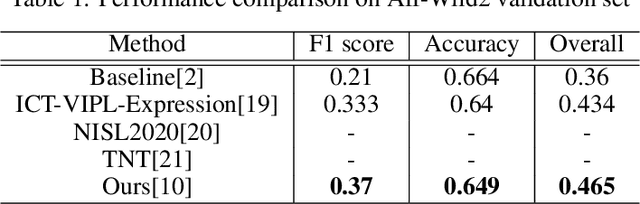
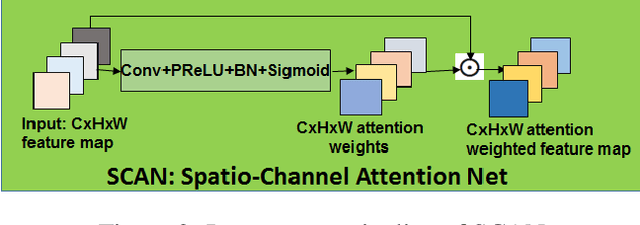

Facial expression recognition(FER) in the wild is crucial for building reliable human-computer interactive systems. However, current FER systems fail to perform well under various natural and un-controlled conditions. This report presents attention based framework used in our submission to expression recognition track of the Affective Behaviour Analysis in-the-wild (ABAW) 2020 competition. Spatial-channel attention net(SCAN) is used to extract local and global attentive features without seeking any information from landmark detectors. SCAN is complemented by a complementary context information(CCI) branch which uses efficient channel attention(ECA) to enhance the relevance of features. The performance of the model is validated on challenging Aff-Wild2 dataset for categorical expression classification.
Ensemble plasticity and network adaptability in SNNs
Mar 11, 2022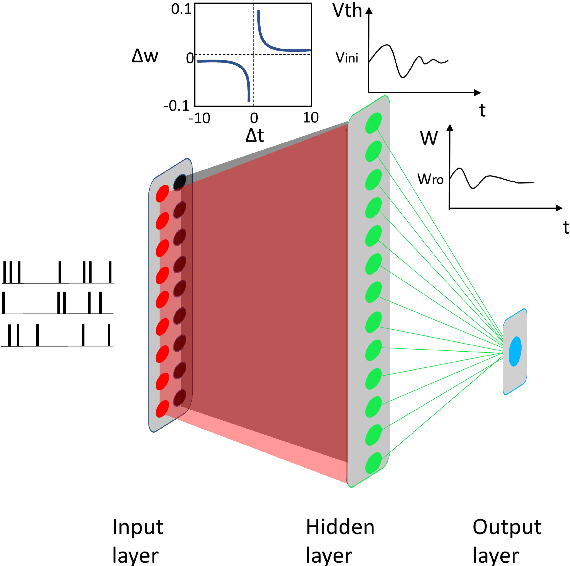
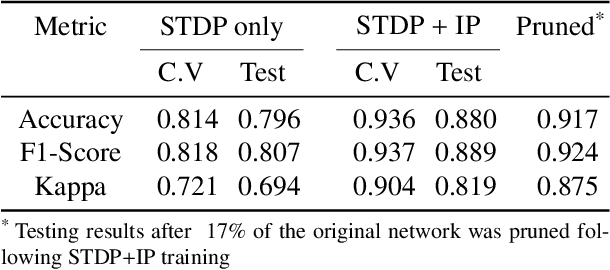
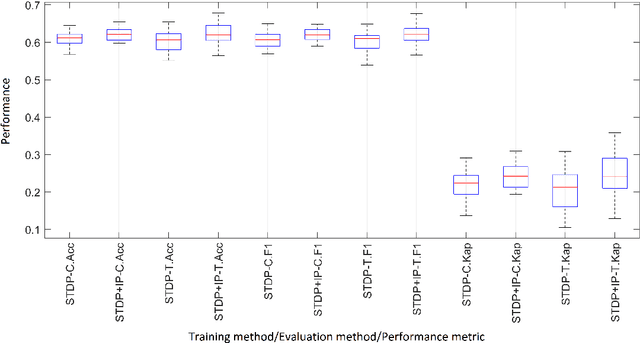
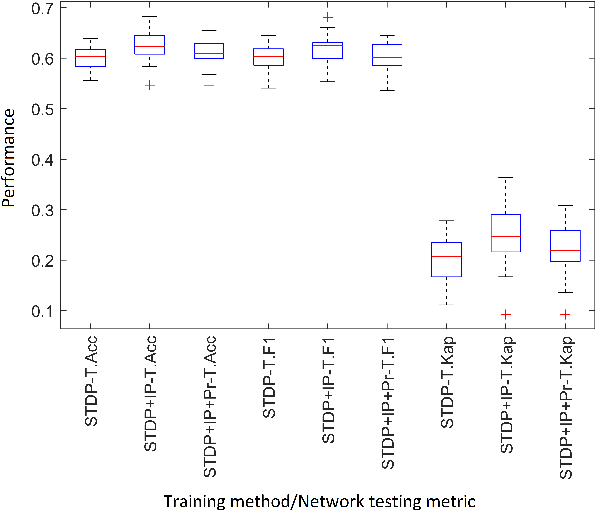
Artificial Spiking Neural Networks (ASNNs) promise greater information processing efficiency because of discrete event-based (i.e., spike) computation. Several Machine Learning (ML) applications use biologically inspired plasticity mechanisms as unsupervised learning techniques to increase the robustness of ASNNs while preserving efficiency. Spike Time Dependent Plasticity (STDP) and Intrinsic Plasticity (IP) (i.e., dynamic spiking threshold adaptation) are two such mechanisms that have been combined to form an ensemble learning method. However, it is not clear how this ensemble learning should be regulated based on spiking activity. Moreover, previous studies have attempted threshold based synaptic pruning following STDP, to increase inference efficiency at the cost of performance in ASNNs. However, this type of structural adaptation, that employs individual weight mechanisms, does not consider spiking activity for pruning which is a better representation of input stimuli. We envisaged that plasticity-based spike-regulation and spike-based pruning will result in ASSNs that perform better in low resource situations. In this paper, a novel ensemble learning method based on entropy and network activation is introduced, which is amalgamated with a spike-rate neuron pruning technique, operated exclusively using spiking activity. Two electroencephalography (EEG) datasets are used as the input for classification experiments with a three-layer feed forward ASNN trained using one-pass learning. During the learning process, we observed neurons assembling into a hierarchy of clusters based on spiking rate. It was discovered that pruning lower spike-rate neuron clusters resulted in increased generalization or a predictable decline in performance.
Lifelong Adaptive Machine Learning for Sensor-based Human Activity Recognition Using Prototypical Networks
Mar 11, 2022
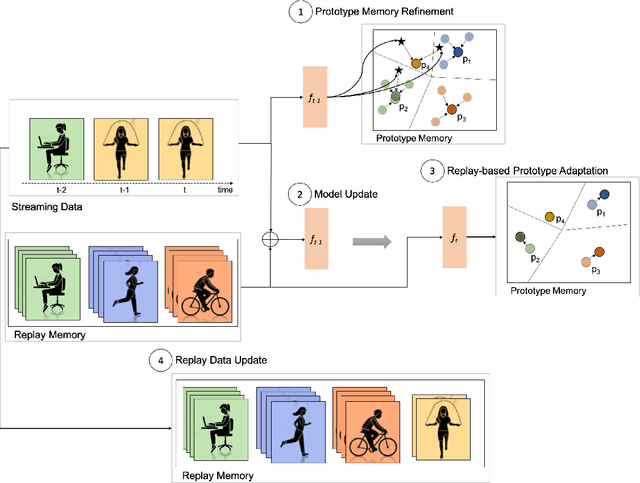
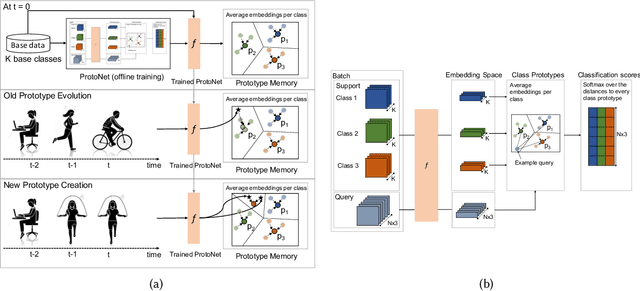

Continual learning, also known as lifelong learning, is an emerging research topic that has been attracting increasing interest in the field of machine learning. With human activity recognition (HAR) playing a key role in enabling numerous real-world applications, an essential step towards the long-term deployment of such recognition systems is to extend the activity model to dynamically adapt to changes in people's everyday behavior. Current research in continual learning applied to HAR domain is still under-explored with researchers exploring existing methods developed for computer vision in HAR. Moreover, analysis has so far focused on task-incremental or class-incremental learning paradigms where task boundaries are known. This impedes the applicability of such methods for real-world systems since data is presented in a randomly streaming fashion. To push this field forward, we build on recent advances in the area of continual machine learning and design a lifelong adaptive learning framework using Prototypical Networks, LAPNet-HAR, that processes sensor-based data streams in a task-free data-incremental fashion and mitigates catastrophic forgetting using experience replay and continual prototype adaptation. Online learning is further facilitated using contrastive loss to enforce inter-class separation. LAPNet-HAR is evaluated on 5 publicly available activity datasets in terms of the framework's ability to acquire new information while preserving previous knowledge. Our extensive empirical results demonstrate the effectiveness of LAPNet-HAR in task-free continual learning and uncover useful insights for future challenges.
Symbiotic Attention with Privileged Information for Egocentric Action Recognition
Feb 08, 2020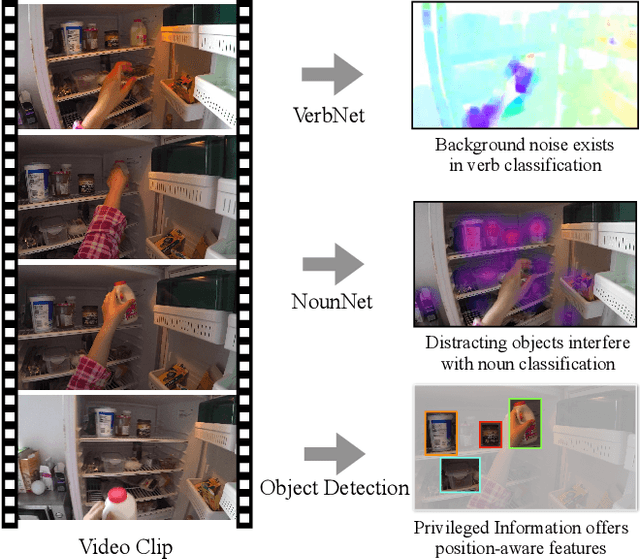
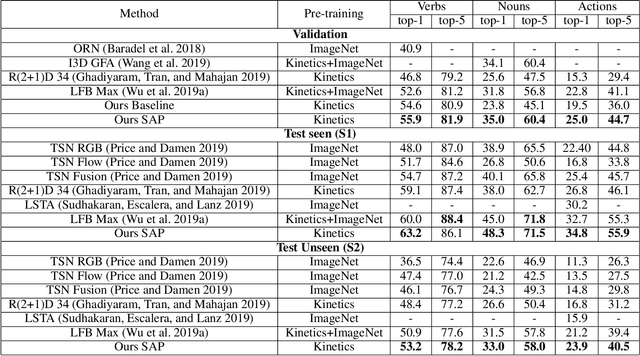
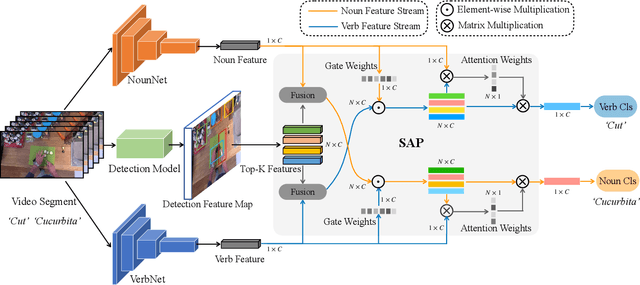
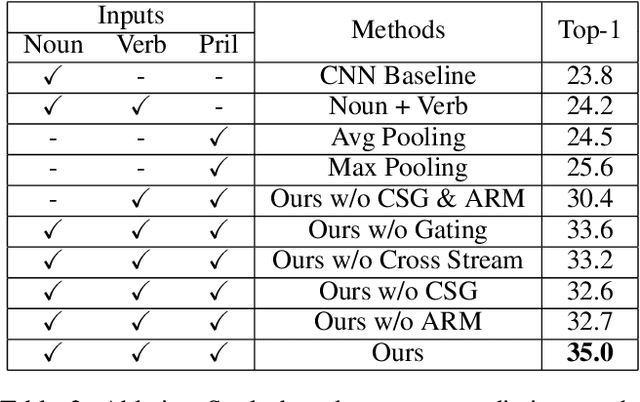
Egocentric video recognition is a natural testbed for diverse interaction reasoning. Due to the large action vocabulary in egocentric video datasets, recent studies usually utilize a two-branch structure for action recognition, ie, one branch for verb classification and the other branch for noun classification. However, correlation studies between the verb and the noun branches have been largely ignored. Besides, the two branches fail to exploit local features due to the absence of a position-aware attention mechanism. In this paper, we propose a novel Symbiotic Attention framework leveraging Privileged information (SAP) for egocentric video recognition. Finer position-aware object detection features can facilitate the understanding of actor's interaction with the object. We introduce these features in action recognition and regard them as privileged information. Our framework enables mutual communication among the verb branch, the noun branch, and the privileged information. This communication process not only injects local details into global features but also exploits implicit guidance about the spatio-temporal position of an on-going action. We introduce novel symbiotic attention (SA) to enable effective communication. It first normalizes the detection guided features on one branch to underline the action-relevant information from the other branch. SA adaptively enhances the interactions among the three sources. To further catalyze this communication, spatial relations are uncovered for the selection of most action-relevant information. It identifies the most valuable and discriminative feature for classification. We validate the effectiveness of our SAP quantitatively and qualitatively. Notably, it achieves the state-of-the-art on two large-scale egocentric video datasets.
Semantically Proportional Patchmix for Few-Shot Learning
Feb 17, 2022
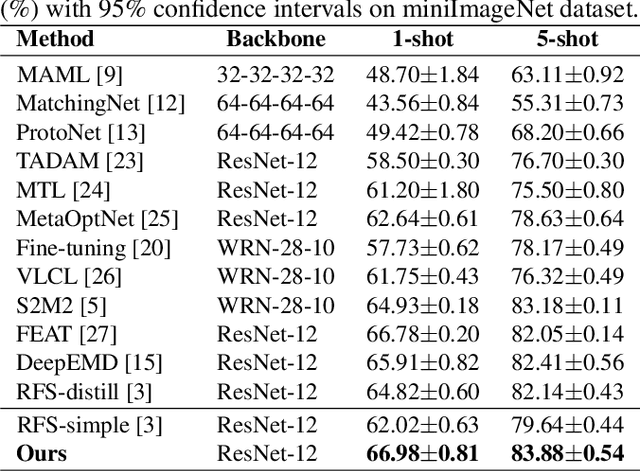

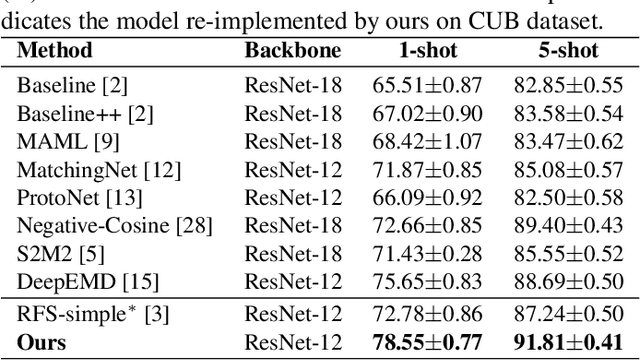
Few-shot learning aims to classify unseen classes with only a limited number of labeled data. Recent works have demonstrated that training models with a simple transfer learning strategy can achieve competitive results in few-shot classification. Although excelling at distinguishing training data, these models are not well generalized to unseen data, probably due to insufficient feature representations on evaluation. To tackle this issue, we propose Semantically Proportional Patchmix (SePPMix), in which patches are cut and pasted among training images and the ground truth labels are mixed proportionally to the semantic information of the patches. In this way, we can improve the generalization ability of the model by regional dropout effect without introducing severe label noise. To learn more robust representations of data, we further take rotate transformation on the mixed images and predict rotations as a rule-based regularizer. Extensive experiments on prevalent few-shot benchmarks have shown the effectiveness of our proposed method.
Discrete and continuous representations and processing in deep learning: Looking forward
Jan 04, 2022
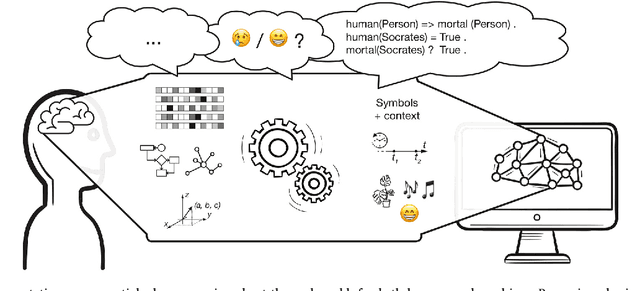
Discrete and continuous representations of content (e.g., of language or images) have interesting properties to be explored for the understanding of or reasoning with this content by machines. This position paper puts forward our opinion on the role of discrete and continuous representations and their processing in the deep learning field. Current neural network models compute continuous-valued data. Information is compressed into dense, distributed embeddings. By stark contrast, humans use discrete symbols in their communication with language. Such symbols represent a compressed version of the world that derives its meaning from shared contextual information. Additionally, human reasoning involves symbol manipulation at a cognitive level, which facilitates abstract reasoning, the composition of knowledge and understanding, generalization and efficient learning. Motivated by these insights, in this paper we argue that combining discrete and continuous representations and their processing will be essential to build systems that exhibit a general form of intelligence. We suggest and discuss several avenues that could improve current neural networks with the inclusion of discrete elements to combine the advantages of both types of representations.